1.自注意力机制与卷积结合
论文:On the Integration of Self-Attention and Convolution

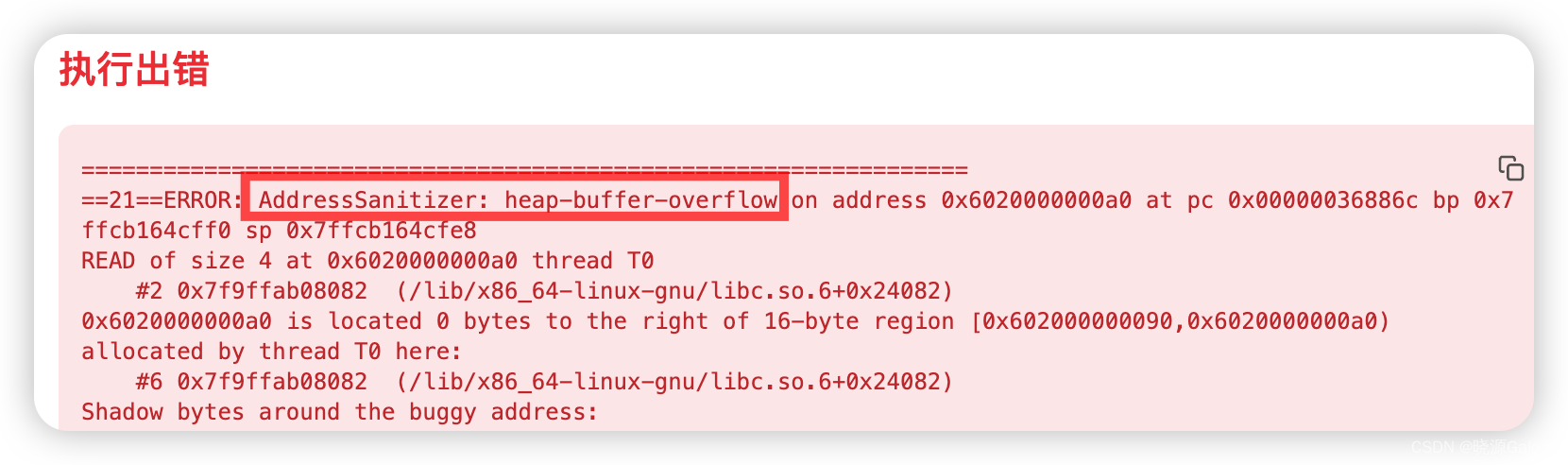
1:卷积可以接受比较大的图片的,但自注意力机制如果图片特别大的话,运算规模会特别大,即上图中右边(卷积)会算得比较快,左边(自注意力机制)会算得比较慢,所以我们要想些办法让自注意力机制规模小一点,本篇文章就只让qkv计算部分区域,而不是整个全局图片了。
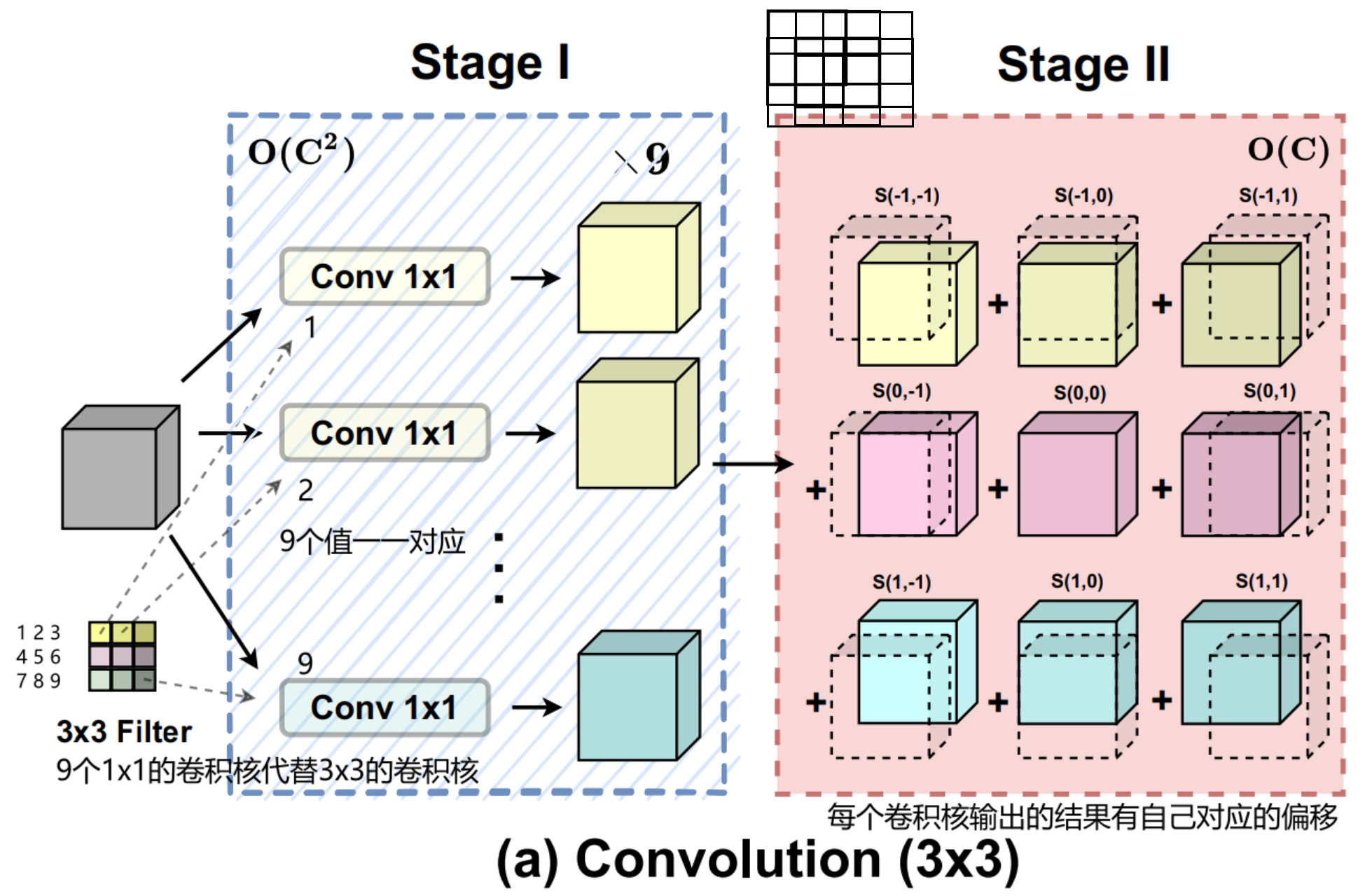
2:自注意力机制中的qkv与卷积中的卷积核(比如说3x3的卷积核)能否一起得到?额,好像两者不是一类东西,但如果qkv用1x1的卷积核话,似乎有可能..
但是1x1的卷积核与3x3的卷积核似乎很难配套,有没有可能将3x3的卷积核用9个1x1的卷积核去替代呢?那既然两者(自注意力机制与卷积)都用到1x1的卷积,不妨两者共享1x1的卷积?
论文解读:
论文解读:On the Integration of Self-Attention and Convolution-CSDN博客
2.新的坐标注意力机制Coordinate Attention
论文:Coordinate Attention for Efficient Mobile Network Design(CVPR2021)
最近关于mobile network设计的研究已经证明了通道注意(例如,the Squeeze-and-Excitation attention)对于提高模型性能的显着有效性,但它们通常忽略了位置信息,而位置信息对于生成空间选择性注意图非常重要。在本文中,我们提出了一种新的移动网络注意机制,将位置信息嵌入到通道注意中,我们称之为“坐标注意(coordinate attention)”。与通过二维全局池化将特征张量转换为单个特征向量的通道注意不同,坐标注意将通道注意分解为两个一维特征编码过程,分别沿着两个空间方向聚合特征。这样可以在一个空间方向上捕获远程依赖关系,同时在另一个空间方向上保持精确的位置信息。然后将得到的特征图分别编码为一对方向感知和位置敏感的注意图,它们可以互补地应用于输入特征图,以增强感兴趣对象的表示。

论文解读:论文解读:Coordinate Attention for Efficient Mobile Network Design(CVPR2021)-CSDN博客
3. 更好的下采样操作SPD
论文:No More Strided Convolutions or Pooling:A New CNN Building Block for Low-ResolutionImages and Small Objects
之前常规的操作都是通过stride和pooling这些下采样操作,但是这些操作都会或多或少丢失图像的信息,所以这不适用于具有低分辨率图像和小物体的更困难的任务上。像池化选择maxpooling或者是averagepooling、卷积的步长(太大的话会丢失信息)都是很头疼的问题,为此设计SPD模型。

论文解读:论文解读:A New CNN Building Block for Low-ResolutionImages and Small Objects-CSDN博客