一、前言
计数器是并发编程中非常常见的一个需求,例如统计网站的访问量、计算某个操作的执行次数等等。在高并发场景下,如何实现一个线程安全的计数器是一个比较有挑战性的问题。本文将介绍几种常用的计数器实现方式,包括AtomicLong、LongAdder和LongAccumulator,并深入讲解其中的CAS操作。
二、计数器
计数器是一种非常基础的数据结构,用于记录某个事件发生的次数。在并发编程中,由于多个线程可能同时对计数器进行修改,因此需要保证计数器的线程安全性。
三、AtomicLong
AtomicLong是Java中的一个原子类,主要作用是对长整形进行原子操作,保证并发情况下数据的安全性。它实现了一系列线程安全的方法,包括初始化为特定值和以原子方式设置当前值等。
AtomicLong的核心机制是通过CAS(Compare and Swap)操作来确保并发安全性。CAS是一种无锁算法,其核心思想是:如果内存中的值V符合预期值A,则将内存中值修改为B,否则不进行任何操作。整个过程是原子的,不会出现线程安全问题。在高并发环境下,当大量线程同时竞争更新同一个原子变量时,只有一个线程的CAS会成功,其他线程会不断尝试直到成功,这就可能造成大量线程竞争失败后,通过无限循环不断尝试自旋尝试CAS操作,白白浪费了CPU资源。
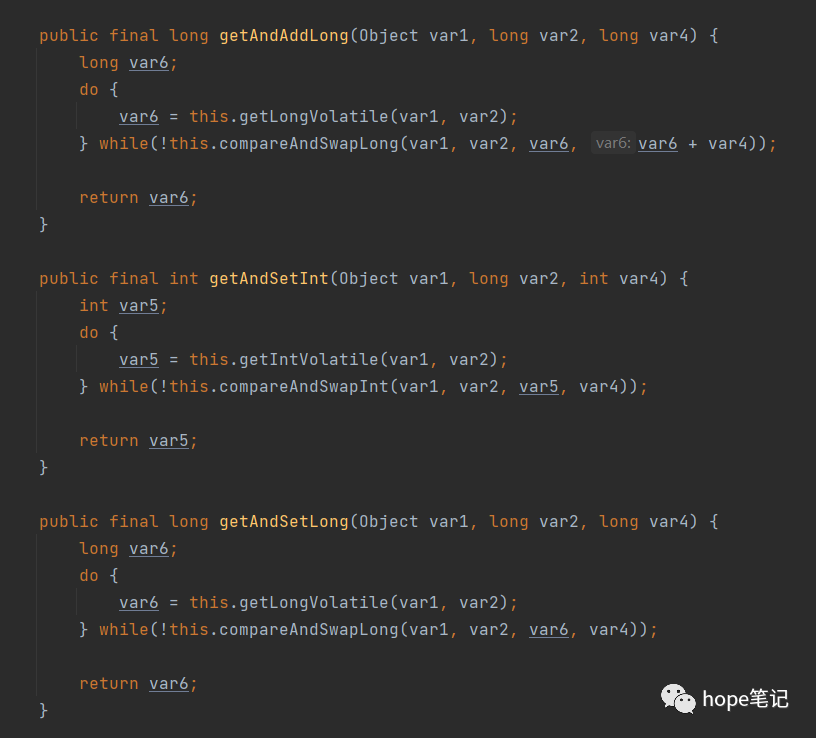
图里可以看出在高并发情况下,当有大量线程同时去更新一个变量,任意一个时间点只有一个线程能够成功,绝大部分的线程在尝试更新失败后,会通过自旋的方式再次进行尝试,这样严重占用了 CPU 的时间片,进而导致系统性能问题。
多线程并发下AtomicLong实现计数器demo:
import java.util.concurrent.atomic.AtomicLong;
public class AtomicLongCounter {
private AtomicLong counter = new AtomicLong(0);
public void increment() {
long oldValue, newValue;
do {
oldValue = counter.get();
newValue = oldValue + 1;
} while (!counter.compareAndSet(oldValue, newValue));
}
public long getCount() {
return counter.get();
}
public static void main(String[] args) throws InterruptedException {
AtomicLongCounter counter = new AtomicLongCounter();
int threadCount = 10;
Thread[] threads = new Thread[threadCount];
for (int i = 0; i < threadCount; i++) {
threads[i] = new Thread(() -> {
for (int j = 0; j < 1000; j++) {
counter.increment();
}
});
threads[i].start();
}
for (int i = 0; i < threadCount; i++) {
threads[i].join();
}
System.out.println("计数器的值:" + counter.getCount());
}
}四、LongAdder
LongAdder是Java 8新增的一个类,主要用于解决高并发下的计数问题。与AtomicLong不同,LongAdder内部采用了分段锁技术,将一个大的计数空间分成若干个小的空间进行累加操作。每个小空间都有一个独立的锁,当多个线程同时对不同的小空间进行累加操作时,它们可以并行执行,从而提高了并发性能。
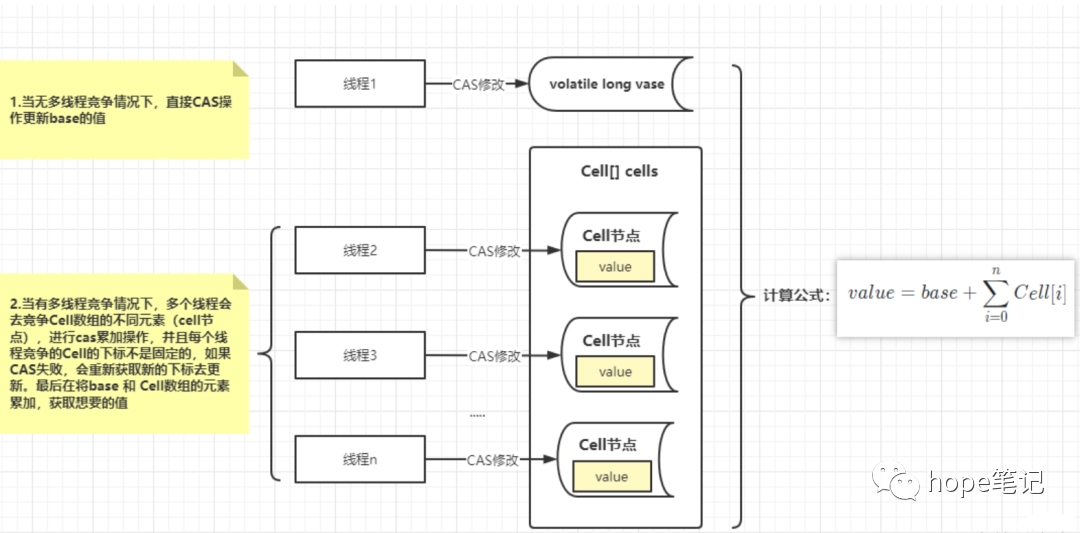
如图所示,LongAdder 设计思想上,采用分段的方式降低并发冲突的概率。通过维护一个基准值 base 和 Cell 数组。
多线程并发下LongAdder实现计数器demo:
import java.util.concurrent.atomic.LongAdder;
public class LongAdderCounter {
private final LongAdder longAdder = new LongAdder();
public void increment() {
longAdder.increment();
}
public long getCount() {
return longAdder.sum();
}
public static void main(String[] args) throws InterruptedException {
LongAdderCounter counter = new LongAdderCounter();
int threadCount = 10;
Thread[] threads = new Thread[threadCount];
for (int i = 0; i < threadCount; i++) {
threads[i] = new Thread(() -> {
for (int j = 0; j < 1000; j++) {
counter.increment();
}
});
threads[i].start();
}
for (int i = 0; i < threadCount; i++) {
threads[i].join();
}
System.out.println("计数器的值:" + counter.getCount());
}
}五、LongAccumulator
LongAccumulator是Java 8新增的一个类,用于实现自定义的累加操作。它提供了一种简单而灵活的方式来实现复杂的累加逻辑。LongAccumulator内部维护了一个累加结果和一个标识位,当调用accumulate方法时,会根据标识位的值来决定是否直接返回结果还是进入累加逻辑。这种方式可以有效地避免重复计算和线程竞争问题。
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.util.LongAccumulator;
public class LongAccumulatorCounter {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("LongAccumulatorCounter").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
LongAccumulator longAccumulator = sc.longAccumulator();
JavaRDD<Integer> rdd = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5), 2);
rdd.foreachPartition(partition -> {
for (int value : partition) {
longAccumulator.add(value);
}
});
System.out.println("累加器的值:" + longAccumulator.value());
sc.stop();
}
}六、CAS(Compare and Swap)
CAS 全称:compare and swap,比较并交换。CAS操作是上述三种计数器实现方式的核心机制之一。它通过比较内存中的值和预期值是否相等来判断是否需要进行更新操作。如果相等,则将内存中的值修改为新值;否则不做任何操作。整个过程是原子的,不会出现线程安全问题。但是需要注意的是,在高并发场景下,当多个线程同时竞争同一个原子变量时,可能会出现“ABA”问题。即当一个线程读取了内存中的值A之后,另一个线程将其修改为B再修改为A,此时第一个线程再次读取该变量时会发现它的值仍然是A而不是B。为了解决这个问题,可以使用版本号等方式来解决“ABA”问题,使用Java提供的AtomicStampedReference 类。
七、总结
阿里巴巴推荐使用 LongAdder, 原因主要有以下几点:
高并发性能:LongAdder 采用分段锁的策略,可以避免 AtomicLong 中的竞争问题,提高并发性能。在分布式系统中,高并发性能是非常重要的。
可扩展性:LongAdder 支持可扩展性,可以通过增加更多的段来提高性能。这对于需要处理大量请求的分布式系统来说是非常有利的。
代码简单易懂:虽然LongAdder 的代码相对复杂一些,但是相对于 AtomicLong 来说更容易理解和维护。这对于开发人员来说是非常重要的。
更好的适用场景:阿里巴巴推荐使用 LongAdder 主要是因为在分布式系统中需要一个高性能、高可用的计数器实现。而 LongAdder 正好符合这个需求。











![【前端】[vue3] vue-router使用](https://img-blog.csdnimg.cn/direct/b3211660f8d34d01b83ab4c29e441240.png)