实现零停机、高效率和成功迁移更新的指南。更多阅读:Elasticsearch:如何轻松安全地对实时 Elasticsearch 索引 reindex 你的数据。

在使用 Elasticsearch 的时候,总会有需要修改索引映射的时候,遇到这种情况,我们只能做 _reindex。 事实上,这是一项相当昂贵的操作,因为根据数据量和分片数量,完成索引的完整复制可能需要长达几个小时的时间。
花费的时间并不是一个大问题,但更严重的是,它会影响生产环境的性能甚至功能。
相信大家都明白,数据迁移会消耗大量的硬盘资源,肯定会影响性能,但是功能呢?
我们以常规的 _reindex 为例。 假设我们在索引上创建了一个别名。 如果我们没有别名,我们就有大麻烦了。

常规 _reindex 过程分为两个步骤。
- 调用 _reindex 命令开始数据迁移。
- 数据迁移完成后,调用 _aliases 命令进行新旧索引切换。
步骤 2 之后,新索引正式运行,并将负责所有读写请求。 然而,这只是一个完美的理想场景,事实上,事情不会那样发展。
下面是一个正常的场景。

实际上,在数据迁移期间或者切换别名之前,客户端会不断向原来的索引写入数据,而这些新的变化并不会迁移到新的索引中,从而导致数据不一致。
对于客户端来说,感觉是更改别名后,刚才所做的所有更改都会消失。 此外,正如我刚才提到的,一个大的索引迁移可能需要几个小时,所以客户的感受一定是显而易见的。
那么该怎么办?
Reindex 的正确流程
上述流程对原始流程进行了两处更改。
- _reindex 必须使用外部类型(external type)。
- 切换别名后再次需要 _reindex。
我们来解释一下外部类型的概念。
默认情况下,_reindex 是内部的,这种数据迁移是通过使用原始索引覆盖新索引来完成的,并删除文档的 _version,因此新索引中的所有文档重新开始。
如果使用外部类型,则数据迁移时文档的 _version 会被带入新索引,那么如果新旧索引的 _id 冲突,则会比较 _version。 只有当原始文档的版本大于目标文档时才会被覆盖。
有点抽象? 让我们举个例子。
假设原始索引有一个如下所示的文档,Elasticsearch 元数据位于下划线开头。
PUT test/_doc/1
{
"data": "Hello Elastic"
}
{
"_id": "1",
"_version": 1,
"data": "Hello Elastic"
}我们再次运行上面的命令一次以使得它的版本号码变为 2:

假如我们使用如下的命令来进行 reindex:
POST _reindex
{
"source": {
"index": "test"
},
"dest": {
"index": "test_reindexed"
}
}
我们查看 test_reindexed 的内容:
GET test_reindexed/_doc/1
从上面的输出中,我们可以看出来无论之前的 version 号码是多少,在 reindex 之后,它的版本在新的索引中是 1,也即回到最初的版本。
上面的命令是 reindex 在默认时的表现。它相当于如下的命令格式:
POST _reindex
{
"source": {
"index": "test"
},
"dest": {
"index": "test_reindexed",
"version_type": "internal"
}
}在进行迁移的时候,我们可以把 version_type 设置为 external。那么它的命令格式是这样的:
DELETE test_reindexed
POST _reindex
{
"source": {
"index": "test"
},
"dest": {
"index": "test_reindexed",
"version_type": "external"
}
}运行完上面的命令后,我们可以查看 test_reindexd 里的数据:
GET test_reindexed/_doc/1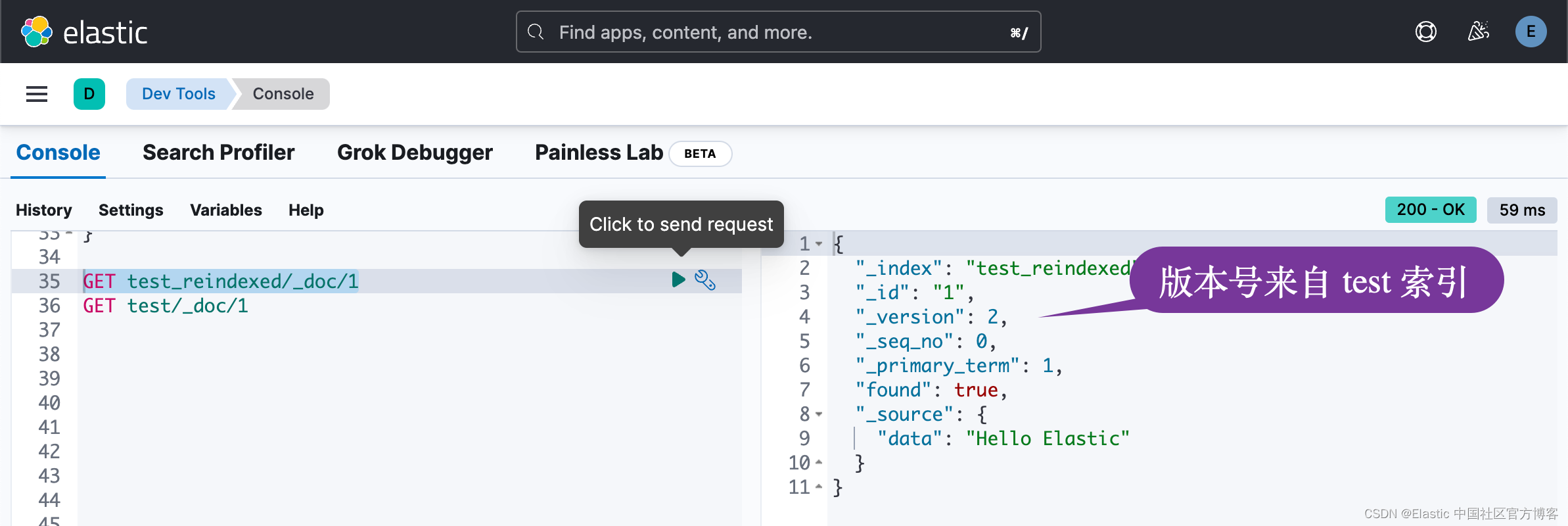
从上面的结果中,我们可以看出来,在新的索引中,它的 version 不再是之前 version_type 为 internal 时的情况。它的版本号现在是 2,而不是之前的 1。
当我们进行外部数据迁移时,_version: 2 也会被写入到新索引中。 如果有人在数据迁移期间将原始文档更改为 Hello Search,那么完整的文档将如下所示。
PUT test/_doc/1
{
"data": "Hello Search"
}那么,ID 为 1 的文档的版本会变为 3.
{
"_id": "1",
"_version": 3,
"data": "Hello Search"
}
重做 _reindex 将发现 3 > 3,因此它将被 Hello Search 覆盖。
我们再次重新进行 reindex,我们会发现由于 _version 的值变为 3,它是大于 test_reindexed 索引中的版本号码 2:
POST _reindex
{
"source": {
"index": "test"
},
"dest": {
"index": "test_reindexed",
"version_type": "external"
}
}我们再次查看最新的文档的值:

从上面的过程中,我们可以看出来:如果在迁移的过程中,或者我们再次运行 reindex,如果 test 中的值有变化,那么再次运行 reindex 后,它的值也会被更新到新的索引中。
那么,如果第二个 _reindex 有人修改了新索引中的文档怎么办? 例如,如果有人在新索引中将 Hello Elatic 更改为 Hello Elasticsearch,是否会被旧值覆盖? 整个过程如下所示。

答案是否定的,因为原始版本必须大于要覆盖的新版本才可以覆盖。
我们可以做如下的练习:
我们把 test_reindexed 中的文档的值修改为 Hello Elasticsearch:
PUT test_reindexed/_doc/1
{
"data": "Hello Elasticsearch"
}我们可以通过如下命令来查看它的值:
GET test_reindexed/_doc/1
我们再次确认 test 中的版本号码:
GET test/_doc/1
我们可以看到它们的版本号码是一致的。我们运行如下的 reindex:
POST _reindex
{
"source": {
"index": "test"
},
"dest": {
"index": "test_reindexed",
"version_type": "external"
}
}
很显然,由于 test 文档中版本号要低于 test_reindexed 中的版本号,那么我们的文档不会被更新。
还有一个问题。
虽然我们会进行第二次 _reindex 来修补数据,但是如果修补时间很长,对于用户来说仍然会不一致。比如,在我们第一次的时候有多次更新,从而使得 test 中的 version 号码比较高。在切换之后,在 test_reindexed 中的文档更新过一次。那么在第二次 reindex 的过程中极有可能把 test 中的文档覆盖最新的数据中,从而造成数据的丢失。
有两种方法可以缩短重新索引时间。
- 尽可能减少第一次 _reindex 的时间。
- 提前过滤补丁数据。
关于第一点,_reindex 过程是由 Elasticsearch 控制的,我们还能做些什么来提高效率呢? 嘿,有。
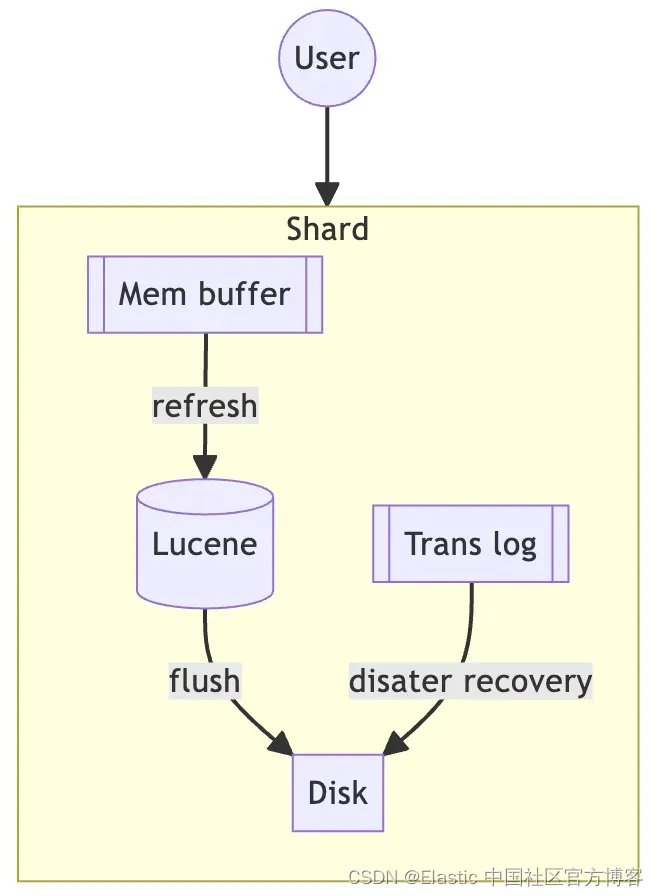
我们可以修改新索引的设置,以尽量减少数据迁移过程中的 IO 开销。
refresh_interval = -1
number_of_replicas = 0这非常简单。 首先,关闭 refresh_interval 的目的是让数据迁移期间只专注于写入 Translog,而不是在 Lucene 上花费额外的磁盘 IO。
其次,关闭 number_of_replicas 可以减少集群必须处理的额外数据复制开销。
另一方面,除了减少第一次 _reindex 的时间之外,还可以通过一些数据过滤来减少第二次 _reindex 的数据量。
例如,在 _reindex 期间引入数据的最后更新时间是一种可能的解决方案。 假设每个文档都有一个 updated_at 字段,那么在 _reindex 的查询中添加以下条件就会有效。
{
"range": {
"updated_at": { "gte": "now-1d"}
}
}结论
基于上述细节,让我们列出重建索引的理想流程。
- 创建目标索引。
- 更新目标索引的设置。 (refresh_interval = -1 且 number_of_replicas = 0)
- 使用外部类型进行 _reindex。
- 将别名从原始索引切换到目标索引。
- 使用外部类型再次执行 _reindex,最好进行额外的过滤。
- 再次更新目标索引设置。 (refresh_interval = null 且 number_of_replicas = null)
根据官方文档,设置为 null 可以恢复原来的设置。
因为 _reindex 是不可避免的,所以了解如何在不停机的情况下执行 _reindex 很重要。
事实上,利用 Elasticsearch 的流式索引,有更优雅的方法来完成它。 然而,流式索引的用例有很多限制,因此在实践中更常见的是使用常规索引。
本文提供了一个完整的过程来尽可能快地执行 _reindex 并最大限度地减少数据不一致的时间。 然而,所有这些都假设别名已正确创建,如果没有正确创建,则需要更多额外的步骤。 我觉得缺少别名已经违反了 Elasticsearch 的最佳实践,因此本文不会专门讨论这种情况。