
概述
智慧医药系统(smart-medicine)是一个基于 SpringBoot 开发的Web 项目。整体页面简约大气,增加了AI医生问诊功能,功能设计的较为简单。
开源地址
https://gitcode.net/NVG_Haru/Java_04
界面预览

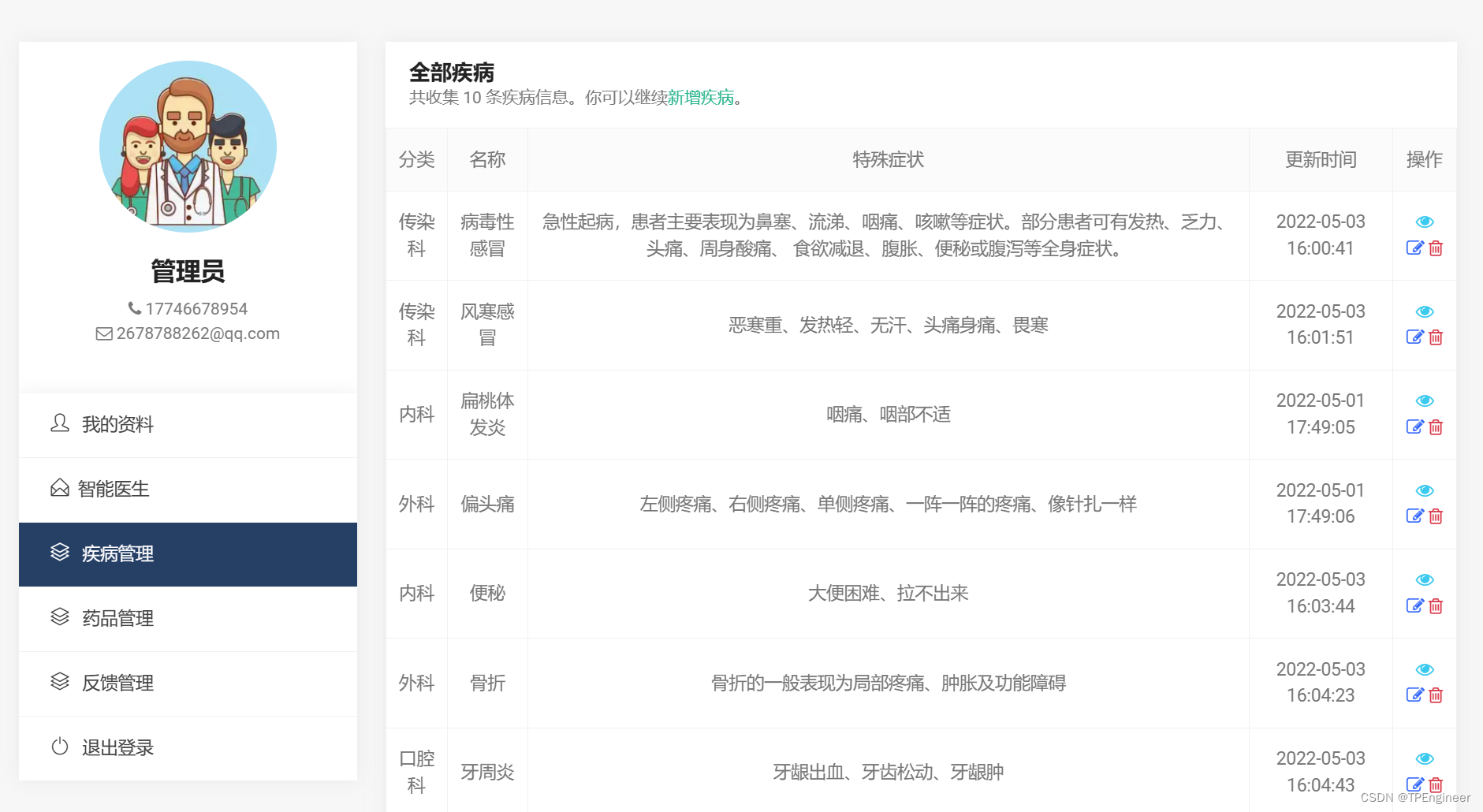
功能介绍
游客功能介绍
| 功能模块 | 功能描述 |
|---|---|
| 登录注册方面 | 注册成为系统用户 |
| 系统主页 | 浏览系统主页、疾病、药品信息搜索、详情的查看(统计浏览量) |
用户功能介绍
| 功能模块 | 功能描述 |
|---|---|
| 登录注册方面 | 填写用户信息进行账号注册(邮件接收验证码)、使用账号密码进行登录 |
| 个人资料方面 | 修改个人资料(姓名、年龄、手机号、头像等)、修改登录密码 |
| 系统反馈方面 | 提交系统反馈意见 |
| 智能医生方面 | 与智能医生进行交流聊天 |
管理员功能介绍
| 功能模块 | 功能描述 |
|---|---|
| 登录注册方面 | 填写用户信息进行账号注册(邮件接收验证码)、使用账号密码进行登录 |
| 个人资料方面 | 修改个人资料(姓名、年龄、手机号、头像等)、修改登录密码 |
| 系统反馈方面 | 提交系统反馈意见 |
| 智能医生方面 | 与智能医生进行交流聊天 |
| 疾病管理方面 | 发布疾病、编辑(名称、原因、症状、分类等)、删除药品等 |
| 药品管理方面 | 发布药品、编辑(名称、搜索关键词、功效、用法用量、类型等)、关联疾病、删除药品等 |
| 反馈管理方面 | 管理用户提交的反馈信息 |
数据库设计
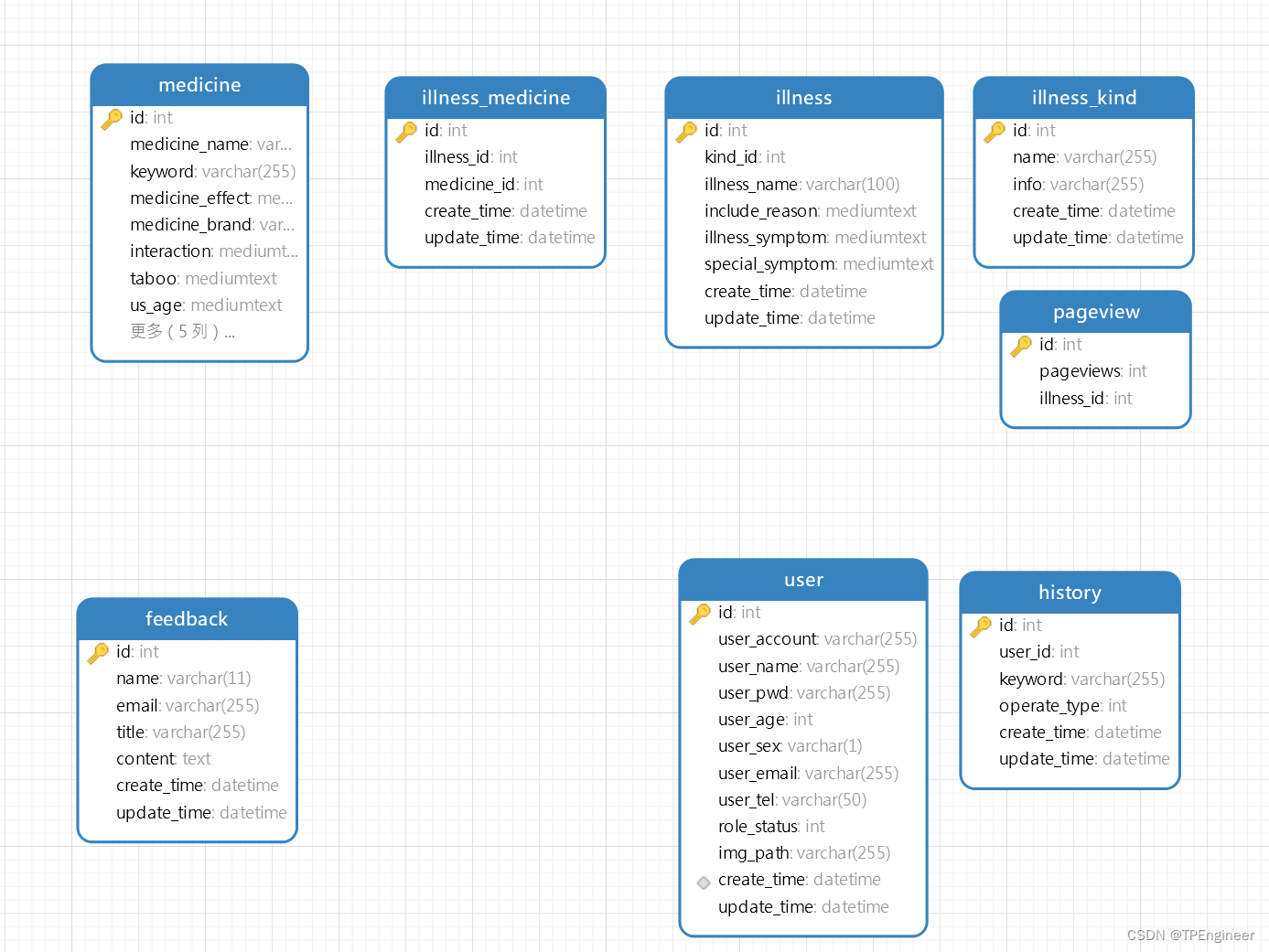
代码讲解
AI 问诊功能
这个功能借助阿里通义千问大模型实现,调用了com.alibaba.dashscope.*sdk提供的接口,主要流程如下:
- 创建Generation对象
- 创建MessageManager对象
- 创建系统消息
- 将系统消息和用户消息添加到MessageManager中
- 创建QwenParam对象
- 调用Generation的call方法,获取GenerationResult对象
- 获取GenerationResult对象的输出部分
- 获取输出中的第一个消息并返回
public String query(String queryMessage) {
// 设置API key
Constants.apiKey = apiKey;
try {
// 创建Generation对象
Generation gen = new Generation();
// 创建MessageManager对象
MessageManager msgManager = new MessageManager(10);
// 创建系统消息
Message systemMsg = Message.builder().role(Role.SYSTEM.getValue())
.content("你是智能医生,你只回答与医疗相关的问题,不要回答其他问题!").build();
// 创建用户消息
Message userMsg = Message.builder().role(Role.USER.getValue()).content(queryMessage).build();
// 将系统消息和用户消息添加到MessageManager中
msgManager.add(systemMsg);
msgManager.add(userMsg);
// 创建QwenParam对象
QwenParam param = QwenParam.builder().model(Generation.Models.QWEN_TURBO).messages(msgManager.get())
.resultFormat(QwenParam.ResultFormat.MESSAGE).build();
// 调用Generation的call方法,获取GenerationResult对象
GenerationResult result = gen.call(param);
// 获取GenerationResult对象的输出部分
GenerationOutput output = result.getOutput();
// 获取输出中的第一个消息
Message message = output.getChoices().get(0).getMessage();
// 返回消息的内容
return message.getContent();
} catch (Exception e) {
return "智能医生现在不在线,请稍后再试~";
}
}
反馈功能
主要讲解一下query这个查询函数,该函数接受一个Feedback实体函数,实际上这是一种偷懒的做法,最佳方案还是确定好哪些参数可以进入函数。
package world.xuewei.service;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import world.xuewei.dao.FeedbackDao;
import world.xuewei.entity.Feedback;
import world.xuewei.utils.Assert;
import world.xuewei.utils.BeanUtil;
import world.xuewei.utils.VariableNameUtils;
import java.io.Serializable;
import java.util.List;
import java.util.Map;
/**
* 反馈服务类
*
*/
@Service
public class FeedbackService extends BaseService<Feedback> {
@Autowired
protected FeedbackDao userDao;
/**
* 查询满足指定条件的Feedback列表
*
* @param o 查询条件对象
* @return 满足条件的Feedback列表
*/
@Override
public List<Feedback> query(Feedback o) {
// 创建QueryWrapper对象
QueryWrapper<Feedback> wrapper = new QueryWrapper();
if (Assert.notEmpty(o)) {
// 将对象转换为Map
Map<String, Object> bean2Map = BeanUtil.bean2Map(o);
// 遍历Map中的键值对
for (String key : bean2Map.keySet()) {
if (Assert.isEmpty(bean2Map.get(key))) {
continue;
}
// 根据键值对创建查询条件
wrapper.eq(VariableNameUtils.humpToLine(key), bean2Map.get(key));
}
}
// 执行查询操作
return userDao.selectList(wrapper);
}
@Override
public List<Feedback> all() {
return query(null);
}
@Override
public Feedback save(Feedback o) {
if (Assert.isEmpty(o.getId())) {
userDao.insert(o);
} else {
userDao.updateById(o);
}
return userDao.selectById(o.getId());
}
@Override
public Feedback get(Serializable id) {
return userDao.selectById(id);
}
@Override
public int delete(Serializable id) {
return userDao.deleteById(id);
}
}
疾病功能
package world.xuewei.service;
import cn.hutool.core.collection.CollUtil;
import cn.hutool.core.map.MapUtil;
import cn.hutool.core.util.ObjectUtil;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import world.xuewei.dao.IllnessDao;
import world.xuewei.entity.*;
import world.xuewei.utils.Assert;
import world.xuewei.utils.BeanUtil;
import world.xuewei.utils.VariableNameUtils;
import java.io.Serializable;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* 疾病服务类
*
* @author XUEW
*/
@Service
public class IllnessService extends BaseService<Illness> {
@Autowired
protected IllnessDao illnessDao;
@Override
public List<Illness> query(Illness o) {
QueryWrapper<Illness> wrapper = new QueryWrapper();
if (Assert.notEmpty(o)) {
Map<String, Object> bean2Map = BeanUtil.bean2Map(o);
for (String key : bean2Map.keySet()) {
if (Assert.isEmpty(bean2Map.get(key))) {
continue;
}
wrapper.eq(VariableNameUtils.humpToLine(key), bean2Map.get(key));
}
}
return illnessDao.selectList(wrapper);
}
@Override
public List<Illness> all() {
return query(null);
}
@Override
public Illness save(Illness o) {
if (Assert.isEmpty(o.getId())) {
illnessDao.insert(o);
} else {
illnessDao.updateById(o);
}
return illnessDao.selectById(o.getId());
}
@Override
public Illness get(Serializable id) {
return illnessDao.selectById(id);
}
@Override
public int delete(Serializable id) {
return illnessDao.deleteById(id);
}
public Map<String, Object> findIllness(Integer kind, String illnessName, Integer page) {
Map<String, Object> map = new HashMap<>(4);
QueryWrapper<Illness> illnessQueryWrapper = new QueryWrapper<>();
if (Assert.notEmpty(illnessName)) {
illnessQueryWrapper
.like("illness_name", illnessName)
.or()
.like("include_reason", illnessName)
.or()
.like("illness_symptom", illnessName)
.or()
.like("special_symptom", illnessName);
}
if (kind != null) {
if (Assert.notEmpty(illnessName)) {
illnessQueryWrapper.last("and (kind_id = " + kind + ") ORDER BY create_time DESC limit " + (page - 1) * 9 + "," + page * 9);
} else {
illnessQueryWrapper.eq("kind_id", kind);
illnessQueryWrapper.orderByDesc("create_time");
illnessQueryWrapper.last("limit " + (page - 1) * 9 + "," + page * 9);
}
} else {
illnessQueryWrapper.orderByDesc("create_time");
illnessQueryWrapper.last("limit " + (page - 1) * 9 + "," + page * 9);
}
int size = illnessDao.selectMaps(illnessQueryWrapper).size();
List<Map<String, Object>> list = illnessDao.selectMaps(illnessQueryWrapper);
list.forEach(l -> {
Integer id = MapUtil.getInt(l, "id");
Pageview pageInfo = pageviewDao.selectOne(new QueryWrapper<Pageview>().eq("illness_id", id));
l.put("kindName", "暂无归属类");
l.put("create_time", MapUtil.getDate(l, "create_time"));
l.put("pageview", pageInfo == null ? 0 : pageInfo.getPageviews());
Integer kindId = MapUtil.getInt(l, "kind_id");
if (Assert.notEmpty(kindId)) {
IllnessKind illnessKind = illnessKindDao.selectById(kindId);
if (Assert.notEmpty(illnessKind)) {
l.put("kindName", illnessKind.getName());
}
}
});
map.put("illness", list);
map.put("size", size < 9 ? 1 : size / 9 + 1);
return map;
}
public Map<String, Object> findIllnessOne(Integer id) {
Illness illness = illnessDao.selectOne(new QueryWrapper<Illness>().eq("id", id));
List<IllnessMedicine> illnessMedicines = illnessMedicineDao.selectList(new QueryWrapper<IllnessMedicine>().eq("illness_id", id));
List<Medicine> list = new ArrayList<>(4);
Map<String, Object> map = new HashMap<>(4);
Pageview illness_id = pageviewDao.selectOne(new QueryWrapper<Pageview>().eq("illness_id", id));
if (Assert.isEmpty(illness_id)) {
illness_id = new Pageview();
illness_id.setIllnessId(id);
illness_id.setPageviews(1);
pageviewDao.insert(illness_id);
} else {
illness_id.setPageviews(illness_id.getPageviews() + 1);
pageviewDao.updateById(illness_id);
}
map.put("illness", illness);
if (CollUtil.isNotEmpty(illnessMedicines)) {
illnessMedicines.forEach(illnessMedicine -> {
Medicine medicine = medicineDao.selectOne(new QueryWrapper<Medicine>().eq("id", illnessMedicine.getMedicineId()));
if (ObjectUtil.isNotNull(medicine)) {
list.add(medicine);
}
});
map.put("medicine", list);
}
return map;
}
public Illness getOne(QueryWrapper<Illness> queryWrapper) {
return illnessDao.selectOne(queryWrapper);
}
}
讲一讲findIllnessOne,这个函数是一个用于查找疾病信息的方法。它接受三个参数:kind表示疾病类型,illnessName表示疾病名称,page表示页码。函数首先创建一个HashMap用于存储结果。然后创建一个QueryWrapper对象用于构建查询条件。如果illnessName不为空,则通过like操作符模糊匹配illness_name、include_reason、illness_symptom和special_symptom字段中的任意一个包含illnessName的内容。接下来根据kind和illnessName的值,构建查询条件,包括对kind_id和create_time的筛选和排序。然后通过调用illnessDao.selectMaps方法获取查询结果的列表。接着遍历列表,对每个疾病对象获取id,并通过pageviewDao.selectOne方法查询对应的pageview信息。然后将一些字段放入疾病对象的HashMap中,包括kindName(默认值为"暂无归属类")、create_time、pageview(如果查询失败则为0)和kindName(如果有)。接下来根据疾病列表的大小计算总页数,并将疾病列表和总页数放入HashMap中。最后将HashMap作为结果返回。
主要问题有:
-
重复代码:在kind !=
null和else部分,关于orderByDesc和last的查询条件重复了分页逻辑。可以简化这两个部分的代码。 -
查询条件构造:like操作的字段和值应该使用占位符,这样可以避免SQL注入。
-
断言Assert.notEmpty的使用:代码中使用了Assert.notEmpty,这通常用于校验条件,但在这个上下文中,这个校验似乎是多余的,因为如果illnessName为空,之前的like条件就无法匹配任何结果。
-
使用更合适的数据容器:List和Map已经足够表达结果,可以考虑直接返回一个Page对象,而不是Map,其中包含数据列表和分页信息。
-
代码可读性:一些变量的命名可以更加清晰,例如map变量可以命名为pageResult,以更清楚地表示它包含的是分页结果。
-
避免硬编码:分页大小(即每页9条记录)被硬编码在查询中,可以作为常量提取出来。
-
异常处理:在查询过程中,应该有适当的异常处理机制,以处理潜在的数据库访问错误。
-
数据映射:数据映射和处理逻辑可以封装到单独的方法中,以提高代码的可读性和可维护性。







![Mac 安装 Minikube 及解决 “[ERROR ImagePull]: failed to pull image“ 问题](https://img-blog.csdnimg.cn/direct/27d169bb8b1044689c76c8032ceec120.png)