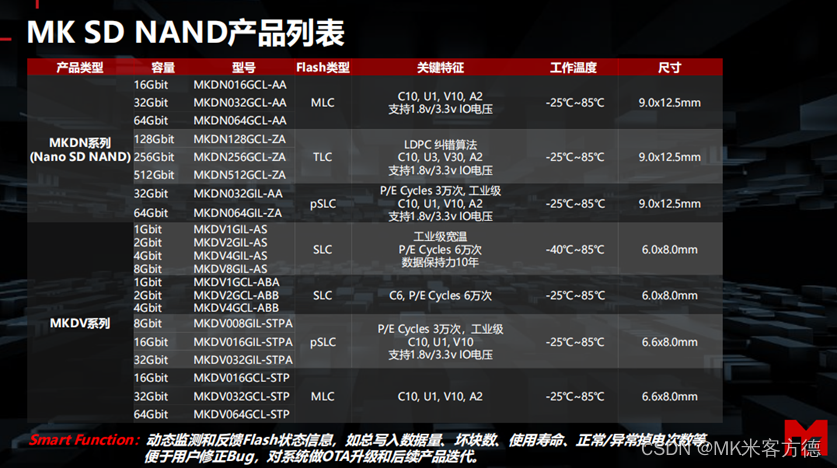
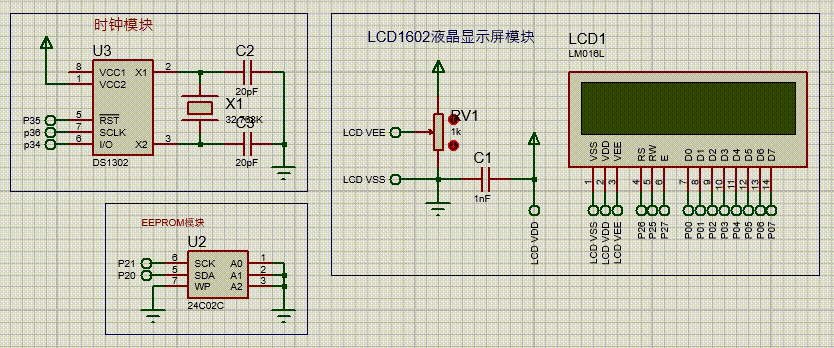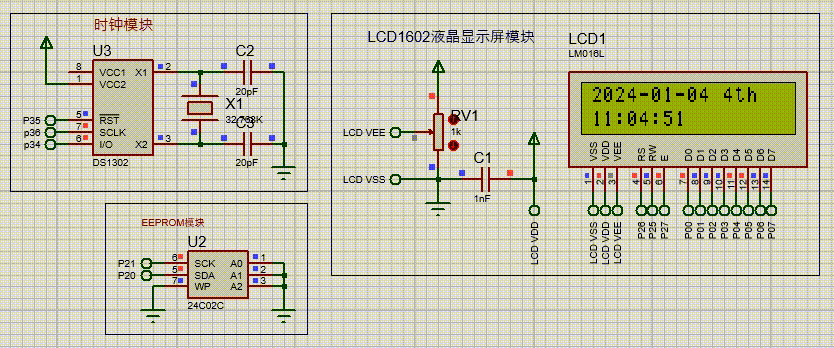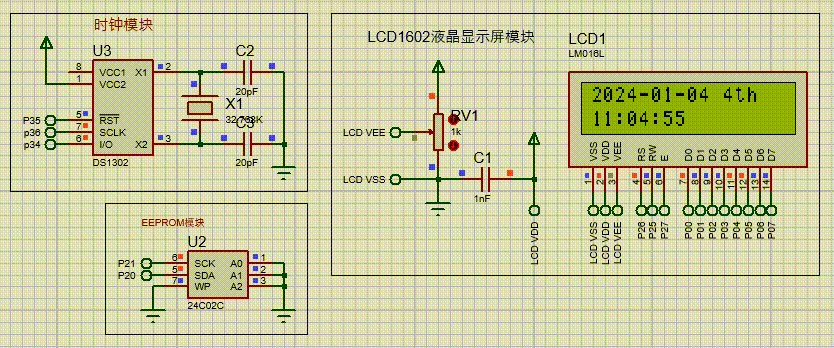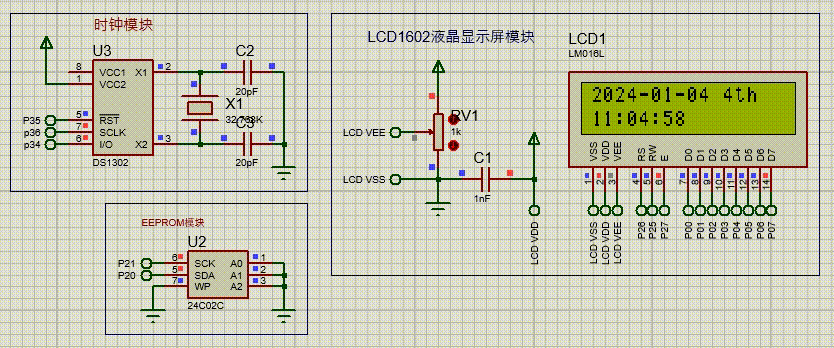
MongoDB 介绍
什么是 MongoDB
MongoDB 是一个文档数据库(以 JSON 为数据模型),由 C++ 语言编写,旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。
文档来自于“JSON Document”,并非我们一般理解的 PDF、WORD 文档。
MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。它支持的数据结构非常松散,数据格式是 BSON,一种类似 JSON 的二进制形式的存储格式,简称 Binary JSON,和 JSON 一样支持内嵌的文档对象和数组对象,因此可以存储比较复杂的数据类型。Mongo 最大的特点是它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。原则上 Oracle 和 MySQL 能做的事情,MongoDB 都能做(包括 ACID 事务)。
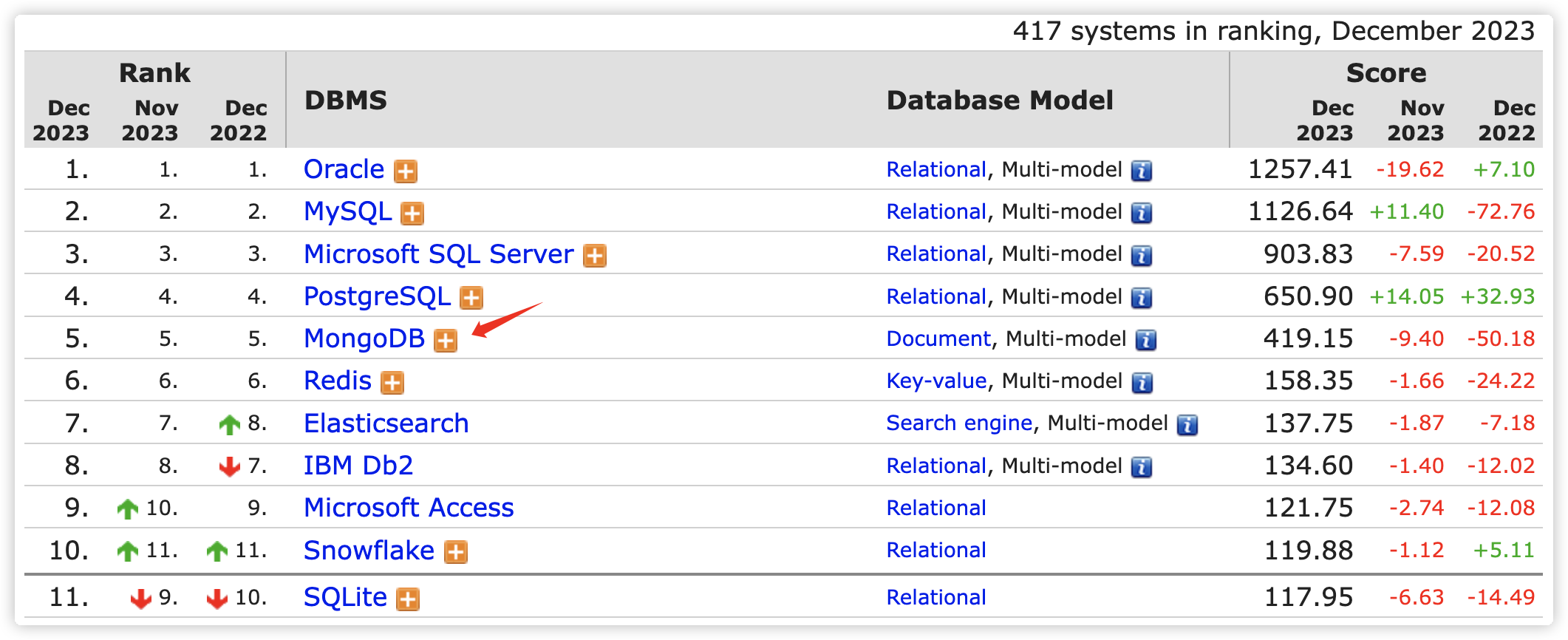
MongoDB 在数据库总排名第 5,仅次于 Oracle、MySQL 等 RDBMS,在 NoSQL 数据库排名首位。从诞生以来,其项目应用广度、社区活跃指数持续上升。
数据库排名网站:https://db-engines.com/en/ranking
MongoDB6.0 新特性
该版本的主要功能特性包括:
- 时序集合增强
- Change Stream 增强
- 可查询加密
- 聚合&query 能力增强
- 集群同步
官网关于升级到 MongoDB6.0 的原因:https://www.mongodb.com/blog/post/big-reasons-upgrade-mongodb-6-0
官方文档:https://www.mongodb.com/docs/v6.0/
MongoDB6.0 发行版本说明:https://www.mongodb.com/docs/v6.0/release-notes/6.0/
阿里云关于 MongoDB6.0 新特性说明:https://help.aliyun.com/document_detail/462614.html?spm=a2c4g.312011.0.0.75b42ab8s9NasS#section-hvy-d22-stk
MongoDB vs 关系型数据库
MongoDB 概念与关系型数据库(RDBMS)非常类似:
| SQL 概念 | MongoDB 概念 |
|---|---|
| 数据库(database) | 数据库(database) |
| 表(table) | 集合(collection) |
| 行(row) | 文档(document) |
| 列(column) | 字段(field) |
| 索引(index) | 索引(index) |
| 主键(primary key) | _id(字段) |
| 视图(view) | 视图(view) |
| 表连接(table joins) | 聚合操作($lookup) |
- 数据库(database):最外层的概念,可以理解为逻辑上的名称空间,一个数据库包含多个不同名称的集合。
- 集合(collection):相当于SQL中的表,一个集合可以存放多个不同的文档。
- 文档(document):一个文档相当于数据表中的一行,由多个不同的字段组成。
- 字段(field):文档中的一个属性,等同于列(column)。
- 索引(index):独立的检索式数据结构,与 SQL 概念一致。
- _id:每个文档中都拥有一个唯一的 _id 字段,相当于 SQL 中的主键(primary key)。
- 视图(view):可以看作一种虚拟的(非真实存在的)集合,与 SQL 中的视图类似。从 MongoDB3.4 版本开始提供了视图功能,其通过聚合管道技术实现。
- 聚合操作($lookup):MongoDB 用于实现“类似”表连接(tablejoin)的聚合操作符。
尽管这些概念大多与 SQL 标准定义类似,但 MongoDB 与传统 RDBMS 仍然存在不少差异,包括:
- 半结构化
在一个集合中,文档所拥有的字段并不需要是相同的,而且也不需要对所用的字段进行声明。因此,MongoDB 具有很明显的半结构化特点。除了松散的表结构,文档还可以支持多级的嵌套、数组等灵活的数据类型,非常契合面向对象的编程模型。
- 弱关系
MongoDB 没有外键的约束,也没有非常强大的表连接能力。类似的功能需要使用聚合管道技术来弥补。
MongoDB 技术优势
MongoDB 基于灵活的 JSON 文档模型,非常适合敏捷式的快速开发。与此同时,其与生俱来的高可用、高水平扩展能力使得它在处理海量、高并发的数据应用时颇具优势。
- JSON 结构和对象模型接近,开发代码量低
- JSON 的动态模型意味着更容易响应新的业务需求
- 复制集提供 99.999% 高可用
- 分片架构支持海量数据和无缝扩容
MongoDB 与关系型数据库对比:
| MongoDB | 关系型数据库 | |
|---|---|---|
| 亿级以上数据量 | 轻松支持 | 分库分表 |
| 灵活表结构 | 轻松支持 | Entity Key/Value 表,关联查询比较痛苦 |
| 高并发读 | 轻松支持 | 需要优化 |
| 高并发写 | 轻松支持 | 需要优化 |
| 跨地区集群 | 轻松支持 | 需要定制方案 |
| 分片集群 | 轻松支持 | 需要中间件 |
| 地理位置查询 | 比较完整的地理位置 | PG 还可以,其他数据库略麻烦 |
| 聚合计算 | 功能很强大 | 使用 Group By 等,能力有限 |
| 异构数据 | 轻松支持 | 使用 EKV 属性表 |
| 大宽表 | 轻松支持 | 性能受限 |
MongoDB 应用场景
从目前阿里云 MongoDB 云数据库上的用户看,MongoDB 的应用已经渗透到各个领域:
- 游戏场景,使用 MongoDB 存储游戏用户信息,用户的装备、积分等直接以内嵌文档的形式存储,方便查询、更新;
- 物流场景,使用 MongoDB 存储订单信息,订单状态在运送过程中会不断更新,以 MongoDB 内嵌数组的形式来存储,一次查询就能将订单所有的变更读取出来;
- 社交场景,使用 MongoDB 存储存储用户信息,以及用户发表的朋友圈信息,通过地理位置索引实现附近的人、地点等功能;
- 物联网场景,使用 MongoDB 存储所有接入的智能设备信息,以及设备汇报的日志信息,并对这些信息进行多维度的分析;
- 视频直播,使用 MongoDB 存储用户信息、礼物信息等;
- 大数据应用,使用云数据库 MongoDB 作为大数据的云存储系统,随时进行数据提取分析,掌握行业动态。
当前业务是否适合使用 MongoDB?
没有某个业务场景必须要使用 MongoDB 才能解决,但使用 MongoDB 通常能让你以更低的成本解决问题。如果你不清楚当前业务是否适合使用 MongoDB,可以通过做几道选择题来辅助决策。
| 应用特征 | Yes/No |
|---|---|
| 应用不需要复杂/长事务及 join 支持 | 必须 Yes |
| 新应用,需求会变,数据模型无法确定,想快速迭代开发 | ? |
| 应用需要 2000-3000 以上的读写 QPS(更高也可以) | ? |
| 应用需要 TB 甚至 PB 级别数据存储 | ? |
| 应用发展迅速,需要能快速水平扩展 | ? |
| 应用要求存储的数据不丢失 | ? |
| 应用需要 99.999% 高可用 | ? |
| 应用需要大量的地理位置查询、文本查询 | ? |
只要有一项需求满足就可以考虑使用 MongoDB,匹配越多,选择 MongoDB 越合适。
MongoDB 环境搭建
linux 安装 MongoDB
1)环境准备
linux系统:centos7
安装 MongoDB 社区版
# 查看linux版本
[root@hecs-403280 ~]# cat /etc/redhat-release
CentOS Linux release 7.9.2009 (Core)
2)下载 MongoDB Community Server
下载地址:https://www.mongodb.com/try/download/community
# 下载MongoDB
wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-6.0.5.tgz
tar -zxvf mongodb-linux-x86_64-rhel70-6.0.5.tgz
3)启动 MongoDB Server
# 创建dbpath和logpath
[root@hecs-403280 mongodb]# pwd
/usr/local/mongodb
[root@hecs-403280 mongodb]# mkdir -p data log
[root@hecs-403280 mongodb]# ls
bin data LICENSE-Community.txt log MPL-2 README THIRD-PARTY-NOTICES
# 进入mongodb目录,启动mongodb服务
bin/mongod --port=27017 --dbpath=/usr/local/mongodb/data --logpath=/usr/local/mongodb/log/mongodb.log --bind_ip=0.0.0.0 --fork
–dbpath:指定数据文件存放目录
–logpath:指定日志文件,注意是指定文件不是目录
–logappend:使用追加的方式记录日志
–port:指定端口,默认为27017
–bind_ip:默认只监听localhost网卡
–fork:后台启动
–auth:开启认证模式

4)添加环境变量
修改/etc/profile,添加环境变量,方便执行 MongoDB 命令
export MONGODB_HOME=/usr/local/mongodb
PATH=$PATH:$MONGODB_HOME/bin
然后执行 source /etc/profile 重新加载环境变量。
5)利用配置文件启动服务
编辑/usr/local/mongodb/conf/mongo.conf文件,内容如下:
systemLog:
destination: file
path: /usr/local/mongodb/log/mongod.log # log path
logAppend: true
storage:
dbPath: /usr/local/mongodb/data # data directory
engine: wiredTiger #存储引擎
journal: #是否启用journal日志
enabled: true
net:
bindIp: 0.0.0.0
port: 27017 # port
processManagement:
fork: true
注意:一定要yaml格式。
启动 mongod:
mongod -f /usr/local/mongodb/conf/mongo.conf
-f 选项表示将使用配置文件启动 mongodb。
6)关闭 MongoDB 服务
方式 1:
mongod --port=27017 --dbpath=/usr/local/mongodb/data --shutdown
方式 2:
进入 mongosh
use admin
# 关闭 MongoDB server 服务
db.shutdownServer()
mongosh 使用
mongosh 是 MongoDB 的交互式 JavaScript Shell 界面,它为系统管理员提供了强大的界面,并为开发人员提供了直接测试数据库查询和操作的方法。
注意:MongoDB 6.0 移除了mongo,使用 mongosh。
mongosh 下载地址:https://www.mongodb.com/try/download/shell
# centos7 安装mongosh
wget https://downloads.mongodb.com/compass/mongodb-mongosh-1.8.0.x86_64.rpm
yum install -y mongodb-mongosh-1.8.0.x86_64.rpm
# 连接mongodb server端
# mongosh --host=192.168.65.206 --port=27017
# mongosh 192.168.65.206:27017
# 指定uri方式连接
# mongosh mongodb://192.168.65.206:27017/test
mongosh
–port:指定端口,默认为27017
–host:连接的主机地址,默认127.0.0.1

mongosh 常用命令
| 命令 | 说明 |
|---|---|
| show dbs | show databases | 显示数据库列表 |
| use 数据库名 | 切换数据库,如果不存在创建数据库 |
| db.dropDatabase() | 删除数据库 |
| show collections | show tables | 显示当前数据库的集合列表 |
| db.集合名.stats() | 查看集合详情 |
| db.集合名.drop() | 删除集合 |
| show users | 显示当前数据库的用户列表 |
| show roles | 显示当前数据库的角色列表 |
| show profile | 显示最近发生的操作 |
| load(“xxx.js”) | 执行一个 JavaScript 脚本文件 |
| exit | quit | 退出当前 shell |
| help | 查看 mongodb 支持哪些命令 |
| db.help() | 查询当前数据库支持的方法 |
| db.集合名.help() | 显示集合的帮助信息 |
| db.version() | 查看数据库版本 |
数据库操作
# 查看所有库
show dbs
# 切换到指定数据库,不存在则创建
use test
# 删除当前数据库
db.dropDatabase()
集合操作
# 查看集合
show collections
# 创建集合
db.createCollection("emp")
# 删除集合
db.emp.drop()
创建集合语法
db.createCollection(name, options)
options 参数:
| 字段 | 类型 | 描述 |
|---|---|---|
| capped | 布尔 | (可选)如果为 true,则创建固定集合。固定集合是指有着固定大小的集合,当达到最大值时,它会自动覆盖最早的文档。 |
| size | 数值 | (可选)为固定集合指定一个最大值(以字节计)。 如果 capped 为 true,也需要指定该字段。 |
| max | 数值 | (可选)指定固定集合中包含文档的最大数量。 |
注意:当集合不存在时,向集合中插入文档也会创建集合。
安全认证
使用用户名和密码来认证用户身份是 MongoDB 中最常用的安全认证方式。可以通过以下步骤实现:
- 创建一个管理员用户(root)并设置密码,具有所有数据库的管理权限。
- 创建一个或多个普通用户,指定相应的数据库和集合权限,并设置密码。
启用认证后,客户端连接 MongoDB 服务器时需要提供用户名和密码才能成功连接。
创建管理员用户
# 设置管理员用户名密码需要切换到admin库
use admin
# 创建管理员
db.createUser({user:"firechou",pwd:"firechou",roles:["root"]})
# 查看当前数据库所有用户信息
show users
# 显示可设置权限
show roles
# 显示所有用户
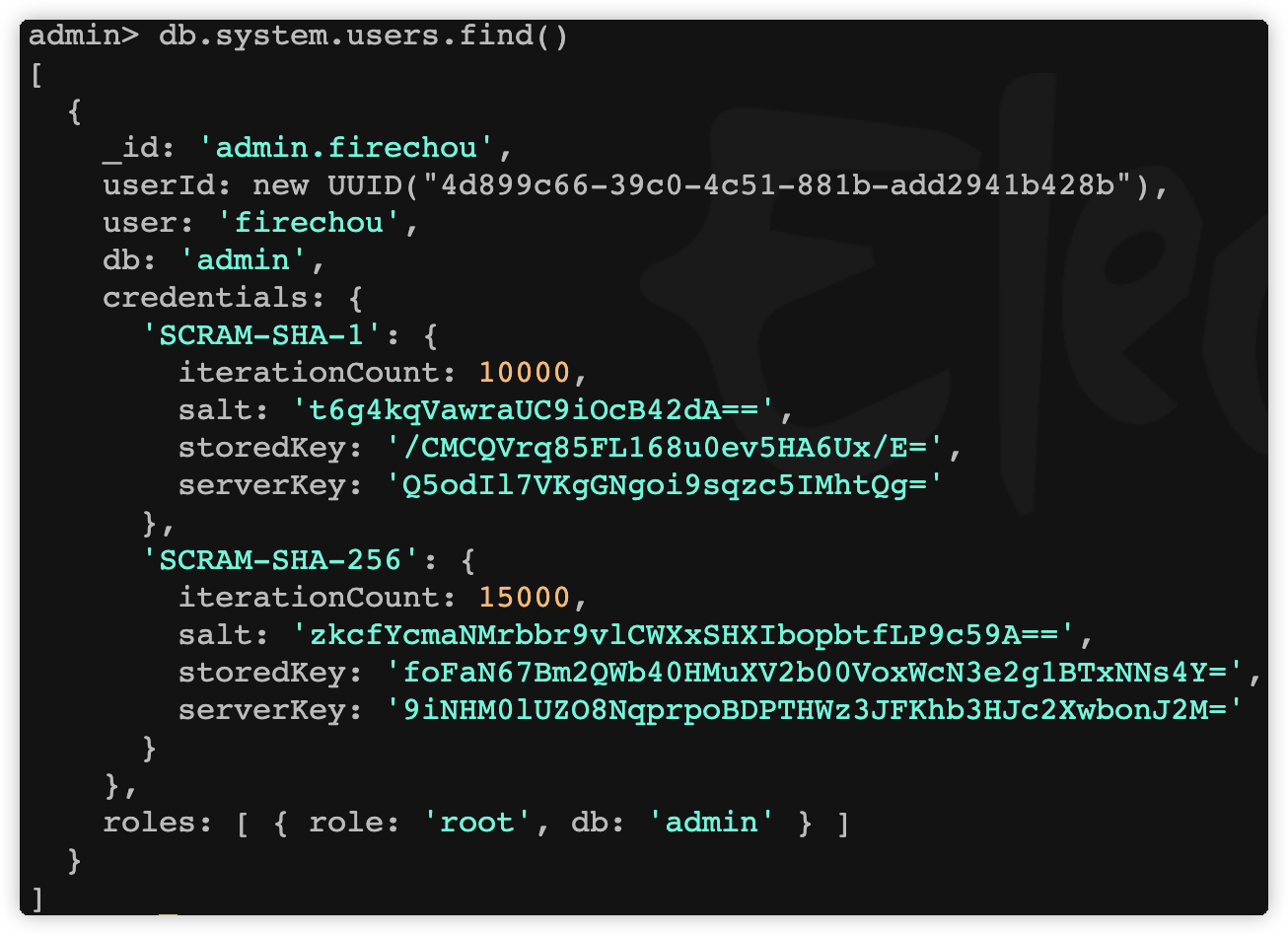
db.system.users.find()
常用权限
| 权限名 | 描述 |
|---|---|
| read | 允许用户读取指定数据库 |
| readWrite | 允许用户读写指定数据库 |
| dbAdmin | 允许用户在指定数据库中执行管理函数,如索引创建、删除,查看统计或访问 system.profile |
| dbOwner | 允许用户在指定数据库中执行任意操作,增、删、改、查等 |
| userAdmin | 允许用户向 system.users 集合写入,可以在指定数据库里创建、删除和管理用户 |
| clusterAdmin | 只在 admin 数据库中可用,赋予用户所有分片和复制集相关函数的管理权限 |
| readAnyDatabase | 只在 admin 数据库中可用,赋予用户所有数据库的读权限 |
| readWriteAnyDatabase | 只在 admin 数据库中可用,赋予用户所有数据库的读写权限 |
| userAdminAnyDatabase | 只在 admin 数据库中可用,赋予用户所有数据库的 userAdmin 权限 |
| dbAdminAnyDatabase | 只在 admin 数据库中可用,赋予用户所有数据库的 dbAdmin 权限 |
| root | 只在 admin 数据库中可用。超级账号,超级权限 |
重新赋予用户操作权限:
db.grantRolesToUser( "firechou" , [
{ role: "clusterAdmin", db: "admin" } ,
{ role: "userAdminAnyDatabase", db: "admin"},
{ role: "readWriteAnyDatabase", db: "admin"}
])
删除用户:
db.dropUser("firechou")
# 删除当前数据库所有用户
db.dropAllUser()
用户认证,返回 1 表示认证成功:
创建应用数据库用户
use appdb
db.createUser({user:"appdb",pwd:"firechou",roles:["dbOwner"]})
MongoDB 启用鉴权
默认情况下,MongoDB 不会启用鉴权,以鉴权模式启动 MongoDB:
mongod -f /usr/local/mongodb/conf/mongo.conf --auth
启用鉴权之后,连接 MongoDB 的相关操作都需要提供身份认证。
mongosh 192.168.65.206:27017 -u firechou -p firechou --authenticationDatabase=admin
Docker 安装 MongoDB
https://hub.docker.com/_/mongo?tab=description&page=3
# 拉取mongo镜像
docker pull mongo:6.0.5
# 运行mongo镜像
docker run --name mongo-server -p 29017:27017 \
-e MONGO_INITDB_ROOT_USERNAME=firechou \
-e MONGO_INITDB_ROOT_PASSWORD=firechou \
-d mongo:6.0.5 --wiredTigerCacheSizeGB 1
默认情况下,Mongo 会将 wiredTigerCacheSizeGB 设置为与主机总内存成比例的值,而不考虑你可能对容器施加的内存限制。
MONGO_INITDB_ROOT_USERNAME 和 MONGO_INITDB_ROOT_PASSWORD 都存在就会启用身份认证(mongod --auth)
利用 mongosh 建立连接:
# 远程连接
mongosh ip:29017 -u firechou -p firechou
MongoDB 常用工具
GUI 工具
(1)官方GUI:COMPASS
MongoDB 图形化管理工具(GUI),能够帮助您在不需要知道 MongoDB 查询语法的前提下,便利地分析和理解您的数据库模式,并且帮助您可视化地构建查询。
下载地址:https://www.mongodb.com/zh-cn/products/compass
(2)Robo 3T(免费)
下载地址:https://robomongo.org/
(3)Studio 3T(收费,试用30天)
下载地址:https://studio3t.com/download/
MongoDB Database Tools
下载地址:https://www.mongodb.com/try/download/database-tools
| 文件名称 | 作用 |
|---|---|
| mongostat | 数据库性能监控工具 |
| mongotop | 热点表监控工具 |
| mongodump | 数据库逻辑备份工具 |
| mongorestore | 数据库逻辑恢复工具 |
| mongoexport | 数据导出工具 |
| mongoimport | 数据导入工具 |
| bsondump | BSON 格式转换工具 |
| mongofiles | GridFS 文件工具 |
MongoDB 文档操作
SQL to MongoDB Mapping Chart :https://www.mongodb.com/docs/manual/reference/sql-comparison/
插入文档
MongoDB 提供了以下方法将文档插入到集合中:
- db.collection.insertOne ():将单个文档插入到集合中。
- db.collection.insertMany ():将多个文档插入到集合中。
新增单个文档
- insertOne:用于向集合中插入一条文档数据,支持 writeConcern。语法如下:
db.collection.insertOne(
<document>,
{
writeConcern: <document>
}
)

设置 writeConcern 参数的示例:
db.emps.insertOne(
{ name: "firechou", age: 33},
{
writeConcern: { w: "majority", j: true, wtimeout: 5000 }
}
)
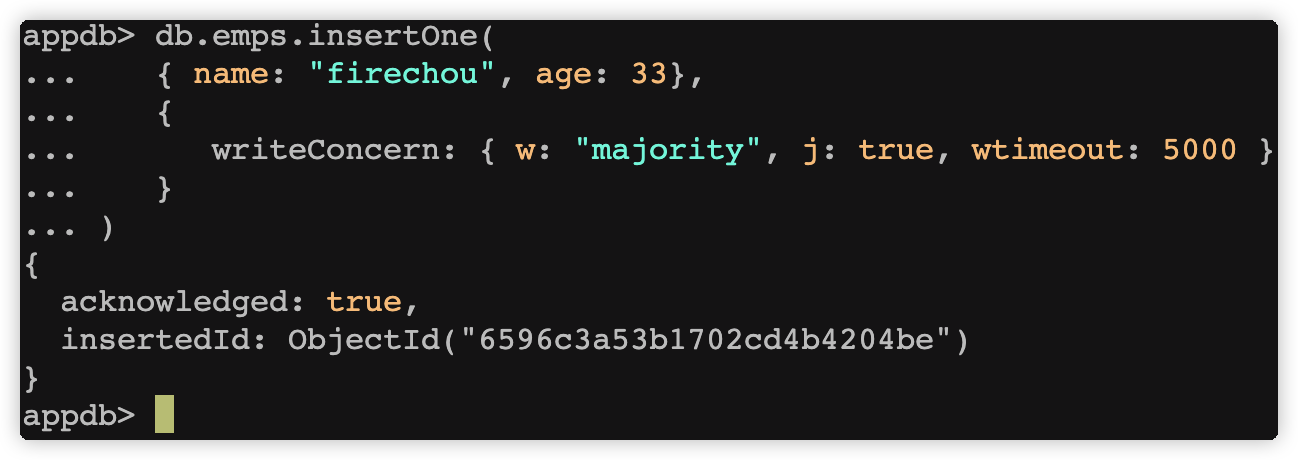
writeConcern 是 MongoDB 中用来控制写入确认的选项。以下是 writeConcern 参数的一些常见选项:
w:指定写入确认级别。如果指定为数字,则表示要等待写入操作完成的节点数。如果指定为 majority,则表示等待大多数节点完成写入操作。默认为 1,表示等待写入操作完成的节点数为 1。
j:表示写入操作是否要求持久化到磁盘。如果设置为 true,则表示写入操作必须持久化到磁盘后才返回成功。如果设置为 false,则表示写入操作可能在数据被持久化到磁盘之前返回成功。默认为 false。
wtimeout:表示等待写入操作完成的超时时间,单位为毫秒。如果超过指定的时间仍然没有返回确认信息,则返回错误。默认为 0,表示不设置超时时间。
批量新增文档
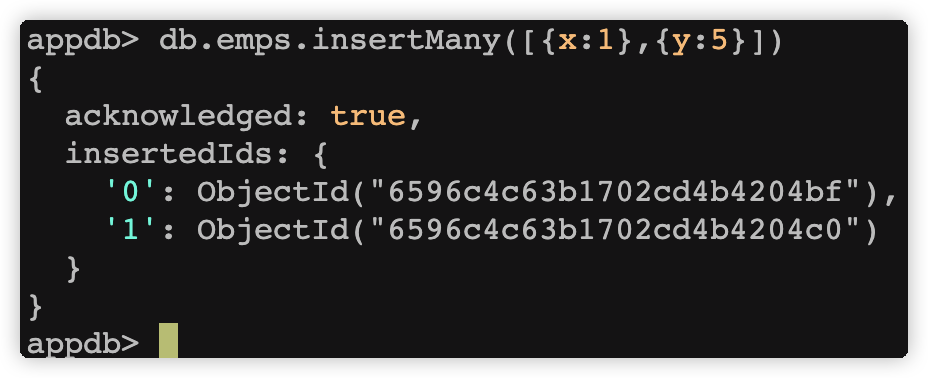
- insertMany:向指定集合中插入多条文档数据
db.collection.insertMany(
[ <document 1> , <document 2>, ... ],
{
writeConcern: <document>,
ordered: <boolean>
}
)
writeConcern:写入确认选项,可选。
ordered:指定是否按顺序写入,默认 true,按顺序写入。
db.emps.insertMany([{x:1},{y:5}])
测试:批量插入 50 条随机数据
编辑脚本 book.js:
var tags = ["nosql","mongodb","document","developer","popular"];
var types = ["technology","sociality","travel","novel","literature"];
var books=[];
for(var i=0;i<50;i++){
var typeIdx = Math.floor(Math.random()*types.length);
var tagIdx = Math.floor(Math.random()*tags.length);
var favCount = Math.floor(Math.random()*100);
var book = {
title: "book-"+i,
type: types[typeIdx],
tag: tags[tagIdx],
favCount: favCount,
author: "xxx"+i
};
books.push(book)
}
db.books.insertMany(books);
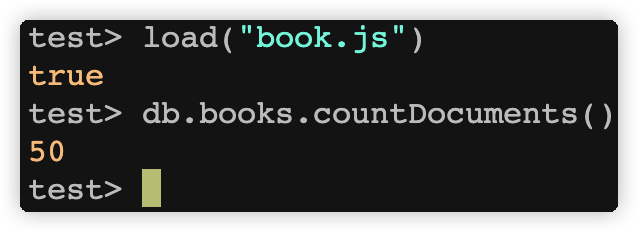
进入 mongosh,执行:
load("books.js")
查询文档
查询集合中的若干文档
语法格式如下:
db.collection.find(query, projection)
query:可选,使用查询操作符指定查询条件
projection:可选,使用投影操作符指定返回的键。查询时返回文档中所有键值,只需省略该参数即可(默认省略)。投影时,_id 为 1 的时候,其他字段必须是 1;_id 是 0 的时候,其他字段可以是 0;如果没有 _id 字段约束,多个其他字段必须同为 0 或同为 1。
如果查询返回的条目数量较多,mongosh 则会自动实现分批显示。默认情况下每次只显示 20 条,可以输入 it 命令读取下一批。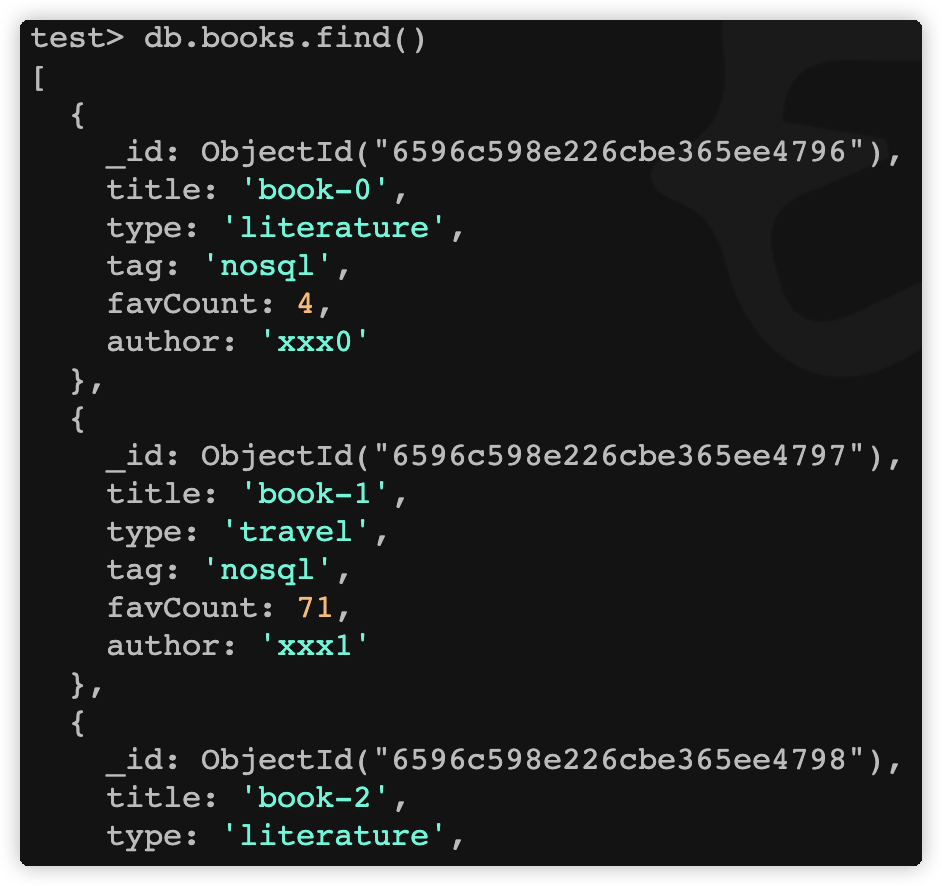
查询集合中的第一个文档
语法格式如下:
db.collection.findOne(query, projection)
示例:
db.books.findOne()
db.books.find({tag:"nosql"},{title:1,author:1})
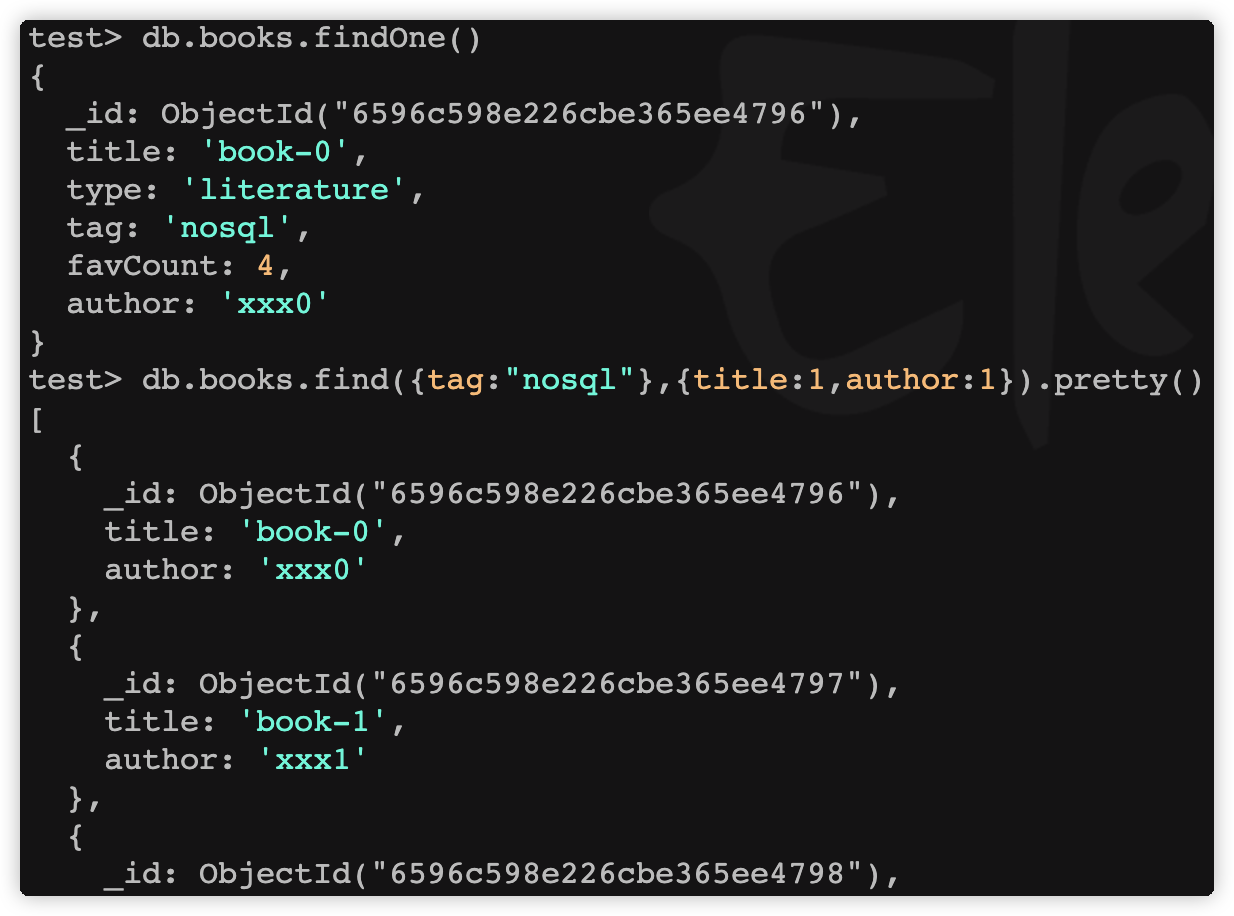
如果你需要以易读的方式来读取数据,可以使用 pretty 方法,语法格式如下:
db.collection.find().pretty()
注意:pretty() 方法以格式化的方式来显示所有文档。
条件查询
查询条件对照表:
| **SQL ** | MQL |
|---|---|
| a = 1 | {a: 1} |
| a <> 1 | {a: {$ne: 1}} |
| a > 1 | {a: {$gt: 1}} |
| a >= 1 | {a: {$gte: 1}} |
| a < 1 | {a: {$lt: 1}} |
| a <= 1 | {a: {$lte: 1}} |
查询逻辑对照表:
| **SQL ** | MQL |
|---|---|
| a = 1 AND b = 1 | {a: 1, b: 1}或{$and: [{a: 1}, {b: 1}]} |
| a = 1 OR b = 1 | {$or: [{a: 1}, {b: 1}]} |
| a IS NULL | {a: {$exists: false}} |
| a IN (1, 2, 3) | {a: {$in: [1, 2, 3]}} |
查询逻辑运算符:
$lt: 存在并小于
$lte: 存在并小于等于
$gt: 存在并大于
$gte: 存在并大于等于
$ne: 不存在或存在但不等于
$in: 存在并在指定数组中
$nin: 不存在或不在指定数组中
$or: 匹配两个或多个条件中的一个
$and: 匹配全部条件
# 查询带有nosql标签的book文档:
db.books.find({tag:"nosql"})
# 按照id查询单个book文档:
db.books.find({_id:ObjectId("6596c598e226cbe365ee4796")})
# 查询分类为“travel”、收藏数超过60个的book文档:
db.books.find({type:"travel",favCount:{$gt:60}})
正则表达式匹配查询
MongoDB 使用 $regex 操作符来设置匹配字符串的正则表达式。
# 使用正则表达式查找type包含 so 字符串的book
db.books.find({type:{$regex:"so"}})
# 或者
db.books.find({type:/so/})
排序
在 MongoDB 中使用 sort() 方法对数据进行排序
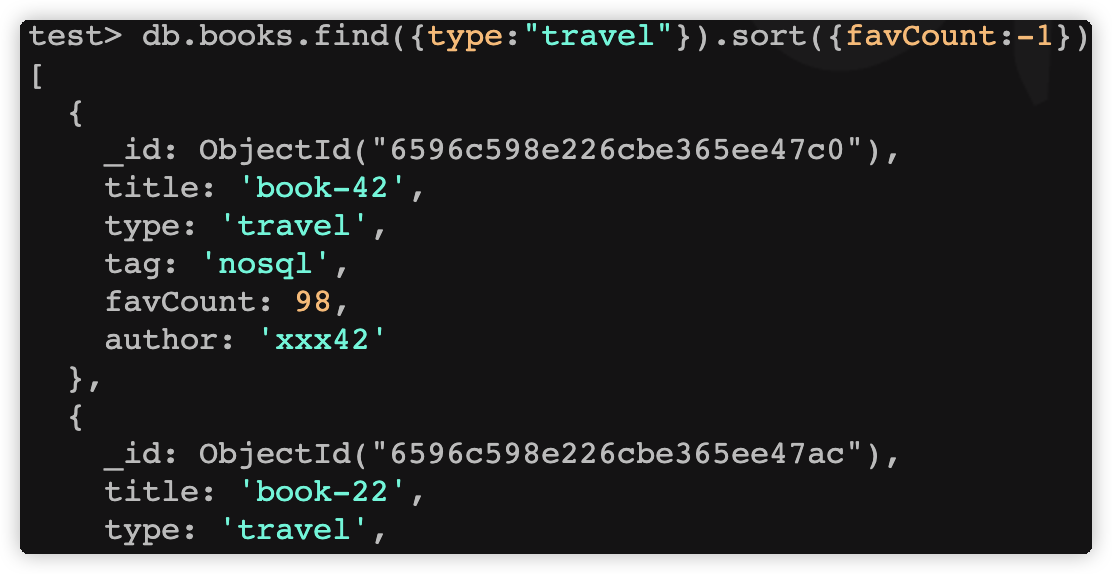
# 指定按收藏数(favCount)降序返回
db.books.find({type:"travel"}).sort({favCount:-1})
1 为升序排列,而 -1 是用于降序排列
分页
skip 用于指定跳过记录数,limit 则用于限定返回结果数量。可以在执行 find 命令的同时指定 skip、limit 参数,以此实现分页的功能。
比如,假定每页大小为 8 条,查询第 3 页的 book 文档:
db.books.find().skip(16).limit(8)
.skip(16) 表示跳过前面 16 条记录,即前两页的所有记录。
.limit(8) 表示返回 8 条记录,即第三页的所有记录。
(1)处理分页问题-巧分页
数据量大的时候,应该避免使用 skip/limit 形式的分页。
替代方案:使用查询条件+唯一排序条件。
例如:
# 第一页
db.books.find({}).sort({_id: 1}).limit(10);
# 第二页
db.books.find({_id: {$gt: <第一页最后一个_id>}}).sort({_id: 1}).limit(10);
# 第三页
db.books.find({_id: {$gt: <第二页最后一个_id>}}).sort({_id: 1}).limit(10);
(2)处理分页问题–避免使用 count
尽可能不要计算总页数,特别是数据量大和查询条件不能完整命中索引时。
考虑以下场景:假设集合总共有 1000w 条数据,在没有索引的情况下考虑以下查询:
db.coll.find({x: 100}).limit(50);
db.coll.count({x: 100});
前者只需要遍历前 n 条,直到找到 50 条 x=100 的文档即可结束;
后者需要遍历完 1000w 条找到所有符合要求的文档才能得到结果。为了计算总页数而进行的 count() 往往是拖慢页面整体加载速度的原因;
更新文档
MongoDB 提供了以下方法来更新集合中的文档:
- db.collection.updateOne ()
即使多个文档可能与指定的筛选器匹配,也只会更新第一个匹配的文档。
- db.collection.updateMany ()
更新与指定筛选器匹配的所有文档。
更新操作符:
| 操作符 | 格式 | 描述 |
|---|---|---|
| $set | {$set:{field:value}} | 指定一个键并更新值,若键不存在则创建 |
| $unset | {$unset : {field : 1 }} | 删除一个键 |
| $inc | {$inc : {field : value } } | 对数值类型进行增减 |
| $rename | {$rename : {old_field_name : new_field_name } } | 修改字段名称 |
| $push | { $push : {field : value } } | 将数值追加到数组中,若数组不存在则会进行初始化 |
| $pushAll | {$pushAll : {field : value_array }} | 追加多个值到一个数组字段内 |
| $pull | {$pull : {field : _value } } | 从数组中删除指定的元素 |
| $addToSet | {$addToSet : {field : value } } | 添加元素到数组中,具有排重功能 |
| $pop | {$pop : {field : 1 }} | 删除数组的第一个或最后一个元素 |
更新单个文档
updateOne 语法如下:
db.collection.updateOne(
<filter>,
<update>,
{
upsert: <boolean>,
writeConcern: <document>,
collation: <document>,
arrayFilters: [ <filterdocument1>, ... ],
hint: <document|string> // Available starting in MongoDB 4.2.1
}
)
db.collection.updateOne() 方法的参数含义如下:
:一个筛选器对象,用于指定要更新的文档。只有与筛选器对象匹配的第一个文档才会被更新。
:一个更新操作对象,用于指定如何更新文档。可以使用一些操作符,例如 s e t 、 set、 set、inc、 u n s e t 等,以更新文档中的特定字段。 u p s e r t :一个布尔值,用于指定如果找不到与筛选器匹配的文档时是否应插入一个新文档。如果 u p s e r t 为 t r u e ,则会插入一个新文档。默认值为 f a l s e 。 w r i t e C o n c e r n :一个文档,用于指定写入操作的安全级别。可以指定写入操作需要到达的节点数或等待写入操作的时间。 c o l l a t i o n :一个文档,用于指定用于查询的排序规则。例如,可以通过指定 l o c a l e 属性来指定语言环境,从而实现基于区域设置的排序。 a r r a y F i l t e r s :一个数组,用于指定要更新的数组元素。数组元素是通过使用更新操作符 unset 等,以更新文档中的特定字段。 upsert:一个布尔值,用于指定如果找不到与筛选器匹配的文档时是否应插入一个新文档。如果 upsert 为 true,则会插入一个新文档。默认值为 false。 writeConcern:一个文档,用于指定写入操作的安全级别。可以指定写入操作需要到达的节点数或等待写入操作的时间。 collation:一个文档,用于指定用于查询的排序规则。例如,可以通过指定 locale 属性来指定语言环境,从而实现基于区域设置的排序。 arrayFilters:一个数组,用于指定要更新的数组元素。数组元素是通过使用更新操作符 unset等,以更新文档中的特定字段。upsert:一个布尔值,用于指定如果找不到与筛选器匹配的文档时是否应插入一个新文档。如果upsert为true,则会插入一个新文档。默认值为false。writeConcern:一个文档,用于指定写入操作的安全级别。可以指定写入操作需要到达的节点数或等待写入操作的时间。collation:一个文档,用于指定用于查询的排序规则。例如,可以通过指定locale属性来指定语言环境,从而实现基于区域设置的排序。arrayFilters:一个数组,用于指定要更新的数组元素。数组元素是通过使用更新操作符[]和$来指定的。
hint:一个文档或字符串,用于指定查询使用的索引。该参数仅在 MongoDB 4.2.1 及以上版本中可用。
注意,除了 filter 和 update 参数外,其他参数都是可选的。
某个 book 文档被收藏了,则需要将该文档的 favCount 字段自增:
db.books.updateOne({_id:ObjectId("6596c598e226cbe365ee47ac")},{$inc:{favCount:1}})
upsert 是一种特殊的更新,其表现为如果目标文档不存在,则执行插入命令。
db.books.updateOne(
{title:"my book"},
{$set:{tags:["nosql","mongodb"],type:"none",author:"firechou"}},
{upsert:true}
)
更新多个文档
updateMany 更新与集合的指定筛选器匹配的所有文档.
将分类为“novel”的文档的增加发布时间(publishedDate):
db.books.updateMany({type:"novel"},{$set:{publishedDate:new Date()}})
(1)findAndModify
findAndModify 兼容了查询和修改指定文档的功能,findAndModify 只能更新单个文档:
# 将某个book文档的收藏数(favCount)加1
db.books.findAndModify({
query:{_id:ObjectId("6457a39c817728350ec83b9d")},
update:{$inc:{favCount:1}}
})
该操作会返回符合查询条件的文档数据,并完成对文档的修改。
默认情况下,findAndModify 会返回修改前的“旧”数据。如果希望返回修改后的数据,则可以指定 new 选项:
db.books.findAndModify({
query:{_id:ObjectId("6457a39c817728350ec83b9d")},
update:{$inc:{favCount:1}},
new: true
})
与 findAndModify 语义相近的命令如下:
- findOneAndUpdate:更新单个文档并返回更新前(或更新后)的文档。
- findOneAndReplace:替换单个文档并返回替换前(或替换后)的文档。
删除文档
deleteOne & deleteMany
官方推荐使用 deleteOne() 和 deleteMany() 方法删除文档,语法格式如下:
# 删除 type 等于 novel 的一个文档
db.books.deleteOne({ type:"novel" })
# 删除集合下全部文档
db.books.deleteMany({})
# 删除 type等于 novel 的全部文档
db.books.deleteMany({ type:"novel" })
注意:remove、deleteMany 命令需要对查询范围内的文档逐个删除,如果希望删除整个集合,则使用 drop 命令会更加高效。
findOneAndDelete
deleteOne 命令在删除文档后只会返回确认性的信息,如果希望获得被删除的文档,则可以使用 findOneAndDelete 命令:
db.books.findOneAndDelete({type:"novel"})
除了在结果中返回删除文档,findOneAndDelete 命令还允许定义“删除的顺序”,即按照指定顺序删除找到的第一个文档。利用这个特性,findOneAndDelete 可以实现队列的先进先出:
db.books.findOneAndDelete({type:"novel"},{sort:{favCount:1}})
批量操作
bulkwrite() 方法提供了执行批量插入、更新和删除操作的能力。
bulkWrite() 支持以下写操作:
- insertOne
- updateOne
- updateMany
- replaceOne
- deleteOne
- deleteMany
每个写操作都作为数组中的文档传递给 bulkWrite()。
db.pizzas.insertMany( [
{ _id: 0, type: "pepperoni", size: "small", price: 4 },
{ _id: 1, type: "cheese", size: "medium", price: 7 },
{ _id: 2, type: "vegan", size: "large", price: 8 }
] )
db.pizzas.bulkWrite( [
{ insertOne: { document: { _id: 3, type: "beef", size: "medium", price: 6 } } },
{ insertOne: { document: { _id: 4, type: "sausage", size: "large", price: 10 } } },
{ updateOne: {
filter: { type: "cheese" },
update: { $set: { price: 8 } }
} },
{ deleteOne: { filter: { type: "pepperoni"} } },
{ replaceOne: {
filter: { type: "vegan" },
replacement: { type: "tofu", size: "small", price: 4 }
} }
] )