作者:i阿极
作者简介:数据分析领域优质创作者、多项比赛获奖者:博主个人首页
😊😊😊如果觉得文章不错或能帮助到你学习,可以点赞👍收藏📁评论📒+关注哦!👍👍👍
📜📜📜如果有小伙伴需要数据集和学习交流,文章下方有交流学习区!一起学习进步!💪
大家好,我i阿极。喜欢本专栏的小伙伴,请多多支持
| 专栏案例:机器学习案例 |
|---|
| 机器学习(一):线性回归之最小二乘法 |
| 机器学习(二):线性回归之梯度下降法 |
| 机器学习(三):基于线性回归对波士顿房价预测 |
| 机器学习(四):基于KNN算法对鸢尾花类别进行分类预测 |
| 机器学习(五):基于KNN模型对高炉发电量进行回归预测分析 |
| 机器学习(六):基于高斯贝叶斯对面部皮肤进行预测分析 |
| 机器学习(七):基于多项式贝叶斯对蘑菇毒性分类预测分析 |
| 机器学习(八):基于PCA对人脸识别数据降维并建立KNN模型检验 |
| 机器学习(十四):基于逻辑回归对超市销售活动预测分析 |
| 机器学习(十五):基于神经网络对用户评论情感分析预测 |
| 机器学习(十六):线性回归分析女性身高与体重之间的关系 |
| 机器学习(十七):基于支持向量机(SVM)进行人脸识别预测 |
| 机器学习(十八):基于逻辑回归对优惠券使用情况预测分析 |
| 机器学习(十九):基于逻辑回归对某银行客户违约预测分析 |
| 机器学习(二十):LightGBM算法原理(附案例实战) |
| 机器学习(二十一):基于朴素贝叶斯对花瓣花萼的宽度和长度分类预测 |
| 机器学习(二十二):基于逻辑回归(Logistic Regression)对股票客户流失预测分析 |
文章目录
- 1、前言
- 2、数据说明
- 3、种类分布及其在不同岛屿上的分布
- 4、企鹅身体测量特征的相关性分析
- 5、种类特征差异
- 6、性别差异分析
- 7、岛屿影响分析
- 8、喙长与鳍状肢长度(按岛屿区分)
- 9、预测模型
- 9.1决策树
- 9.2随机森林
- 9.3层次聚类分析
- 总结
1、前言
随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。Palmer Penguins 数据集是近年来在数据科学和机器学习领域受到关注的一个数据集,经常被用作鸢尾花数据集的一个替代品。
数据集包含了对南极洲不同地区生活的企鹅种群的研究数据,主要用于数据探索和可视化,以及分类任务。
2、数据说明
| 英文字段 | 中文字段 | 描述 |
|---|---|---|
| species | 种类 | Gentoo:巴布亚企鹅(也叫金图企鹅);Adelie:阿德利企鹅;Chinstrap:帽带企鹅 |
| culmen_length_mm | 喙长(毫米) | 喙的长度(毫米) |
| culmen_depth_mm | 喙深(毫米) | 喙的深度(毫米) |
| flipper_length_mm | 鳍状肢长度(毫米) | 鳍状肢的长度(毫米) |
| body_mass_g | 体重(克) | 体重(克) |
| island | 岛屿名称 | 梦想岛、托尔格森岛、比斯科岛 |
| sex | 性别 | 企鹅的性别 |
以上为简化后的数据字段
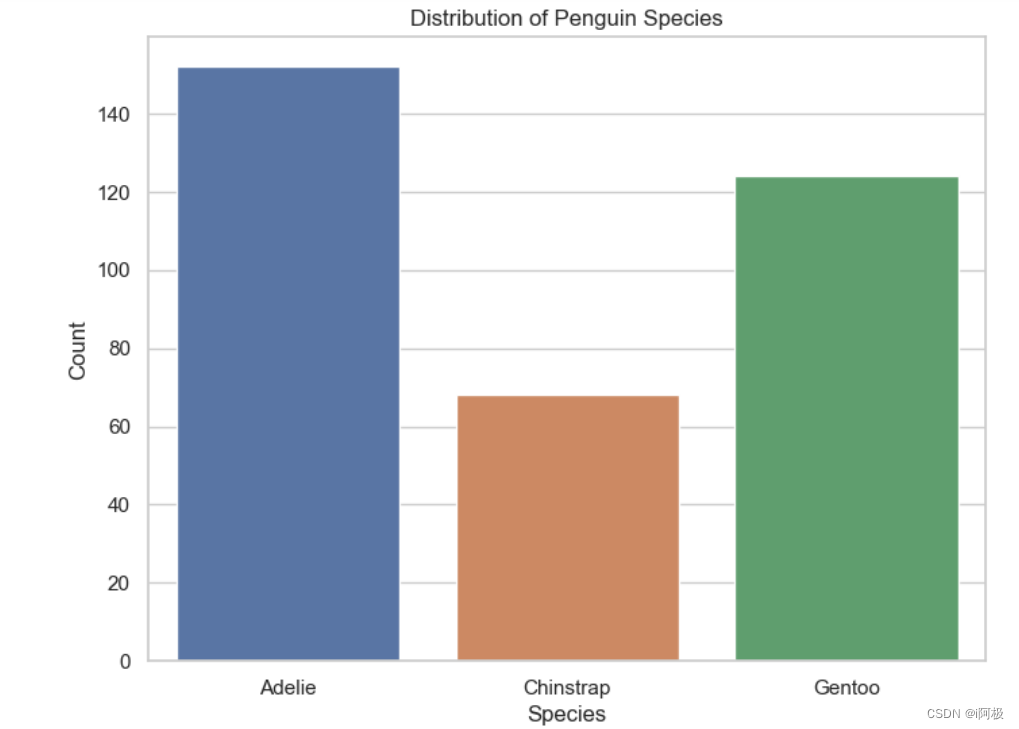
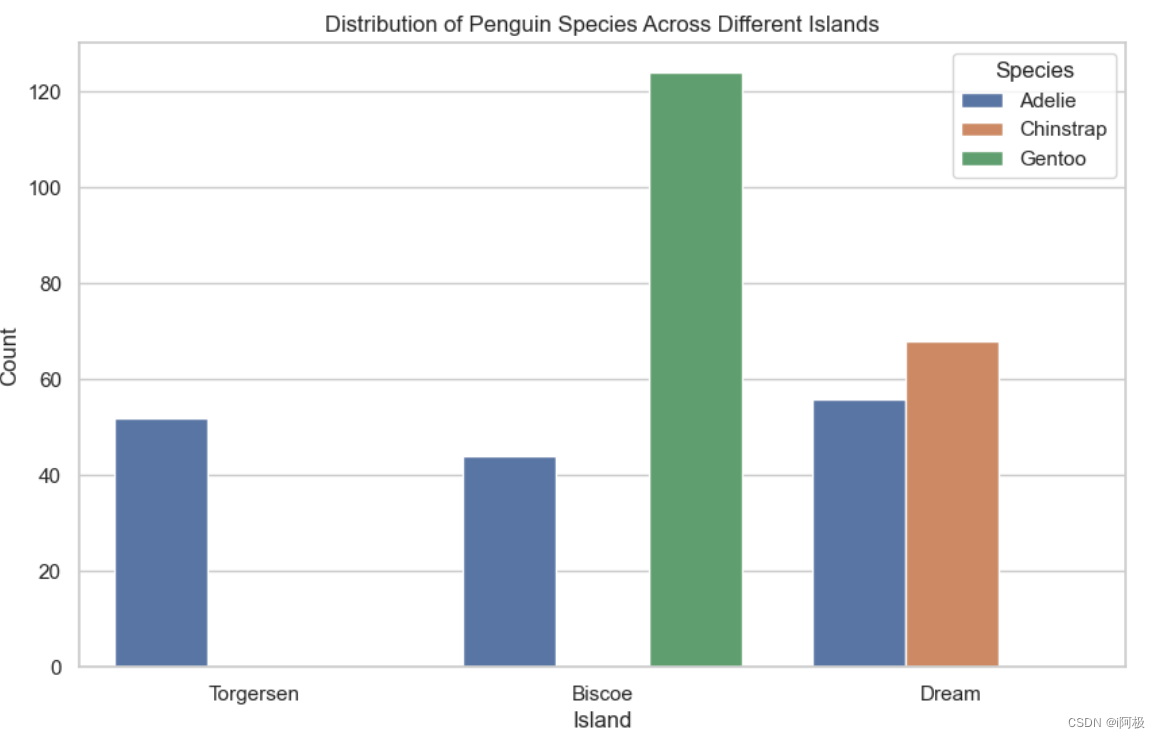
3、种类分布及其在不同岛屿上的分布
通过 Pandas 读取企鹅尺寸数据集 penguins_size.csv。使用 Seaborn 设置图表的美观风格为白色网格。利用 Seaborn 绘制条形图展示不同种类企鹅的分布情况。绘制不同岛屿上企鹅种类分布的条形图,通过不同颜色的条形表示不同的企鹅种类,并添加图例说明。使用 Matplotlib 展示绘制的图表,包括设置图表的标题、横轴标签、纵轴标签等元素。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 加载数据
penguins_size_df = pd.read_csv(r'D:\model\帕尔默企鹅数据\penguins_size.csv')
# 设置图表的美观风格
sns.set(style="whitegrid")
# 绘制企鹅种类分布的条形图
plt.figure(figsize=(8, 6))
sns.countplot(data=penguins_size_df, x='species')
plt.title('Distribution of Penguin Species')
plt.xlabel('Species')
plt.ylabel('Count')
plt.show()
# 绘制不同岛屿上企鹅种类分布的条形图
plt.figure(figsize=(10, 6))
sns.countplot(data=penguins_size_df, x='island', hue='species')
plt.title('Distribution of Penguin Species Across Different Islands')
plt.xlabel('Island')
plt.ylabel('Count')
plt.legend(title='Species')
plt.show()
4、企鹅身体测量特征的相关性分析
通过 Pandas 计算选定特征(culmen_length_mm、culmen_depth_mm、flipper_length_mm、body_mass_g)的相关系数矩阵。利用 Seaborn 绘制相关性热图,通过颜色深浅表示不同特征之间的相关性强度。annot=True 参数用于在图中显示具体的相关系数数值,cmap=‘coolwarm’ 参数选择了颜色映射方案,fmt=“.2f” 参数控制显示的小数位数。使用 Matplotlib 展示绘制的相关性热图,并添加图表的标题。该可视化图表有助于直观地理解不同企鹅物理测量特征之间的相关性程度,深入分析数据集的关联性。
# 计算相关系数矩阵
correlation_matrix = penguins_size_df[['culmen_length_mm', 'culmen_depth_mm', 'flipper_length_mm', 'body_mass_g']].corr()
# 绘制相关性热图
plt.figure(figsize=(10, 8))
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', fmt=".2f")
plt.title('Correlation Matrix of Penguin Physical Measurements')
plt.show()
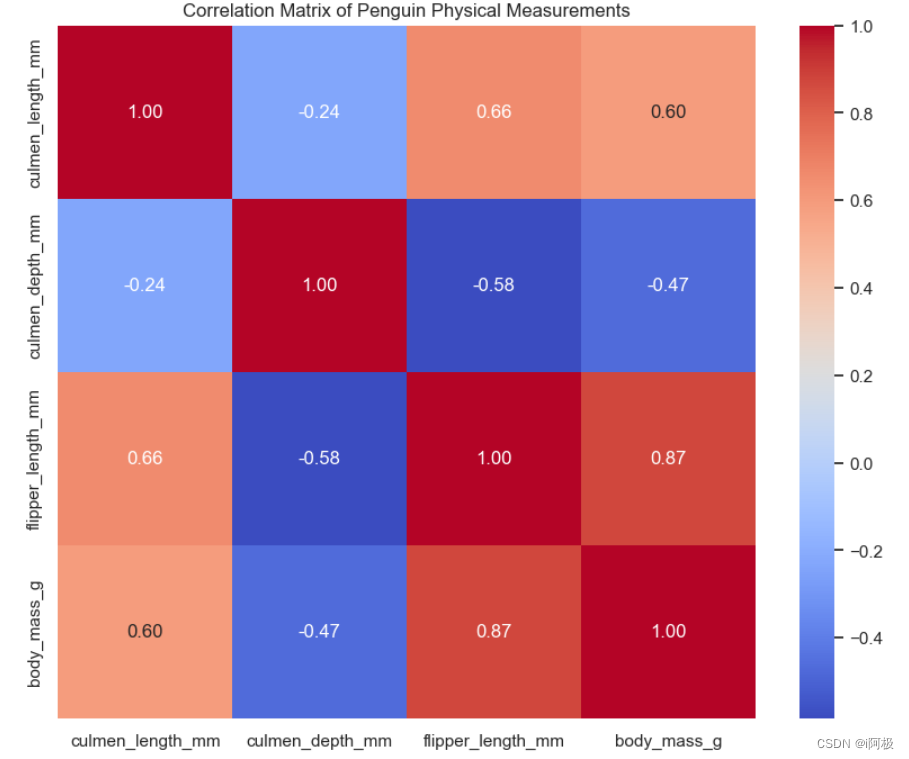
5、种类特征差异
加载企鹅物理测量数据集。设置整体图表布局为2x2的子图,总图表大小为(15, 12)。在每个子图中绘制不同物理测量特征(culmen_length_mm、culmen_depth_mm、flipper_length_mm、body_mass_g)的箱线图,通过不同种类企鹅进行分组。设置每个子图的标题、横轴标签、纵轴标签,以及总图表的标题。使用 plt.tight_layout(rect=[0, 0.03, 1, 0.95]) 调整布局,避免子图重叠。
该可视化图表展示了不同企鹅物理测量特征在不同种类企鹅间的分布差异,通过箱线图直观呈现了数据的分布范围、中位数和离群值等信息。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 加载数据
# penguins_size_df = pd.read_csv('penguins_size.csv')
# 设置整体图表布局
fig, axes = plt.subplots(2, 2, figsize=(15, 12))
fig.suptitle('Physical Measurement Differences Among Penguin Species', fontsize=16)
# 喙长的箱线图
sns.boxplot(ax=axes[0, 0], data=penguins_size_df, x='species', y='culmen_length_mm')
axes[0, 0].set_title('Culmen Length (mm)')
axes[0, 0].set_xlabel('Species')
axes[0, 0].set_ylabel('Culmen Length (mm)')
# 喙深的箱线图
sns.boxplot(ax=axes[0, 1], data=penguins_size_df, x='species', y='culmen_depth_mm')
axes[0, 1].set_title('Culmen Depth (mm)')
axes[0, 1].set_xlabel('Species')
axes[0, 1].set_ylabel('Culmen Depth (mm)')
# 鳍状肢长度的箱线图
sns.boxplot(ax=axes[1, 0], data=penguins_size_df, x='species', y='flipper_length_mm')
axes[1, 0].set_title('Flipper Length (mm)')
axes[1, 0].set_xlabel('Species')
axes[1, 0].set_ylabel('Flipper Length (mm)')
# 体重的箱线图
sns.boxplot(ax=axes[1, 1], data=penguins_size_df, x='species', y='body_mass_g')
axes[1, 1].set_title('Body Mass (g)')
axes[1, 1].set_xlabel('Species')
axes[1, 1].set_ylabel('Body Mass (g)')
plt.tight_layout(rect=[0, 0.03, 1, 0.95])
plt.show()
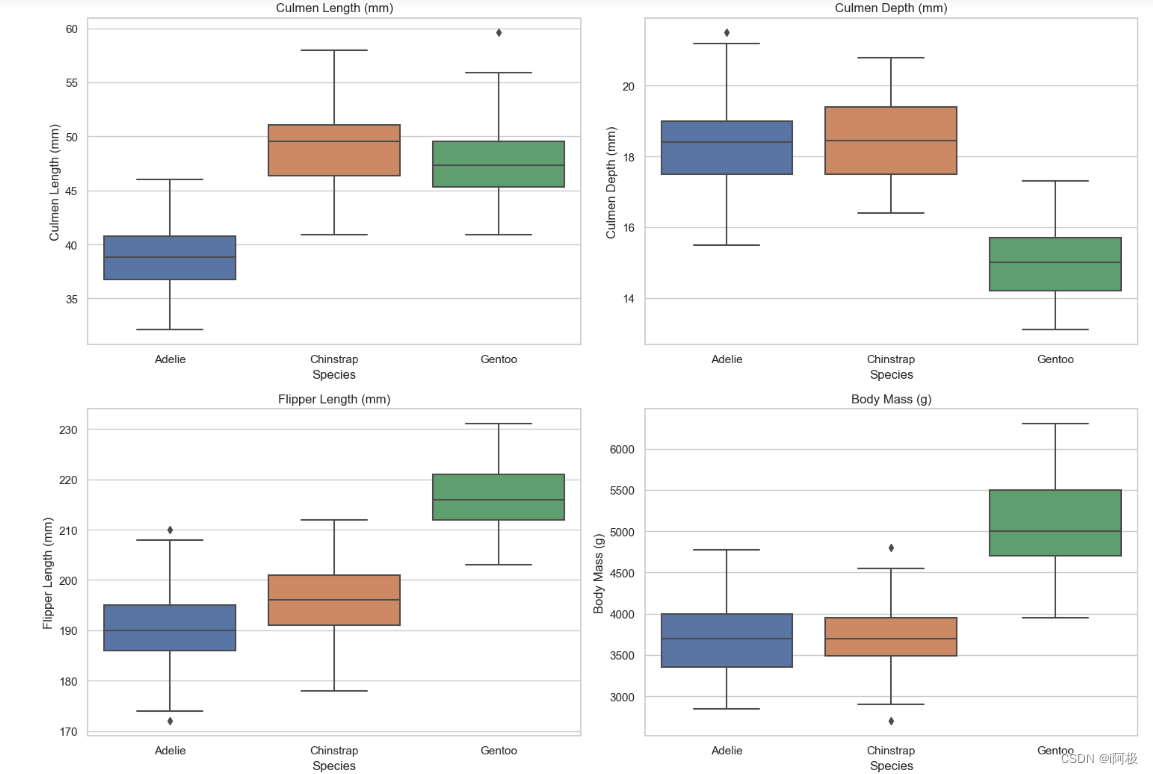
6、性别差异分析
加载企鹅物理测量数据集。设置整体图表布局为2x2的子图,总图表大小为(15, 12)。在每个子图中绘制不同物理测量特征(culmen_length_mm、culmen_depth_mm、flipper_length_mm、body_mass_g)的箱线图,通过不同性别进行分组。设置每个子图的标题、横轴标签、纵轴标签,以及总图表的标题。使用 plt.tight_layout(rect=[0, 0.03, 1, 0.95]) 调整布局,避免子图重叠。
该可视化图表展示了不同性别企鹅在不同物理测量特征上的分布差异,通过箱线图形象地呈现了性别间的数据分布范围、中位数和离群值等信息。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 加载数据
penguins_size_df = pd.read_csv('penguins_size.csv')
# 设置整体图表布局 - 性别差异
fig, axes = plt.subplots(2, 2, figsize=(15, 12))
fig.suptitle('Gender Differences in Penguin Physical Measurements', fontsize=16)
# 喙长的箱线图 - 性别
sns.boxplot(ax=axes[0, 0], data=penguins_size_df, x='sex', y='culmen_length_mm')
axes[0, 0].set_title('Culmen Length by Gender')
axes[0, 0].set_xlabel('Gender')
axes[0, 0].set_ylabel('Culmen Length (mm)')
# 喙深的箱线图 - 性别
sns.boxplot(ax=axes[0, 1], data=penguins_size_df, x='sex', y='culmen_depth_mm')
axes[0, 1].set_title('Culmen Depth by Gender')
axes[0, 1].set_xlabel('Gender')
axes[0, 1].set_ylabel('Culmen Depth (mm)')
# 鳍状肢长度的箱线图 - 性别
sns.boxplot(ax=axes[1, 0], data=penguins_size_df, x='sex', y='flipper_length_mm')
axes[1, 0].set_title('Flipper Length by Gender')
axes[1, 0].set_xlabel('Gender')
axes[1, 0].set_ylabel('Flipper Length (mm)')
# 体重的箱线图 - 性别
sns.boxplot(ax=axes[1, 1], data=penguins_size_df, x='sex', y='body_mass_g')
axes[1, 1].set_title('Body Mass by Gender')
axes[1, 1].set_xlabel('Gender')
axes[1, 1].set_ylabel('Body Mass (g)')
plt.tight_layout(rect=[0, 0.03, 1, 0.95])
plt.show()
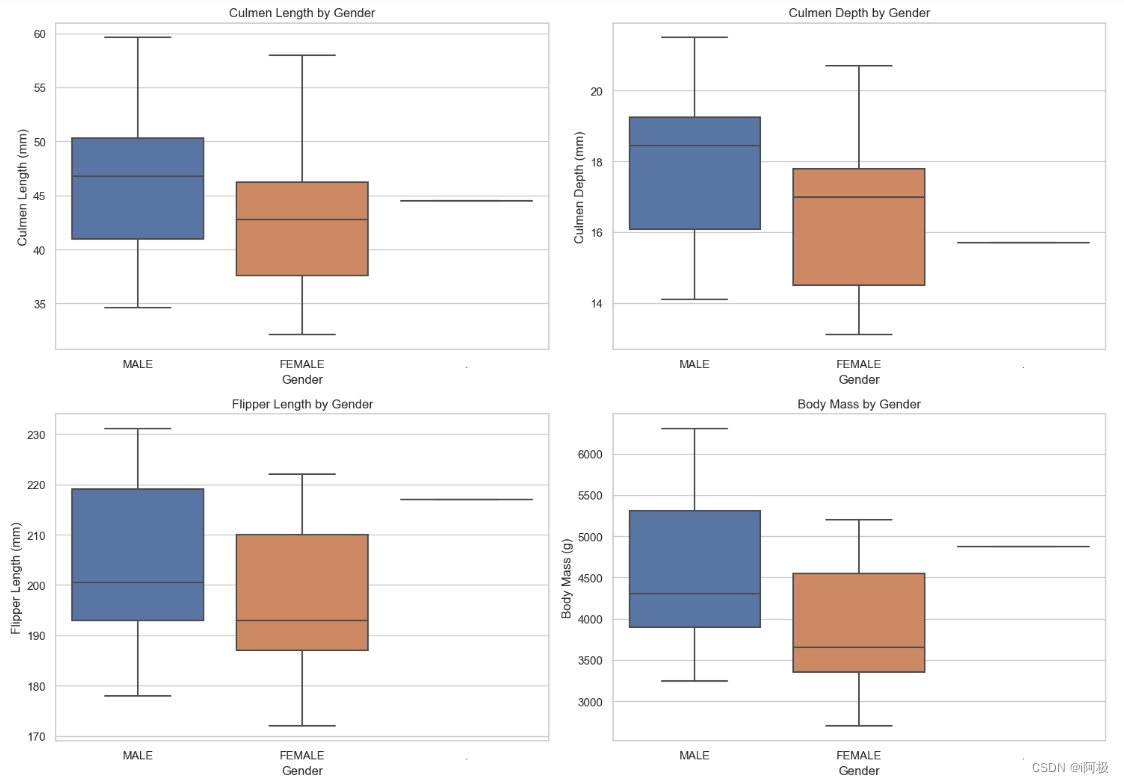
7、岛屿影响分析
设置整体图表布局为2x2的子图,总图表大小为(15, 12)。在每个子图中循环绘制不同物理测量特征(culmen_length_mm、culmen_depth_mm、flipper_length_mm、body_mass_g)的箱线图,通过不同岛屿进行分组。设置每个子图的标题、横轴标签、纵轴标签,以及总图表的标题。使用 plt.tight_layout(rect=[0, 0.03, 1, 0.95]) 调整布局,避免子图重叠。
该可视化图表展示了不同岛屿对于企鹅物理测量特征的影响,通过箱线图形象地呈现了数据分布范围、中位数和离群值等信息,使得观察者能够直观了解不同岛屿的差异。
设置整体图表布局 - 岛屿影响
fig, axes = plt.subplots(2, 2, figsize=(15, 12))
fig.suptitle('Influence of Island on Penguin Physical Measurements', fontsize=16)
# 调整每个身体测量特征的箱线图 - 岛屿
for i, feature in enumerate(['culmen_length_mm', 'culmen_depth_mm', 'flipper_length_mm', 'body_mass_g']):
ax = axes[i//2, i%2]
sns.boxplot(ax=ax, data=penguins_size_df, x='island', y=feature)
ax.set_title(feature.replace('_', ' ').title() + ' by Island')
ax.set_xlabel('Island')
ax.set_ylabel(feature.replace('_', ' ').title())
plt.tight_layout(rect=[0, 0.03, 1, 0.95])
plt.show()
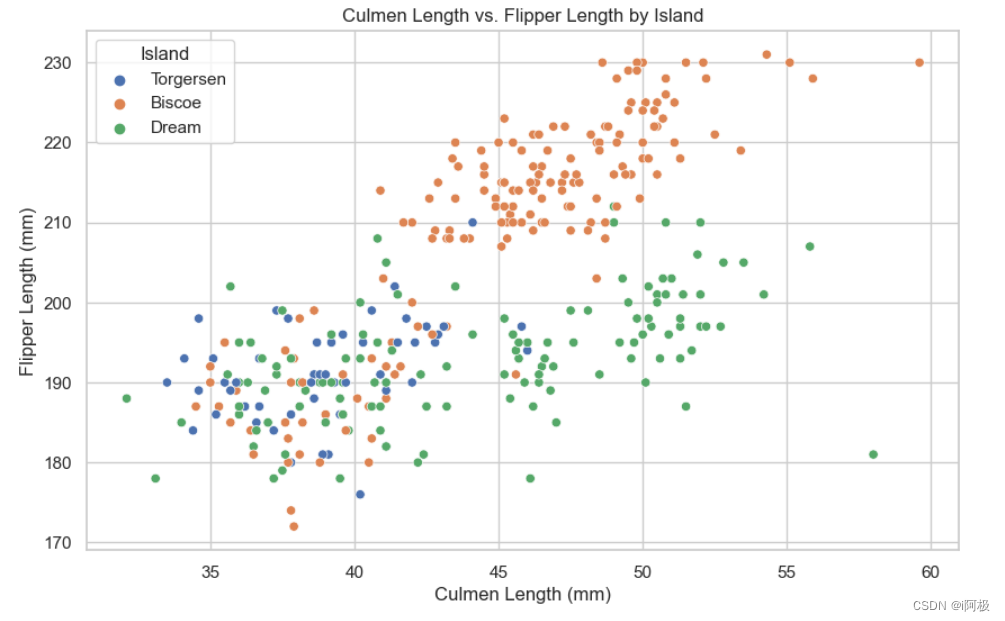
8、喙长与鳍状肢长度(按岛屿区分)
加载企鹅物理测量数据集。利用 Seaborn 绘制散点图,横轴表示喙长(culmen_length_mm),纵轴表示鳍状肢长度(flipper_length_mm),并根据岛屿进行颜色区分。设置图表的标题、横轴标签、纵轴标签,并添加图例说明不同岛屿的颜色。使用 plt.show() 显示图表。
该可视化图表通过散点图清晰展示了喙长与鳍状肢长度之间的关系,并通过颜色区分不同岛屿的数据点,有助于观察者直观地识别岛屿间的差异。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 加载数据
# penguins_size_df = pd.read_csv('penguins_size.csv')
# 绘制喙长与鳍状肢长度的散点图,并按岛屿区分颜色
plt.figure(figsize=(10, 6))
sns.scatterplot(data=penguins_size_df, x='culmen_length_mm', y='flipper_length_mm', hue='island')
plt.title('Culmen Length vs. Flipper Length by Island')
plt.xlabel('Culmen Length (mm)')
plt.ylabel('Flipper Length (mm)')
plt.legend(title='Island')
plt.show()
9、预测模型
9.1决策树
重新加载企鹅物理测量数据集。
数据准备:选择特征和目标变量。选择的特征包括 ‘culmen_length_mm’, ‘culmen_depth_mm’, ‘flipper_length_mm’, ‘body_mass_g’,目标变量为 ‘species’。数据处理:删除包含缺失值的行,并获取特征(X)和目标变量(y)。
数据分割:划分数据集为训练集和测试集,其中测试集占总数据的30%。使用决策树模型(DecisionTreeClassifier)进行训练,并使用训练好的模型进行测试集的预测。
模型评估:计算模型的准确度(accuracy_score)和分类报告(classification_report),并输出结果。
该代码展示了如何使用决策树模型对企鹅物理测量数据进行分类,并评估模型的性能。
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
import pandas as pd
# 重新加载数据
penguins_size_df = pd.read_csv('penguins_size.csv')
# 数据准备:选择特征和目标变量
feature_cols = ['culmen_length_mm', 'culmen_depth_mm', 'flipper_length_mm', 'body_mass_g']
# 修正数据处理:在删除缺失值时同时处理特征和目标变量
penguins_cleaned_df = penguins_size_df.dropna(subset=feature_cols + ['species'])
X = penguins_cleaned_df[feature_cols]
y = penguins_cleaned_df['species']
# 数据分割:划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 使用决策树模型
decision_tree = DecisionTreeClassifier(random_state=42)
decision_tree.fit(X_train, y_train)
# 预测测试集
y_pred_dt = decision_tree.predict(X_test)
# 模型评估
accuracy_dt = accuracy_score(y_test, y_pred_dt)
report_dt = classification_report(y_test, y_pred_dt)
print("Accuracy:", accuracy_dt)
print("Classification Report:\n", report_dt)
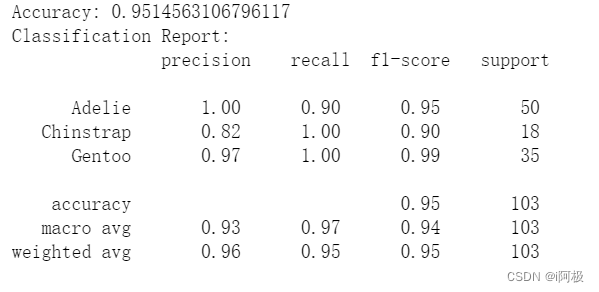
- Adelie 类别的预测准确度为 100%,Chinstrap 类别的召回率为 100%,Gentoo 类别的召回率为 100%。
- 加权平均准确度(weighted avg accuracy)为约 95%。
这说明决策树模型在这个数据集上表现良好,能够对企鹅的种类进行较为准确的分类。
9.2随机森林
重新加载企鹅物理测量数据集。
数据准备:选择特征和目标变量。选择的特征包括 ‘culmen_length_mm’, ‘culmen_depth_mm’, ‘flipper_length_mm’, ‘body_mass_g’,目标变量为 ‘species’。
数据处理:删除包含缺失值的行,并获取特征(X)和目标变量(y)。
数据分割:划分数据集为训练集和测试集,其中测试集占总数据的30%。
使用随机森林模型(RandomForestClassifier)进行训练,并使用训练好的模型进行测试集的预测。
模型评估:计算模型的准确度(accuracy_score)和分类报告(classification_report),并输出结果。
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
import pandas as pd
# 重新加载数据
# penguins_size_df = pd.read_csv('penguins_size.csv')
# 数据准备:选择特征和目标变量
feature_cols = ['culmen_length_mm', 'culmen_depth_mm', 'flipper_length_mm', 'body_mass_g']
# 修正数据处理:在删除缺失值时同时处理特征和目标变量
penguins_cleaned_df = penguins_size_df.dropna(subset=feature_cols + ['species'])
X = penguins_cleaned_df[feature_cols]
y = penguins_cleaned_df['species']
# 数据分割:划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 使用随机森林模型
random_forest = RandomForestClassifier(random_state=42)
random_forest.fit(X_train, y_train)
# 预测测试集
y_pred_rf = random_forest.predict(X_test)
# 模型评估
accuracy_rf = accuracy_score(y_test, y_pred_rf)
report_rf = classification_report(y_test, y_pred_rf)
print("Accuracy:", accuracy_rf)
print("Classification Report:\n", report_rf)
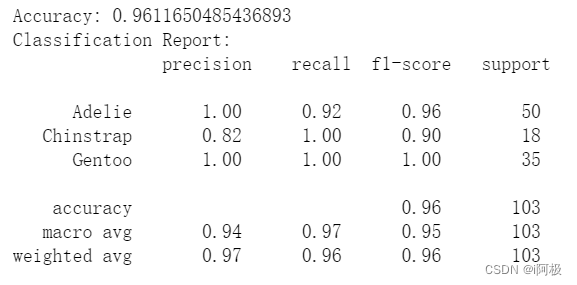
- Adelie 类别的预测准确度为 100%,Chinstrap 类别的召回率为 100%,Gentoo 类别的准确度、召回率和 F1-score 都为 100%。
- 加权平均准确度(weighted avg accuracy)为约 96%。
这说明随机森林模型在这个数据集上表现更好,相比于决策树模型,它对于企鹅的种类进行更为准确的分类。
9.3层次聚类分析
重新加载企鹅物理测量数据集。
选择用于聚类的特征:‘culmen_length_mm’, ‘culmen_depth_mm’, ‘flipper_length_mm’, ‘body_mass_g’。
在删除包含缺失值的行后,获取所选特征的数据。
使用 StandardScaler 对数据进行标准化,以确保每个特征具有相同的尺度。
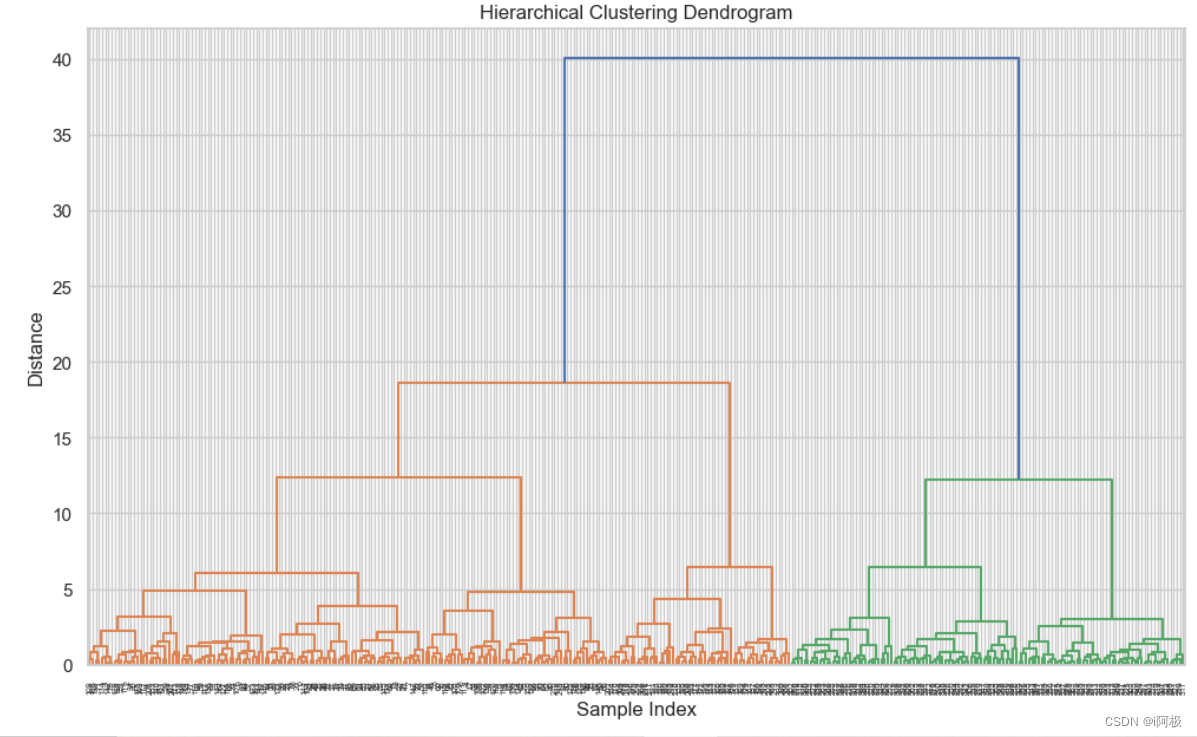
使用层次聚类方法(ward linkage)构建聚类模型。
绘制层次聚类的树状图(Dendrogram)。
import pandas as pd
from sklearn.preprocessing import StandardScaler
from scipy.cluster.hierarchy import dendrogram, linkage
import matplotlib.pyplot as plt
# 重新加载数据并准备聚类分析
penguins_size_df = pd.read_csv('penguins_size.csv')
cluster_features = ['culmen_length_mm', 'culmen_depth_mm', 'flipper_length_mm', 'body_mass_g']
penguins_cleaned_df = penguins_size_df.dropna(subset=cluster_features)
cluster_data = penguins_cleaned_df[cluster_features]
# 标准化数据
scaler = StandardScaler()
cluster_scaled = scaler.fit_transform(cluster_data)
# 使用层次聚类
linked = linkage(cluster_scaled, method='ward')
# 绘制树状图
plt.figure(figsize=(12, 7))
dendrogram(linked, orientation='top', distance_sort='descending', show_leaf_counts=True)
plt.title('Hierarchical Clustering Dendrogram')
plt.xlabel('Sample Index')
plt.ylabel('Distance')
plt.show()
通过对企鹅数据集进行 K-means 聚类和层次聚类的分析,我们可以得出以下结论:
K-means 聚类
K-means 聚类结果将数据有效地分为了三个群组,这可能反映了企鹅种类的不同或其物理特征的显著差异。
聚类的可视化展示了企鹅在二维降维空间中的分布,其中每个群组代表了一种特定的特征组合。
层次聚类
层次聚类的树状图提供了一个关于数据分层结构的视觉表示,其中每个分支代表了数据中的一个群组。
树状图的高度(即距离)展示了不同群组之间的相似度或差异性。较短的连接表示群组间相似性高,而较长的连接表示差异性更大。
总结
这些聚类结果可能与企鹅的物理特征(如喙长、喙深、鳍状肢长度和体重)和/或其地理分布(如所在岛屿)有关。
聚类分析揭示了数据中的自然群组,这可能对进一步的生物学研究和物种分类研究有用。
这些发现可以帮助生物学家和生态学家更好地理解不同企鹅种类或种群的特征。
📢文章下方有交流学习区!一起学习进步!💪💪💪
📢首发CSDN博客,创作不易,如果觉得文章不错,可以点赞👍收藏📁评论📒
📢你的支持和鼓励是我创作的动力❗❗❗