资料
- 课程主页:https://speech.ee.ntu.edu.tw/~hylee/ml/2023-spring.php
- Github:https://github.com/Fafa-DL/Lhy_Machine_Learning
- B站课程:https://space.bilibili.com/253734135/channel/collectiondetail?sid=2014800
一、機器學習基本原理
机器学习本质:机器自动寻找一个最合适的函数f
根据函数的输出可以分为两类:
- Regression(回归):函数的输出是一个数值
例如:输入输入今天的PM2.5值、温度、臭氧量等,输出明天的PM2.5值 - Classification(分类):函数的输出是一个类别(选择题)
例如:判断一封邮件是否为垃圾邮件 - Structured Learning/Generative Learning(结构化学习/生成式学习):生成有结构的物件(如影像、文句等),更复杂
寻找函数f的步骤:

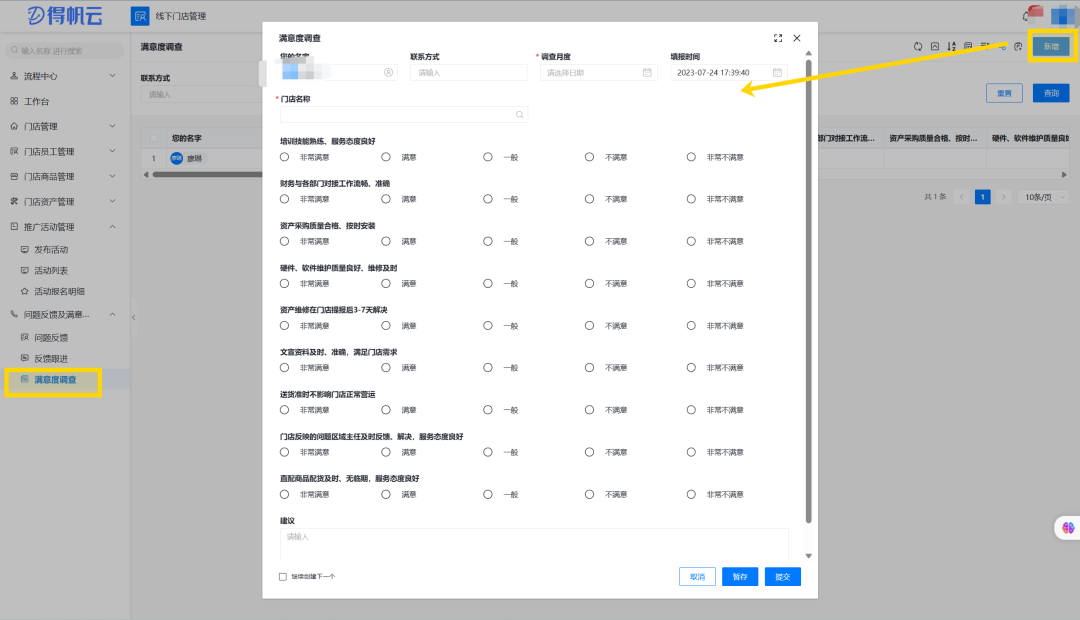
- 第一步:选定候选函数的集合Model;
深度学习中类神经网络的结构(如:CNN、RNN、Transformer、Decision Tree等等)指的就是不同的候选函数集合,函数集合表示为H
目的:缩小选择的范围;技巧性强
训练资料少时,L(f)小但测试差的函数就会多,这个时候画出集合范围要保守(小);反之测试数据多时,上述L(f)小但测试差的函数就会少
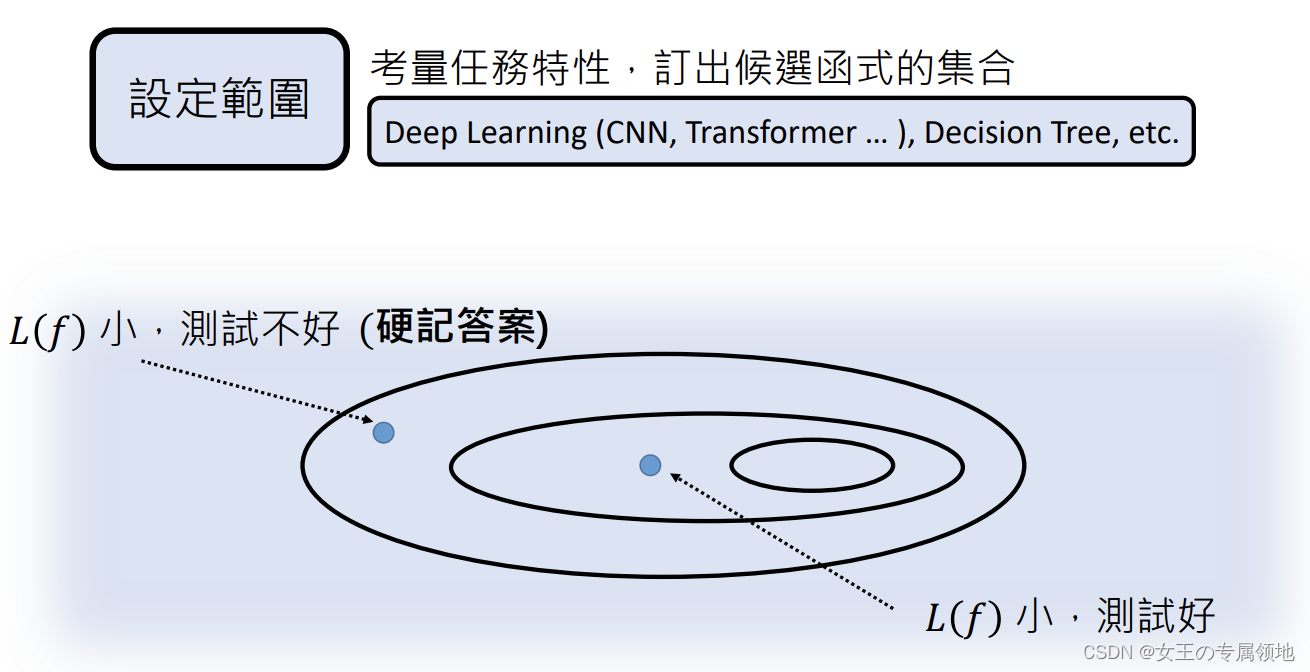
- 第二步:订出评价函数好坏的标准;
使用Loss函数,将f做出输入,输入L函数:L(f),根据输出的大小,评价函数(越大越差),L的计算过程取决于training data
常用方法:
- supervised Learning(全部都有标准答案)
semi-supervised Learning(没有标准答案,要定义评量标准)
RL(reinforcement Learning)等等
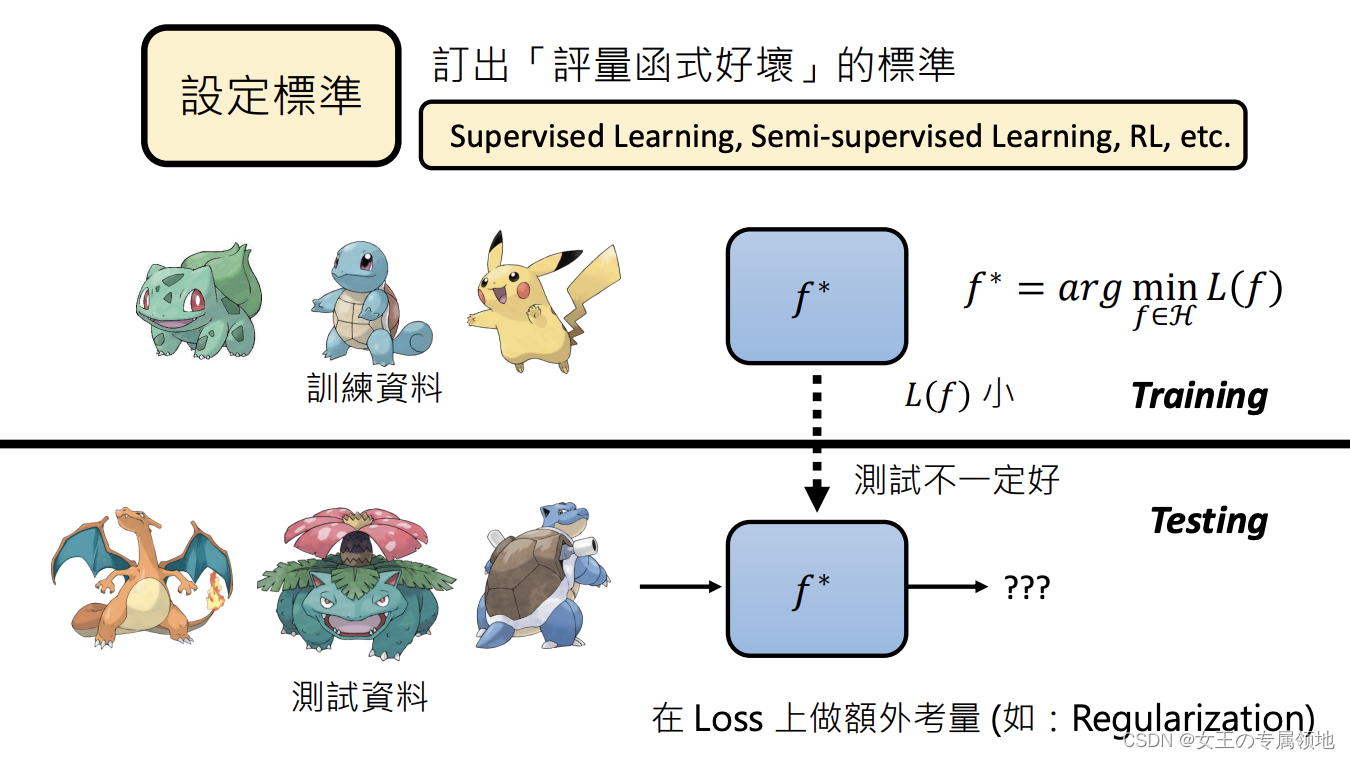
- 第三步:找出最好的函数,最佳化Optimization
将集合H中的所有函数带入L中,寻找Loss最小值
常用方法:Gradient Descent(Adam,AdamW…),Genetic Algorithm等等超参数:手调参数
二、生成式学习的两种策略
生成式学习:生成有结构的物件

案例:
- 生成影片:https://imagen.research.google/video/ 或https://audioldm.github.io/
- 生成语音:https://dongchaoyang.top/InstructTTS/
- 生成声音:https://audioldm.github.io/
两种策略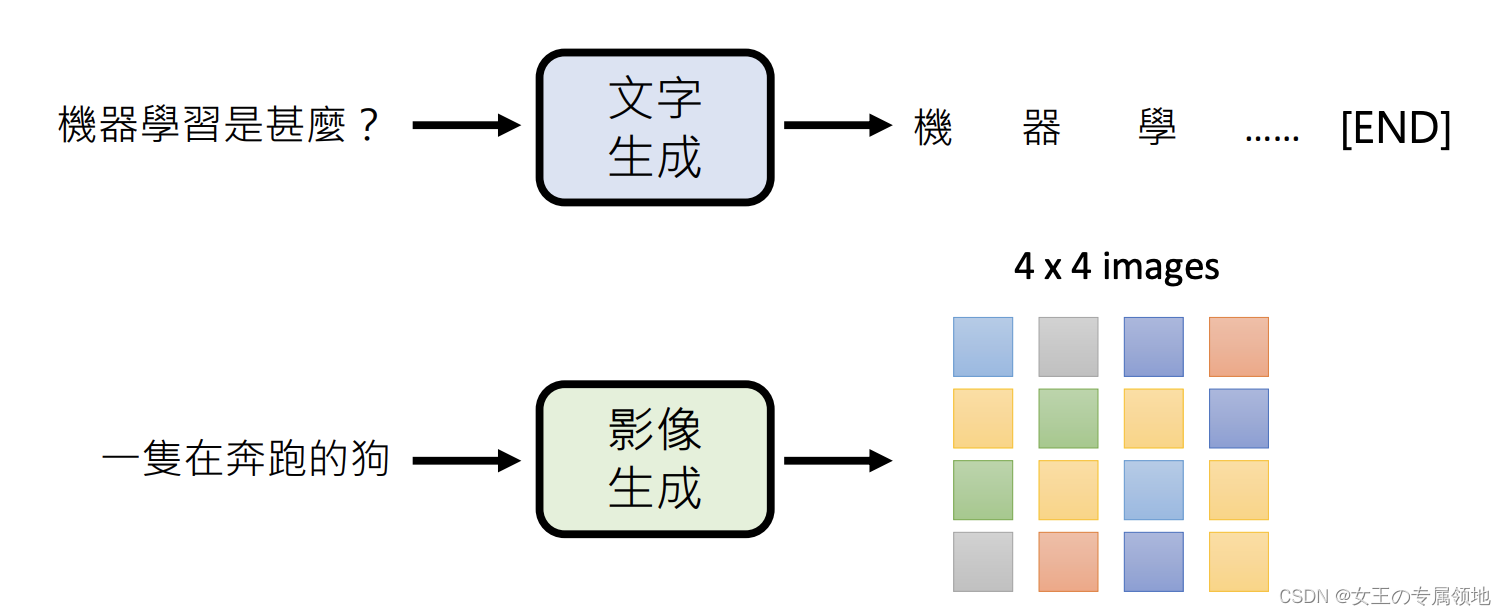
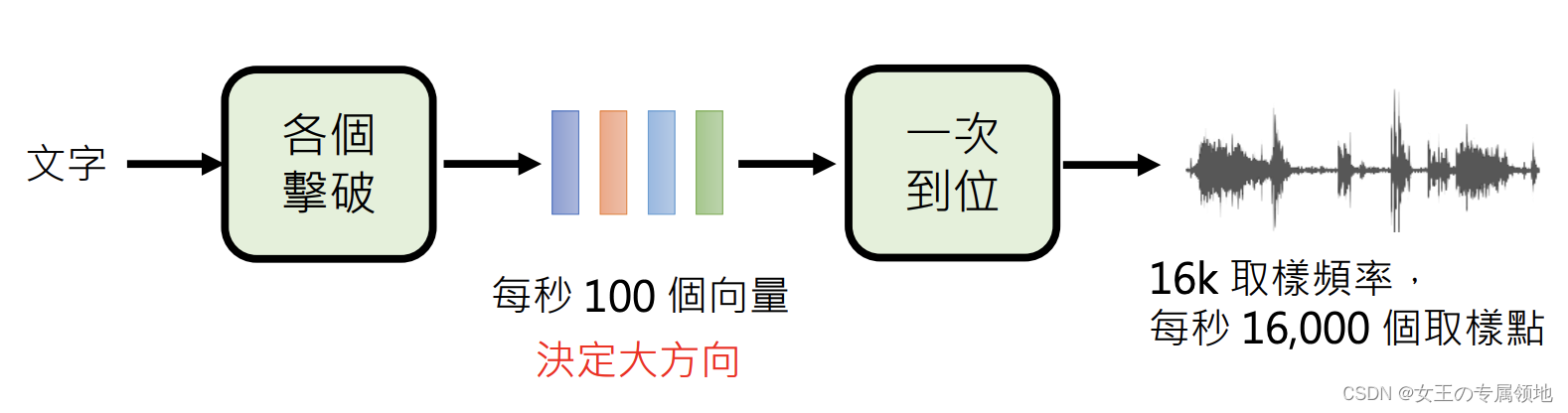
- 策略 1:各个击破AR(Autoregressive Model):上一个生成才生成下一个
- 策略 2:一次到位NAR(Non-autoregressive Model):一次性生成所有的
- 策略比较:
- AR:速度慢,答案质量好,适合生成文字
- NAR:速度快,答案质量较差,适合生成图像(影像像素过多,AR太慢)
综合使用: 批次
- 以语音合成为例:生成分为两个阶段,AR决定大方向,NAR生成最后产物
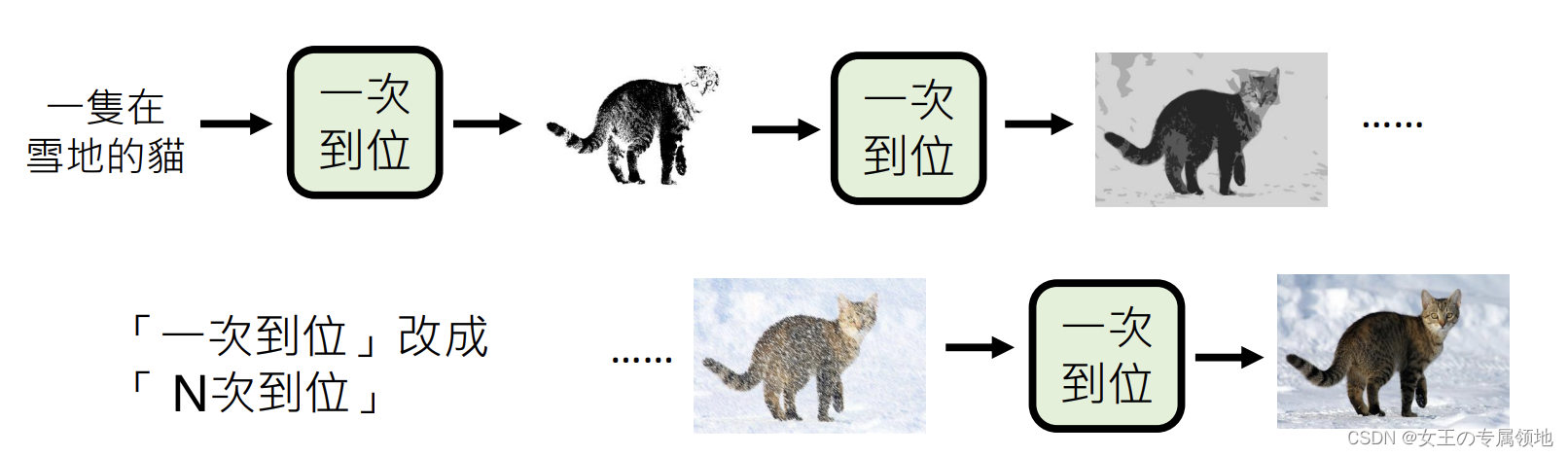
- 将“一次到位”改为“N此到位”(类似Diffusion Model)
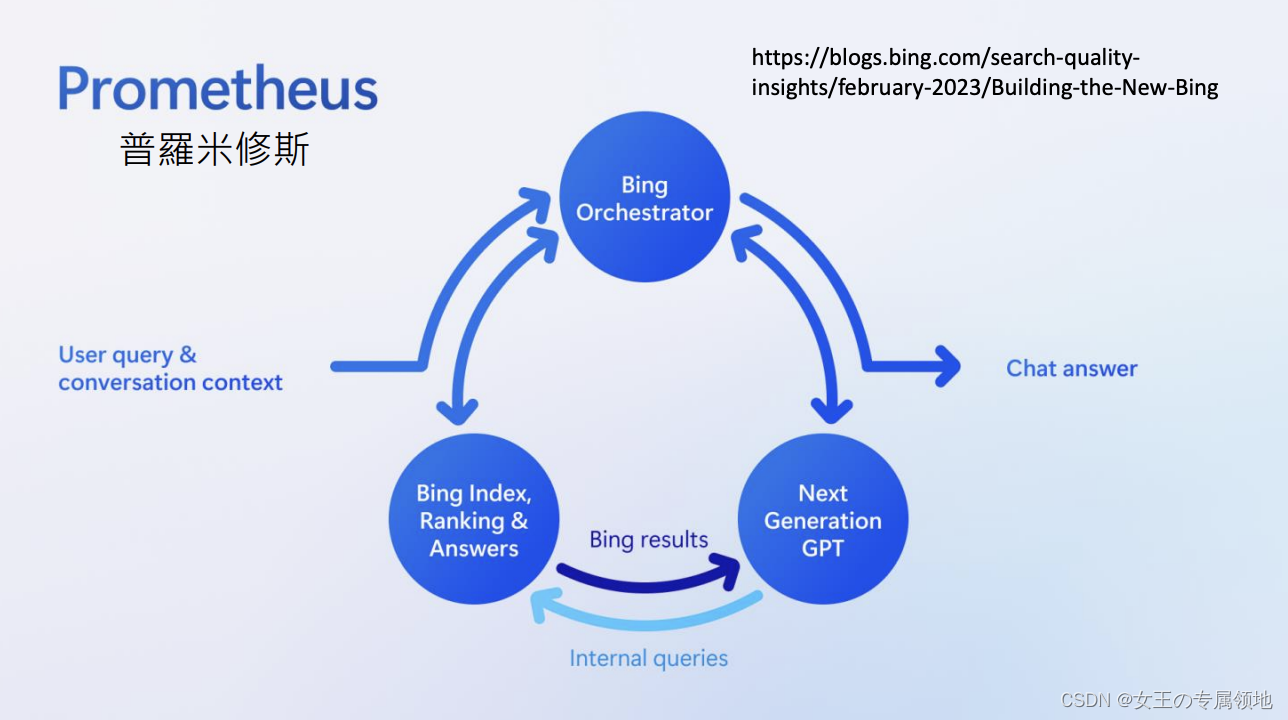
三、能够使用工具的AI
-
New Bing:New Bing是有搜寻网络的,但什么时候进行搜寻是由机器自己决定的
-
WebGPT:也是文字接龙
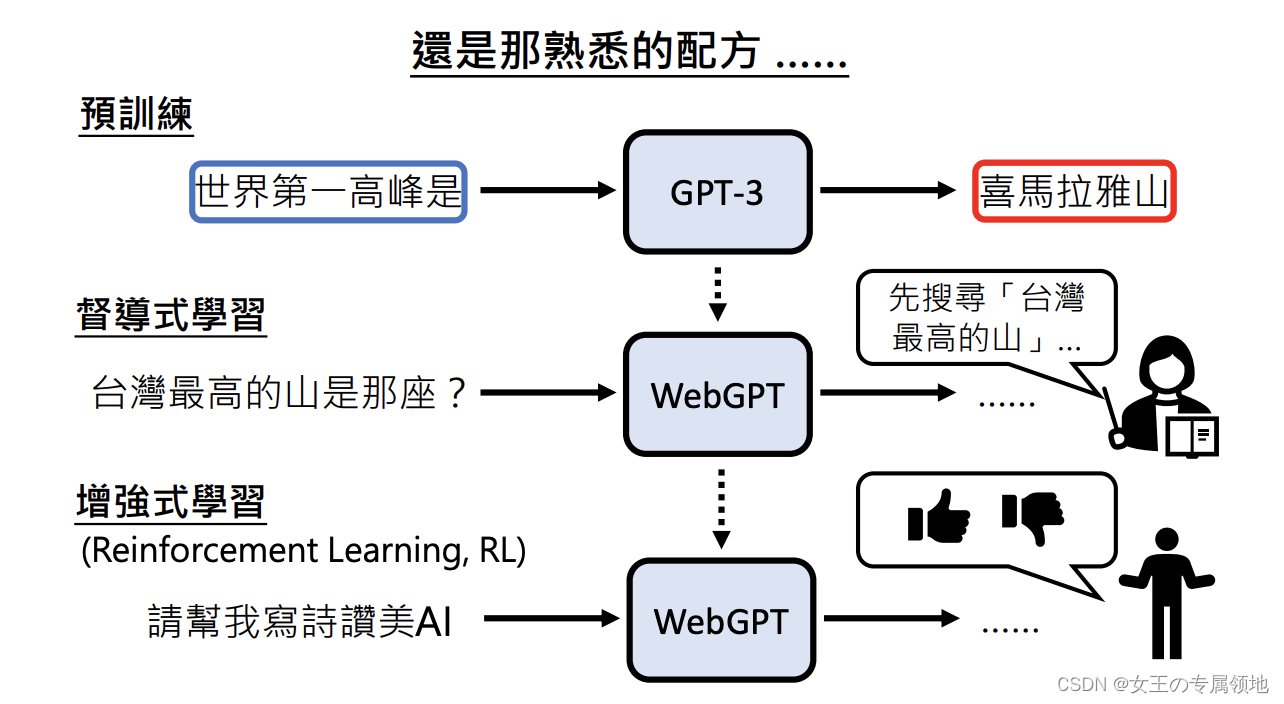
步骤:- 输入”Which river is longer, the Nile or the Yangtze?”(翻译:拿一条河比较长,尼罗河还是扬子江?)
- 提取关键字(如:”Nile vs Yangtze”、”nile length”、”Yangtze length”)
- 对关键字进行网络搜索,根据算法对搜索网页资料的部分段落进行收藏(注意只收藏文字段落,而不是整个网页)
- 整理生成答案(答案后会附上引用的网址)
-
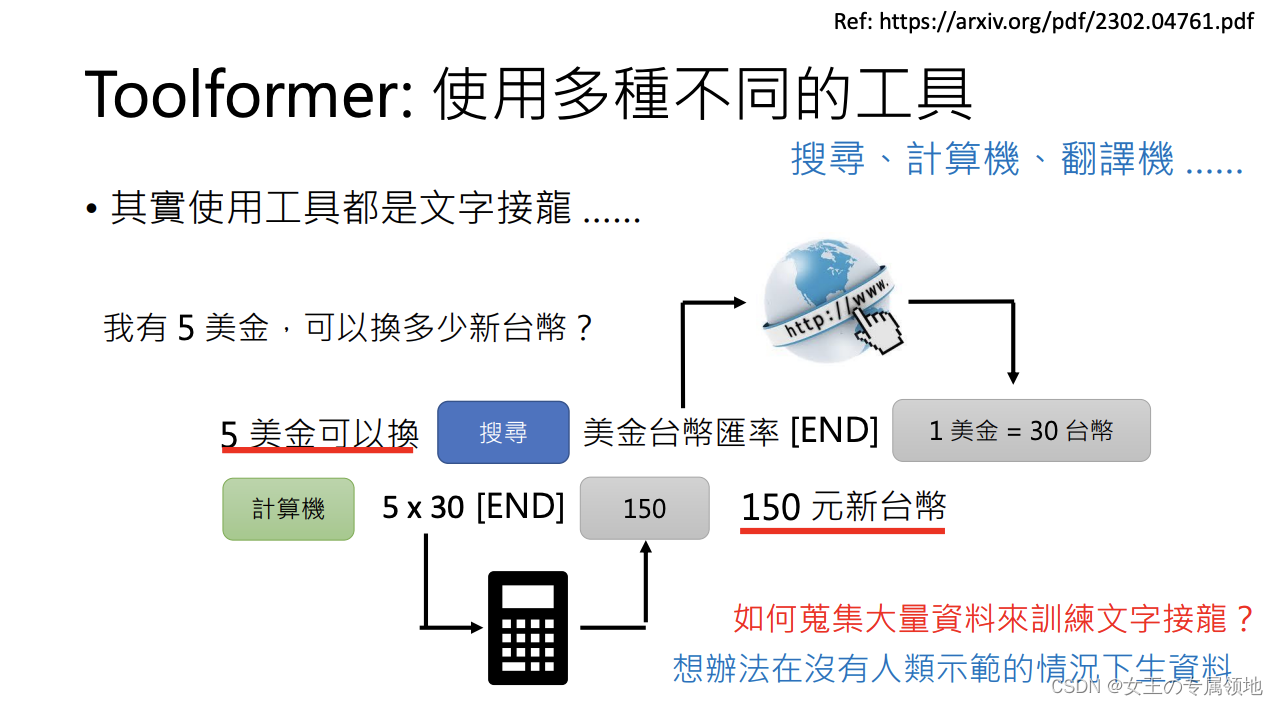
Toolformer:使用多种不同的工具
四、延伸学习
深度学习
梯度下降
反向传播
卷积神经网络
自注意力机制