1, 官方下载网址
注意,本文并不使用nv预编译的包来安装,仅供参考:
NVIDIA Collective Communications Library (NCCL) | NVIDIA Developer
2,github网址
这里是nv开源的nccl源代码,功能完整,不需要有任何疑虑:
GitHub - NVIDIA/nccl: Optimized primitives for collective multi-GPU communication
3,文档网址
这里是官方教程,本文示例是根据其中的example改写的:
Using NCCL — NCCL 2.19.3 documentation
4,源码下载与安装
4.1,下载
git clone --recursive https://github.com/NVIDIA/nccl.git4.2,编译
cd nccl
make -j src.build
或者为了节省编译时间和硬盘空间,可以指定gpu的架构,以sm_70为例:
make -j src.build NVCC_GENCODE="-gencode=arch=compute_70,code=sm_70"效果图:

4.3,打包
安装打包deb的工具:
sudo apt install build-essential devscripts debhelper fakeroot打包:
make pkg.debian.build
ls build/pkg/deb/ ![]()
4.4,安装
其中,deb包的文件名中包含了cuda版本号,以自己生成的安装包的名字为准:
sudo dpkg -i build/pkg/deb/libnccl2_2.19.4-1+cuda12.1_amd64.deb
sudo dpkg -i build/pkg/deb/libnccl-dev_2.19.4-1+cuda12.1_amd64.deb5,示例
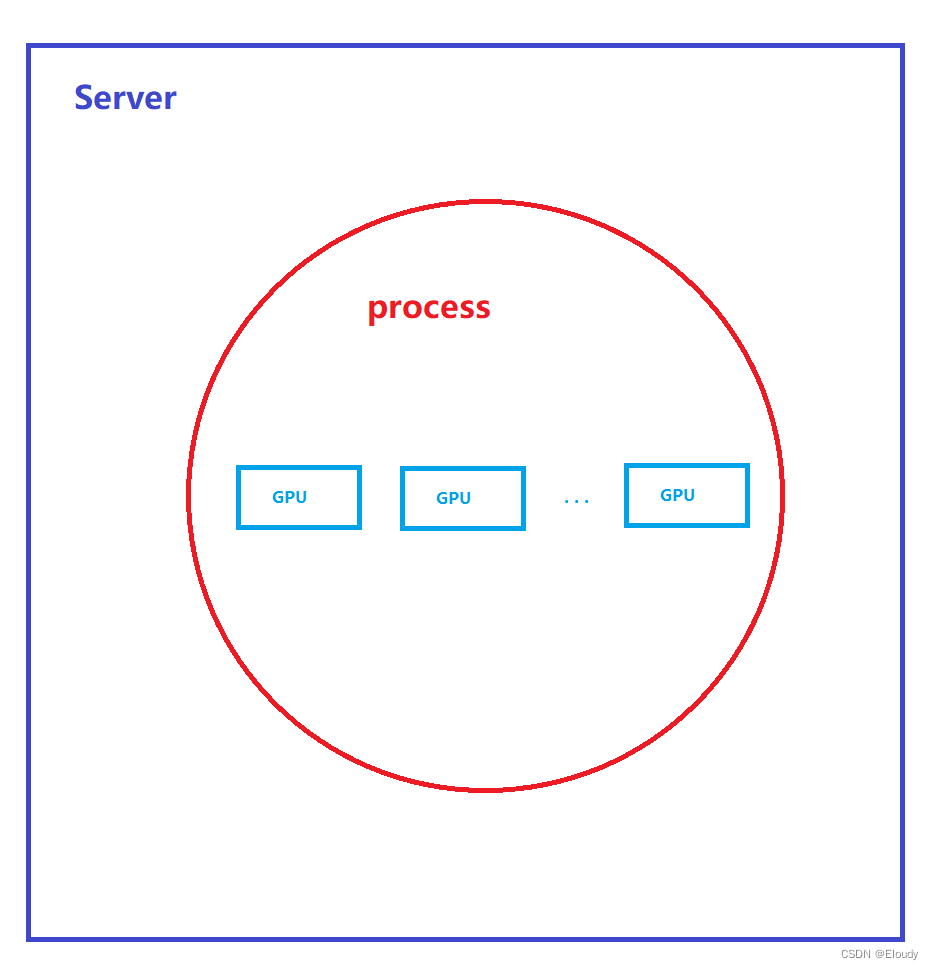
这里的示例是单机单线程多卡的示例,本文使用了双gpu显卡为例,即,在一个进程中迭代操作两个gpu 显卡,实现 allreduce操作, 四个 float vector, S0,S1,R0,R1,数学效果如下:
R0 = S0 + S1;R[0] = S0[0] + S1[0];
R1 = S0 + S1;R[0] = S0[0] + S1[0];
对应代码,其中 :
sendbuff[0] 是gpu-0 显存里边的要给vector,
sendbuff[1] 是gpu-1 显存里边的要给vector,
实现的数学效果为
显存 recvbuff[0] = sendbuff[0] + sendbuff[1];
显存 recvbuff[1] = sendbuff[0] + sendbuff[1];
本示例结构:
5.1,源代码
#include <stdlib.h>
#include <stdio.h>
#include "cuda_runtime.h"
#include "nccl.h"
#include <time.h>
#include <sys/time.h>
#define CUDACHECK(cmd) do { \
cudaError_t err = cmd; \
if (err != cudaSuccess) { \
printf("Failed: Cuda error %s:%d '%s'\n", \
__FILE__,__LINE__,cudaGetErrorString(err)); \
exit(EXIT_FAILURE); \
} \
} while(0)
#define NCCLCHECK(cmd) do { \
ncclResult_t res = cmd; \
if (res != ncclSuccess) { \
printf("Failed, NCCL error %s:%d '%s'\n", \
__FILE__,__LINE__,ncclGetErrorString(res)); \
exit(EXIT_FAILURE); \
} \
} while(0)
void get_seed(long long &seed)
{
struct timeval tv;
gettimeofday(&tv, NULL);
seed = (long long)tv.tv_sec * 1000*1000 + tv.tv_usec;//only second and usecond;
printf("useconds:%lld\n", seed);
}
void init_vector(float* A, int n)
{
long long seed = 0;
get_seed(seed);
srand(seed);
for(int i=0; i<n; i++)
{
A[i] = (rand()%100)/100.0f;
}
}
void print_vector(float* A, float size)
{
for(int i=0; i<size; i++)
printf("%.2f ", A[i]);
printf("\n");
}
void vector_add_vector(float* sum, float* A, int n)
{
for(int i=0; i<n; i++)
{
sum[i] += A[i];
}
}
int main(int argc, char* argv[])
{
ncclComm_t comms[4];
printf("ncclComm_t is a pointer type, sizeof(ncclComm_t)=%lu\n", sizeof(ncclComm_t));
//managing 4 devices
//int nDev = 4;
int nDev = 2;
//int size = 32*1024*1024;
int size = 16*16;
int devs[4] = { 0, 1, 2, 3 };
float** sendbuff_host = (float**)malloc(nDev * sizeof(float*));
float** recvbuff_host = (float**)malloc(nDev * sizeof(float*));
for(int dev=0; dev<nDev; dev++)
{
sendbuff_host[dev] = (float*)malloc(size*sizeof(float));
recvbuff_host[dev] = (float*)malloc(size*sizeof(float));
init_vector(sendbuff_host[dev], size);
init_vector(recvbuff_host[dev], size);
}
//sigma(sendbuff_host[i]); i = 0, 1, ..., nDev-1
float* result = (float*)malloc(size*sizeof(float));
memset(result, 0, size*sizeof(float));
for(int dev=0; dev<nDev; dev++)
{
vector_add_vector(result, sendbuff_host[dev], size);
printf("sendbuff_host[%d]=\n", dev);
print_vector(sendbuff_host[dev], size);
}
printf("result=\n");
print_vector(result, size);
//allocating and initializing device buffers
float** sendbuff = (float**)malloc(nDev * sizeof(float*));
float** recvbuff = (float**)malloc(nDev * sizeof(float*));
cudaStream_t* s = (cudaStream_t*)malloc(sizeof(cudaStream_t)*nDev);
for (int i = 0; i < nDev; ++i) {
CUDACHECK(cudaSetDevice(i));
CUDACHECK(cudaMalloc(sendbuff + i, size * sizeof(float)));
CUDACHECK(cudaMalloc(recvbuff + i, size * sizeof(float)));
CUDACHECK(cudaMemcpy(sendbuff[i], sendbuff_host[i], size*sizeof(float), cudaMemcpyHostToDevice));
CUDACHECK(cudaMemcpy(recvbuff[i], recvbuff_host[i], size*sizeof(float), cudaMemcpyHostToDevice));
CUDACHECK(cudaStreamCreate(s+i));
}
//initializing NCCL
NCCLCHECK(ncclCommInitAll(comms, nDev, devs));
//calling NCCL communication API. Group API is required when using
//multiple devices per thread
NCCLCHECK(ncclGroupStart());
printf("blocked ncclAllReduce will be calleded\n");
fflush(stdout);
for (int i = 0; i < nDev; ++i)
NCCLCHECK(ncclAllReduce((const void*)sendbuff[i], (void*)recvbuff[i], size, ncclFloat, ncclSum, comms[i], s[i]));
printf("blocked ncclAllReduce is calleded nDev =%d\n", nDev);
fflush(stdout);
NCCLCHECK(ncclGroupEnd());
//synchronizing on CUDA streams to wait for completion of NCCL operation
for (int i = 0; i < nDev; ++i) {
CUDACHECK(cudaSetDevice(i));
CUDACHECK(cudaStreamSynchronize(s[i]));
}
for (int i = 0; i < nDev; ++i) {
CUDACHECK(cudaSetDevice(i));
CUDACHECK(cudaMemcpy(recvbuff_host[i], recvbuff[i], size*sizeof(float), cudaMemcpyDeviceToHost));
}
for (int i = 0; i < nDev; ++i) {
CUDACHECK(cudaSetDevice(i));
CUDACHECK(cudaStreamSynchronize(s[i]));
}
for(int i=0; i<nDev; i++) {
printf("recvbuff_dev2host[%d]=\n", i);
print_vector(recvbuff_host[i], size);
}
//free device buffers
for (int i = 0; i < nDev; ++i) {
CUDACHECK(cudaSetDevice(i));
CUDACHECK(cudaFree(sendbuff[i]));
CUDACHECK(cudaFree(recvbuff[i]));
}
//finalizing NCCL
for(int i = 0; i < nDev; ++i)
ncclCommDestroy(comms[i]);
printf("Success \n");
return 0;
}
5.2,编译
参考Makefile中的如下一条:
single_thread_allreduce: single_thread_allreduce.cpp
g++ -g $< -o $@ $(LD_FLAGS)
Makefile:
LD_FLAGS := -lnccl -L/usr/local/cuda/lib64 -lcudart -I/usr/local/cuda/include
MPI_FLAGS := -I /usr/lib/x86_64-linux-gnu/openmpi/include -L /usr/lib/x86_64-linux-gnu/openmpi/lib -lmpi -lmpi_cxx
EXE := single_thread_allreduce oneServer_multiDevice_multiThread mpi_test
all: $(EXE)
single_thread_allreduce: single_thread_allreduce.cpp
g++ -g $< -o $@ $(LD_FLAGS)
oneServer_multiDevice_multiThread: oneServer_multiDevice_multiThread.cpp
g++ -g $< -o $@ $(LD_FLAGS) $(MPI_FLAGS)
mpi_test: mpi_test.cpp
g++ -g $< -o $@ $(LD_FLAGS) $(MPI_FLAGS)
.PHONY: clean
clean:
-rm $(EXE)5.3,运行
这里没有使用 mpi,故可以直接编译运行
make && ./single_thread_allreduce5.4,效果
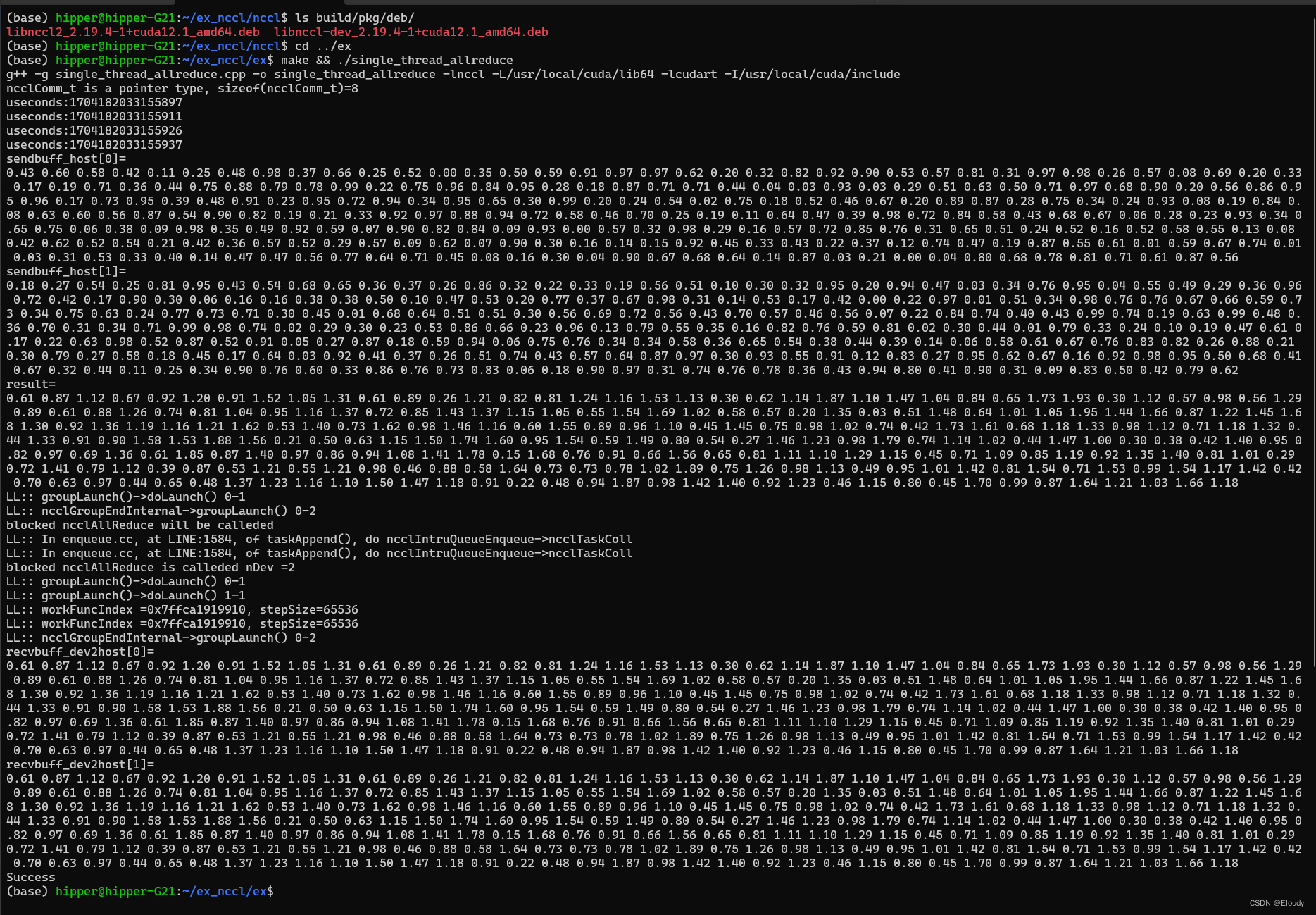
稍微注释一下上图:
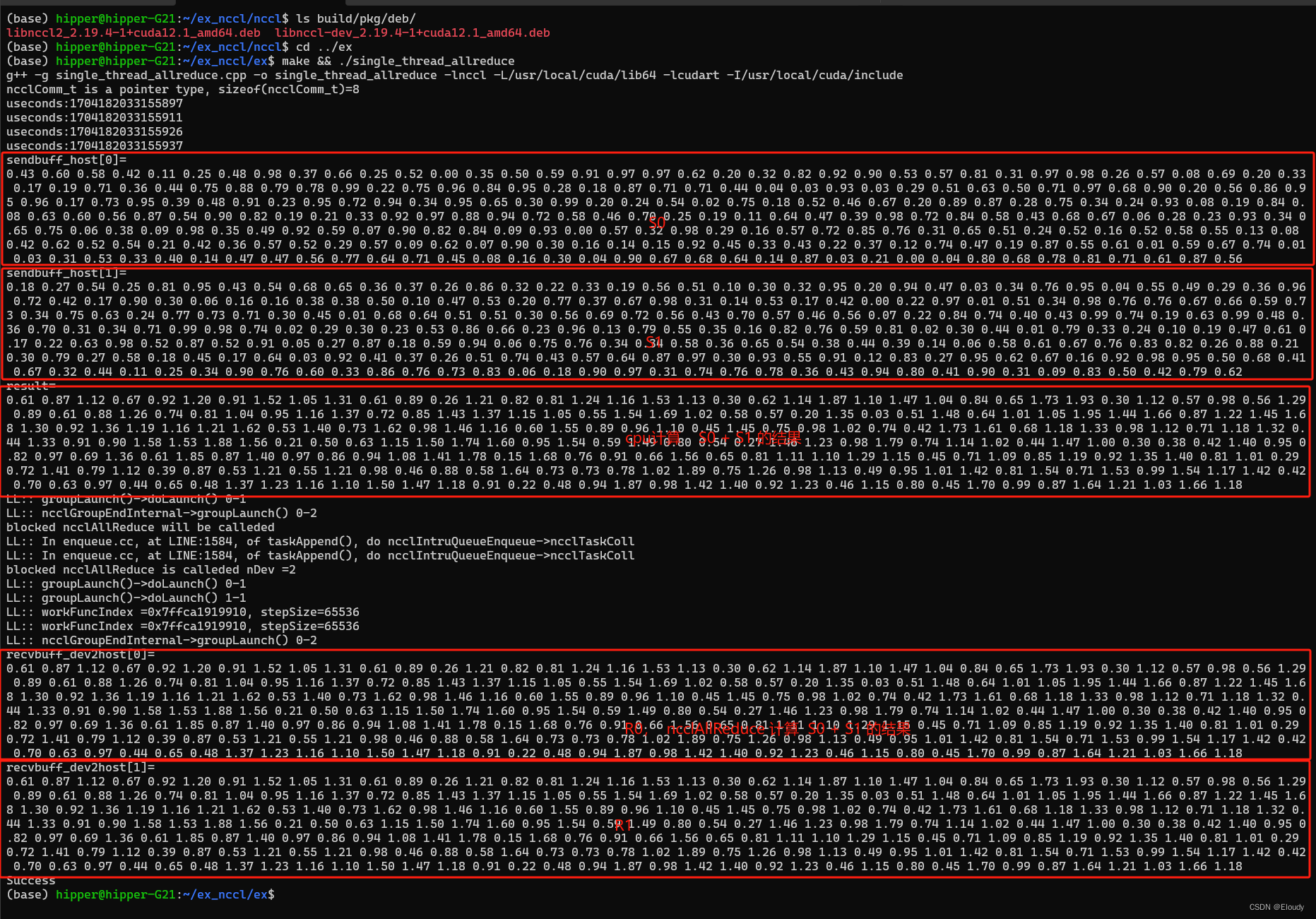
实现了数学目标:
R0 = S0 + S1;R[0] = S0[0] + S1[0];
R1 = S0 + S1;R[0] = S0[0] + S1[0];
6,另一个示例
另一效果类似,但是是多进程的示例,其中的多进程部分是使用mpi实现的,太长了不容易翻,见下一篇