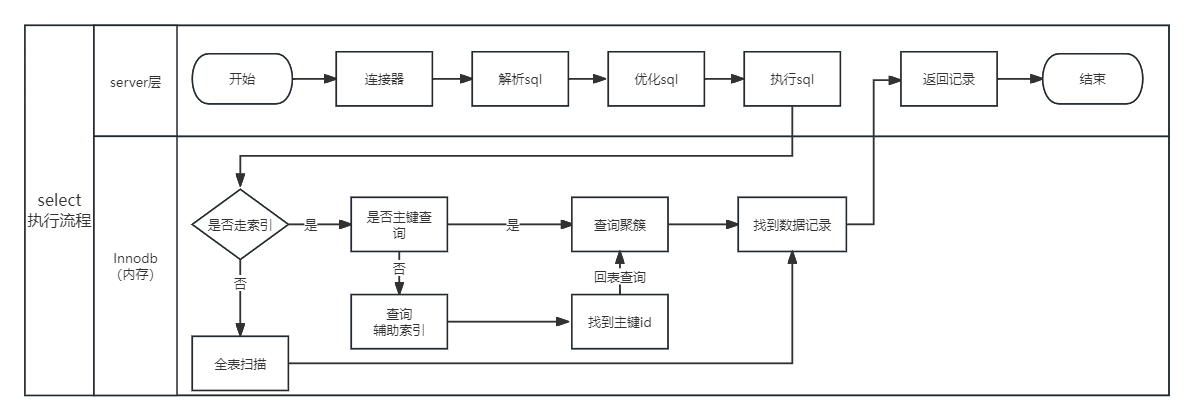
上文我们学习了索引基础知识、所以我画了一个查询语句简单的执行流程、希望可以帮助大家一起学习。
目录
mysql select语句执行流程
普通索引
复合索引
创建索引(三种)
1、使用INDEX建表的时候创建索引 (创建表时建索引)
INDEX的语法:
INDEX的案例:
2、使用 CREATE INDEX 语句可以创建普通索引。(就是给指定表新增索引)
CREATE INDEX 的语法:
CREATE INDEX 案例:
3、使用ALTER语句创建(是给指定表、指定指端新增索引)
ALTER的语法:
ALTER的案例:
索引规则 (最常见的)
Using Where(索引回表)
使用explain执行sql(索引回表)
sql执行流程(索引回表)
Using Index(索引覆盖)
使用explain执行sql(索引覆盖)
sql执行流程(索引回表)
最左匹配:讲了很多遍了、这次讲点不一样的
案例1:age和status做为查询条件
案例2:只用status做为查询条件
Using Index Condition(索引下推)
mysql select语句执行流程
普通索引
索引能够显著提高查询的速度,尤其是在大型表中进行搜索时。通过使用索引,MySQL 可以直接定位到满足查询条件的数据行,而无需逐行扫描整个表。
通俗来讲:普通索引,就是在创建索引时,没有任何限制条件(唯一、非空等限制)。该类型的索引可以创建在任何数据类型的字段上。
复合索引
用户可以在多个列上建立索引,这种索引叫做复合索引(组合索引)。
创建索引(三种)
1、使用INDEX建表的时候创建索引 (创建表时建索引)
INDEX的语法:
INDEX [indexName] (columnName(length))CREATE TABLE table_name (
column1 data_type,
column2 data_type,
...,
INDEX index_name (column1 [ASC|DESC], column2 [ASC|DESC], ...)
);
CREATE INDEX: 用于创建普通索引的关键字。index_name: 指定要创建的索引的名称。索引名称在表中必须是唯一的。table_name: 指定要在哪个表上创建索引。(column1, column2, ...): 指定要索引的表列名。你可以指定一个或多个列作为索引的组合。这些列的数据类型通常是数值、文本或日期。ASC和DESC(可选): 用于指定索引的排序顺序。默认情况下,索引以升序(ASC)排序。
INDEX的案例:
CREATE TABLE user(
id INT NOT NULL,
name varchar(50) NOT NULL,
age INT NOT NULL,
INDEX index_name (name(50))
);2、使用 CREATE INDEX 语句可以创建普通索引。(就是给指定表新增索引)
普通索引是最常见的索引类型,用于加速对表中数据的查询。
CREATE INDEX 的语法:
CREATE INDEX index_name
ON table_name (column1 [ASC|DESC], column2 [ASC|DESC], ...);CREATE INDEX 案例:
就1情况种的 user 的表为例(建表不加索引的情况下),包含 id、name 和 age 列,我们将在 name 列上创建一个普通索引。
CREATE INDEX idx_name ON user (name);还可以指定索引的排序顺序(案例)默认情况下,索引以升序(ASC)排序
CREATE INDEX idx_name ON user (name DESC);3、使用ALTER语句创建(是给指定表、指定指端新增索引)
ALTER的语法:
ALTER TABLE tableName ADD INDEX indexName(columnName);ALTER的案例:
ALTER TABLE user ADD INDEX index_name(name);索引规则 (最常见的)
我们先建一张表user_info表、创建组合索引(复合索引) index_name_age (name,age) 让 名称和年龄做为组合索引。
如果不清楚索引存储的数据结构是什么样子、请移步mysql(二) 索引-基础知识_DJyzh的博客-CSDN博客文章浏览阅读230次。引擎InnoDB与MyISAM的区别存储文件类型事务支持:行级锁定:外键约束:全文搜索:崩溃恢复:表的大小限制:索引的"样子"模拟B+Tree的数据 图InnoDB(结合数据)图MyISAM(结合数据)图索引的基础知识小结:1、为什么不建议使用过长的字段作为主键2、为什么建议使用增长的数字类型作为主键3、索引失效索引及数据都是存在叶子节点中的,默认的节点大小是16kbinnodb 默认的一页大小为 16384B = 16384/1024 = 16kbhttps://blog.csdn.net/qq_42672839/article/details/129261874?spm=1001.2014.3001.5502
CREATE TABLE user_info(
id INT NOT NULL COMMENT '主键',
name varchar(50) NOT NULL COMMENT '名称',
en_name varchar(50) NOT NULL COMMENT '英文名称',
age INT NOT NULL COMMENT '年龄',
status INT NOT NULL COMMENT '0 草稿 1 上架 2 下架',
description varchar(100) NOT NULL COMMENT '描述',
PRIMARY KEY (`id`)
);
#创建组合索引
ALTER TABLE `user_info` ADD INDEX index_name_age_status (`name`,`age`,`status`);
除了id的主键索引以外、我们新建`name`和 `age`、`status`的组合索引index_name_age_status 。我们再写入1000条数据。
CREATE DEFINER=`root`@`localhost` PROCEDURE `123`()
BEGIN
#Routine body goes here...
declare i int default 1;
while(i<1000)do
insert into user_info values(i,CONCAT("yzh",FLOOR(RAND() * 100)),CONCAT("YZH",FLOOR(RAND() * 100)),FLOOR(RAND() * 100),1,FLOOR(RAND() * 1000));
set i=i+1;
end while;
END建好表和数据、我们正式开始。
Using Where(索引回表)
什么样子的查询语句叫做回表查询呢? 本篇开始的 select语句执行流程 不知道大家有么有看懂、我就结合数据再详谈一下。
比如查询语句如下:
select * from user_info where age = "25";使用explain执行sql(索引回表)
 执行计划 Extra: Using where
执行计划 Extra: Using where
当执行这个sql时,会发生回表:从某一个索引的叶子结点中获取聚簇索引的id值,根据id再去聚簇索引中获取全量记录
sql执行流程(索引回表)
如下图红颜色标记的路径

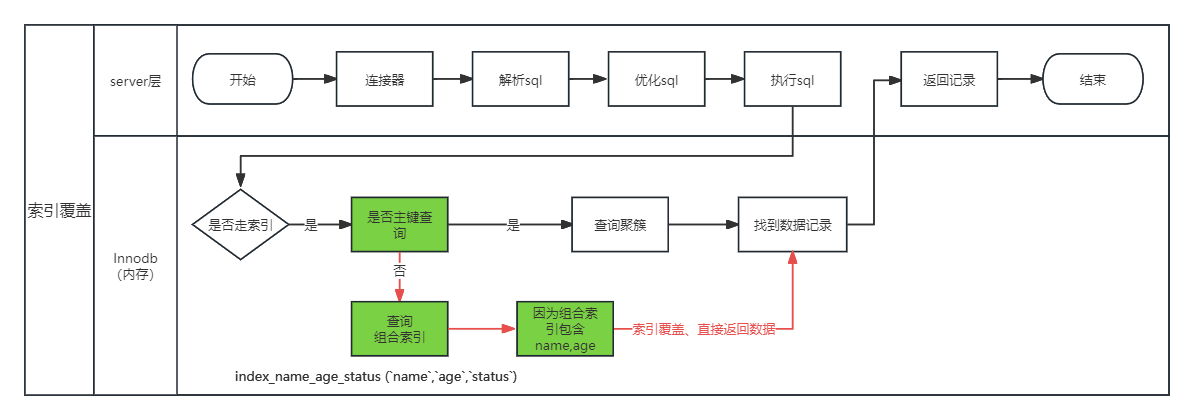
Using Index(索引覆盖)
select age from user_info where name = "李四";使用explain执行sql(索引覆盖)
 Extra“Using index”值表示使用覆盖索引
Extra“Using index”值表示使用覆盖索引
当执行这个sql时,会发生索引覆盖:从索引的叶子结点能获取到全量查询列的过程叫做索引覆盖
sql执行流程(索引回表)
如下图红颜色标记的路径
最左匹配:讲了很多遍了、这次讲点不一样的
我们最常见的最左匹配应该是下面这三种语句:
EXPLAIN select * from user_info where name = "yzh41";
EXPLAIN select * from user_info where name = "yzh41" and age = 10 ;
EXPLAIN select * from user_info where name = "yzh41" and age = 10 and status = 1;毫无疑问这三个查询语句都命中索引(左边顺序)

那么我们接下来考虑一个问题:最左匹配原则外
`name`,`age`,`status`组合索引查`age`,`status`字段,是否使用组合索引?
我们写几个脚本验证一下
案例1:age和status做为查询条件
select * from user_info where age = 10 and status = 1;
select name from user_info where age = 10 and status = 1;第一条很明显不会命中索引

那么第二条呢?

命中了index_name_age_status 索引 Extra“Using index”值表示使用覆盖索引。是不是很神奇?
不急我们再来看一组脚本。
案例2:只用status做为查询条件
select * from user_info where status = 1;
select en_name from user_info where status = 1;
select name from user_info where status = 1;
select age from user_info where status = 1;
select name,status from user_info where status = 1我们可以先猜一猜哪些可以命中、哪些不可以
第一条还是很明显不会命中索引

第二条 select en_name from user_info where status = 1; 没有命中索引

第三条、第四条、第五条都命中了索引(不一一展示了、大家有兴趣自己模拟)

通过上面的案列我们发现、查询的数据是什么很重要、影响是否走索引。 "*"和 非组合索引字段查询都没有走索引。但是如果字段是否可以被覆盖索引覆盖那么会走索引。
总结:根据最左匹配原则外,还要看select语句中字段是否可以被覆盖索引覆盖,如果有则会直接扫描索引返回结果,没有的话则走全表扫描。
Using Index Condition(索引下推)
我想单独写一篇、并且画图解释(请等待)
讲了这多上面的演示可能在实际情况中不会如此建立索引(为了演示才如此)、因为索引并不是建的越多就越快。
因为要平衡 空间上的代价 和 时间上的代价的取舍、建索引查询很爽、但是这个表空间的会越大、带来的后续的很多问题。
比如:索引链很多、现在新增插入数据、那么这些索引的维护操作带来的性能损耗
所以合理建索引是表设计和开发设计的重要环节之一。
版权声明:转载请附上文章地址DJyzh的博客_CSDN博客-java基础,框架,java高级领域博主