文章目录
- 一、均匀分布采样
- 二、直接采样
- 例
- 三、拒绝接受采样
- 实例
- 四、重要性采样
- 参考资料
蒙特卡洛方法(Monte Carlo Simulation)是一种近似推断的方法,通过采样大量粒子的方法来求解期望、均值、面积、积分等问题。
蒙特卡洛对某一种分布的采样方法有直接采样、接受拒绝采样与重要性采样三种:
- 直接采样最简单,但是需要已知累积分布的形式,并且好求逆函数,得到p(x)分布的样本
- 接受拒绝采样是给出一个提议分布,对满足原分布的粒子接受,得到服从p(x)分布的样本
- 重要性采样则是给予每个粒子不同的权重,计算f(x)在概率分布p(x)下的均值
一、均匀分布采样
均匀分布Uniform(0,1)的样本是相对容易生成的。 通过线性同余发生器(LCG)可以生成伪随机数,我们用确定性算法生成[0,1]之间的伪随机数序列后, 这些序列的各种统计指标和均匀分布Uniform(0,1)的理论计算结果非常接近。这样的伪随机序列就有比较好的统计性质,可以被当成真实的随机数使用。
线性同余随机数生成器如下:
x
n
+
1
=
(
a
x
n
+
c
)
m
o
d
m
x_{n+1}=(ax_n+c)\mod m
xn+1=(axn+c)modm式中a,c,m是数学推导出的合适的常数。这种算法产生的下一个随机数完全依赖当前的随机数,当随机数序列足够大的时候,随机数会出现重复子序列的情况。
二、直接采样
直接采样的方法是根据概率分布进行采样。对一个已知概率密度函数(比如均匀分布)与累积概率密度函数的概率分布,我们可以直接从累积分布函数(cdf)进行采样。
原理:

例
设x服从概率密度函数为 F ( x ) = 1 − e − x F(x)=1-e^{-x} F(x)=1−e−x的分布,则可以通过逆变换的方法对F(x)直接采样,产生服从F(X)分布的样本X.
令 y = 1 − e − x → e − x = 1 − y 两边求对数可得 : x = − l n ( 1 − y ) 令\quad y=1-e^{-x} \rightarrow e^{-x}=1-y \\ 两边求对数可得:x=-ln(1-y) 令y=1−e−x→e−x=1−y两边求对数可得:x=−ln(1−y)
则 F − 1 ( x ) = − l n ( 1 − x ) F^{-1}(x)=-ln(1-x) F−1(x)=−ln(1−x)令 x i x_i xi为均匀分布样本,则 X i = − l n ( 1 − x i ) X_i=-ln(1-x_i) Xi=−ln(1−xi)为服从累积密度函数为F(x)分布的样本
三、拒绝接受采样
对于累积分布函数比较复杂,不好求反函数的分布,我们可以采用接受-拒绝采样。如下图所示,p(z)是我们希望采样的分布,q(z)是我们提议的分布(proposal distribution),q(z)分布比较简单,令kq(z)>p(z),我们首先在kq(z)中按照直接采样的方法采样粒子,接下来判断这个粒子落在途中什么区域,对于落在蓝线以外的粒子予以拒绝,落在蓝线下的粒子接受,最终得到符合p(z)的N个粒子。
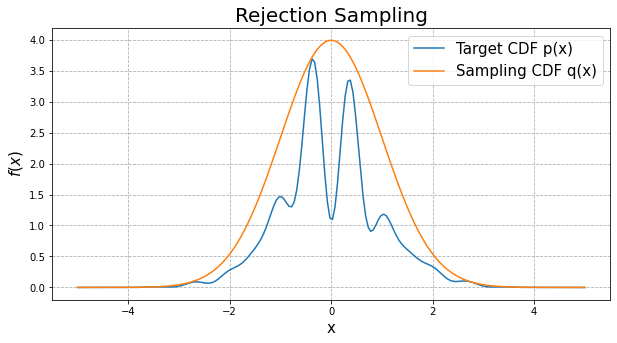
拒绝接受采样的基本步骤:
- 生成服从q(x)的样本 → x i \rightarrow x_i →xi
- 生成服从均匀分布U(0,1)的样本—— u i u_i ui
- 当 q ( x i ) ⋅ u i < p ( x i ) q(x_i)\cdot u_i<p(x_i) q(xi)⋅ui<p(xi),也就是二维点落在蓝线以下,此时接受 X k = x i X_k=x_i Xk=xi
- 最终得到的 X k X_k Xk为服从p(x)的样本
实例
定义拒绝抽样函数:
def Reject_Sampling(p,q_x):
"""对p(x)进行拒绝采样
Args:
p (_type_): 目标CDF函数
q_x (_type_): 选取的简单概率密度函数
Returns:
_type_: 采样样本
"""
size = 1e+05 #初始采样点
k=10
sample=[]
for _ in range(int(size)): #不建议用for循环,速度慢,这样写比较好理解
xi=np.random.normal(0,1)
qi=k*q_x.pdf(xi) #乘上系数
ui=np.random.uniform(0,1)
pi=p(xi)
#判断
if qi*ui<pi:
sample.append(xi)
return sample
实验并作图:
import numpy as np
import matplotlib.pyplot as plt
import scipy.stats as stats
def f(x):
fx=np.exp(-(x**2)/2)*(np.sin(6+x)**2+3*(np.cos(x)**2)*(np.sin(4*x)**2)+1)
return fx
q_x = stats.norm(0, 1)
RS=Reject_Sampling(f,q_x) #抽样数据集
fig,ax=plt.subplots(figsize=(10,5))
ax.hist(RS,bins=2000,density = True, stacked=True) #画出抽样分布
ax.set_xlabel('x', fontsize=15)
ax.set_ylabel("f(x)", fontsize=15)
ax.set_title("Rejection Sampling", fontsize=20)
四、重要性采样
(1) 目的
重要性采样的目的:求一个f(x)在p(x)分布下的期望,即 E ( f ( x ) ) = ∫ f ( x ) p ( x ) d x E(f(x))=\int f(x)p(x)dx E(f(x))=∫f(x)p(x)dx,当p(x)很复杂时,不解析,积分不好求时,可以通过重要性采样来计算。当 f ( x ) = x f(x)=x f(x)=x,则可以算E(x)在p(x)分布下的期望.
(2) 原理
首先, 当我们想要求一个函数 f ( x ) f(x) f(x) 在区间 [ a , b ] [a, b] [a,b] 上的积分 ∫ a b f ( x ) d x \int_{a}^{b} f(x) d x ∫abf(x)dx 时有可能会面临一个问题, 那就是积分曲线难以解析, 无法直接求积分。这时候我们可以采用一种估计的方式, 即在区 间 [ a , b ] [a, b] [a,b] 上进行采样: { x 1 , x 2 … , x n } \left\{x_{1}, x_{2} \ldots, x_{n}\right\} {x1,x2…,xn}, 值为 { f ( x 1 ) , f ( x 2 ) , … , f ( x n ) } \left\{f\left(x_{1}\right), f\left(x_{2}\right), \ldots, f\left(x_{n}\right)\right\} {f(x1),f(x2),…,f(xn)} .
如果采样是均匀的, 即如下图所示:
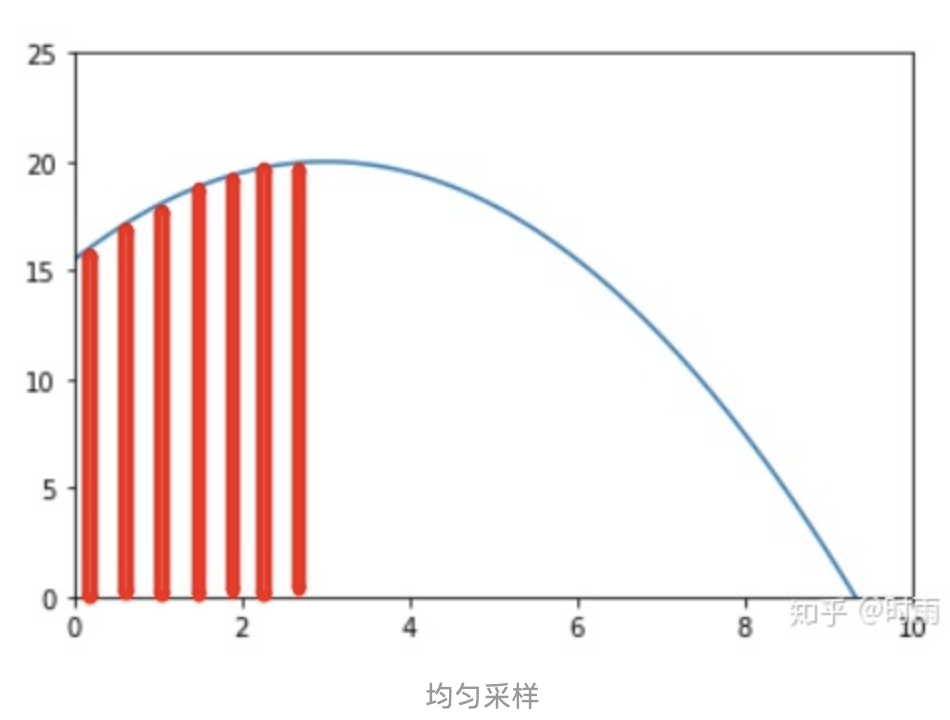
那么显然可以得到这样的估计: ∫ a b f ( x ) d x = b − a N ∑ i = 1 N f ( x i ) \int_{a}^{b} f(x) d x=\frac{b-a}{N} \sum_{i=1}^{N} f\left(x_{i}\right) ∫abf(x)dx=Nb−ai=1∑Nf(xi)在这里 b − a N \frac{b-a}{N} Nb−a 可以看作是上面小长方形的底部的 “宽”, 而 f ( x i ) f\left(x_{i}\right) f(xi) 则是坚直的 “长”。
上述的估计方法随着取样数的增长而越发精确,那么有什么方法能够在一定的抽样数量基础上来增加准确度,减少方差呢?比如x样本数量取10000,那么显然在f(x)比较大的地方,有更多的 x i x_i xi,近似的积分更精确,如下图所示,在圆圈部分 x i x_i xi样本应该更多,所以 x i x_i xi就不用均匀分布产生。
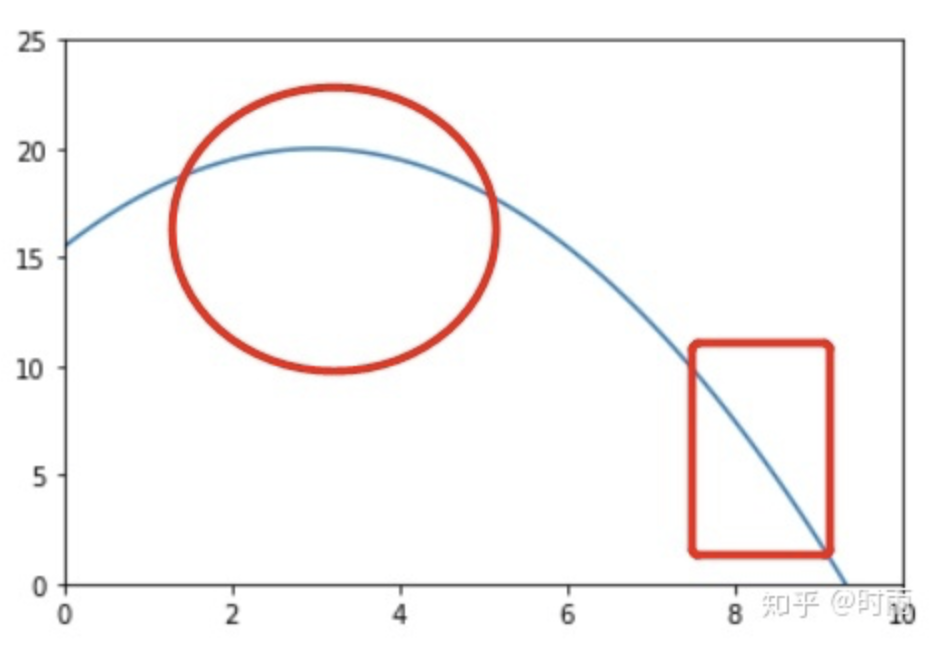
并且原函数 f ( x ) f(x) f(x) 也许本身就是定义在一个分布之上的, 我们定义这个分布为 π ( x ) \pi(x) π(x), 我们无法直接从 π ( x ) \pi(x) π(x) 上进行采样, 所以另辟蹊径重新找到一个更加简明的分布 p ( x ) p(x) p(x), 从它进行取样, 希望间接地求出 f ( x ) f(x) f(x) 在分布 π ( x ) \pi(x) π(x) 下的期望。
(2.1) π ( x ) 归一化 \pi(x)归一化 π(x)归一化
搞清楚了这一点我们可以继续分析了。首先我们知道函数
f
(
x
)
f(x)
f(x) 在概率分布
π
(
x
)
\pi(x)
π(x) 下的期望为:
E
[
f
]
=
∫
x
π
(
x
)
f
(
x
)
d
x
E[f]=\int_{x} \pi(x) f(x) d x
E[f]=∫xπ(x)f(x)dx
但是这个期望的值我们无法直接得到, 因此我们需要借助
p
(
x
)
p(x)
p(x) 来进行采样,
p
(
x
)
p(x)
p(x) 可以选取简单的分布,比如设p(x)为均匀分布,当我们在
p
(
x
)
p(x)
p(x) 上采样
{
x
1
,
x
2
,
…
,
x
n
}
\left\{x_{1}, x_{2}, \ldots, x_{n}\right\}
{x1,x2,…,xn} (即
x
i
x_i
xi服从p(x)分布)后可以估计
f
f
f 在分布
p
(
x
)
p(x)
p(x) 下的期望为:
E
[
f
]
=
∫
x
p
(
x
)
f
(
x
)
d
x
≈
1
N
∑
i
=
1
N
f
(
x
i
)
。
E[f]=\int_{x} p(x) f(x) d x \approx \frac{1}{N} \sum_{i=1}^{N} f\left(x_{i}\right) 。
E[f]=∫xp(x)f(x)dx≈N1i=1∑Nf(xi)。接着我们可以对式子进行改写, 即:
π
(
x
)
f
(
x
)
=
p
(
x
)
π
(
x
)
p
(
x
)
f
(
x
)
\pi(x) f(x)=p(x) \frac{\pi(x)}{p(x)} f(x)
π(x)f(x)=p(x)p(x)π(x)f(x), 所以我们可以得到:
E
[
f
]
=
∫
x
p
(
x
)
π
(
x
)
p
(
x
)
f
(
x
)
d
x
E[f]=\int_{x} p(x) \frac{\pi(x)}{p(x)} f(x) d x
E[f]=∫xp(x)p(x)π(x)f(x)dx这个式子我们可以看作是函数
π
(
x
)
p
(
x
)
f
(
x
)
\frac{\pi(x)}{p(x)} f(x)
p(x)π(x)f(x) 定义在分布
p
(
x
)
p(x)
p(x) 上的期望, 当我们在
p
(
x
)
p(x)
p(x) 上采样
{
x
1
,
x
2
,
…
,
x
n
}
\left\{x_{1}, x_{2}, \ldots, x_{n}\right\}
{x1,x2,…,xn} (服从p(x)分布),可以估计
f
f
f 的期望:
E [ f ] = 1 N ∑ i = 1 N π ( x i ) p ( x i ) f ( x i ) = 1 N ∑ i = 1 N w i f ( x i ) \begin{aligned} E[f]&=\frac{1}{N} \sum_{i=1}^{N} \frac{\pi\left(x_{i}\right)}{p\left(x_{i}\right)} f\left(x_{i}\right)\\ &=\frac{1}{N} \sum_{i=1}^{N} w_i f\left(x_{i}\right) \end{aligned} E[f]=N1i=1∑Np(xi)π(xi)f(xi)=N1i=1∑Nwif(xi)在这里 w i = π ( x i ) p ( x i ) w_i=\frac{\pi\left(x_{i}\right)}{p\left(x_{i}\right)} wi=p(xi)π(xi)就是重要性权重。
(2.2)若 π ( x ) ( 即 p ( x ) 没有归一化 \pi(x)(即p(x)没有归一化 π(x)(即p(x)没有归一化
E
(
f
(
X
)
)
=
∫
f
(
x
)
p
(
x
)
∫
p
(
x
)
d
x
d
x
=
∫
f
(
x
)
p
(
x
)
d
x
∫
p
(
x
)
d
x
=
∫
f
(
x
)
p
(
x
)
q
(
x
)
q
(
x
)
d
x
∫
p
(
x
)
q
(
x
)
q
(
x
)
d
x
\begin{aligned} E(f(X))&=\int f(x) \frac{p(x)}{\int p(x) d x} d x\\ &=\frac{\int f(x) p(x) d x}{\int p(x) d x}\\ &=\frac{\int f(x) \frac{p(x)}{q(x)} q(x) d x}{\int \frac{p(x)}{q(x)} q(x) d x} \end{aligned}
E(f(X))=∫f(x)∫p(x)dxp(x)dx=∫p(x)dx∫f(x)p(x)dx=∫q(x)p(x)q(x)dx∫f(x)q(x)p(x)q(x)dx而分子分母可分别得到:
∫
f
(
x
)
p
(
x
)
q
(
x
)
q
(
x
)
d
x
≈
1
n
∑
i
=
1
n
W
i
f
(
x
i
)
∫
p
(
x
)
q
(
x
)
q
(
x
)
d
x
≈
1
n
∑
i
=
1
n
W
i
\begin{aligned} \int f(x) \frac{p(x)}{q(x)} q(x) d x &\approx \frac{1}{n} \sum_{i=1}^{n} W_{i} f\left(x_{i}\right) \\ \int \frac{p(x)}{q(x)} q(x) d x &\approx \frac{1}{n} \sum_{i=1}^{n} W_{i} \end{aligned}
∫f(x)q(x)p(x)q(x)dx∫q(x)p(x)q(x)dx≈n1i=1∑nWif(xi)≈n1i=1∑nWi则最终可得E(f(x)):
E
(
f
(
X
)
)
≈
∑
i
=
1
n
w
i
f
(
x
i
)
,
w
i
=
W
i
∑
i
=
1
n
W
i
\begin{aligned} E(f(X)) \approx \sum_{i=1}^{n} w_{i} f\left(x_{i}\right), w_{i}=\frac{W_{i}}{\sum_{i=1}^{n} W_{i}} \end{aligned}
E(f(X))≈i=1∑nwif(xi),wi=∑i=1nWiWi其中
W
i
=
p
(
x
i
)
q
(
x
i
)
W_i=\frac{p(x_i)}{q(x_i)}
Wi=q(xi)p(xi).
(3)实例
import numpy as np
import matplotlib.pyplot as plt
import scipy.stats as stats
def f(x): #概率密度函数
fx=np.exp(-(x**2)/2)*(np.sin(6+x)**2+3*(np.cos(x)**2)*(np.sin(4*x)**2)+1)
return fx
q_x = stats.norm(0, 1) #取q(x)为正太分布
# 从 q(x) 进行重要性采样
def Importance_Sampling(f):
"""对f(x)进行重要性采样
Args:
f (_type_): 传入f(x)函数
Returns:
_type_: 返回采样结果
"""
EX_list = []
W=0
for i in range(n):
x_i = np.random.normal(0, 1) #x为正太分布的采样样本
w_i=f(x_i) / (1*q_x.pdf(x_i)) #权重
value = x_i*w_i
W+=w_i
EX_list.append(value)
W=W/n
return EX_list/W #归一化,并返回采样结果
IS=Importance_Sampling(f)
IS_Mean=np.mean(IS)
print("E(X)=",IS_Mean)
参考资料
- 重要性采样
- 蒙特卡洛方法
- 一文看懂蒙特卡洛方法