〇、前言
12月1日,2023中国图象图形学学会青年科学家会议在广州召开。超1400名研究人员齐聚一堂,进行学术交流与研讨,共同探索促进图象图形领域“产学研”交流合作。
大会上,合合信息智能技术平台事业部副总经理、高级工程师丁凯博士在《垂直领域大模型》主题论坛上进行了《文档图像大模型的思考与探索》主题分享。

一、技术难题仍存在
2023年,随着以Chat-GPT为代表的大语言模型和GPT4-V多模态大模型的爆火,虽然他们在文档领域已经取得了令人惊艳的效果,但目前,OCR文档图像识别等领域的核心技术难题仍然存在。
- 场景及版式多样:文档图像可能来自不同的场景和版式,如报纸、书籍、手写笔记等,每种场景和版式都具有不同的特点和挑战,需要算法能够适应不同的场景和版式。
- 采集设备不确定性:文档图像可能通过不同的采集设备获取,如扫描仪、手机相机等,不同设备的成像质量和参数不同,导致图像质量和特征的差异,需要算法具备鲁棒性,能够处理不同设备采集的图像。
- 用户需求多样性:用户对文档图像的需求各不相同,有些用户可能只需要提取文本信息,而有些用户可能需要进行结构化的理解和分析,算法需要能够满足不同用户的需求。
- 文档图像质量退化严重:由于文档的老化、损坏或存储条件等原因,文档图像的质量可能会受到严重的退化,如模糊、噪声、光照不均等,这会给文字检测、字符识别等任务带来困难。
- 文字检测及版面分析困难:文档图像中的文字可能存在不同的字体、大小、颜色等变化,而且文字可能与背景颜色相似,导致文字检测和版面分析变得困难,算法需要具备高效准确的文字检测和版面分析能力。
- 非限定条件文字识别率低:在非限定条件下,文档图像中的文字可能出现扭曲、变形、遮挡等情况,这会导致传统的文字识别算法的准确率下降,需要算法具备对非限定条件下的文字进行准确识别的能力。
- 结构化智能理解能力差:文档图像中的信息不仅仅是文字,还包括表格、图表、图像等结构化信息,算法需要具备结构化智能理解的能力,能够对文档中的结构化信息进行提取、分析和理解。

虽然大模型技术发展很快,特别是GPT4-V、Gemini等新技术的发明,但是领域内需要解决的核心问题并没有变,在IDP领域,上述这几个大的问题仍然是我们重点关注的,只不过由于大模型的出现,使得我们对技术的期待变得更高了。
二、GPT4-V在文档处理领域的表现
“LLM出现后,IDP的问题解决的如何了? 在具体的技术方案上有没有什么重大的变化?这个是我们关心的话题。”
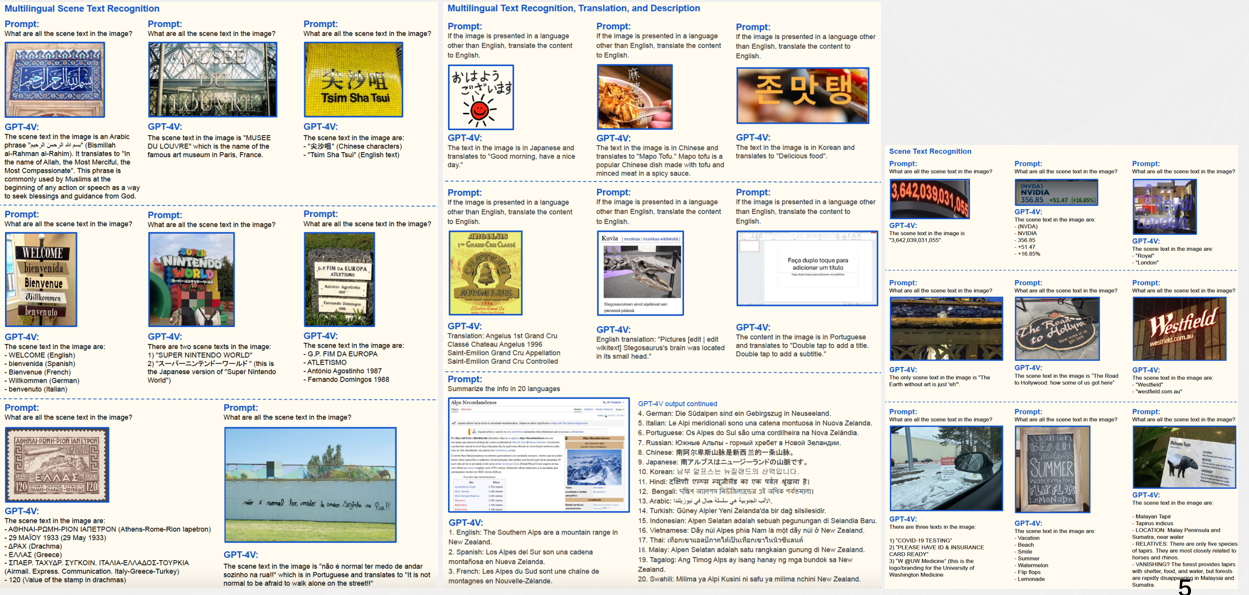
GPT4-V优点
- 端到端解决识别和理解问题,认知能力强。
- 支持识别和理解的文档元素类型远超传统IDP算法。
在场景文字识别上,无论是何种不同语言形态和种类的场景下,在手写密集文档、几何图形与文字结合、图表理解、教育场景、信息抽取、文档理解等领域,GPT-4V都可以取得比较好的结果。
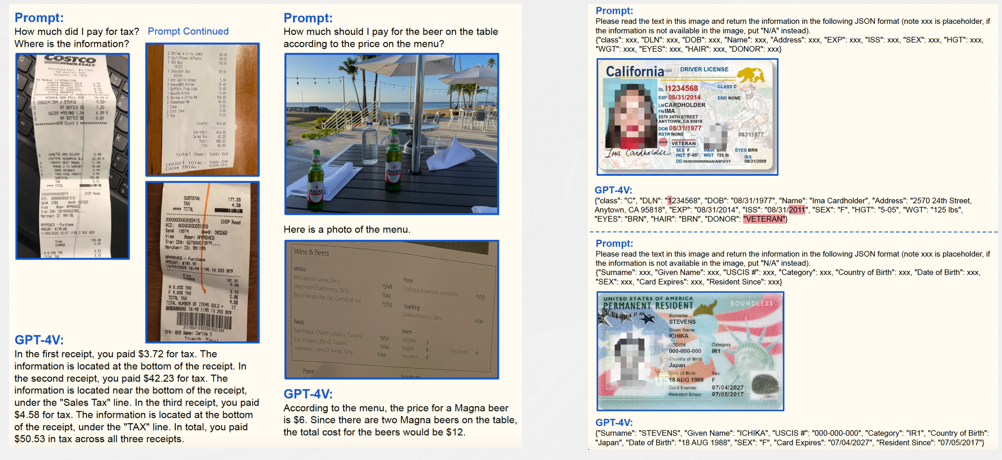
GPT4-V不足
- OCR精度距离SOTA有较大差距。
- 长文档依赖外部的OCR/文档解析引擎。
GPT-4V目前在手写中文识别、公式等方面仍存在识别混乱、错误等问题。
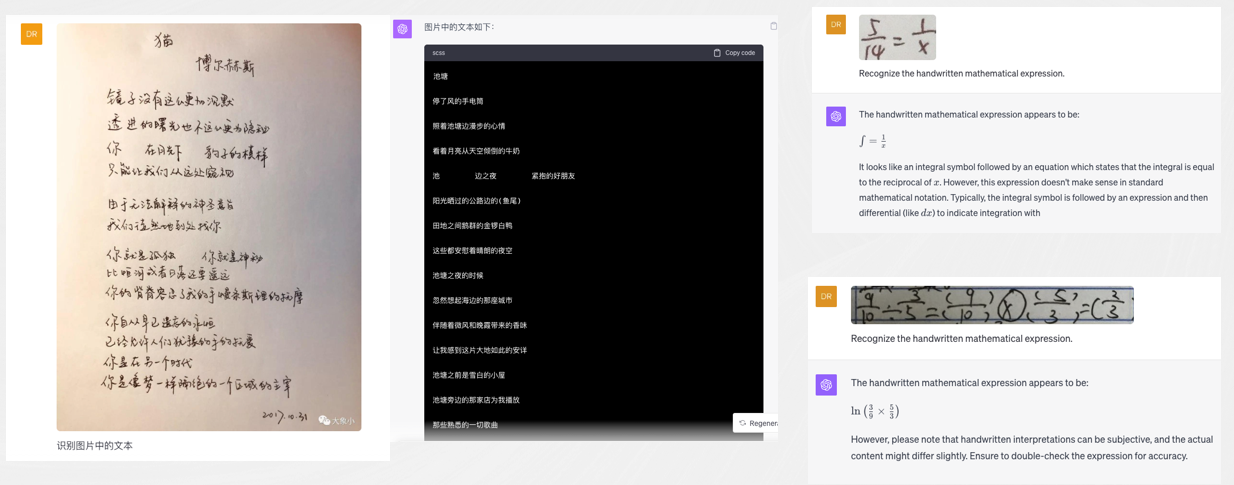
目前,GPT-4V在 OCR、IDP 领域的水平较 SOTA 还有非常大的差距,对于长文档,仍然有文档解析和识别的前置依赖,ChatGPT 调用了开源的 PyPDF2,但该插件效果并不好,且输出不支持表格结构、不支持扫描件、不支持处理复杂版式、不支持定位到原文。
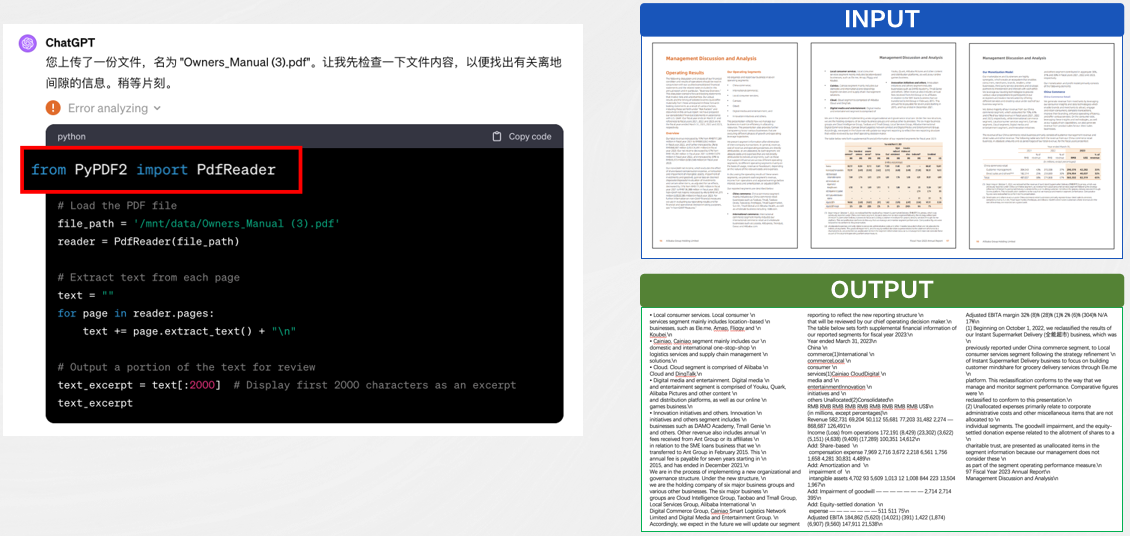
思考与总结
GPT4-V多模态大模型大幅度提升了AI技术在文档分析与识别领域的能力边界,端到端实现了文档的识别到理解的全过程。并且提供了一条研发新范式:“大数据、大算力、多任务、端到端。”
像篡改检测、文本分割擦除这样像素级的任务,GPT-4V大模型处理的并不好,虽然它在文档解析和识别领域的能力已经具备,但较之于SOTA方法来比较,性能还是有待提升。
GPT-4V这样多模态大模型的强项在于信息抽取和理解认知层面,这一特点在经过有效利用后,可以大幅提升该研究领域的天花板。
三、大模型时代对IDP的思考与探索
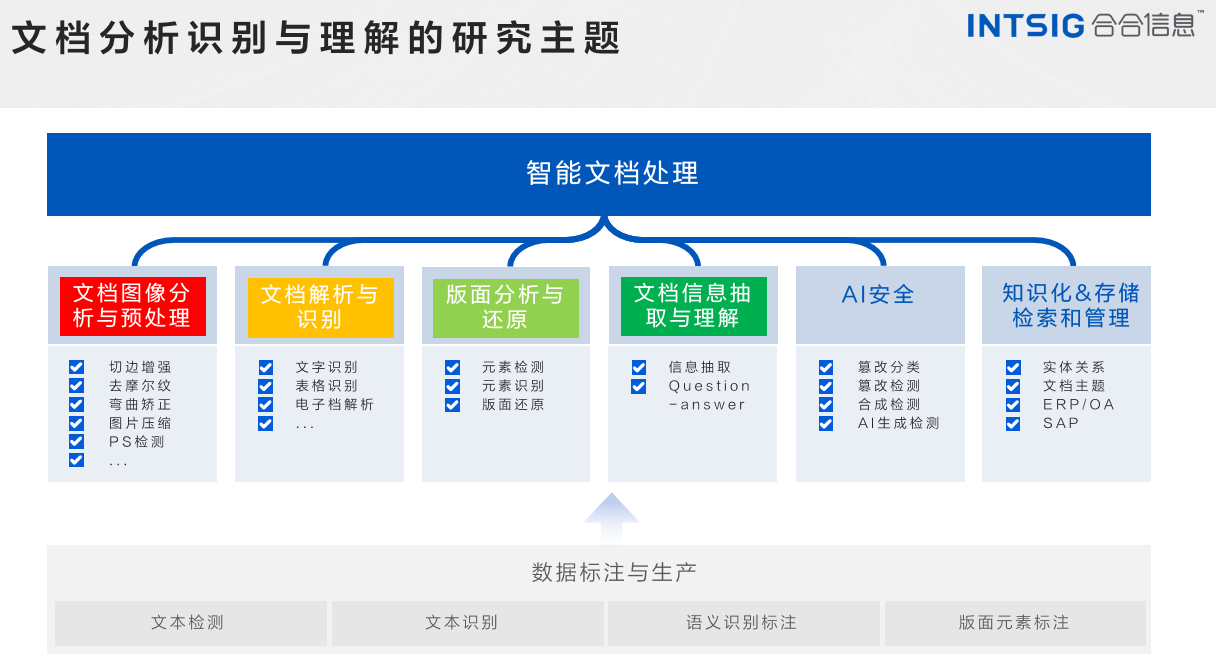
1.像素级OCR统一模型
在文档图像预处理统一模型方面,下面介绍2个合合信息与华南理工大学联合实验室的研究成果。
第一个研究成果是UPOCR,一种文档图像像素级多任务处理的统一模型。模型如图所示,UPOCR是一个通用的OCR模型,引入可学习的Prompt来指导基于ViT的编码器-解码器架构,统一了不同像素级OCR任务的范式、架构和训练策略。 UPOCR的通用能力在文本去除、文本分割和篡改文本检测任务上得到了广泛验证,显著优于现有的专门模型。
2.OCR大一统模型
- 将文档图像识别分析的各种任务定义为序列预测的形式
文本,段落,版面分析,表格,公式等等 - 通过不同的prompt引导模型完成不同的OCR任务
- 支持篇章级的文档图像识别分析,输出Markdown/HTML/Text等标准格式
- 将文档理解相关的工作交给LLM去做
一个复杂的系统模型应该需要做到:
在输入层,模型可以接收任何类型的文本文件作为输入,包括Word文档、PDF文档等。这一层的主要任务是对原始文本数据进行预处理,为后续的处理阶段准备数据。
处理层是模型的核心部分,它将对输入的文本数据进行一系列的分析和操作,如分词、语法分析、语义分析以及拼写检查等。这些处理步骤能帮助模型更好地理解和处理文本数据。
在输出层,模型将对处理后的结果进行可视化展示,可以是以图表、图形、文字等形式。这一层的主要任务是将复杂的数据处理结果以易于理解的方式呈现给用户。
尽管这个模型已经实现了高效的数据处理,但它仍有进一步发展和优化的空间。例如,可以探索如何更准确地识别和处理各种类型的文本数据,如何改进语法分析和语义理解的技术以提升模型的性能,以及如何设计和实现更有效的数据可视化方法以帮助用户更好地理解和利用模型输出的结果。这些方向的研究和发展将推动文本数据处理技术的进步,对许多领域都将产生深远的影响。
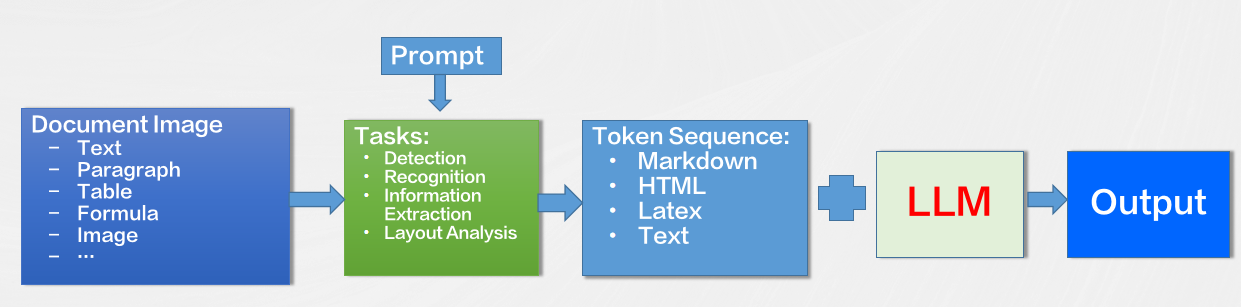
合合信息基于SPTS的OCR大一统模型(SPTS v3)
SPTS 是一种创新的端到端文本检测和识别方法,它颠覆了传统的文本检测和识别流程。传统的方法通常将文本检测和识别看作两个独立的任务,导致处理流程复杂且冗余。而SPTS将这两个任务融为一体,将文本检测和识别定义为图片到序列的预测任务,极大地简化了处理流程。另外,SPTS采用单点标注技术指示文本位置,这样就可以极大地降低标注成本。同时,它无需RoI采样和复杂的后处理操作,真正将检测和识别融为一体。
将多种OCR任务定义为序列预测的形式,通过不同的prompt引导模型完成不同的OCR任务,模型沿用SPTS的CNN+TransformerEncoder+Transformer Decoder的图片到序列的结构。

SPTS v3目前主要关注以下任务:端到端检测识别、表格结构识别、手写数学公式识别。
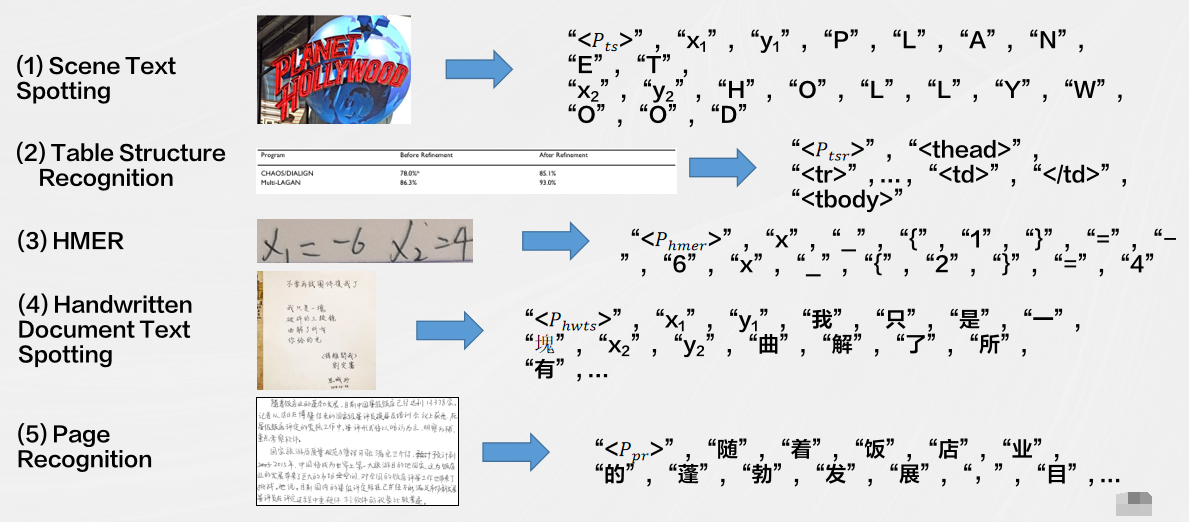
实验结果表明,SPTSv3 在各个OCR任务上都取得了出色的性能,显示了其在文档图像处理中的潜力。这为文档图像的多任务处理提供了一种高效的解决方案,有望应用于广泛的应用领域,包括自动化文档处理、文档搜索和内容提取等。
3.文档识别分析+LLM应用
检索增强生成(RAG)和文档问答是LLM在文档领域最常见和最广泛的应用之一
。
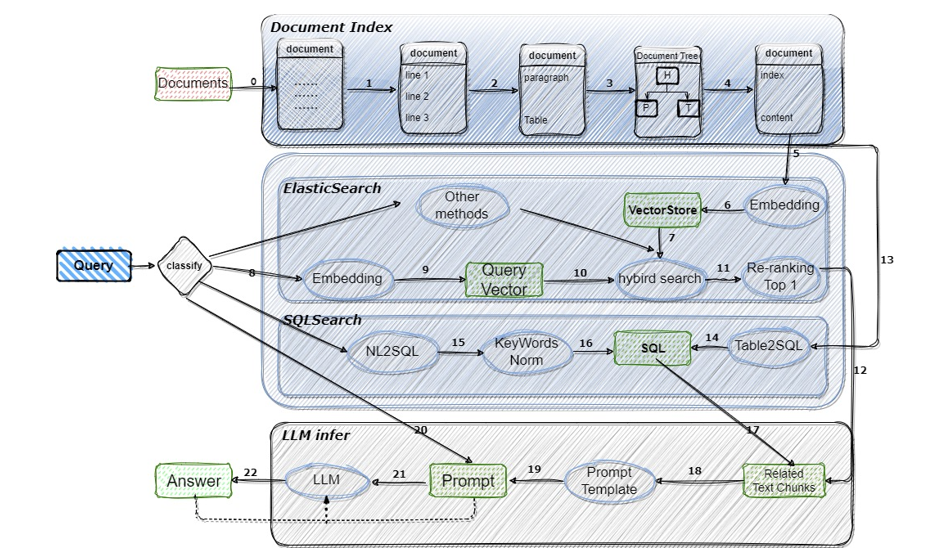
合合信息提出文档识别分析+LLM应用解决方案
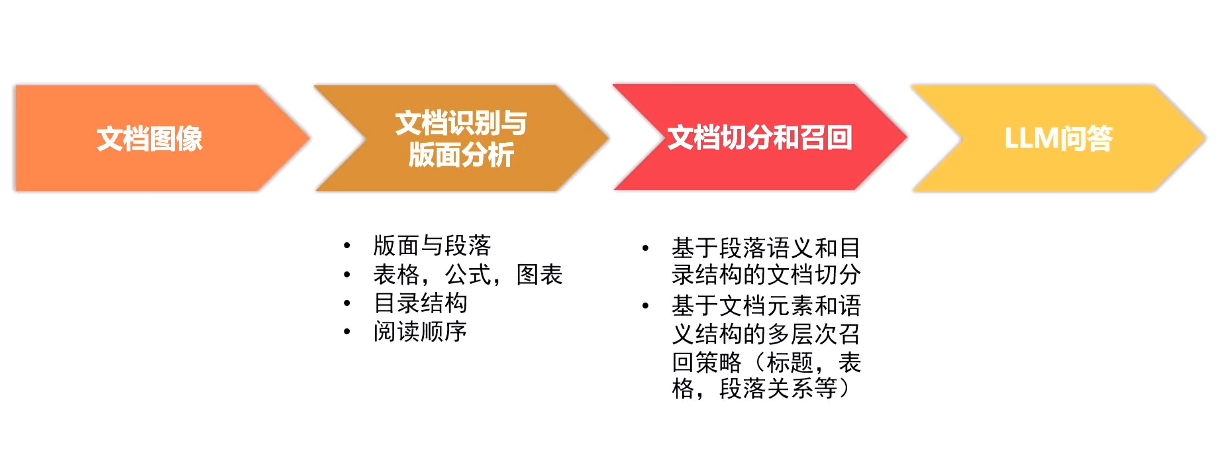
合合信息文档图像识别与分析产品
基于深度学习的方法,合合信息将文档图像切分为文本、图形、公式、表格、印章等不同类型的内容区域,并分析区域之间的逻辑关系,让机器更精准地确定文档中的文字位置、字体、大小和排版方式,可以更好地理解文档的结构和内容,并提取出有用的信息。
此外,合合信息表格结构解析方法在逻辑版面分析中利用自上而下的方法以及端到端图像到标记的方法等,保证区域内容的完整性的同时,显著提升检测准确率。
版面分析是文档图像还原的核心,通过解决版面分析的痛点,合合信息将图像文档以数字化的手段更精准地转化为文档数据,应用于多种使用场景、提升工作效率。
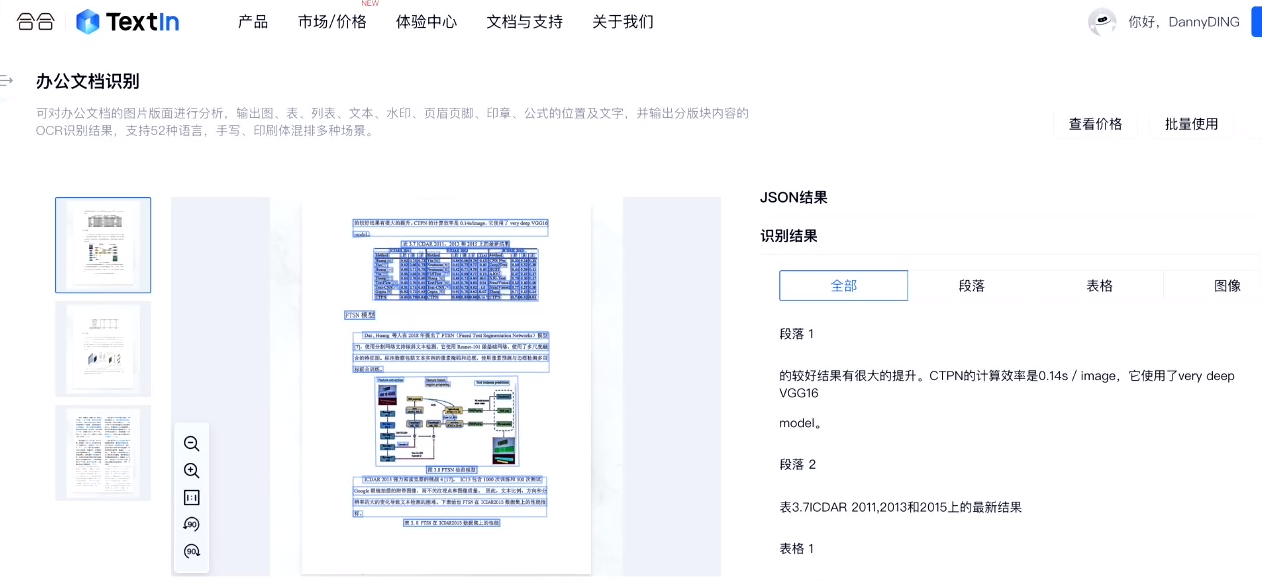
四、总结
1.机遇与挑战
- GPT4-V 为代表的多模态大模型技术极大的推进了文档识别与分析领域的技术进展,也给传统的IDP技术带来了挑战。
2.问题仍未消灭
- 大模型并没有完全解决IDP领域面临的问题,很多问题值得我们研究。
3.结合提升能力
- 如何结合大模型的能力,更好的解决IDP的问题,值得我们做更多的思考和探索。
4.合合信息聚焦文档图像领域,大有可为
- 合合信息的研究成果具有重要意义,同时这些成果和问题的探索也将为文档图像领域的发展提供新的思路和方向。
作为行业领先的人工智能及大数据科技企业,合合信息深耕智能文字识别、图像处理、自然语言处理等领域,其研发的智能图像处理技术等已落地并服务与各行业领域。未来,合合信息还将继续在文档图像处理方向发力,让新技术实现多场景应用。
文末粉丝福利
抽10人,每人50元京东卡:填问卷才可以抽哦→ 点此参与,12号开奖,快来参与吧。

![[C语言]程序设计(四)](https://img-blog.csdnimg.cn/direct/25f7de481da54bc6a073cbbedf5c9ffa.png)