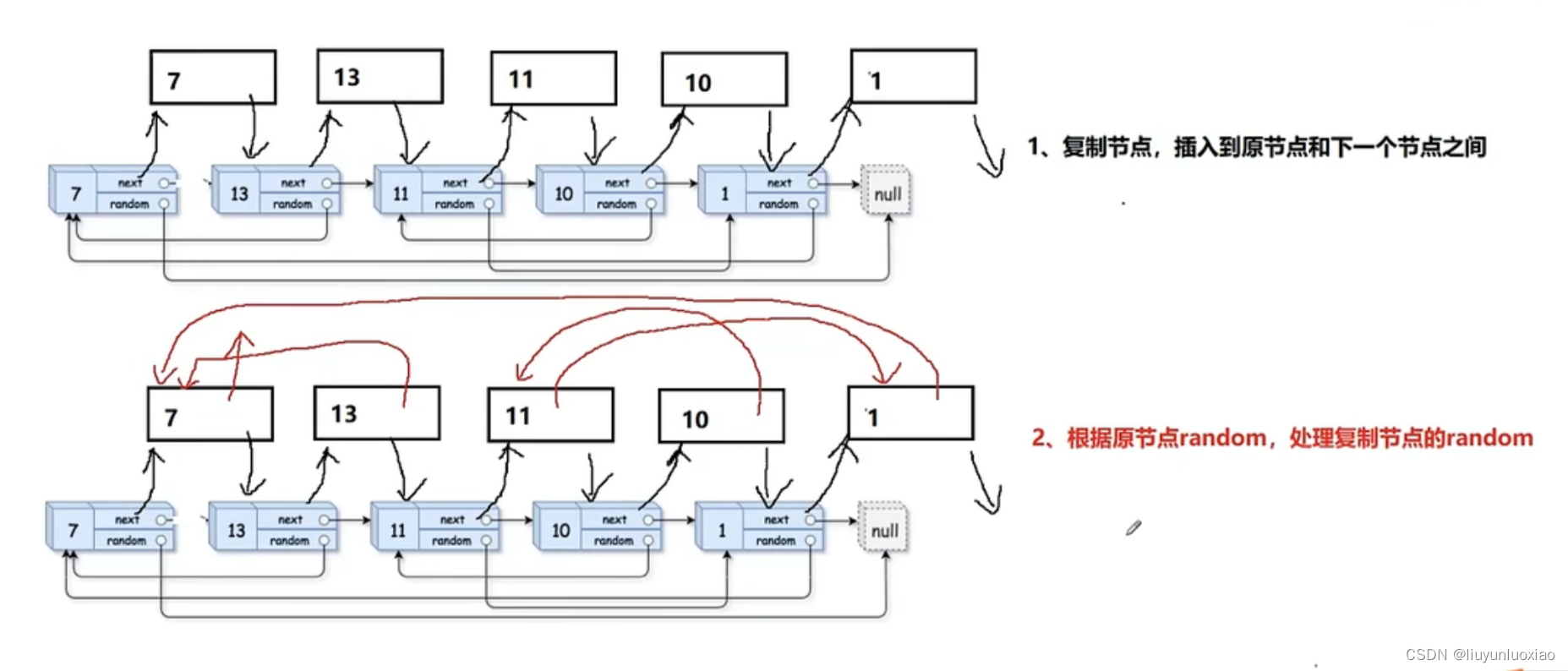
轨道画线分为以下步骤:
1.读取摄像头图片
2.图片灰度处理,截取轨道区域的图片
3.中值滤波处理,并区域取均值后做期望差的绝对值。本人通过一些轨道图片实验,用这种方法二值化得到的效果比caany算子等方法的效果好
4.二值化后再用DBSAN聚类算法对图片分类
5.对分好类的坐标在图片中画图
具体代码如下:
import numpy as np
import cv2
colors = [ (0, 0, 0), (128, 0, 0), (0, 128, 0), (128, 128, 0), (0, 0, 128), (128, 0, 128), (0, 128, 128),
(128, 128, 128), (64, 0, 0), (192, 0, 0), (64, 128, 0), (192, 128, 0), (64, 0, 128), (192, 0, 128),
(64, 128, 128), (192, 128, 128), (0, 64, 0), (128, 64, 0), (0, 192, 0), (128, 192, 0), (0, 64, 128),
(128, 64, 12)]
def cluster(points, radius=100):
"""
points: pointcloud
radius: max cluster range
"""
print("................", len(points))
items = []
while len(points)>1:
item = np.array([points[0]])
base = points[0]
points = np.delete(points, 0, 0)
distance = (points[:,0]-base[0])**2+(points[:,1]-base[1])**2#获得距离
infected_points = np.where(distance <= radius**2)#与base距离小于radius**2的点的坐标
item = np.append(item, points[infected_points], axis=0)
border_points = points[infected_points]
points = np.delete(points, infected_points, 0)
#print("................",len(points))
#print(border_points)
while len(border_points) > 0:
border_base = border_points[0]
border_points = np.delete(border_points, 0, 0)
border_distance = (points[:,0]-border_base[0])**2+(points[:,1]-border_base[1])**2
border_infected_points = np.where(border_distance <= radius**2)
#print("/",border_infected_points)
item = np.append(item, points[border_infected_points], axis=0)
for k in border_infected_points:
if points[k] not in border_points:
border_points=np.append(border_points,points[k], axis=0)
#border_points = points[border_infected_points]
points = np.delete(points, border_infected_points, 0)
items.append(item)
return items
#2.图像的灰度处理、边缘分割
def mean_img(img):
# gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#1.图片的灰度,截取处理
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
imgss=img[540:743, 810:1035]
gray_img = gray_img[540:741, 810:1030]#[540:741, 810:1080]
img2=gray_img
print(img2.mean())
#中值滤波
gray_img = cv2.medianBlur(gray_img, ksize=3)
cv2.imshow("Dilated Image", gray_img)
cv2.waitKey(0)
#2.行做期望差,3个值取均值再做差
for i in range(gray_img.shape[0]):
for j in range(gray_img.shape[1]-2):
ss1=gray_img[i, j:j+2].mean()
m=abs(gray_img[i][j]-ss1)
if m>13:
img2[i][j] =255
else:
img2[i][j] =0
img2[:,-3:]=0
cv2.imshow("img_mean", img2)
cv2.waitKey(0)
# 3.腐蚀膨胀消除轨道线外的点
kernel = np.uint8(np.ones((5, 2)))
# 膨胀图像.....为了使得轨道线更粗,且补足轨道线缺失的地方
dilated = cv2.dilate(img2, kernel)
#显示膨胀后的图像
#dilated[:, -6:] = 0
cv2.imshow("Dilated Image", dilated)
cv2.waitKey(0)
ss=np.argwhere(dilated>0)
print(ss)
#聚类算法
items = cluster(ss, radius=5)
print(len(items))
i=0
for item in items:
print("====>", len(item))
if len(item)>500:
for k in item:
imgss[k[0]][k[1]]=colors[i]
i+=1
cv2.imshow("ss",imgss)
cv2.waitKey(0)
return ss
if __name__ == '__main__':
img_path=r"图片路径"
img=cv2.imread(img_path)
ss=mean_img(img)
ss=np.array(ss)
items=cluster(ss, radius=25)通过以上聚类的方法处理后的图片如下:

接下来对两类点进行处理。在这里目前想到的处理方式有两种:一是:首先对每个类取行的中值或者均值,即每个类的每行只保留一个坐标(均值或者中间值),去除掉了每行两边的坐标。但这个效果不太好,后面会附加代码和处理的图片结果;二是根据霍夫曼求直线的方法,自己重新写个获取直线。
一、取均值或者中值的代码如下:
import numpy as np
import cv2
import time
colors = [ (0, 0, 0), (128, 0, 0), (0, 128, 0), (128, 128, 0), (0, 0, 128), (128, 0, 128), (0, 128, 128),
(128, 128, 128), (64, 0, 0), (192, 0, 0), (64, 128, 0), (192, 128, 0), (64, 0, 128), (192, 0, 128),
(64, 128, 128), (192, 128, 128), (0, 64, 0), (128, 64, 0), (0, 192, 0), (128, 192, 0), (0, 64, 128),
(128, 64, 12)]
def cluster(points, radius=100):
"""
points: pointcloud
radius: max cluster range
"""
print("................", len(points))
items = []
while len(points)>1:
item = np.array([points[0]])
base = points[0]
points = np.delete(points, 0, 0)
distance = (points[:,0]-base[0])**2+(points[:,1]-base[1])**2#获得距离
infected_points = np.where(distance <= radius**2)#与base距离小于radius**2的点的坐标
item = np.append(item, points[infected_points], axis=0)
border_points = points[infected_points]
points = np.delete(points, infected_points, 0)
#print("................",len(points))
#print(border_points)
while len(border_points) > 0:
border_base = border_points[0]
border_points = np.delete(border_points, 0, 0)
border_distance = (points[:,0]-border_base[0])**2+(points[:,1]-border_base[1])**2
border_infected_points = np.where(border_distance <= radius**2)
#print("/",border_infected_points)
item = np.append(item, points[border_infected_points], axis=0)
if len(border_infected_points)>0:
for k in border_infected_points:
if points[k] not in border_points:
border_points=np.append(border_points,points[k], axis=0)
#border_points = points[border_infected_points]
points = np.delete(points, border_infected_points, 0)
items.append(item)
return items
def k_mean(out):
print("........................开始计算图片的均值.....................")
median = {}
i = 1
for items in out:
median[str(i)] = []
result = items[:, :-1]
ss = result.shape
result = result.reshape(ss[1], ss[0])
result = result[0].tolist()
result = list(set(result)) # 去掉result重复的值
for m in result:
#print("...............", m, "...............................")
item = np.where(items[:, :-1] == m)[0]
# median[str(i)].append(items[item[len(item)//2]].tolist()) #中位数,有用
median[str(i)].append([m, int(items[item][:, -1:].mean())]) # 均值
i += 1
return median
#直线的拟合
def lines(median,distances):
print("...................直线的拟合......................")
for items in median:
n_m=np.array(median[items])#转换为array数据
means=n_m[:,1:]#取坐标的第二列
lens=n_m[-1][0]+1#总共多少个坐标,即坐标个数
#print(lens)
#1.获取x1,x2的坐标
if lens%4>2:
x10=lens//4+1
else:
x10 = lens // 4
x20=x10*3
x=lens//2
#print("x1,x2: ",x10,x20)
#2.获取y1,y2的坐标
y10=means[:lens//2].mean()
y20 = means[lens // 2-1:].mean()
y=means.mean()
#print("y1,y2: ", y10, y20)
#3.获取直线斜率k k=(y1-y2)/(x1-x2)
k=(y10-y20)/(x10-x20)
#print("k: ",k)
#print("x,y: ",x,y)
#4.预测某个点的y值 y-pred=k*(x_pred-x)+y n_m[i]
for i in range(len(n_m)):
y_pred = k * (n_m[i][0] - x) + y
#print("===>",y_pred,n_m[i][0],n_m[i][1])
if abs(y_pred-n_m[i][1])>distances:
n_m[i][1]=y_pred
#median[items][i][1]=int(y_pred)
median[items]=n_m.tolist()
return median
#2.图像的灰度处理、边缘分割
def mean_img(img,x1,x2,y1,y2):
imgs=img.copy()
img4 = img.copy()
#1.图片的灰度,截取处理
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
gray_img = gray_img[x1:x2, y1:y2]#[540:741, 810:1080],截取轨道画线的区域,对该区域识别轨道
img2=gray_img
#2.中值滤波
gray_img = cv2.medianBlur(gray_img, ksize=3)
# cv2.imshow("Dilated Image", gray_img)
# cv2.waitKey(0)
st=time.time()
for i in range(gray_img.shape[0]):
for j in range(gray_img.shape[1]-2):
ss1 = gray_img[i, j:j + 2].mean()
m=abs(gray_img[i][j]-ss1)
if m>9:
img2[i][j] =255
else:
img2[i][j] =0
img2[:,-3:]=0
et = time.time()
print("kmeans时间",et-st)
# cv2.imshow("img_mean", img2)
# cv2.waitKey(0)
# 3.腐蚀膨胀消除轨道线外的点
st1=time.time()
kernel = np.uint8(np.ones((2, 1)))
# 膨胀图像.....为了使得轨道线更粗,且补足轨道线缺失的地方
dilated = cv2.dilate(img2, kernel)
#显示膨胀后的图像
# cv2.imshow("Dilated Image", dilated)
# cv2.waitKey(0)
kernel = np.ones((2, 2), np.uint8)
dilated = cv2.erode(dilated, kernel)
cv2.imshow("ss",dilated)
cv2.waitKey(0)
ss=np.argwhere(img2>0)#dilated
#聚类算法
items = cluster(ss, radius=3)
print(len(items))
i=0
out=[]#获得大于300个坐标的类
for item in items:
if len(item)>300:
out.append(item)
print("====>", len(item))
for k in item:
img[k[0]+x1][k[1]+y1]=colors[i]#[540:743, 810:1035]
i+=1
# cv2.imshow("ss",img)
# cv2.waitKey(0)
et1 = time.time()
print("聚类时间:", et1 - st1)
#求聚类的每类每行的中位数
median=k_mean(out)
#根据中位数画图
j=0
for item in median:
for k in median[item]:
#print(k[0],k[1])
imgs[k[0]+x1][k[1]+y1] = colors[j] # [540:743, 810:1035]
j+=1
et3=time.time()
print("中位数时间:", et3 - et1)
print(".....................................","\n")
#用直线拟合,首先用两个均值得到初始线的斜率及均值坐标,然后不断对远离的坐标点拟合
distances=4
while distances>0:
median=lines(median,distances)
distances-=1
#画图
j = 0
for item in median:
for k in median[item]:
# print(k[0],k[1])
img4[k[0] + x1][k[1] + y1] = colors[j] # [540:743, 810:1035]
j += 1
et4=time.time()
print("直线拟合消耗时间:",et4-et3)
return out
if __name__ == '__main__':
start=time.time()
img_path=r图片路径"
img=cv2.imread(img_path)
out=mean_img(img,x1=650,x2=741,y1=825,y2=1025)
end=time.time()
print("time:",end-start)
上述的直线拟合没有用最小二乘法,处理后的画图结果如下:


显然,拟合的结果并不好。下面用霍夫曼求直线的方法拟合。
二、霍夫曼圆找直线
这种方法不用上面的代码,简单直接,并且效果更好。代码和结果如下:
代码:
import numpy as np
import time
import cv2
#2.图片处理,再通过上面的聚类函数获取轨道的类
def mean_img(img,x1,x2,y1,y2):
#1.图片的灰度,截取处理
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
gray_img = gray_img[x1:x2, y1:y2]#[540:741, 810:1080],截取轨道画线的区域,对该区域识别轨道
#2.霍夫曼直线求点
edges=cv2.Canny(gray_img, 120, 255, apertureSize=3)
lines = cv2.HoughLinesP(edges, 1, np.pi / 180, 30, minLineLength=50, maxLineGap=10)
ss=[]#获取每条直线的长度的平方,以便后面根据直线的长度排序
for line in lines:
# print(type(line))
x10, y10, x20, y20 = line[0]
distance=(y20-y10)**2+(x10-x20)**2#每条直线长度的平方
ss.append([distance,[x10, y10, x20, y20]])
ss=np.array(ss)
indexs=np.lexsort([ss[:,0]])#根据长度对直线由小到大排序,获得排序的index值
data=ss[indexs,:]#data:排序后的ss
lines=data[:,-1:]
index_2 =[]#从lines获取轨道两边的直线
index_2.append(lines[-1][0])#首先获取长度最长的一条直线
for i in range(len(lines)-1,0,-1):
if abs(lines[i][0][0]-index_2[0][0])>25:#另一条直线的获取是从后向前遍历,两直线一端的横坐标的差大于25时,则是另外一条直线,获得后结束后面的遍历
index_2.append(lines[i][0])
break
#画图
for iten in index_2:
x10, y10, x20, y20 = iten
cv2.line(img, (x10 + y1, y10 + x1), (x20 + y1, y20 + x1), (0, 0, 255), 2)
cv2.imwrite("保存文件的路径\\120.jpg", img)
# cv2.imshow("line_detect_possible_demo", img)
# cv2.waitKey(0)
if __name__ == '__main__':
start=time.time()
img_path=r"图片路径"
img=cv2.imread(img_path)
#x1, x2, y1, y2:表示在相机图片中截取要画线区域的轨道部分的区域(减小计算,使背景更简单)
out = mean_img(img, x1=650, x2=741, y1=825, y2=1025) # x1=540,x2=741,y1=810,y2=1030
end = time.time()
print("time:", end - start)
效果如下:

当然,这个是近焦相机拍的近距离的轨道,可以再用远焦相机拍远距离的轨道拟合直线,然后将两条直线融合。