摘要:
高效地将多通道的图像数据压缩(如高光谱、多光谱成像数据)至较低的通道数,对提高深度学习(DL)模型的训练速度和预测至关重要。本文主要展示利用PCA降维结合weight-average的图像融合方法。文章主要参考了题为“Noninvasive Detection of Salt Stress in Cotton Seedlings by Combining Multicolor Fluorescence–Multispectral Reflectance Imaging with EfficientNet-OB2”在论文中使用的方法。
论文源:Noninvasive Detection of Salt Stress in Cotton Seedlinmbining Multicolor Fluorescence–Multispectral Reflectance Imaging with EfficientNet-OB2 | Plant Phenomics (science.org)
PCA-WA简介:
PCA-WA(主成分分析-加权平均)是一种图像融合方法,结合了主成分分析(PCA,principal component analysis)和加权平均(WA,weight average)两种技术。
优点:
- 保留主要信息:通过PCA方法,可以提取出源图像中的主要成分,即包含最多信息的特征。这有助于在融合过程中保留关键信息,使得融合后的图像在保留重要特征方面表现较好。
- 降低维度:PCA方法可以将高维数据降维,从而减少计算量和存储需求。这在处理大规模图像数据时尤为重要,可以加快处理速度和节省存储空间。
缺点:
- 对源图像质量敏感:PCA-WA方法的性能在很大程度上取决于源图像的质量。如果源图像存在噪声、模糊或对比度低等问题,那么融合后的图像质量可能会受到影响。
- 可能产生光谱失真:在使用PCA进行降维时,可能会丢失一些光谱信息。这可能导致融合后的图像在光谱特性上与源图像存在差异,从而产生光谱失真现象。
注意事项
数据预处理:在进行数据融合之前需要将数据进行对应的校正,避免后续噪声污染
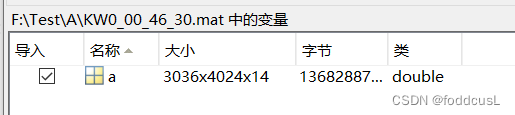
输入数据:为M*N*C的double矩阵也就是校正后的图像浮点数值。需要事先将这些变量存储为.mat文件。储存变量命为a
操作示范
首先是输入的文件:如图,PCA需要所有处理的样本信息,所以按照格式将所有样本整理好
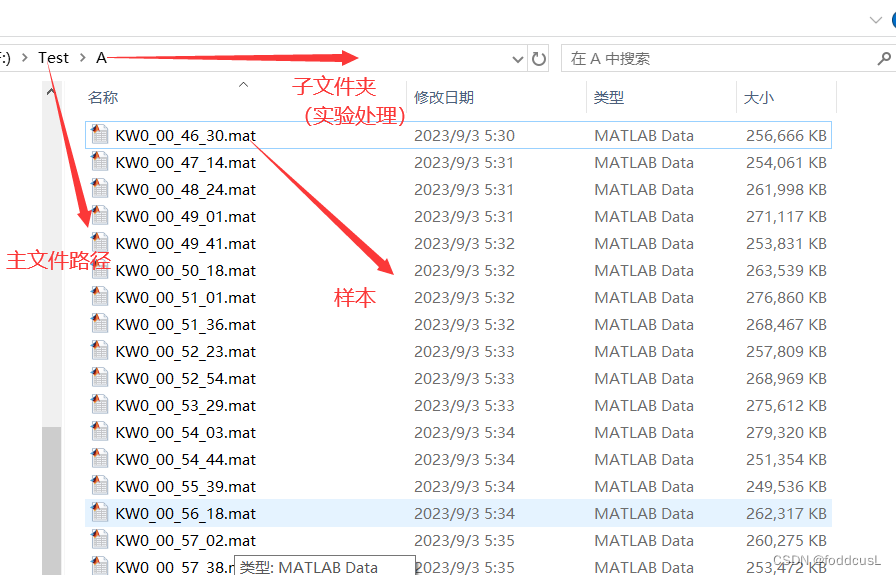
单个样本的信息如图:我测试的数据是自己采集的4K分辨率且有14个通道的多源光谱数据,变量统一为a,其中几个未融合的通道的图像可以展示如下



使用PCA-WA算法进行图像融合后,生成的图像会存放至预设的文件夹中

融合后的数据,前三个主成分占95%的贡献率,所以融合后为3个主成分通道。手动将这些数据归一化映射至uint8(0-255)展示如下:融合后数据量得到了充分的压缩。

代码
主脚本代码FusionProject
clear all
获得PCA-WA融合的数据
WA图像融合,全称为Weighted Averaging图像融合,
也叫简单加权融合或者像素加权平均法,是一种图像融合方法。
这种方法的基本思想是将多源信道采集到的关于同一目标的图像
数据经过处理和计算,将各自信道中的有利信息提取出来,然后综合成
一幅高质量的图像。
在具体实现时,WA图像融合通过对来自不同图像的对应像素进行加权平均,
以得到融合后图像中的每个像素值。这种方法具有简单易实现、运算速度快
的优点,并能提高融合图像的信噪比。然而,它也存在一些缺点,比如可能
会削弱图像中的细节信息,降低图像的对比度,并在一定程度上使图像中的
边缘变得模糊。
为了改进这些缺点,可以采用一些优化方法,
如主成分分析(Principal Component Analysis,PCA)来优化权值的选择,
从而得到一幅亮度方差最大的融合图像。
%输入部分(根据自己的需求修改这部分内容)
%要处理文件所在的文件夹
% (多个文件夹则输入多个文件夹,要包含所有样本,PCA计算才准确),样本变量名均为a
% 注意地址要单引号标志
DealPath{1}='F:\Test\A';
DealPath{2}='F:\Test\B';
%处理好的文件输出位置,对应你输入文件的数量
OutputPath{1}='C:\Users\ljy\Desktop\Test1\A';
OutputPath{2}='C:\Users\ljy\Desktop\Test1\B';
%%图片的基本信息
%通道数
ChannelNum=14;
%红色荧光(F740)所在的通道
fluo_CNum=4;
%图像输出的分辨率
outputReso=[300 400];
orinPath=cd();
%%这一过程可能很漫长,运行时间主要取决于你的样本量、数据大小、CPU性能及硬盘速度。
%%1000个样本跑一个小时以上是正常的
%%阶段1:获取数据的通道均值
fileNum=length(DealPath);
allData=[];
%启用红色荧光分割图像,(如果前期工作已经校正及图像分割了,请关闭)
% 其他数据把分割关掉(1改为0)
for i=1:fileNum
allData=[allData;AverageChannelData(DealPath{i},ChannelNum,[0,fluo_CNum])];
end
%阶段二:PCA分析
%归一化
[ynum,~]=size(allData);
stdr =std(allData); %计算标准差,计算每一列的标准差
averageD=mean(allData,1);
for i=1:ynum
data2(i,:)=allData(i,:)-averageD(1,:);
end
%sr是预处理后的数据,使原始数据每个参数除于其标准差
sr =data2./repmat(stdr,size(allData,1),1);
%% PCA
%获取主成分系数
[coeff,~,~,~,explained,~]= pca(sr);
%分析占 95% 解释性的主成分
for i=1:ChannelNum
if sum(explained(1:i))>95
numP=i
break
end
end
%阶段3融合图像
for i=1:fileNum
srcDir=dir(DealPath{i}); %获得选择的文件夹
[numFile,~]=size(srcDir);
for j=3 :numFile
names_Fir=srcDir(j).('name');
newfile_Fir=[DealPath{i},'\',names_Fir];%数据文件名
load(newfile_Fir);
%图像归一化
for cn=1:numP
Nora(:,:,cn)=(a(:,:,cn)-averageD(cn))./stdr(cn);
end
%融合
FusionPic=imresize(FusionPic_WA_PCA(Nora,coeff),outputReso);
cd(OutputPath{i});
save(names_Fir,"FusionPic");%储存
cd(orinPath);
end
end
附带自定义函数
T_SGM
%阈值分割函数,获得分割的蒙版
%输入:img:图像(灰度图像)
% ThresH:阈值
% (为0时为二值化分割,为1时为迭代法全局阈值分割,为2时为全局阈值Otsu法阈值分割,三为基于形态学元素的局部分割,4为指定阈值分割)
%pluse:补充数据,当ThresH为3时,pluse表示形态学的元素的半径,其值越大,分割区域越大,为4时为分割的数
function output=T_SGM(img,ThresH,pluse)
img=im2double(img);%图像二值化
if ThresH==0
output =im2double(imbinarize(I));
elseif ThresH==1
T=0.5*(min(img(:))+max(img(:)));
done=false;
while ~done
g=(img>=T);%建立区域g,为大于阈值的部分
Tn=0.5*(mean(img(g))+mean(img(~g)));%当图像中g的区域与非g的区域的均值接近于目标阈值时,分割完成
done = abs(T-Tn)<0.1;
T=Tn;
end
output=imbinarize(img,T);
elseif ThresH==2
Th=graythresh(img);%阈值
output=imbinarize(img,Th);
elseif ThresH==3
se=strel('disk',pluse);%建立形态学 结构元素
ft=imtophat(img,se);%使用结构元素进行滤波
Thr=graythresh(ft);%早对滤波后的图像进行阈值取值
output = imbinarize(ft,Thr);
elseif ThresH==4
output=imbinarize(img,pluse);
end
end
SelecValueOfPic
function [actualaverageValue,actualNum,segama,K,S] = SlecValueOfPic(img,range,method)
%SLECVALUEOFPIC
%输入一张分割后的灰度图片;根据这这张图片的像素值统计(除零外),取中间range值的范围的内容;并返回这个范围的平均值;
%这个取值的逻辑是取像素值中间的分布,以个数划分,如10个像素取60%取平均,就是取中间值的6个像素的平均;这种方法可以提高图像反射率的数值的鲁棒性,将噪点和背景的反射屏蔽掉一部分;
% actualavergeValue:最后输出的平均值
% img:输入的图像
% range:范围,大小为0-1之间;(折合百分数)
% method:方法 1为中位数法 2为正太分布法 3为平均数法
% actualnum:为成像面积
% segama:偏度
segama=0;
K=0;
S=0;
if method==1
staticD=imhist(img);
allN=sum(staticD(2:256,1));
rangeN=ceil(allN*range);
thresholdNum=ceil((allN-rangeN)/2);
thresholdValue=0;%初始化
thresholdValueHigh=0;
actualNum=0;
for i=2:256%计算区间,为0的背景不算;
nowSum=sum(staticD(2:i,1));
if nowSum>thresholdNum
if thresholdValue==0
thresholdValue=i;%获得了最低门槛;
end
end
if nowSum>(thresholdNum+rangeN)
if thresholdValueHigh==0
thresholdValueHigh=i;%获得了最高门槛;
end
end
end
allV=0;
if thresholdValue~=0
for j=thresholdValue:thresholdValueHigh%计算这个像素区间的平均值
repreValue=staticD(j,1)*(j-1);%统计是从零开始统计;
allV=allV+repreValue;
end
actualNum=sum(staticD(thresholdValue:thresholdValueHigh,1));
actualaverageValue=allV/rangeN;
else
actualNum=0;
actualaverageValue=0;
end
elseif method==2%正太分布估计,此时actualnum为偏度
[r,c]=find(img);
[actualaverageValue,segama] = normfit(img(find(img)));
K=kurtosis(img(find(img)));%峰度
S=skewness(img(find(img)));%偏度
[actualNum,~]=size(r);
elseif method==3%平均,正太分布和平均效果一致(如果符合正太分布的话);
[r,c]=find(img);
actualaverageValue = mean(img(find(img)),'all');
[actualNum,~]=size(r);
end
endMap_uint8
function U8_p =Map_uint8(doubleP,num_min,num_max)
band_div=(num_max-num_min)/256;
U8_p=(doubleP-num_min)/band_div;
MapMax=find(U8_p(:,:)>255);
MapMin=find(U8_p(:,:)<0);
U8_p(MapMax)=255;
U8_p(MapMin)=0;
U8_p=uint8(U8_p);
endFusionPic_WA_PCA
function FusionPic=FusionPic_WA_PCA(IMGmat,PCAdet)
%输入:IMGmat 为基本处理(校正)后的成像数据(储存格式为matlab data *.mat)
% 大小为M(图像高度)*N(图像宽度)*C(图像通道数)
%输入: PCAdet 为PCA的降维数据,为PCA-WA的权重提供参考
[y,x,cnum]=size(IMGmat);
FusionPic=zeros(y,x,cnum);
%数据叠加
for i=1:cnum
for j=1:cnum
FusionPic(:,:,i)=FusionPic(:,:,i)+PCAdet(i,j)*IMGmat(:,:,j);
end
end
DeleNos_dot
%输入 mask为2值化图像
%在特定区域内的分割若达不到比例,则进行消除
function output=DeleNos_dot(mask,length,Percent)
numDiv=ceil(Percent*length^2);
[ysize,xsize]=size(mask);
for i=length:xsize-length%用区域蒙版的量做判断消除杂点
for j=length:ysize-length
if mask(j,i)==1
if sum(sum(mask(j-3:j+3,i-3:i+3)))<numDiv
mask(j,i)=0;
end
end
end
end
output=mask;AverageOneSample
function data = AverageOneSample(Sample,EX)
%主要是求图像校正后,分割后的平均值
%EX为1*2的double 分别代表范围和取值的方法 默认【0.6,3】
%[actualaverageValue,actualNum,segama,K,S] = slecValueOfPic(img,range,method)
%SLECVALUEOFPIC
%输入一张分割后的灰度图片;根据这这张图片的像素值统计(除零外),取中间range值的范围的内容;并返回这个范围的平均值;
% actualavergeValue:最后输出的平均值
% img:输入的图像
% range:范围,大小为0-1之间;
% method:方法 1为中位数法 2为正太分布法 3为平均数法,基本上2和3一致
% actualnum:为成像面积
% segama:偏度
[x,y,z]=size(Sample);
for i=1:z
[data(i,1),data(i,2),~,~,~] = SlecValueOfPic(Sample(:,:,i),EX(1),EX(2));
end
endAverageChannelData
%检查文件数量是否匹配
function allData=AverageChannelData(aimPath,numchannel,IFSGM)
%输入部分
%aimPath:采集目标的路径
%aimPath='F:\23新疆大田数据校正后\SSS';%目标路径,得用单引号"
%IFSGM 大小为1*2,(1,1)若为1则执行基于荧光的分割,(1,2)为红色荧光所在的位置
orinPath=cd();%函数执行所在的路径,默认原路径
%目标文件
srcDir=dir(aimPath); %获得选择的文件夹
[numFile,~]=size(srcDir);
data=zeros(numchannel,2);
for j=3 :numFile
names_Fir=srcDir(j).('name');
newfile_Fir=[aimPath,'\',names_Fir];%数据文件名
load(newfile_Fir);
if IFSGM(1,1)==1
tureMask=T_SGM(Map_uint8(a(:,:,3),min(min(a(:,:,3))),max(max(a(:,:,3)))),4,0.045);%图像分割
tureMask2=DeleNos_dot(tureMask,10,0.2);%清理噪点
[yn,xn,zn]=size(a);
b=zeros(yn,xn,zn);
for i=1:14
b(:,:,i)=a(:,:,i).*tureMask2;
end
else
b=a;
end
data = AverageOneSample(b,[0.6,3]);
allData(j-2,1:14)=data(1:14,1)';
end
end