前言
最近公司新启动了一个项目,然后领导想用一下新技术,并且为公司提供多个大数据调度解决方案,我呢就根据领导要求调研了下当前的开源调度工具,最终决定采用DolphinScheduler, 因此研究了一下DolphinScheduler ,然后记录一下笔记:
DolphinScheduler官网
https://dolphinscheduler.apache.org/zh-cn/docs/3.2.0/about/introduction
一、DolphinScheduler概述
1.1 、DolphinScheduler 简介(官网的介绍,都很优秀,有些方面确实优秀,要不然也不用它)
Apache DolphinScheduler 是一个分布式易扩展的可视化DAG工作流任务调度开源系统。适用于企业级场景,提供了一个可视化操作任务、工作流和全生命周期数据处理过程的解决方案。
Apache DolphinScheduler 旨在解决复杂的大数据任务依赖关系,并为应用程序提供数据和各种 OPS 编排中的关系。 解决数据研发ETL依赖错综复杂,无法监控任务健康状态的问题。 DolphinScheduler 以 DAG(Directed Acyclic Graph,DAG)流式方式组装任务,可以及时监控任务的执行状态,支持重试、指定节点恢复失败、暂停、恢复、终止任务等操作。
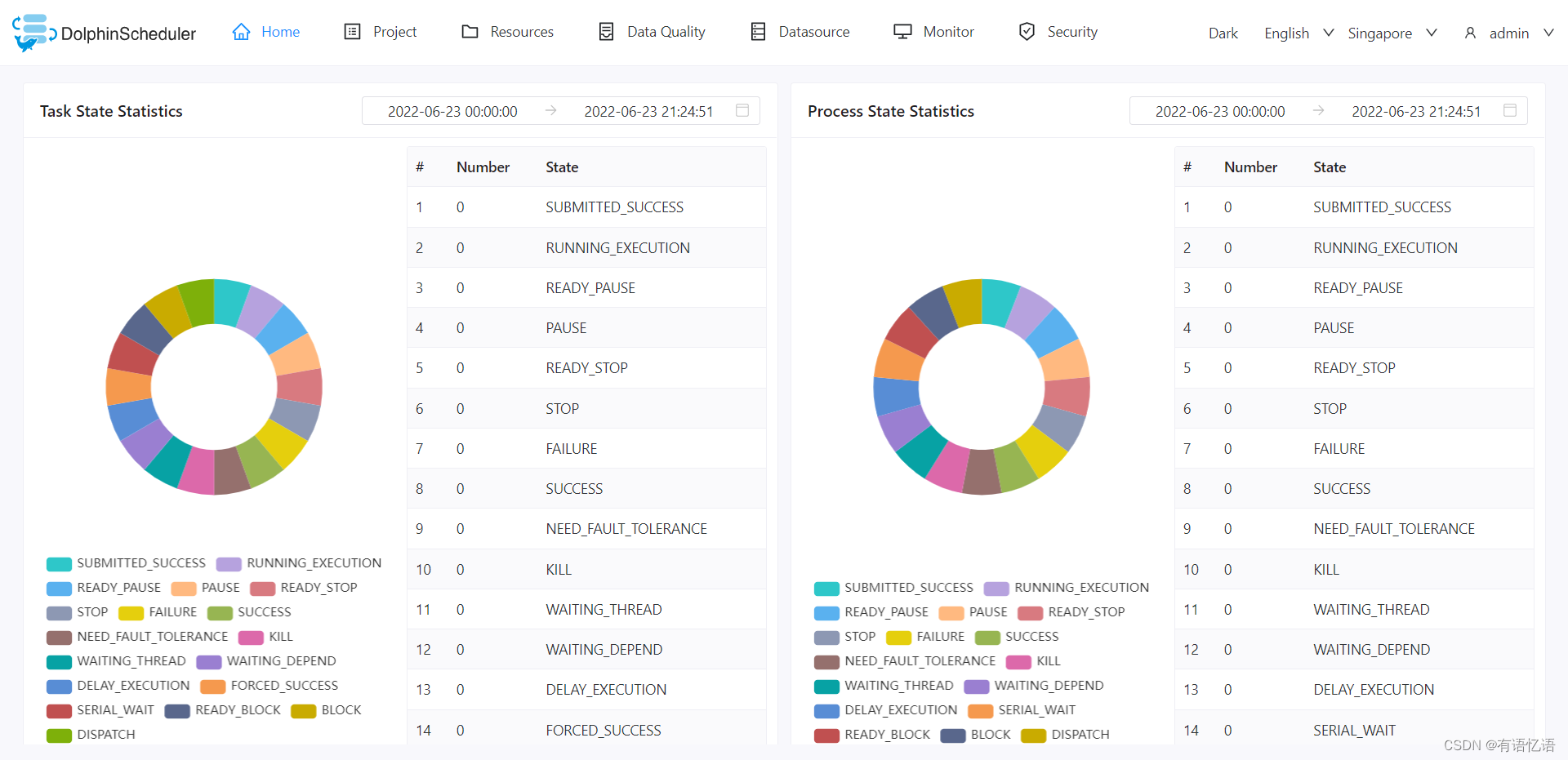
1.2、 特性
简单易用
可视化 DAG: 用户友好的,通过拖拽定义工作流的,运行时控制工具
模块化操作: 模块化有助于轻松定制和维护。
丰富的使用场景
支持多种任务类型: 支持Shell、MR、Spark、SQL等10余种任务类型,支持跨语言,易于扩展
丰富的工作流操作: 工作流程可以定时、暂停、恢复和停止,便于维护和控制全局和本地参数。
High Reliability
高可靠性: 去中心化设计,确保稳定性。 原生 HA 任务队列支持,提供过载容错能力。 DolphinScheduler 能提供高度稳健的环境。
High Scalability
高扩展性: 支持多租户和在线资源管理。支持每天10万个数据任务的稳定运行。
1.3、建议配置
软硬件环境建议配置
DolphinScheduler 作为一款开源分布式工作流任务调度系统,可以很好地部署和运行在 Intel 架构服务器及主流虚拟化环境下,并支持主流的Linux操作系统环境.
linux
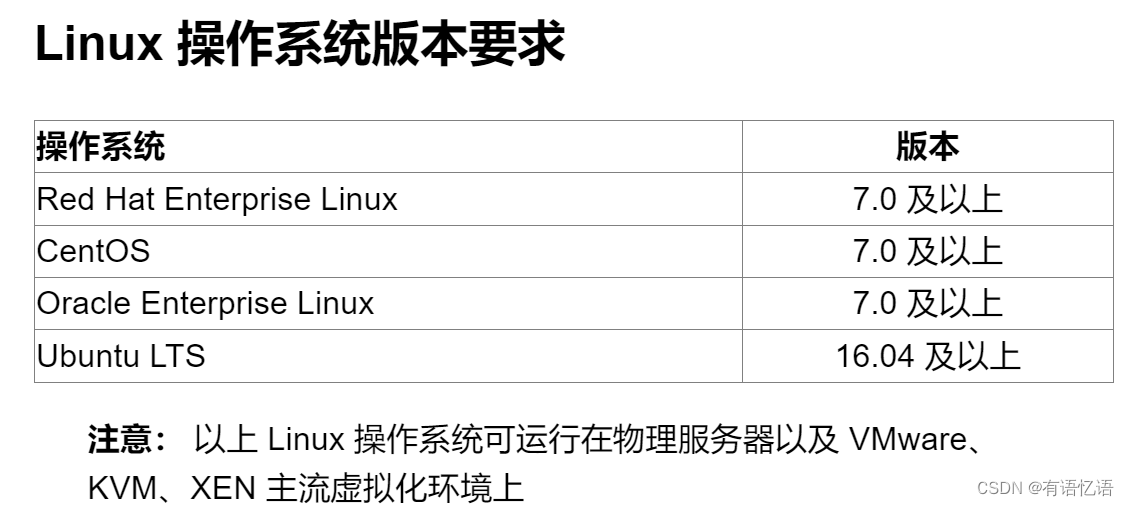
服务器建议配置
DolphinScheduler 支持运行在 Intel x86-64 架构的 64 位通用硬件服务器平台。对生产环境的服务器硬件配置有以下建议:

网络要求

客户端 Web 浏览器要求
DolphinScheduler 推荐 Chrome 以及使用 Chromium 内核的较新版本浏览器访问前端可视化操作界面
时钟同步
为避免可能影响任务执行的内部集群通信问题,请确保所有集群节点上的时钟与公共时钟源同步,例如使用 Chrony 和/或 NTP。 同步时间确保集群中的每个节点都有相同的时间
1.4、名词解释
DAG: 全称 Directed Acyclic Graph,简称 DAG。工作流中的 Task 任务以有向无环图的形式组装起来,从入度为零的节点进行拓扑遍历,直到无后继节点为止。举例如下图:
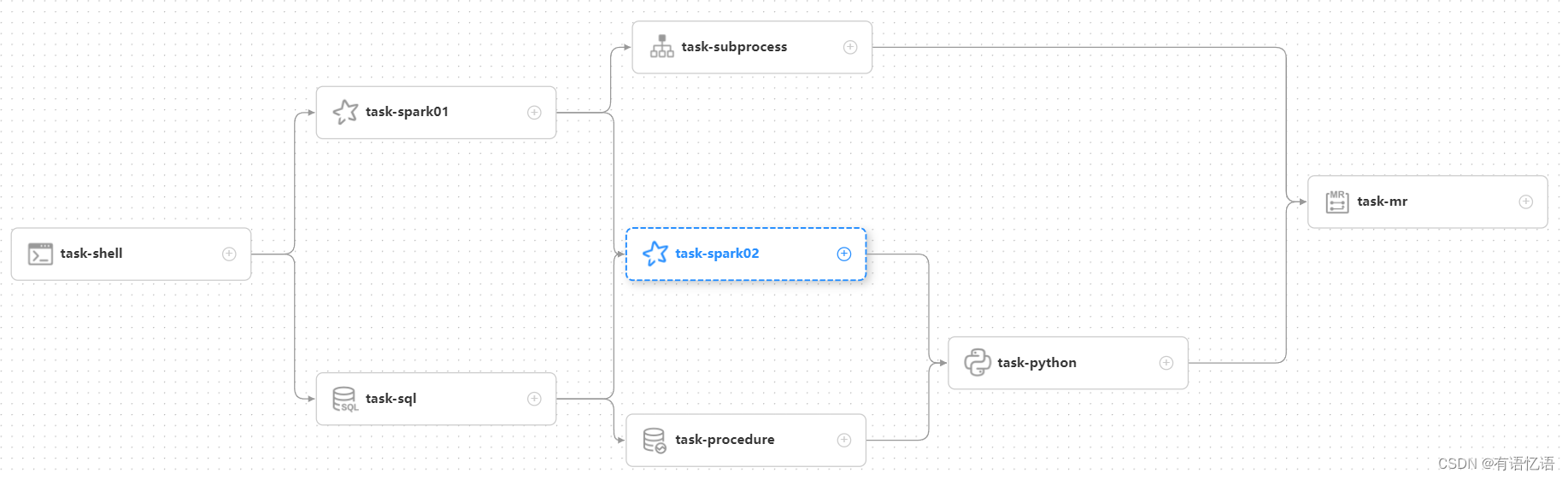
流程定义:通过拖拽任务节点并建立任务节点的关联所形成的可视化DAG
流程实例:流程实例是流程定义的实例化,可以通过手动启动或定时调度生成。每运行一次流程定义,产生一个流程实例
任务实例:任务实例是流程定义中任务节点的实例化,标识着某个具体的任务
任务类型:目前支持有 SHELL、SQL、SUB_PROCESS(子流程)、PROCEDURE、MR、SPARK、PYTHON、DEPENDENT(依赖),同时计划支持动态插件扩展,注意:其中 SUB_PROCESS类型的任务需要关联另外一个流程定义,被关联的流程定义是可以单独启动执行的
调度方式:系统支持基于 cron 表达式的定时调度和手动调度。命令类型支持:启动工作流、从当前节点开始执行、恢复被容错的工作流、恢复暂停流程、从失败节点开始执行、补数、定时、重跑、暂停、停止、恢复等待线程。 其中 恢复被容错的工作流 和 恢复等待线程 两种命令类型是由调度内部控制使用,外部无法调用
定时调度:系统采用 quartz 分布式调度器,并同时支持cron表达式可视化的生成
依赖:系统不单单支持 DAG 简单的前驱和后继节点之间的依赖,同时还提供任务依赖节点,支持流程间的自定义任务依赖
优先级 :支持流程实例和任务实例的优先级,如果流程实例和任务实例的优先级不设置,则默认是先进先出
邮件告警:支持 SQL任务 查询结果邮件发送,流程实例运行结果邮件告警及容错告警通知
失败策略:对于并行运行的任务,如果有任务失败,提供两种失败策略处理方式,继续是指不管并行运行任务的状态,直到流程失败结束。结束是指一旦发现失败任务,则同时Kill掉正在运行的并行任务,流程失败结束
补数:补历史数据,支持区间并行和串行两种补数方式,其日期选择方式包括日期范围和日期枚举两种
模块介绍(核心架构)
dolphinscheduler-master master模块,提供工作流管理和编排服务。
dolphinscheduler-worker worker模块,提供任务执行管理服务。
dolphinscheduler-alert 告警模块,提供 AlertServer 服务。
dolphinscheduler-api web应用模块,提供 ApiServer 服务。
dolphinscheduler-common 通用的常量枚举、工具类、数据结构或者基类
dolphinscheduler-dao 提供数据库访问等操作。
dolphinscheduler-remote 基于 netty 的客户端、服务端
dolphinscheduler-service service模块,包含Quartz、Zookeeper、日志客户端访问服务,便于server模块和api模块调用
dolphinscheduler-ui 前端模块
二、快速上手(就是使用教程和最简单的安装方式)
2.1、使用教程
直接看链接也可以:https://dolphinscheduler.apache.org/zh-cn/docs/3.2.0/guide/start/quick-start
设置 Dolphinscheduler
在继续之前,您必须先安装并启动 dolphinscheduler。 对于初学者,我们建议设置 dolphionscheduler 与官方 Docker image 或 standalone server。
构建您的第一个工作流程
您可以使用默认用户名/密码 http://localhost:12345/dolphinscheduler/ui 登录 dolphinscheduler 是“admin/dolphinscheduler123”。
创建租户
Tenant是使用DolphinScheduler时绕不开的一个概念,所以先简单介绍一下tenant的概念。
登录 DolphinScheduler 名为 admin 的帐户在 dolphinscheduler 中称为 user。 为了更好的控制系统资源,DolphinScheduler引入了概念租户,用于执行任务。
简述如下:
用户:登录web UI,在web UI中进行所有操作,包括工作流管理和租户创建。
Tenant:任务的实际执行者,A Linux user for DolphinScheduler worker。
我们可以在 DolphinScheduler Security -> Tenant Manage 页面创建租户。
注意:如果没有关联租户,则会使用默认租户,默认租户为default,会使用程序启动用户执行任务。
将租户分配给用户
正如我们上面在创建租户中谈到的,用户只能运行任务除非用户被分配给租户。
我们可以在 DolphinScheduler 的“安全 -> 用户管理”页面中将租户分配给特定用户。
在我们创建一个租户并将其分配给一个用户之后,我们可以开始创建一个 DolphinScheduler 中的简单工作流程。
创建项目
但是在 DolphinScheduler 中,所有的工作流都必须属于一个项目,所以我们需要首先创建一个项目。
我们可以通过单击在 DolphinScheduler Project 页面中创建一个项目 “创建项目” 按钮。
创建工作流
现在我们可以为项目“tutorial”创建一个工作流程。 点击我们刚刚创建的项目,转到“工作流定义”页面,单击“创建工作流”按钮,我们将重定向到工作流详细信息页面。
创建任务
我们可以使用鼠标从工作流画布的工具栏中拖动要创建的任务。 在这种情况下,我们创建一个 Shell 任务。 输入任务的必要信息,对于这个简单的工作流程 我们只需将属性“节点名称”填充为“脚本”即可。之后,我们可以单击“保存”按钮将任务保存到工作流中。 我们创建另一个任务使用相同的方式。
设置任务依赖
因此,我们有两个具有不同名称和命令的不同任务在工作流中运行。 这当前工作流中唯一缺少的是任务依赖性。 我们可以使用添加依赖,鼠标将箭头从上游任务拖到下游 然后松开鼠标。您可以看到从上游创建了两个任务之间带有箭头的链接任务交给下游一个。 最后,我们可以点击右上角的“保存”按钮保存工作流,不要忘记填写工作流名称。
运行工作流
全部完成后,我们可以通过单击“在线”然后单击“运行”按钮来运行工作流工作流列表。 如果您想查看工作流实例,只需转到 “工作流实例” 页面,可以看到工作流实例正在运行,状态为Executing。
查看日志
如需查看任务日志,请从工作流实例中点击工作流实例列表,然后找到要查看日志的任务,右击鼠标选择View Log 从上下文对话框中,您可以看到任务的详细日志。
您可以在任务中打印 Hello DolphinScheduler 和 Ending… 这和我们一样定义 在创建任务中。
你刚刚完成了 DolphinScheduler 的第一个教程,你现在可以运行一些简单的工作流在 DolphinScheduler 中,恭喜!
2.2、Docker 快速使用教程
此部分忽略,有需要可以去官网查看,链接如下:
https://dolphinscheduler.apache.org/zh-cn/docs/3.2.0/guide/start/docker
三、部署指南
DolphinScheduler有单机部署、伪集群部署、集群部署、容器部署,还有集成部署,但是我们生成环境一般都是部署集群模式,因此我们这里只写集群模式了,官网链接如下:
https://dolphinscheduler.apache.org/zh-cn/docs/3.2.0/guide/installation/cluster
3.1、前置准备工作
1、分布式部署 DolphinScheduler 需要有外部软件的支持
JDK:下载JDK (1.8+),安装并配置 JAVA_HOME 环境变量,并将其下的 bin 目录追加到 PATH 环境变量中。如果你的环境中已存在,可以跳过这步。
二进制包:在下载页面下载 DolphinScheduler 二进制包
数据库:PostgreSQL (8.2.15+) 或者 MySQL (5.7+),两者任选其一即可,如 MySQL 则需要 JDBC Driver 8.0.16
注册中心:ZooKeeper (3.8.0+),下载地址
进程树分析
macOS 安装pstree
Fedora/Red/Hat/CentOS/Ubuntu/Debian 安装psmisc
注意: DolphinScheduler 本身不依赖 Hadoop、Hive、Spark,但如果你运行的任务需要依赖他们,就需要有对应的环境支持
2、准备 DolphinScheduler 启动环境
2.1、配置用户免密及权限
创建部署用户,并且一定要配置 sudo 免密。以创建 dolphinscheduler 用户为例
# 创建用户需使用 root 登录
useradd dolphinscheduler
# 添加密码
echo "dolphinscheduler" | passwd --stdin dolphinscheduler
# 配置 sudo 免密
sed -i '$adolphinscheduler ALL=(ALL) NOPASSWD: NOPASSWD: ALL' /etc/sudoers
sed -i 's/Defaults requirett/#Defaults requirett/g' /etc/sudoers
# 修改目录权限,使得部署用户对二进制包解压后的 apache-dolphinscheduler-*-bin 目录有操作权限
chown -R dolphinscheduler:dolphinscheduler apache-dolphinscheduler-*-bin
chmod -R 755 apache-dolphinscheduler-*-bin
注意:
因为任务执行服务是以 sudo -u {linux-user} 切换不同 linux 用户的方式来实现多租户运行作业,所以部署用户需要有 sudo 权限,而且是免密的。初学习者不理解的话,完全可以暂时忽略这一点
如果发现 /etc/sudoers 文件中有 “Defaults requirett” 这行,也请注释掉
2.2、配置机器 SSH 免密登陆
由于安装的时候需要向不同机器发送资源,所以要求各台机器间能实现 SSH 免密登陆。配置免密登陆的步骤如下
su dolphinscheduler
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
注意: 配置完成后,可以通过运行命令 ssh localhost 判断是否成功,如果不需要输入密码就能 ssh 登陆则证明成功
2.3、启动 zookeeper
进入 zookeeper 的安装目录,将 zoo_sample.cfg 配置文件复制到 conf/zoo.cfg,并将 conf/zoo.cfg 中 dataDir 中的值改成 dataDir=./tmp/zookeeper
# 启动 zookeeper
./bin/zkServer.sh start
2.4、修改相关配置
完成基础环境的准备后,需要根据你的机器环境修改配置文件。配置文件可以在目录 bin/env 中找到,他们分别是 并命名为 install_env.sh 和 dolphinscheduler_env.sh。
1、修改 install_env.sh 文件
文件 install_env.sh 描述了哪些机器将被安装 DolphinScheduler 以及每台机器对应安装哪些服务。您可以在路径 bin/env/install_env.sh 中找到此文件,可通过以下方式更改 env 变量,export <ENV_NAME>=,配置详情如下。
修改相关配置
这个是与伪集群部署差异较大的一步,因为部署脚本会通过 scp 的方式将安装需要的资源传输到各个机器上,所以这一步我们仅需要修改运行install.sh脚本的所在机器的配置即可。配置文件在路径在bin/env/install_env.sh下,此处我们仅需修改INSTALL MACHINE,DolphinScheduler ENV、Database、Registry Server与伪集群部署保持一致,下面对必须修改参数进行说明
# ---------------------------------------------------------
# INSTALL MACHINE
# ---------------------------------------------------------
# 需要配置master、worker、API server,所在服务器的IP均为机器IP或者localhost
# 如果是配置hostname的话,需要保证机器间可以通过hostname相互链接
# 如下图所示,部署 DolphinScheduler 机器的 hostname 为 ds1,ds2,ds3,ds4,ds5,其中 ds1,ds2 安装 master 服务,ds3,ds4,ds5安装 worker 服务,alert server安装在ds4中,api server 安装在ds5中
ips="ds1,ds2,ds3,ds4,ds5"
masters="ds1,ds2"
workers="ds3:default,ds4:default,ds5:default"
alertServer="ds4"
apiServers="ds5"
# DolphinScheduler installation path, it will auto-create if not exists
installPath=~/dolphinscheduler
# Deploy user, use the user you create in section **Configure machine SSH password-free login**
deployUser="dolphinscheduler"
2、修改 dolphinscheduler_env.sh 文件
文件 ./bin/env/dolphinscheduler_env.sh 描述了下列配置:
DolphinScheduler 的数据库配置,详细配置方法见[初始化数据库]
一些任务类型外部依赖路径或库文件,如 JAVA_HOME 和 SPARK_HOME都是在这里定义的
如果您不使用某些任务类型,您可以忽略任务外部依赖项,但您必须根据您的环境更改 JAVA_HOME、注册中心和数据库相关配置。
# JAVA_HOME, will use it to start DolphinScheduler server
export JAVA_HOME=${JAVA_HOME:-/opt/soft/java}
# Database related configuration, set database type, username and password
export DATABASE=${DATABASE:-postgresql}
export SPRING_PROFILES_ACTIVE=${DATABASE}
export SPRING_DATASOURCE_URL="jdbc:postgresql://127.0.0.1:5432/dolphinscheduler"
export SPRING_DATASOURCE_USERNAME={user}
export SPRING_DATASOURCE_PASSWORD={password}
# DolphinScheduler server related configuration
export SPRING_CACHE_TYPE=${SPRING_CACHE_TYPE:-none}
export SPRING_JACKSON_TIME_ZONE=${SPRING_JACKSON_TIME_ZONE:-UTC}
export MASTER_FETCH_COMMAND_NUM=${MASTER_FETCH_COMMAND_NUM:-10}
# Registry center configuration, determines the type and link of the registry center
export REGISTRY_TYPE=${REGISTRY_TYPE:-zookeeper}
export REGISTRY_ZOOKEEPER_CONNECT_STRING=${REGISTRY_ZOOKEEPER_CONNECT_STRING:-localhost:2181}
# Tasks related configurations, need to change the configuration if you use the related tasks.
export HADOOP_HOME=${HADOOP_HOME:-/opt/soft/hadoop}
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-/opt/soft/hadoop/etc/hadoop}
export SPARK_HOME=${SPARK_HOME:-/opt/soft/spark}
export PYTHON_LAUNCHER=${PYTHON_LAUNCHER:-/opt/soft/python}
export HIVE_HOME=${HIVE_HOME:-/opt/soft/hive}
export FLINK_HOME=${FLINK_HOME:-/opt/soft/flink}
export DATAX_LAUNCHER=${DATAX_LAUNCHER:-/opt/soft/datax/bin/python3}
export PATH=$HADOOP_HOME/bin:$SPARK_HOME/bin:$PYTHON_LAUNCHER:$JAVA_HOME/bin:$HIVE_HOME/bin:$FLINK_HOME/bin:$DATAX_LAUNCHER:$PATH
3、初始化数据库
请参考 [数据源配置] 伪分布式/分布式安装初始化数据库 创建并初始化数据库
https://gitee.com/dolphinscheduler/DolphinScheduler/blob/dev/docs/docs/zh/guide/howto/datasource-setting.md#https://gitee.com/link?target=https%3A%2F%2Fdownloads.MySQL.com%2Farchives%2Fc-j%2F
3.1、伪分布式/分布式安装初始化数据库(给的账号都要具有建库建表权限,且连接信息需要配置字符集?useUnicode=true&characterEncoding=UTF-8&useSSL=false 要不然会报错)
DolphinScheduler 元数据存储在关系型数据库中,目前支持 PostgreSQL 和 MySQL。下面分别介绍如何使用 MySQL 和 PostgresQL 初始化数据库。
如果使用 MySQL 需要手动下载 mysql-connector-java 驱动 (8.0.16) 并移动到 DolphinScheduler 的每个模块的 libs 目录下,其中包括 api-server/libs 和 alert-server/libs 和 master-server/libs 和 worker-server/libs 和 tools/libs。
对于mysql 5.6 / 5.7:
mysql -uroot -p
mysql> CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
# 修改 {user} 和 {password} 为你希望的用户名和密码
mysql> GRANT ALL PRIVILEGES ON dolphinscheduler.* TO '{user}'@'%' IDENTIFIED BY '{password}';
mysql> GRANT ALL PRIVILEGES ON dolphinscheduler.* TO '{user}'@'localhost' IDENTIFIED BY '{password}';
mysql> flush privileges;
对于mysql 8:
mysql -uroot -p
mysql> CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
# 修改 {user} 和 {password} 为你希望的用户名和密码
mysql> CREATE USER '{user}'@'%' IDENTIFIED BY '{password}';
mysql> GRANT ALL PRIVILEGES ON dolphinscheduler.* TO '{user}'@'%';
mysql> CREATE USER '{user}'@'localhost' IDENTIFIED BY '{password}';
mysql> GRANT ALL PRIVILEGES ON dolphinscheduler.* TO '{user}'@'localhost';
mysql> FLUSH PRIVILEGES;
对于 PostgreSQL:
# 采用命令行工具登陆 PostgreSQL
psql
# 创建数据库
postgres=# CREATE DATABASE dolphinscheduler;
# 修改 {user} 和 {password} 为你希望的用户名和密码
postgres=# CREATE USER {user} PASSWORD {password};
postgres=# ALTER DATABASE dolphinscheduler OWNER TO {user};
# 退出 PostgreSQL
postgres=#\q
# 在终端执行如下命令,向配置文件新增登陆权限,并重载 PostgreSQL 配置,替换 {ip} 为对应的 DS 集群服务器 IP 地址段
echo "host dolphinscheduler {user} {ip} md5" >> $PGDATA/pg_hba.conf
pg_ctl reload
然后设置以下环境变量,将username和password改成你在上一步中设置的用户名{user}和密码{password}
对于 MySQL:
# for mysql
export DATABASE=${DATABASE:-mysql}
export SPRING_PROFILES_ACTIVE=${DATABASE}
export SPRING_DATASOURCE_URL="jdbc:mysql://127.0.0.1:3306/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8&useSSL=false"
export SPRING_DATASOURCE_USERNAME={user}
export SPRING_DATASOURCE_PASSWORD={password}
对于 PostgreSQL:
# for postgresql
export DATABASE=${DATABASE:-postgresql}
export SPRING_PROFILES_ACTIVE=${DATABASE}
export SPRING_DATASOURCE_URL="jdbc:postgresql://127.0.0.1:5432/dolphinscheduler"
export SPRING_DATASOURCE_USERNAME={user}
export SPRING_DATASOURCE_PASSWORD={password}
完成上述步骤后,您已经为 DolphinScheduler 创建一个新数据库,现在你可以通过快速的 Shell 脚本来初始化数据库
bash tools/bin/upgrade-schema.sh
4、启动 DolphinScheduler
使用上面创建的部署用户运行以下命令完成部署,部署后的运行日志将存放在 logs 文件夹内
bash ./bin/install.sh
注意: 第一次部署的话,可能出现 5 次sh: bin/dolphinscheduler-daemon.sh: No such file or directory相关信息,此为非重要信息直接忽略即可
5、登录 DolphinScheduler
浏览器访问地址 http://localhost:12345/dolphinscheduler/ui 即可登录系统 UI。默认的用户名和密码是 admin/dolphinscheduler123
6、启停服务
# 一键停止集群所有服务
bash ./bin/stop-all.sh
# 一键开启集群所有服务
bash ./bin/start-all.sh
# 启停 Master
bash ./bin/dolphinscheduler-daemon.sh stop master-server
bash ./bin/dolphinscheduler-daemon.sh start master-server
# 启停 Worker
bash ./bin/dolphinscheduler-daemon.sh start worker-server
bash ./bin/dolphinscheduler-daemon.sh stop worker-server
# 启停 Api
bash ./bin/dolphinscheduler-daemon.sh start api-server
bash ./bin/dolphinscheduler-daemon.sh stop api-server
# 启停 Alert
bash ./bin/dolphinscheduler-daemon.sh start alert-server
bash ./bin/dolphinscheduler-daemon.sh stop alert-server
注意 1:: 每个服务在路径 /conf/dolphinscheduler_env.sh 中都有 dolphinscheduler_env.sh 文件,这是可以为微 服务需求提供便利。意味着您可以基于不同的环境变量来启动各个服务,只需要在对应服务中配置 /conf/dolphinscheduler_env.sh 然后通过 /bin/start.sh 命令启动即可。但是如果您使用命令 /bin/dolphinscheduler-daemon.sh start 启动服务器,它将会用文件 bin/env/dolphinscheduler_env.sh 覆盖 /conf/dolphinscheduler_env.sh 然后启动服务,目的是为了减少用户修改配置的成本.
四、功能介绍
上链接,看链接吧:
https://dolphinscheduler.apache.org/zh-cn/docs/3.2.0/%E5%8A%9F%E8%83%BD%E4%BB%8B%E7%BB%8D_menu