阿里后端实习二面
记录面试题目,希望可以帮助到大家
类加载的流程?
类加载分为三个部分:加载、连接、初始化
加载
类的加载主要的职责为将.class文件的二进制字节流读入内存(JDK1.7及之前为JVM内存,JDK1.8及之后为本地内存),并在堆内存中为之创建Class对象,作为.class进入内存后的数据的访问入口。在这里只是读入二进制字节流,后续的验证阶段就是要拿二进制字节流来验证.class文件,验证通过,才会将.class文件转为运行时数据结构
连接
类的连接分为三个阶段:验证、准备、解析。
验证:
该阶段主要是为了保证加载进来的字节流符合JVM的规范,不会对JVM有安全性问题。
其中有对元数据的验证,例如检查类是否继承了被final修饰的类;还有对符号引用的验证,例如校验符号引用是否可以通过全限定名找到,或者是检查符号引用的权限(private、public)是否符合语法规定等。
准备:
准备阶段的主要任务是为类的类变量开辟空间并赋默认值。
- 静态变量是基本类型(int、long、short、char、byte、boolean、float、double)的默认值为0
- 静态变量是引用类型的,默认值为null
- 静态常量默认值为声明时设定的值。例如:public static final int i = 3; 在准备阶段,i的值即为3
解析:
该阶段的主要职责为将Class在常量池中的符号引用转变为直接引用,此处针对的是静态方法及属性和私有方法与属性,因为这类方法与私有方法不能被重写。静态属性在运行期也没有多态这一说,即在编译器可知,运行期不可变,所以适合在该阶段解析,如类方法main替换为直接引用,为静态连接,区别于运行时的动态连接
初始化
该阶段初始化类变量值,初始化有两种方式:
1、在声明类变量时,直接给变量赋值
2、在静态初始化块为类变量赋值
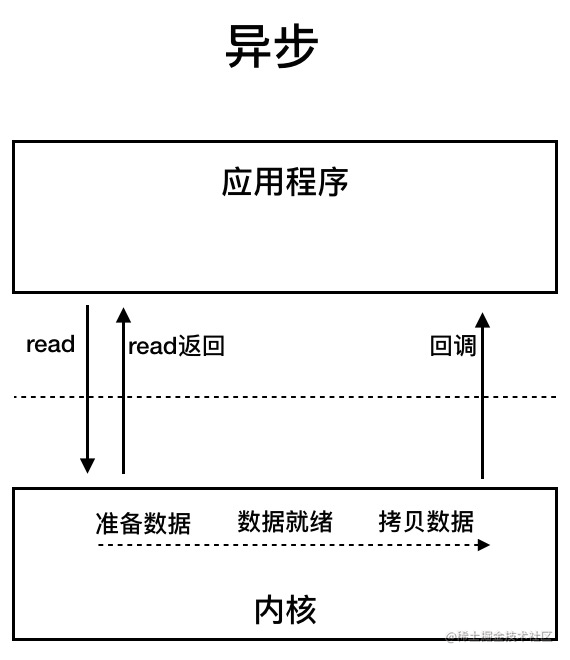
Java的IO模型?
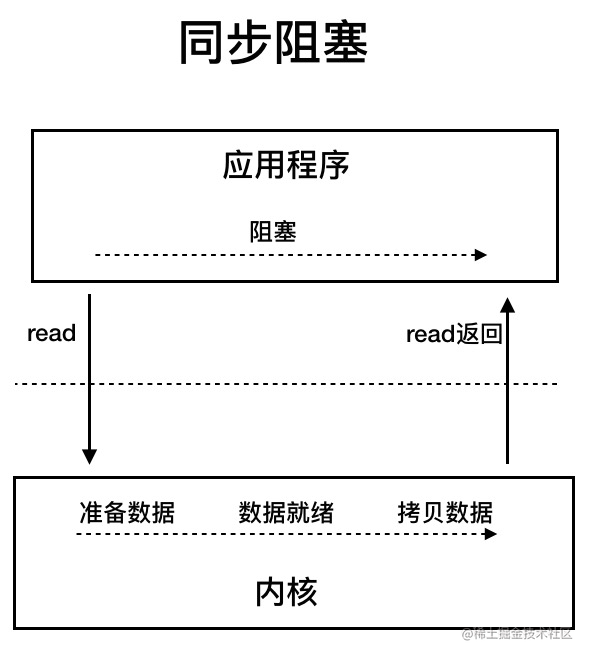
BIO (Blocking I/O)
BIO 属于同步阻塞 IO 模型 。
同步阻塞 IO 模型中,应用程序发起 read 调用后,会一直阻塞,直到内核把数据拷贝到用户空间。
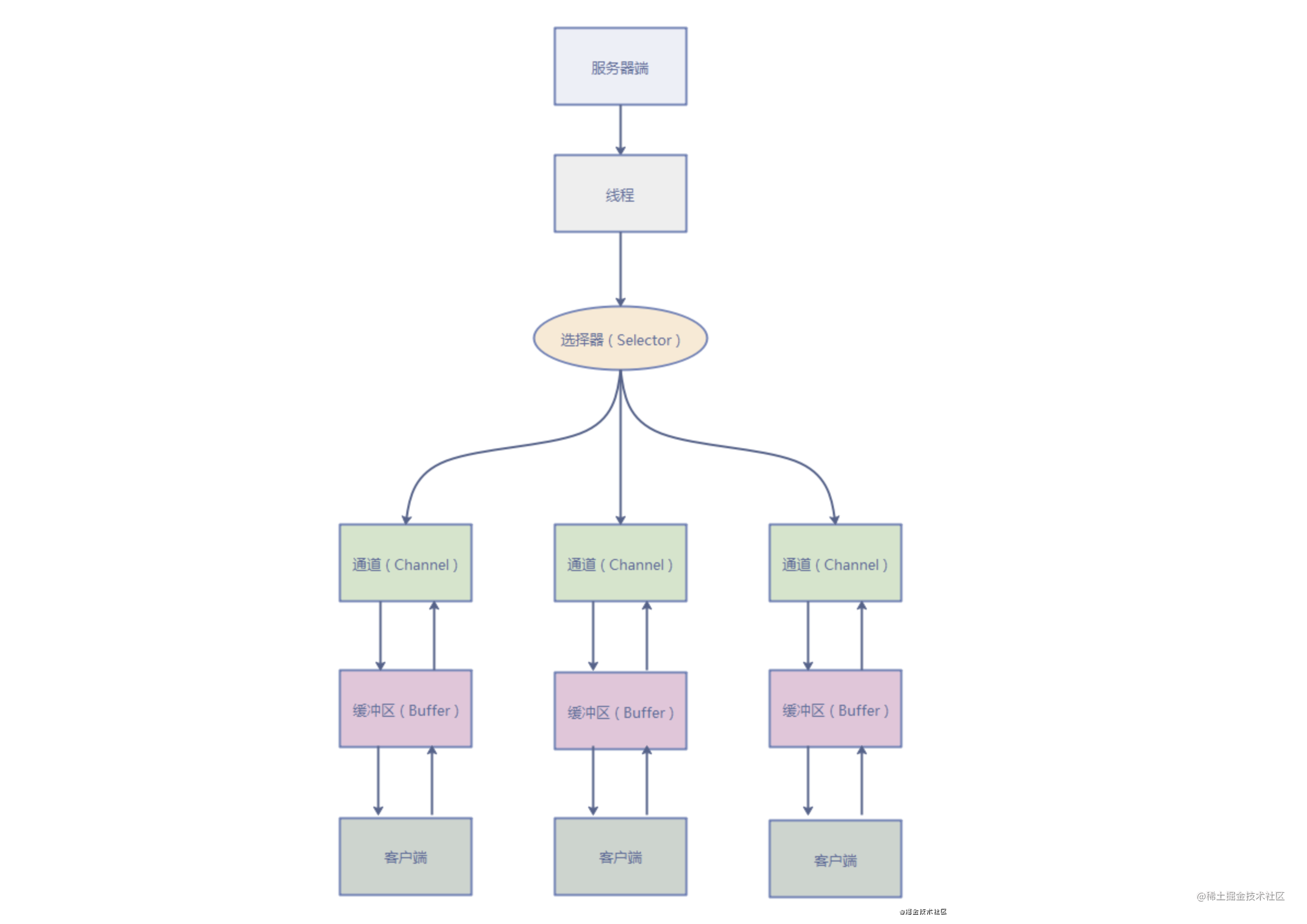
NIO (Non-blocking/New I/O)
Java 中的 NIO 于 Java 1.4 中引入,对应 java.nio 包,提供了 Channel , Selector,Buffer 等抽象。NIO 中的 N 可以理解为 Non-blocking,不单纯是 New。它是支持面向缓冲的,基于通道的 I/O 操作方法。 对于高负载、高并发的(网络)应用,应使用 NIO 。
Java NIO 系统的核心在于:通道(Channel)和缓冲区(Buffer)。通道表示打开到 IO 设备(例如:文件、套接字)的连接。若需要使用 NIO 系统,需要获取用于连接IO 设备的通道以及用于容纳数据的缓冲区。然后操作缓冲区,对数据进行处理。简而言之 Channel 负责传输,Buffer 负责存储。
AIO (Asynchronous I/O)
AIO 也就是 NIO 2。Java 7 中引入了 NIO 的改进版 NIO 2,它是异步 IO 模型。
异步IO则是采用“订阅-发布”模式: 即应用程序向操作系统注册IO监听,然后继续做自己的事情。当操作系统发生IO事件,并且准备好数据后,在主动通知应用程序,触发相应的函数
设计模式,比如单例模式?
定义:
单例模式(Singleton Pattern)是 Java 中最简单的设计模式之一。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。
这种模式涉及到一个单一的类,该类负责创建自己的对象,同时确保只有单个对象被创建。这个类提供了一种访问其唯一的对象的方式,可以直接访问,不需要实例化该类的对象。
- 1、单例类只能有一个实例。
- 2、单例类必须自己创建自己的唯一实例。
- 3、单例类必须给所有其他对象提供这一实例
案例:
在计算机系统中,线程池、缓存、日志对象、对话框、打印机、显卡的驱动程序对象常被设计成单例。这些应用都或多或少具有资源管理器的功能。每台计算机可以有若干个打印机,但只能有一个Printer Spooler,以避免两个打印作业同时输出到打印机中。
Windows 是多进程多线程的,在操作一个文件的时候,就不可避免地出现多个进程或线程同时操作一个文件的现象,所以所有文件的处理必须通过唯一的实例来进行。
懒汉式(线程不安全):
public class Singleton {
private static Singleton instance;
private Singleton (){}
public static Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}
懒汉式(线程安全):
public class Singleton {
private static Singleton instance;
private Singleton (){}
public static synchronized Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}
饿汉式:
public class Singleton {
private static Singleton instance = new Singleton();
private Singleton (){}
public static Singleton getInstance() {
return instance;
}
}
双检锁/双重校验模式:
针对线程安全的懒汉式,我们加锁的范围是整个函数块,但实际上在getSingleton中我们只需要创建一次对象,我们可以缩小锁的粒度,来实现高可用。
public class Singleton {
private volatile static Singleton singleton;
private Singleton (){}
public static Singleton getSingleton() {
if (singleton == null) { //线程1,2同时到达,均通过(instance == null)判断。
// 线程1进入下面的同步块,线程2被阻塞
synchronized (Singleton.class) {
if (singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
}
如果不使用volatile关键字,隐患来自于代码中注释了 erro 的一行,这行代码大致有以下三个步骤:
if (instance == null) {
instance = new Singleton();//erro
}
- 在堆中开辟对象所需空间,分配地址
- 根据类加载的初始化顺序进行初始化
- 将内存地址返回给栈中的引用变量
由于 Java 内存模型允许“无序写入”,有些编译器因为性能原因,可能会把上述步骤中的 2 和 3 进行重排序,顺序就成了
- 在堆中开辟对象所需空间,分配地址
- 将内存地址返回给栈中的引用变量(此时变量已不在为null,但是变量却并没有初始化完成)
- 根据类加载的初始化顺序进行初始化
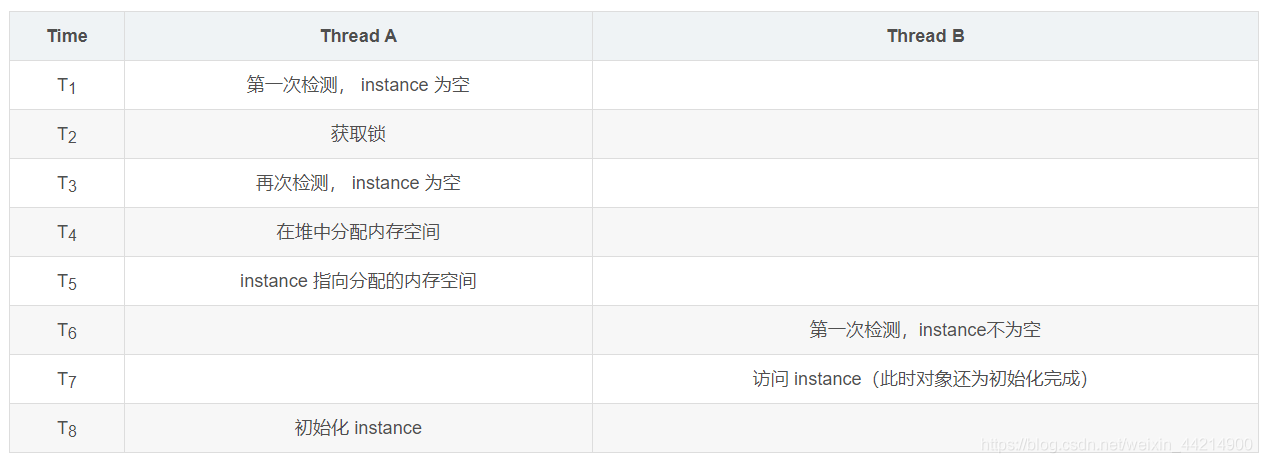
从上面的图中可以看到,线程B返回了一个未初始化成功的事例,voltail就是为了避免这种情况而使用的,相当于加上了一个内存屏障(指重排序时不能把后面的指令重排序到内存屏障之前的位置)。
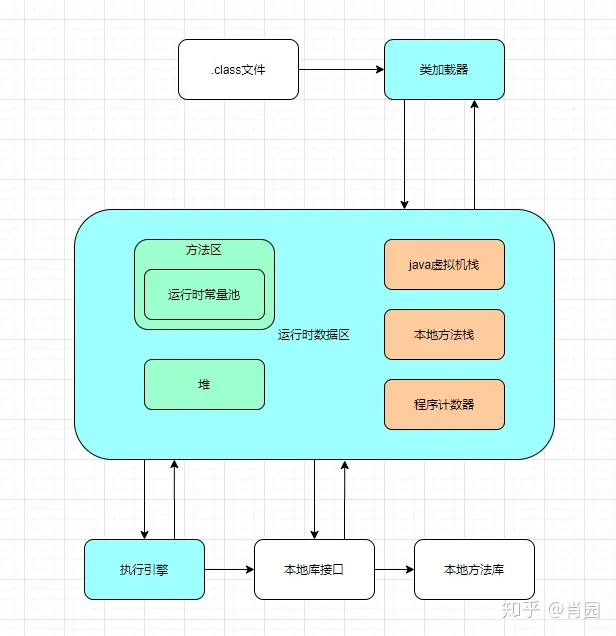
jvm有哪些组成?
如图蓝色填充所示,JVM可以分为3大部分:类加载器,运行时数据区和执行引擎。
类加载器负责加载字节码文件,即java编译后的 .class 文件。
运行时数据区负责存放.class 文件,分配内存。运行时数据区又分为5个部分:
- 方法区:负责存放.class 文件,方法区里有一块区域是运行时常量池,用来存放程序的常量。
- 堆:分配给对象的内存空间(实例)。
方法区和堆是所有线程共享的内存空间。
- java虚拟机栈:每个线程独享的内存空间,每个方法被执行的时候,Java虚拟机都会同步创建一个栈帧存储局部变量表、操作数栈、动态连接、方法出口等信息。
- 本地方法栈:本地native 方法独享的内存空间,为虚拟机使用到的本地方法服务。
- 程序计数器:记录线程执行的位置,方便线程切换后再次执行。
java虚拟机栈,本地方法栈,程序计数器是每个线程独享的。
Java堆有哪些内容?
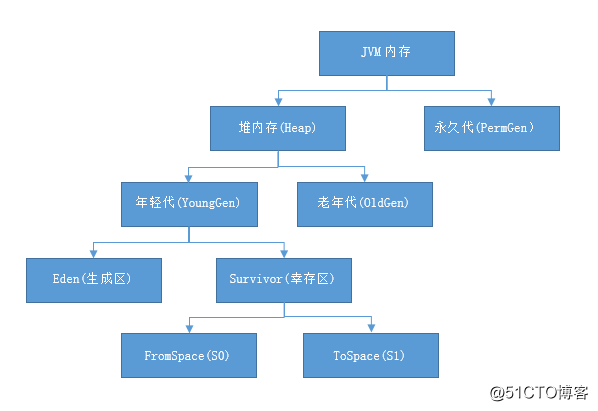
- JVM内存划分为堆内存和非堆内存,堆内存分为年轻代(Young Generation)、老年代(Old Generation),非堆内存就一个永久代(Permanent Generation)。
- 年轻代又分为Eden和Survivor区。Survivor区由FromSpace和ToSpace组成。Eden区占大容量,Survivor两个区占小容量,默认比例是8:1:1。
- 堆内存用途:存放的是对象,垃圾收集器就是收集这些对象,然后根据GC算法回收。
- 非堆内存用途:永久代,也称为方法区,存储程序运行时长期存活的对象,比如类的元数据、方法、常量、属性等。
bean的创建过程?
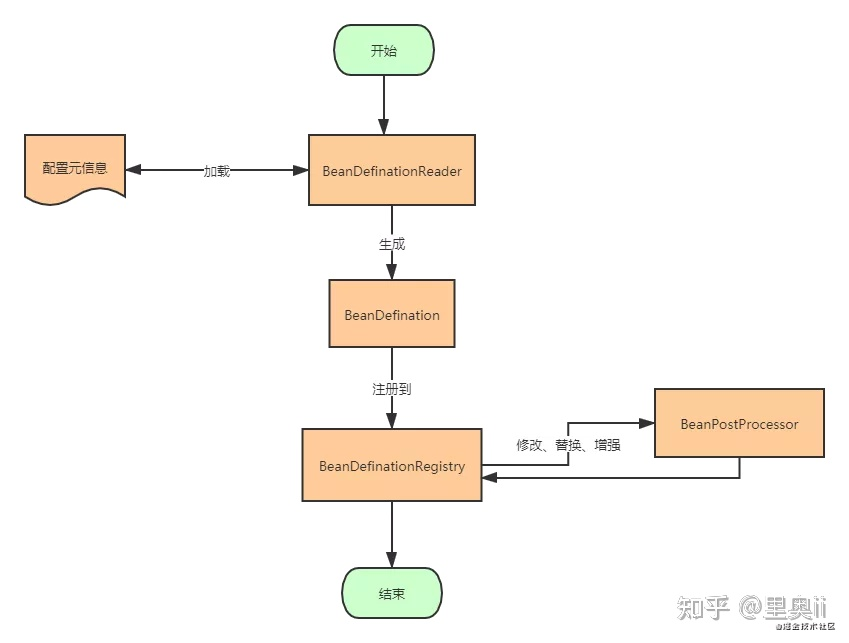
容器启动阶段
配置元信息,BeanDefinationReader加载配置元信息,并将其转化为内存形式的BeanDefination,再其注册到
BeanDefinationRegistry中,BeanDefinationRegistry就是一个存放BeanDefination的大篮子,它也是一种键值对的形式,通过特定的Bean定义的id,映射到相应的BeanDefination。
BeanFactoryPostProcessor是容器启动阶段Spring提供的一个扩展点,主要负责对注册到BeanDefinationRegistry中的一个个的BeanDefination进行一定程度上的修改与替换。
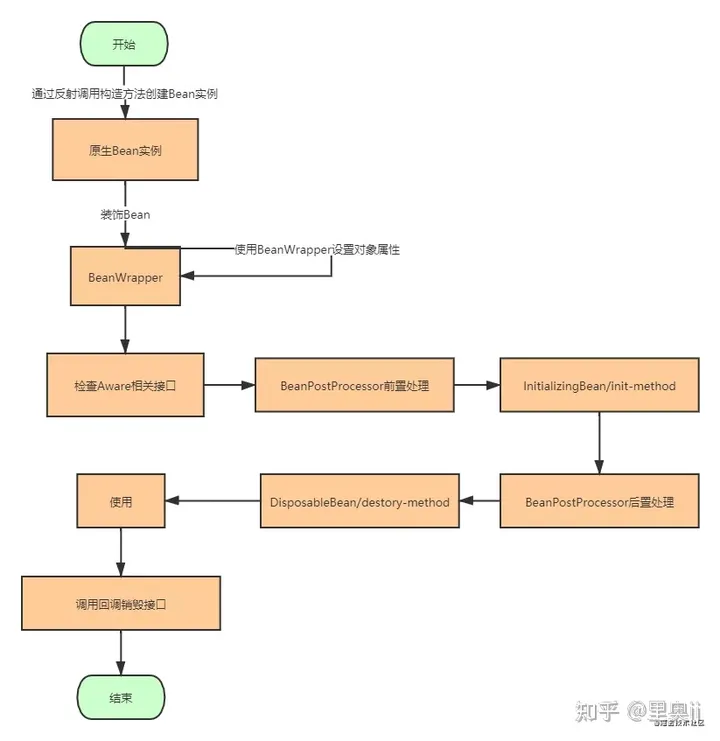
Bean实例化阶段
使用反射的方式创建对象,装饰bean生成beanWrapper封装反射接口API
如果要依赖Spring中的相关对象,使用Spring的相关API,那么就要实现相应的Aware接口,Spring IOC容器就会为我们自动注入相关依赖对象实例,所以我们要进行检查Aware相关接口
BeanPostProcessor前置处理就是在要生产的Bean实例放到容器之前,允许我们程序员对Bean实例进行一定程度的修改,替换等操作。
通过InitializingBean,配置init-method参数自定义初始化逻辑
BeanPostProcess后置处理
这一步对应自定义初始化逻辑,同样有两种方式:
- 实现DisposableBean接口
- 配置destory-method参数
使用
调用回调销毁接口
讲一下爬虫的过程
1.发起请求:
通过HTTP库向目标站点发起请求,即发送一个Request,请求可以包含额外的headers、data等信息,然后等待服务器响应。这个请求的过程就像我们打开浏览器,在浏览器地址栏输入网址:www.baidu.com,然后点击回车。这个过程其实就相当于浏览器作为一个浏览的客户端,向服务器端发送了 一次请求。
2.获取响应内容:
如果服务器能正常响应,我们会得到一个Response,Response的内容便是所要获取的内容,类型可能有HTML、Json字符串,二进制数据(图片,视频等)等类型。这个过程就是服务器接收客户端的请求,进过解析发送给浏览器的网页HTML文件。
3.解析内容:
得到的内容可能是HTML,可以使用正则表达式,网页解析库进行解析。也可能是Json,可以直接转为Json对象解析。可能是二进制数据,可以做保存或者进一步处理。这一步相当于浏览器把服务器端的文件获取到本地,再进行解释并且展现出来。
4.保存数据:
保存的方式可以是把数据存为文本,也可以把数据保存到数据库,或者保存为特定的jpg,mp4 等格式的文件。这就相当于我们在浏览网页时,下载了网页上的图片或者视频。


![助力城市部件[标石/电杆/光交箱/人井]精细化管理,基于YOLOv8全系列模型【n/s/m/l/x】开发构建生活场景下城市部件检测识别系统](https://img-blog.csdnimg.cn/direct/50ec80339b124176bb9d2896100f75c7.png)