文章目录
- 概要
- 一、数据结构
- 二、初始化
- 2.1、字面量
- 2.2、下标截取
- 2.2.1、截取原理
- 2.3、make关键字
- 2.3.1、编译时
- 三、复制
- 3.1、copy源码
- 四、扩容
- 4.1、append源码
- 五:切片使用注意事项
- 六:参考
概要
Go语言的切片(slice)是对数组的扩展,类似C语言常见的简单动态字符串(典型应用如Redis的string类型),动态扩容是其相对数组的最大优势。
本人在工作过程中,对slice的使用与底层原理有了较为全面的理解,特在这里针对其初始化、扩容、复制等机制进行源码分析。
PS: go V1.20.6
一、数据结构
slice的数据结构非常简单,其提供了和数组一样的下标访问任意元素方式。在运行时,其结构由有一个数组字段,一个长度字段,一个容量字段组成。
最初是在runtime/slice.go文件中:
type slice struct {
array unsafe.Pointer
len int
cap int
}
但是2018年10月份的一次优化cmd/compile: move slice construction to callers of makeslice,如下:
![[Go]move slice construction to callers of makeslice](https://img-blog.csdnimg.cn/direct/3a4ca884591146ff97114fdcc146aa0f.png)
本次优化运行时结构迁移到reflect/value.go文件中:
// SliceHeader is the runtime representation of a slice.
// It cannot be used safely or portably and its representation may
// change in a later release.
// Moreover, the Data field is not sufficient to guarantee the data
// it references will not be garbage collected, so programs must keep
// a separate, correctly typed pointer to the underlying data.
//
// In new code, use unsafe.Slice or unsafe.SliceData instead.
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
至今未改,其中Data字段是指向底层数组的指针,Len是当前底层数组使用的长度,Cap是当前底层数组的总长度。
二、初始化
切片有三种初始化方式:
- 使用字面量初始化新的切片;
- 通过下标的方式获得数组或截取切片的一部分;
- 使用关键字 make 创建切片。
2.1、字面量
示例如下:
a := []int64{4, 8, 9, 6, 4}
2.2、下标截取
数组转切片:
a := [5]int64{4, 8, 9, 6, 4}
b := a[:]
从切片截取(截取是遵循左闭右开原则):
a := []int64{4, 8, 9, 6, 4}
//删除第一个元素
b1 := a[1:]
//删除最后一个元素
b2 := a[:len(a)-1]
//删除中间一个元素
n := len(a)/2
b3 := append(a[:n],a[n+1:]...)
这种操作非常高效,不会申请内存,相比b1和b2,b3还会涉及到元素的移动,进而改变了a的内容。
2.2.1、截取原理
a := []int64{4, 8, 9, 6, 4}
b1 := a[1:4]//仅指定长度
b2 := a[1:2:3]//指定长度为1(2-1),容量为2(3-1)。【1标识索引下标1、2标识索引下标2,决定长度、3表示索引下标3,决定容量】
长度和容量变化如下:
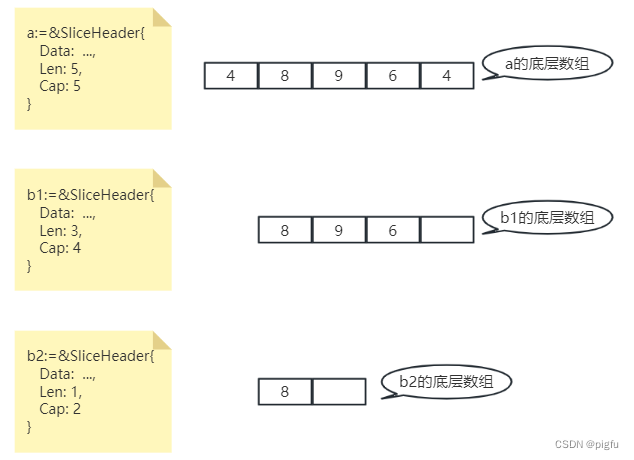
如图所示,虽说a、b1、b2的值不是同一个,但底层数组还共用同一段连续的内存块,所以在编码中要注意,这一点我们可以从Go SSA过程中一窥究竟:
【在go的源码和汇编码之间,其实编译器做了很多事情,而ssa(是一种中间代码的表示形式)就是查看编译器优化行为的利器】
先设置下环境变量。
# windows
$env:GOSSAFUNC="main"
# linux
export GOSSAFUNC="main"
再运行以下代码:
package main
import "fmt"
func main() {
a := []int64{4, 8, 9, 6, 4}
b1 := a[2:4]
fmt.Println(b1, len(b1), cap(b1))
b2 := a[1:2:3]
fmt.Println(b2, len(b2), cap(b2))
}
执行go build main.go就可以得到ssa.html文件,读者可自行试验下,内容太多,我们是看start和opt阶段的就可以:
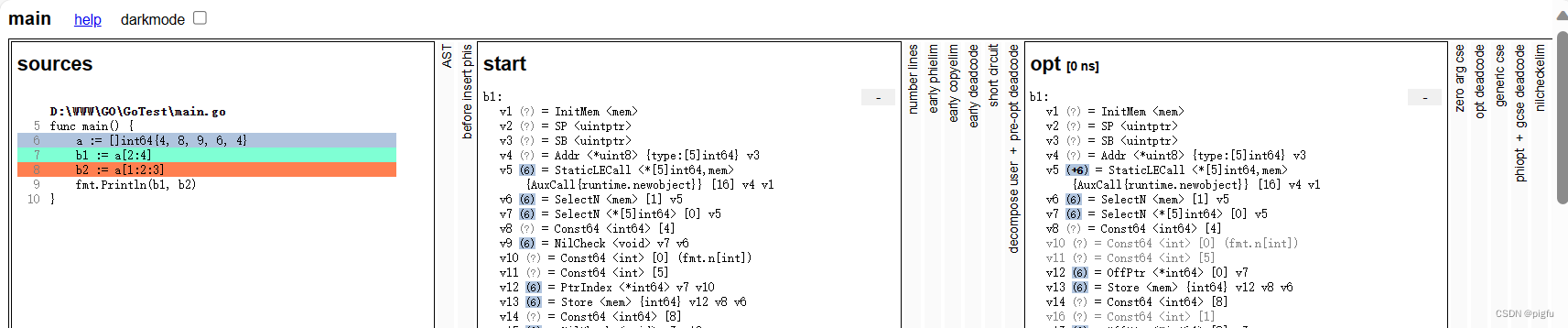 我们只探究
我们只探究b1 := a[2:4]即可,关键两处如下:
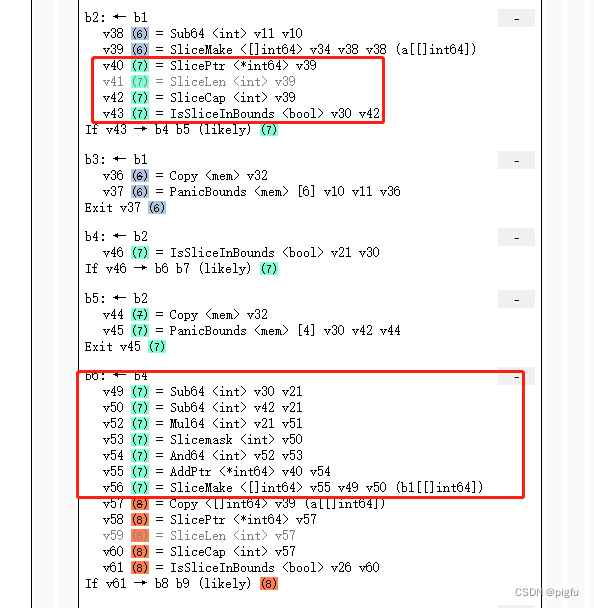
start阶段:
opt阶段:
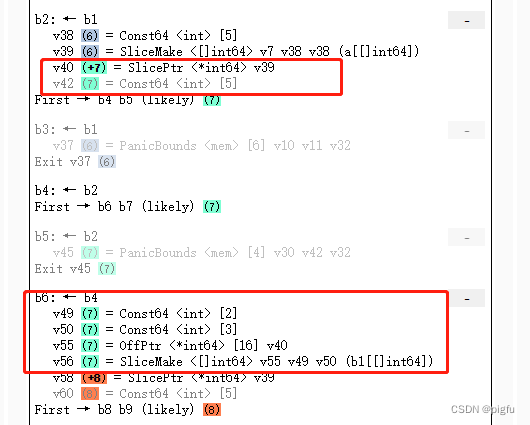
对比可以看到,从start阶段到opt阶段,中间码已经简化很多。
从中可以看到:
- 变量v39表示源码中的变量a;
- 变量v56表示源码中的变量b1;
那么b1 := a[2:4]如何变化的呢?
在opt阶段可以看到v40=v39,
- v49表示源码中的变量b1的长度,已经计算出来真实数值 2(在start阶段还不是呢),v50表示源码中的变量b1的容量,已经计算出来真实数值 3。
- v55 通过对变量v40进行OffPtr操作得到一个地址,就是一个指针运算,我们知道a,b1元素是int64的,一个元素8字节。b1相对a是右移了两个元素,就是16字节了。即对a的底层数组指针加16字节,就是b1的底层数组的指针了。
- v56 就是整合v49,v50,v55这几个变量到一起了。通过SliceMake 操作会接受四个参数创建新的切片,依次元素类型([]int64)、底层数组指针(v55)、长度(v49)和容量(v50),这也是我们在数据结构一节中提到的切片的几个字段 。
可以看到整个过程并没有重新申请新的内存段,是基于a的底层数组,进行指针运算,调整切片长度和容量的值等操作得到b1,
所以需要注意的是修改新切片b1的数据也会改变原切片a的数据。
所以说b2 := a[:2:3]操作只是改小了切片容量,并不会释放a申请的内存段,这种缩容是伪缩容
2.3、make关键字
提到make的源码,我们第一时间想到的就是Go SDK下的src/runtime/slice.go文件中的makeslice函数,但该函数目前只是申请了一块连续内存(见第一章节2018年10月份的一次优化相关),那么什么地方调用了该函数呢?这就要去看一下Go编译器的源码了。
2.3.1、编译时
Go编译器的执行流程有多个阶段:
- 经过词法分析和语法分析得到抽象语法树AST;
- 类型检查,包含检查常量、类型和函数名等类型,变量捕获与赋值,函数内联、逃逸分析、闭包重写、遍历函数(有些会导入内建的运行时函数,如runtime.makeslice,runtime.makechan等);
- SSA生成;
- 机器码生成。
分析何处调用runtime.makeslice函数我们只要分析类型检查阶段。
编译器入口文件src/cmd/compile/main.go,代码如下:
func main() {
// disable timestamps for reproducible output
log.SetFlags(0)
log.SetPrefix("compile: ")
buildcfg.Check()
archInit, ok := archInits[buildcfg.GOARCH]
if !ok {
fmt.Fprintf(os.Stderr, "compile: unknown architecture %q\n", buildcfg.GOARCH)
os.Exit(2)
}
gc.Main(archInit)//注意此处gc是go compiler的缩写,与垃圾回收的GC(garbage collection)区分开
base.Exit(0)
}
进入gc.Main函数:
func Main(archInit func(*ssagen.ArchInfo)) {
//此处省略若干代码...
// Prepare for backend processing. This must happen before pkginit,
// because it generates itabs for initializing global variables.
ssagen.InitConfig()//ssa初始化
// 词法解析、语法解析、类型检查工作
noder.LoadPackage(flag.Args())
//此处省略若干代码...
// 逃逸分析
escape.Funcs(typecheck.Target.Decls)
//遍历函数工作
base.Timer.Start("be", "compilefuncs")
fcount := int64(0)
for i := 0; i < len(typecheck.Target.Decls); i++ {
if fn, ok := typecheck.Target.Decls[i].(*ir.Func); ok {
// Don't try compiling dead hidden closure.
if fn.IsDeadcodeClosure() {
continue
}
enqueueFunc(fn)
fcount++
}
}
base.Timer.AddEvent(fcount, "funcs")
//ssa生成、机器码生成工作
compileFunctions()
// Write object data to disk.
base.Timer.Start("be", "dumpobj")
dumpdata()
base.Ctxt.NumberSyms()
dumpobj()
if base.Flag.AsmHdr != "" {
dumpasmhdr()
}
}
进入noder.LoadPackage函数:
该函数位于src/cmd/compile/internal/noder/目录下,
func LoadPackage(filenames []string) {
//只摘抄了部分关键代码
// Limit the number of simultaneously open files.
sem := make(chan struct{}, runtime.GOMAXPROCS(0)+10)
noders := make([]*noder, len(filenames))
//...
// 词法解析、语法解析工作
p.file, _ = syntax.Parse(fbase, f, p.error, p.pragma, syntax.CheckBranches)
// 类型检查相关
check2(noders)
}
check2函数会在某个节点调用typecheck.Expr,typecheck.Stmt,typecheck.Call等函数进行类型检查,即转入typecheck.typecheck函数。
func typecheck(n ir.Node, top int) (res ir.Node) {
//省略...
n.SetTypecheck(2)
n = typecheck1(n, top)
n.SetTypecheck(1)
//省略...
}
// typecheck1 should ONLY be called from typecheck.
func typecheck1(n ir.Node, top int) ir.Node {
switch n.Op() {
case ir.OMAKE://make操作
n := n.(*ir.CallExpr)
return tcMake(n)
}
}
// tcMake typechecks an OMAKE node.
func tcMake(n *ir.CallExpr) ir.Node {
args := n.Args
l := args[0]
l = typecheck(l, ctxType)
t := l.Type()
var nn ir.Node
switch t.Kind() {
case types.TSLICE:
//...,设置为ir.OMAKESLICE操作
nn = ir.NewMakeExpr(n.Pos(), ir.OMAKESLICE, l, r)
}
//省略...
return nn
}
func NewMakeExpr(pos src.XPos, op Op, len, cap Node) *MakeExpr {
n := &MakeExpr{Len: len, Cap: cap}
n.pos = pos
n.SetOp(op)
return n
}
至此获取了make([]int,0,10)之类操作的类型,稍后进入遍历函数操作,即gc.Main函数中的enqueueFunc。
func enqueueFunc(fn *ir.Func) {
//...
todo := []*ir.Func{fn}
for len(todo) > 0 {
next := todo[len(todo)-1]
todo = todo[:len(todo)-1]
prepareFunc(next)
todo = append(todo, next.Closures...)
}
//...
}
// prepareFunc handles any remaining frontend compilation tasks that
// aren't yet safe to perform concurrently.
func prepareFunc(fn *ir.Func) {
walk.Walk(fn)//进入遍历函数核心逻辑
}
调用链:Walk->walkStmtList->walkStmt->walkExpr->walkExpr1
func walkExpr1(n ir.Node, init *ir.Nodes) ir.Node {
switch n.Op() {
case ir.OMAKESLICE:
n := n.(*ir.MakeExpr)
return walkMakeSlice(n, init)
case ir.OSLICEHEADER:
n := n.(*ir.SliceHeaderExpr)
return walkSliceHeader(n, init)
}
}
// walkMakeSlice walks an OMAKESLICE node.
func walkMakeSlice(n *ir.MakeExpr, init *ir.Nodes) ir.Node {
l := n.Len
r := n.Cap
if n.Esc() == ir.EscNone {//不发生逃逸,分配栈内内存,注意这里由gc.Main函数中的escape.Funcs函数分析得到
t = types.NewArray(t.Elem(), i) // [r]T
var_ := typecheck.Temp(t)
appendWalkStmt(init, ir.NewAssignStmt(base.Pos, var_, nil)) // zero temp
r := ir.NewSliceExpr(base.Pos, ir.OSLICE, var_, nil, l, nil) // arr[:l]
// The conv is necessary in case n.Type is named.
return walkExpr(typecheck.Expr(typecheck.Conv(r, n.Type())), init)
}
len, cap := l, r
fnname := "makeslice64"//声明要调用runtime.makeslice64函数
argtype := types.Types[types.TINT64]
if (len.Type().IsKind(types.TIDEAL) || len.Type().Size() <= types.Types[types.TUINT].Size()) &&
(cap.Type().IsKind(types.TIDEAL) || cap.Type().Size() <= types.Types[types.TUINT].Size()) {
fnname = "makeslice"//声明要调用runtime.makeslice函数
argtype = types.Types[types.TINT]
}
fn := typecheck.LookupRuntime(fnname)
//调用得到一块连续内存的头指针
ptr := mkcall1(fn, types.Types[types.TUNSAFEPTR], init, reflectdata.MakeSliceElemRType(base.Pos, n), typecheck.Conv(len, argtype), typecheck.Conv(cap, argtype))
ptr.MarkNonNil()
//修正slice长度和容量
len = typecheck.Conv(len, types.Types[types.TINT])
cap = typecheck.Conv(cap, types.Types[types.TINT])
//这里转化为ir.OSLICEHEADER操作
sh := ir.NewSliceHeaderExpr(base.Pos, t, ptr, len, cap)
//执行ir.OSLICEHEADER操作
return walkExpr(typecheck.Expr(sh), init)
}
// 转化为ir.SliceHeaderExpr,在程序启动后,就会变成反射库中的SliceHeader 结构体
func walkSliceHeader(n *ir.SliceHeaderExpr, init *ir.Nodes) ir.Node {
n.Ptr = walkExpr(n.Ptr, init)
n.Len = walkExpr(n.Len, init)
n.Cap = walkExpr(n.Cap, init)
return n
}
至此把编译阶段如何调用makeslice基本解释清楚了,也顺便了解了Go编译相关的知识
至于makeslice函数就很简单了
func makeslice(et *_type, len, cap int) unsafe.Pointer {
mem, overflow := math.MulUintptr(et.size, uintptr(cap))
if overflow || mem > maxAlloc || len < 0 || len > cap {//参数自动修正
mem, overflow := math.MulUintptr(et.size, uintptr(len))
if overflow || mem > maxAlloc || len < 0 {
panicmakeslicelen()
}
panicmakeslicecap()
}
return mallocgc(mem, et, true)//申请一块连续的内存
}
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
//...
if size == 0 {//这时mallocgc函数有意思的地方,此时会返回一个固定指针,我们常用的struct{}{}就是因此而来
return unsafe.Pointer(&zerobase)
}
//...
}
PS:ir.SliceHeaderExpr是如何在程序启动后转化为reflect.SliceHeader 的呢?有兴趣的大佬可在评论区解释下
三、复制
func main() {
s1 := []string{"aaa", "sss", "ddd"}
s2 := make([]string, 2, 6)
copy(s2, s1)
s2 = append(s2, "yyy")
printSlice(s2)//output: len=3 cap=6 slice=[aaa sss yyy]
s3 := make([]string, 4, 6)
copy(s3, s1)
s3 = append(s3, "xxx")
printSlice(s3)//output: len=5 cap=6 slice=[aaa sss ddd xxx]
}
func printSlice(x []string) {
fmt.Printf("len=%d cap=%d slice=%v\n", len(x), cap(x), x)
}
根据s2,s3的打印结果可知,若想将源slice的内容全部复制到目的slice,那么目的slice的长度必须大于等于源slice的长度。
3.1、copy源码
编译时源码可见2.3.1小节,关键词是src/cmd/compile/internal/ir/node.go中的OCOPY ,搜索可知其遍历函数是walkCopy。
// Lower copy(a, b) to a memmove call or a runtime call.
// Also works if b is a string.
func walkCopy(n *ir.BinaryExpr, init *ir.Nodes, runtimecall bool) ir.Node {
if n.X.Type().Elem().HasPointers() {//slice在堆上的话调用runtime.typedslicecopy
fn := writebarrierfn("typedslicecopy", n.X.Type().Elem(), n.Y.Type().Elem())
return mkcall1(fn, n.Type(), init, reflectdata.CopyElemRType(base.Pos, n), ptrL, lenL, ptrR, lenR)
}
if runtimecall {//某些特殊情况,比如编译时开启竞态检查(-race),调用runtime.slicecopy
fn := typecheck.LookupRuntime("slicecopy")
fn = typecheck.SubstArgTypes(fn, ptrL.Type().Elem(), ptrR.Type().Elem())
return mkcall1(fn, n.Type(), init, ptrL, lenL, ptrR, lenR, ir.NewInt(n.X.Type().Elem().Size()))
}
//排除以上两种情况,都走runtime.memmove
nlen := typecheck.Temp(types.Types[types.TINT])
// n = len(to)
l = append(l, ir.NewAssignStmt(base.Pos, nlen, ir.NewUnaryExpr(base.Pos, ir.OLEN, nl)))
fn := typecheck.LookupRuntime("memmove")
fn = typecheck.SubstArgTypes(fn, nl.Type().Elem(), nl.Type().Elem())
call := mkcall1(fn, nil, init, nto, nfrm, nwid)
ne.Body.Append(call)
return nlen
}
进入runtime.typedslicecopy和runtime.slicecopy函数,其最后也是调用的runtime.memmove函数。
该函数与C语言的memmove作用是一样的,时间复杂度是O(N),所以面对较多元素的切片时,使用copy操作应当慎重。
四、扩容
func main() {
r := make([]int, 0, 3)
fmt.Printf("len=%d cap=%d slice=%v,r addr:%p,addr:%p\n", len(r), cap(r), r, &r, r) //初始化,但可以看出r本质为*SliceHeader的指针类型,所以在传参时就是指针传递
r = append(r, 5, 6)
fmt.Printf("len=%d cap=%d slice=%v,r addr:%p,addr:%p,r[0] addr:%p\n", len(r), cap(r), r, &r, r, &r[0]) //第一个元素地址没变
r = append(r, 11)
fmt.Printf("len=%d cap=%d slice=%v,r addr:%p,addr:%p,r[0] addr:%p\n", len(r), cap(r), r, &r, r, &r[0]) //第一个元素地址没变
r = append(r, 22)
fmt.Printf("扩容:len=%d cap=%d slice=%v,r addr:%p,addr:%p,r[0] addr:%p\n", len(r), cap(r), r, &r, r, &r[0]) //扩容后地址发生变化,即底层数组发生变化,但变量的地址不变
fmt.Printf("r addr:%p,addr:%p,r[0] addr:%p,r[1] addr:%p,\n", &r, r, &r[0], &r[1]) //r值的地址也变为扩容后第一个元素的地址
r = append(r, []int{10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110}...)
fmt.Printf("扩容 len=%d cap=%d slice=%v,r addr:%p,r[0] addr:%p\n", len(r), cap(r), r, &r, &r[0]) //扩容后地址发生变化,即底层数组发生变化,但变量的地址不变。扩容后newCap本应该是15,但实际是16,因为做了内存对齐
}
运行代码输出如下:
len=0 cap=3 slice=[],r addr:0xc000008570,addr:0xc000017698
len=2 cap=3 slice=[5 6],r addr:0xc000008570,addr:0xc000017698,r[0] addr:0xc000017698
len=3 cap=3 slice=[5 6 11],r addr:0xc000008570,addr:0xc000017698,r[0] addr:0xc000017698
扩容:len=4 cap=6 slice=[5 6 11 22],r addr:0xc000008570,addr:0xc00000eba0,r[0] addr:0xc00000eba0
r addr:0xc000008570,addr:0xc00000eba0,r[0] addr:0xc00000eba0,r[1] addr:0xc00000eba8,
扩容 len=15 cap=16 slice=[5 6 11 22 10 20 30 40 50 60 70 80 90 100 110],r addr:0xc000008570,r[0] addr:0xc000078f00
其扩容流程图如下:
假设有一切片,其长度为oldLen,容量为oldCap,现要增加num个元素。则有newLen=oldLen+num,doublecap=oldCap+oldCap。

4.1、append源码
编译时源码可见2.3.1小节,关键词是src/cmd/compile/internal/ir/node.go中的OAPPEND ,注意walkExpr1函数源码中OAPPEND已废弃,而是走OAS搜索可知其遍历函数是walkAssign。
func walkAssign(init *ir.Nodes, n ir.Node) ir.Node {
//...
as := n.(*ir.AssignStmt)
switch as.Y.Op() {
case ir.OAPPEND:
var r ir.Node
switch {
case isAppendOfMake(call):
// x = append(y, make([]T, y)...)
r = extendSlice(call, init)
case call.IsDDD:
r = appendSlice(call, init) // also works for append(slice, string).
default:
r = walkAppend(call, init, as)
}
}
}
func walkAppend(n *ir.CallExpr, init *ir.Nodes, dst ir.Node) ir.Node {
var l []ir.Node
// s = slice to append to
s := typecheck.Temp(nsrc.Type())
l = append(l, ir.NewAssignStmt(base.Pos, s, nsrc))
// num = number of things to append
num := ir.NewInt(int64(argc))
// newLen := s.len + num
newLen := typecheck.Temp(types.Types[types.TINT])
l = append(l, ir.NewAssignStmt(base.Pos, newLen, ir.NewBinaryExpr(base.Pos, ir.OADD, ir.NewUnaryExpr(base.Pos, ir.OLEN, s), num)))
//调用runtime.growslice函数
fn := typecheck.LookupRuntime("growslice") // growslice(ptr *T, newLen, oldCap, num int, <type>) (ret []T)
fn = typecheck.SubstArgTypes(fn, s.Type().Elem(), s.Type().Elem())
nif.Else = []ir.Node{
ir.NewAssignStmt(base.Pos, s, mkcall1(fn, s.Type(), nif.PtrInit(),
ir.NewUnaryExpr(base.Pos, ir.OSPTR, s),//要扩容切片的地址
newLen,//新切片元素个数
ir.NewUnaryExpr(base.Pos, ir.OCAP, s),//要扩容切片的容量
num,//要追加的元素个数
reflectdata.TypePtr(s.Type().Elem()))),//要扩容切片的类型
}
}
再看看runtime.growslice函数
func growslice(oldPtr unsafe.Pointer, newLen, oldCap, num int, et *_type) slice {
oldLen := newLen - num
if et.size == 0 {
return slice{unsafe.Pointer(&zerobase), newLen, newLen}//扩容的运行时竟然用的是runtime.slice结构体
}
//扩容逻辑
newcap := oldCap
doublecap := newcap + newcap
if newLen > doublecap {
newcap = newLen
} else {
const threshold = 256
if oldCap < threshold {
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < newLen {
// Transition from growing 2x for small slices
// to growing 1.25x for large slices. This formula
// gives a smooth-ish transition between the two.
newcap += (newcap + 3*threshold) / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
newcap = newLen
}
}
}
var overflow bool
var lenmem, newlenmem, capmem uintptr
//进行内存对齐
switch {
case et.size == 1:
lenmem = uintptr(oldLen)
newlenmem = uintptr(newLen)
capmem = roundupsize(uintptr(newcap))
overflow = uintptr(newcap) > maxAlloc
newcap = int(capmem)
case et.size == goarch.PtrSize: //goarch.PtrSize is 4 on 32-bit systems, 8 on 64-bit systems。
lenmem = uintptr(oldLen) * goarch.PtrSize
newlenmem = uintptr(newLen) * goarch.PtrSize
capmem = roundupsize(uintptr(newcap) * goarch.PtrSize)//内存对齐,
overflow = uintptr(newcap) > maxAlloc/goarch.PtrSize
newcap = int(capmem / goarch.PtrSize)
case isPowerOfTwo(et.size):
var shift uintptr
if goarch.PtrSize == 8 {
// Mask shift for better code generation.
shift = uintptr(sys.TrailingZeros64(uint64(et.size))) & 63
} else {
shift = uintptr(sys.TrailingZeros32(uint32(et.size))) & 31
}
lenmem = uintptr(oldLen) << shift
newlenmem = uintptr(newLen) << shift
capmem = roundupsize(uintptr(newcap) << shift)
overflow = uintptr(newcap) > (maxAlloc >> shift)
newcap = int(capmem >> shift)
capmem = uintptr(newcap) << shift
default:
lenmem = uintptr(oldLen) * et.size
newlenmem = uintptr(newLen) * et.size
capmem, overflow = math.MulUintptr(et.size, uintptr(newcap))
capmem = roundupsize(capmem)
newcap = int(capmem / et.size)
capmem = uintptr(newcap) * et.size
}
if overflow || capmem > maxAlloc {
panic(errorString("growslice: len out of range"))
}
//申请新切片所需的内存
var p unsafe.Pointer
if et.ptrdata == 0 {
p = mallocgc(capmem, nil, false)
memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem)
} else {
p = mallocgc(capmem, et, true)
if lenmem > 0 && writeBarrier.enabled {
bulkBarrierPreWriteSrcOnly(uintptr(p), uintptr(oldPtr), lenmem-et.size+et.ptrdata)
}
}
//旧切片中的内容复制到新切片中
memmove(p, oldPtr, lenmem)
return slice{p, newLen, newcap}
}
五:切片使用注意事项
- 切片初始化时尽量确定容量;
六:参考
1]:深入学习go语言-前置知识-编译过程