目录
时间序列网络
NARX 网络
NAR 网络
非线性输入-输出网络
定义问题
使用神经网络时间序列拟合时间序列数据
使用命令行函数拟合时间序列数据
选择数据
选择训练算法
创建网络
准备要训练的数据
划分数据
训练网络
测试网络
查看网络
分析结果
闭环网络
向前一步预测网络
后续步骤
动态神经网络的优势是时间序列预测。要查看在开环形式、闭环形式和开环/闭环多步预测中应用 NARX 网络的示例。
提示
有关时间序列数据深度学习,可以参考使用深度学习进行序列分类。
例如,假设您有 pH 中和过程的数据。想要设计一个网络,该网络可以根据过去的 pH 值和过去的酸值以及流入水槽的液体的基本流速来预测水槽内溶液的 pH 值。总共有 2001 个时间步,有它们的序列。
可以用两种方法解决此问题:
-
使用神经网络时间序列,如使用神经网络时间序列拟合时间序列数据中所述。
-
使用命令行函数,如使用命令行函数拟合时间序列数据中所述。
注意
要以交互方式构建、可视化和训练深度学习神经网络,请使用深度网络设计器。
一般最好从 App 开始,然后使用该 App 自动生成命令行脚本。在使用任何方法之前,首先通过选择数据集来定义问题。每个神经网络 App 都可以访问若干采样数据集,可以使用这些数据集来试验工具箱。如果有要解决的特定问题,可以将自己的数据加载到工作区中。
时间序列网络
可以训练神经网络来求解三种类型的时间序列问题。
NARX 网络
在第一类时间序列问题中,要根据时间序列 y(t) 的过去值和另一个时间序列 x(t) 的过去值来预测前者的将来值。这种预测形式称为外因(外部)输入非线性自回归或 NARX,可以写作如下形式:
y(t) = f(y(t – 1), ..., y(t – d), x(t – 1), ..., (t – d))使用此模型根据失业率、GDP 等经济变量预测股票或债券的将来值。还可以将此模型用于系统辨识,其中模型表示动态系统,例如化工工艺、制造系统、机器人、航空航天器等。
NAR 网络
在第二类时间序列问题中,只涉及一个序列。时间序列 y(t) 的将来值仅根据该时间序列的过去值进行预测。这种预测形式称为非线性自回归(或 NAR),可以写作如下形式:
y(t) = f(y(t – 1), ..., y(t – d))可以用此模型来预测金融工具,但不使用伴随系列。
非线性输入-输出网络
第三类时间序列问题类似于第一类,它也涉及两个序列:一个输入序列 x(t) 和一个输出序列 y(t)。这里想要根据 x(t) 的先前值预测 y(t) 的值,但不知道 y(t) 的先前值。该输入/输出模型可以写作如下形式:
y(t) = f(x(t – 1), ..., x(t – d))NARX 模型将提供比该输入-输出模型更好的预测,因为它使用包含在 y(t) 的先前值中的附加信息。但是,在某些应用中,y(t) 的先前值不可用。只有在这种情况下,才会使用输入-输出模型,而不是 NARX 模型。
定义问题
要为工具箱定义时间序列问题,请将一组时间序列预测变量向量排列为一个元胞数组中的列。然后,将另一组时间序列响应向量(每个预测变量向量的正确响应向量)排列成第二个元胞数组。此外,在某些情况下,只需要有一个响应数据集。例如,可以定义以下时间序列问题,在其中使用先前的序列值预测下一个值:
responses = {1 2 3 4 5};下一节说明如何使用神经网络时间序列来训练用于拟合时间序列数据集的网络。此示例使用工具箱附带的示例数据。
使用神经网络时间序列拟合时间序列数据
此示例说明如何使用神经网络时间序列训练浅层神经网络来拟合时间序列数据。
使用 ntstool 打开神经网络时间序列。
ntstool选择网络
可以使用神经网络时间序列来求解三种不同类型的时间序列问题。
-
在第一类时间序列问题中,您要根据时间序列 y(t) 的过去值和另一个时间序列 x(t) 的过去值来预测前者的将来值。这种形式的预测称为具有外因(外部)输入的非线性自回归网络(或 NARX)。
-
在第二类时间序列问题中,只涉及一个序列。时间序列 y(t) 的将来值仅根据该时间序列的过去值进行预测。这种形式的预测称为非线性自回归(或 NAR)。
-
第三个时间序列问题类似于第一种类型,涉及两个序列,输入序列(预测变量)x(t) 和输出序列(响应变量)y(t)。这里您想要根据 x(t) 的先前值预测 y(t) 的值,但不知道 y(t) 的先前值。
对于此示例,请使用 NARX 网络。点击选择网络 > NARX 网络。

选择数据
神经网络时间序列提供了示例数据来帮助您开始训练神经网络。
要导入 pH 中和过程示例数据,请选择导入 > 更多示例数据集 > 导入 pH 中和数据集。可以使用此数据集来训练神经网络,以使用酸碱溶液流量来预测溶液的 pH 值。如果从文件或工作区导入自己的数据,则必须指定预测变量和响应变量。
有关导入数据的信息显示在模型摘要中。此数据集包含 2001 个时间步。预测变量有两个特征(酸碱溶液流量),响应变量有一个特征(溶液 pH 值)。

将数据分成训练集、验证集和测试集。保留默认设置。数据拆分为:
-
70% 用于训练。
-
15% 用于验证网络是否正在泛化,并在过拟合前停止训练。
-
15% 用于独立测试网络泛化。
创建网络
标准 NARX 网络是一个双层前馈网络,其中在隐藏层有一个 sigmoid 传递函数,在输出层有一个线性传递函数。该网络还使用抽头延迟线来存储 x(t) 和 y(t) 序列的先前值。会注意到,NARX 网络的输出 y(t) 将(通过延迟)反馈给网络的输入,因为 y(t) 是 y(t–1),y(t–2),...,y(t–d) 的函数。然而,为了有效训练,可以打开此反馈回路。
由于在网络训练期间真实输出是可用的,因此可以使用如下所示的开环架构,其中使用真实输出,而不是反馈估计输出。这样有两个优点。第一,前馈网络的输入更准确。第二,生成的网络为纯前馈架构,因此可以使用更高效的算法进行训练。此网络在设计时间序列 NARX 反馈神经网络中有更详细的介绍。
层大小值定义隐藏神经元的数量。保持默认层大小值10。将时滞值更改为4。如果网络训练性能不佳,可能需要调整这些数字。
可以在网络窗格中看到网络架构。

训练网络
要训练网络,请选择训练 > 莱文贝格-马夸特法训练。这是默认训练算法,与点击训练效果相同。

对于大多数问题,都推荐使用莱文贝格-马夸特 (trainlm) 进行训练。对于含噪问题或小型问题,贝叶斯正则化 (trainbr) 可以获得更好的解,但代价是耗时更长。对于大型问题,推荐使用量化共轭梯度 (trainscg),因为它使用的梯度计算比其他两种算法使用的雅可比矩阵计算更节省内存。
在训练窗格中,可以看到训练进度。训练会一直持续,直到满足其中一个停止条件。在此示例中,训练会一直持续,直到 6 次迭代的验证误差持续增大(“满足验证条件”)。
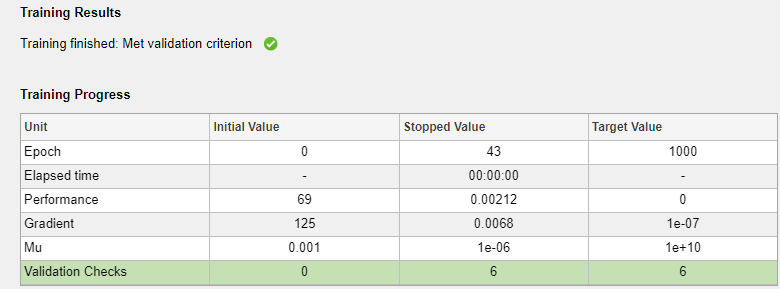
分析结果
模型摘要包含关于每个数据集的训练算法和训练结果的信息。

可以通过生成绘图来进一步分析结果。要对误差自相关性绘图,请在绘图部分中,点击误差自相关性。自相关性图说明了预测误差在时间上是如何关联的。对于完美的预测模型,自相关函数应该只有一个非零值,并且应在零滞后时出现(此值为均方误差)。这表示预测误差彼此完全不相关(白噪声)。如果预测误差中存在显著相关性,则应该可以改进预测,这可以通过增加抽头延迟线中的延迟数量来实现。在这种情况下,除了零滞后时的 1 以外,相关性大约在零附近的 95% 置信界限范围内,因此模型看上去是足够的。如果需要更精确的结果,可以重新训练网络。这将更改网络的初始权重和偏置,并可能在重新训练后生成改进的网络。

查看输入-误差互相关性图,以获得网络性能的额外验证。在绘图部分中,点击输入-误差相关图。该输入-误差互相关性图说明误差如何与输入序列 x(t) 相关。对于完美的预测模型,所有相关性都应为零。如果输入与误差相关,则应该可以改进预测,这可以通过增加抽头延迟线中的延迟数量来实现。在这种情况下,大多数相关性都在零附近的置信边界范围内。

在绘图部分中,点击响应。这显示输出、响应(目标)和误差与时间的关系。它还指示选择了哪些时间点进行训练、测试和验证。

如果对网络性能不满意,可以执行以下操作之一:
-
重新训练网络。
-
增加隐藏神经元的数量。
-
使用更大的训练数据集。
如果基于训练集的性能很好,但测试集的性能很差,这可能表明模型出现了过拟合。减小层大小(从而减少神经元的数量)可以减少过拟合。
还可以评估基于附加测试集的网络性能。要加载附加测试数据来评估网络,请在测试部分中,点击测试。模型摘要显示附加测试数据结果。也可以生成图来分析附加测试数据结果。
生成代码
选择生成代码 > 生成简单的训练脚本以创建 MATLAB 代码,从命令行重现前面的步骤。如果要了解如何使用工具箱的命令行功能来自定义训练过程,则创建 MATLAB 代码会很有帮助。在使用命令行函数拟合时间序列数据中,您可以更详细地研究生成的脚本。

导出网络
可以将经过训练的网络导出到工作区或 Simulink®。也可以使用 MATLAB Compiler™ 工具和其他 MATLAB 代码生成工具部署网络。要导出训练网络和结果,请选择导出模型 > 导出到工作区。

使用命令行函数拟合时间序列数据
了解如何使用工具箱的命令行功能的最简单方法是从 App 生成脚本,然后修改它们以自定义网络训练。例如,参考上一节中使用神经网络时间序列生成的简单脚本。
% Solve an Autoregression Problem with External Input with a NARX Neural Network
% Script generated by Neural Time Series app
% Created 13-May-2021 17:34:27
%
% This script assumes these variables are defined:
%
% phInputs - input time series.
% phTargets - feedback time series.
X = phInputs;
T = phTargets;
% Choose a Training Function
% For a list of all training functions type: help nntrain
% 'trainlm' is usually fastest.
% 'trainbr' takes longer but may be better for challenging problems.
% 'trainscg' uses less memory. Suitable in low memory situations.
trainFcn = 'trainlm'; % Levenberg-Marquardt backpropagation.
% Create a Nonlinear Autoregressive Network with External Input
inputDelays = 1:4;
feedbackDelays = 1:4;
hiddenLayerSize = 10;
net = narxnet(inputDelays,feedbackDelays,hiddenLayerSize,'open',trainFcn);
% Prepare the Data for Training and Simulation
% The function PREPARETS prepares timeseries data for a particular network,
% shifting time by the minimum amount to fill input states and layer
% states. Using PREPARETS allows you to keep your original time series data
% unchanged, while easily customizing it for networks with differing
% numbers of delays, with open loop or closed loop feedback modes.
[x,xi,ai,t] = preparets(net,X,{},T);
% Setup Division of Data for Training, Validation, Testing
net.divideParam.trainRatio = 70/100;
net.divideParam.valRatio = 15/100;
net.divideParam.testRatio = 15/100;
% Train the Network
[net,tr] = train(net,x,t,xi,ai);
% Test the Network
y = net(x,xi,ai);
e = gsubtract(t,y);
performance = perform(net,t,y)
% View the Network
view(net)
% Plots
% Uncomment these lines to enable various plots.
%figure, plotperform(tr)
%figure, plottrainstate(tr)
%figure, ploterrhist(e)
%figure, plotregression(t,y)
%figure, plotresponse(t,y)
%figure, ploterrcorr(e)
%figure, plotinerrcorr(x,e)
% Closed Loop Network
% Use this network to do multi-step prediction.
% The function CLOSELOOP replaces the feedback input with a direct
% connection from the output layer.
netc = closeloop(net);
netc.name = [net.name ' - Closed Loop'];
view(netc)
[xc,xic,aic,tc] = preparets(netc,X,{},T);
yc = netc(xc,xic,aic);
closedLoopPerformance = perform(net,tc,yc)
% Step-Ahead Prediction Network
% For some applications it helps to get the prediction a timestep early.
% The original network returns predicted y(t+1) at the same time it is
% given y(t+1). For some applications such as decision making, it would
% help to have predicted y(t+1) once y(t) is available, but before the
% actual y(t+1) occurs. The network can be made to return its output a
% timestep early by removing one delay so that its minimal tap delay is now
% 0 instead of 1. The new network returns the same outputs as the original
% network, but outputs are shifted left one timestep.
nets = removedelay(net);
nets.name = [net.name ' - Predict One Step Ahead'];
view(nets)
[xs,xis,ais,ts] = preparets(nets,X,{},T);
ys = nets(xs,xis,ais);
stepAheadPerformance = perform(nets,ts,ys)可以保存脚本,然后从命令行运行它,以重现上次 App 会话的结果。还可以编辑脚本来自定义训练过程。在此例中,请执行脚本中的每个步骤。
选择数据
该脚本假设预测变量和响应向量已加载到工作区中。如果未加载数据,可以按如下方式加载它:
load ph_dataset此命令将预测变量 pHInputs 和响应变量 pHTargets 加载到工作区中。
此数据集是工具箱的示例数据集之一。有关可用数据集的信息,可以参考浅层神经网络的样本数据集。可以输入命令 help nndatasets 来查看所有可用数据集的列表。可以使用自己的变量名称从这些数据集中加载变量。例如,命令
[X,T] = ph_dataset;将pH数据集预测变量加载到元胞数组X中,将pH数据集响应变量加载到元胞数组T中。
选择训练算法
定义训练算法。网络使用默认的莱文贝格-马夸特算法 (trainlm) 进行训练。
trainFcn = 'trainlm'; % Levenberg-Marquardt backpropagation.对于莱文贝格-马夸特无法产生期望的准确结果的问题,或对于大型数据问题,请考虑使用以下命令之一将网络训练函数设置为贝叶斯正则化 (trainbr) 或量化共轭梯度 (trainscg):
net.trainFcn = 'trainbr';
net.trainFcn = 'trainscg';创建网络
创建一个网络。NARX 网络 narxnet 是一个前馈网络,其默认 tan-sigmoid 传递函数在隐藏层,线性传递函数在输出层。此网络有两个输入。一个是外部输入,另一个是来自网络输出的反馈连接。完成网络训练后,可以关闭此反馈连接,详见后续步骤。对于这些输入中的每一个,都有一条抽头延迟线来存储先前的值。要为 NARX 网络分配网络架构,必须选择与每条抽头延迟线相关联的延迟,以及隐藏层神经元的数量。在后面的步骤中,需要将输入延迟和反馈延迟的取值范围指定为 1 到 4,并将隐藏神经元的数量指定为 10。
inputDelays = 1:4;
feedbackDelays = 1:4;
hiddenLayerSize = 10;
net = narxnet(inputDelays,feedbackDelays,hiddenLayerSize,'open',trainFcn);注意
增加神经元数量和延迟数量需要更多计算,当数量设置得太高时,可能会出现数据过拟合倾向,但这也使得网络能够求解更复杂的问题。层越多,需要的计算也越多,但使用更多的层可以使网络更高效地求解复杂问题。要使用多个隐藏层,请在 narxnet 命令中输入隐藏层大小作为数组的元素。
准备要训练的数据
准备用于训练的数据。当训练包含抽头延迟线的网络时,有必要用网络预测变量和响应变量的初始值来填充延迟。可以使用工具箱命令 preparets 来完成此过程。此函数有三个输入参数:网络、预测变量和响应变量。该函数返回填充网络中的抽头延迟线所需的初始条件,以及修改后的预测变量序列和响应变量序列(其中已删除初始条件)。可以按如下方式调用该函数:
[x,xi,ai,t] = preparets(net,X,{},T);划分数据
设置数据划分。
net.divideParam.trainRatio = 70/100;
net.divideParam.valRatio = 15/100;
net.divideParam.testRatio = 15/100;基于以上设置,数据将被随机划分为三组,其中 70% 用于训练,15% 用于验证,15% 用于测试。
训练网络
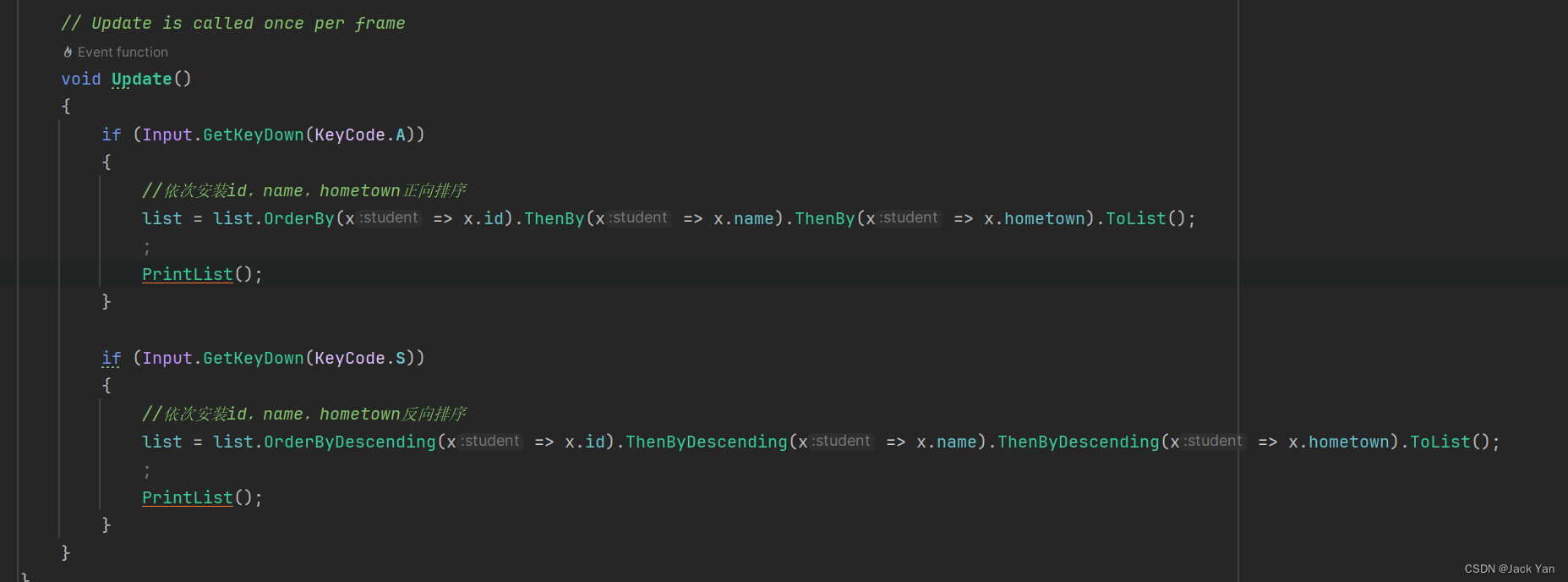
训练网络。
[net,tr] = train(net,x,t,xi,ai);在训练期间,将打开以下训练窗口。此窗口显示训练进度,并允许随时点击停止按钮
![]()
来中断训练。

如果验证误差在六次迭代持续增加,则训练将停止。
测试网络
测试网络。可以使用经过训练的网络来计算网络输出。以下代码将计算网络输出、误差和整体性能。请注意,要仿真具有抽头延迟线的网络,需要为这些延迟信号指定初始值。这是通过在早期阶段由 preparets 提供的输入状态 (xi) 和层状态 (ai) 来完成的。
y = net(x,xi,ai);
e = gsubtract(t,y);
performance = perform(net,t,y)
performance =
0.0042查看网络
查看网络图。
view(net)如图所示:

分析结果
绘制性能训练记录以检查是否存在潜在过拟合。
figure, plotperform(tr)如图所示:
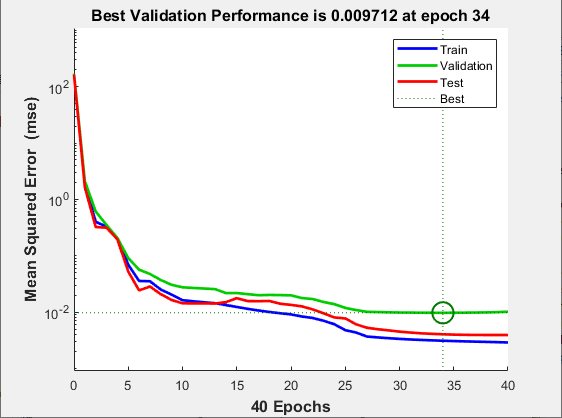
此图显示,训练误差和验证误差一直在降低,直至突出显示的轮数处。图中并未显示发生了任何过拟合,因为验证误差在此轮之前没有增加。
所有训练以开环(也称为串并行架构)形式完成,包括验证和测试步骤。典型的工作流是完全以开环方式创建网络,并且仅当网络经过训练(包括验证和测试步骤)后,它才会变换为闭环,以进行向前多步预测。同样地,神经网络时间序列中的R值是根据开环训练结果计算的。
闭环网络
闭合 NARX 网络上的回路。当 NARX 网络上的反馈回路处于打开状态时,它将执行向前一步预测。它根据 y(t) 和 x(t) 的先前值预测 y(t) 的下一个值。反馈回路闭合后,它可用于执行向前多步预测。这是因为 y(t) 的预测值将用于取代 y(t) 的实际将来值。以下命令可用于闭合回路和计算闭环性能
netc = closeloop(net);
netc.name = [net.name ' - Closed Loop'];
view(netc)
[xc,xic,aic,tc] = preparets(netc,X,{},T);
yc = netc(xc,xic,aic);
closedLoopPerformance = perform(net,tc,yc)
closedLoopPerformance =
0.4014如图所示:
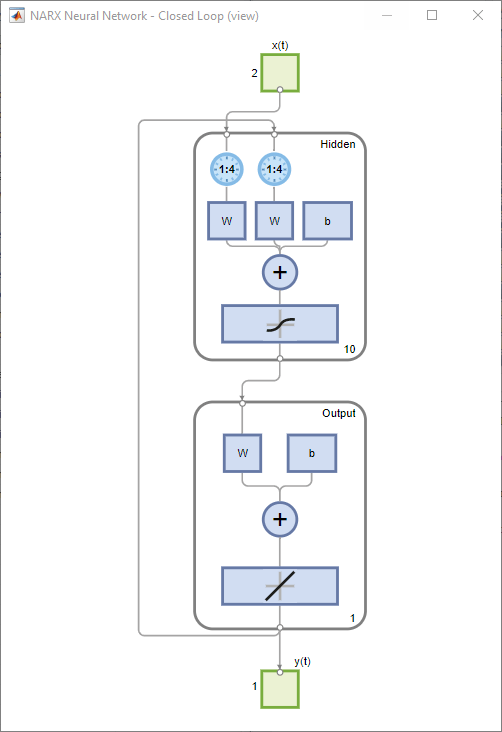
向前一步预测网络
从网络中删除一个延迟,以提前一个时间步获得预测。
nets = removedelay(net);
nets.name = [net.name ' - Predict One Step Ahead'];
view(nets)
[xs,xis,ais,ts] = preparets(nets,X,{},T);
ys = nets(xs,xis,ais);
stepAheadPerformance = perform(nets,ts,ys)
stepAheadPerformance =
0.0042如图所示:

在此图中,可以看到该网络与先前的开环网络相同,只是从每条抽头延迟线中删除了一个延迟。随后的网络输出是 y(t + 1),而不是 y(t)。当为某些应用部署网络时,这可能会有所帮助。
后续步骤
如果网络性能不令人满意,可以尝试以下任一方法:
-
使用init 将初始网络权重和偏置重置为新值,然后再次训练。
-
增加隐藏神经元的数量或延迟的数量。
-
使用更大的训练数据集。
-
增加输入值的数量(如果有更多相关信息可用)。
-
尝试其他训练算法。
要进一步熟悉命令行操作,请尝试以下任务:
-
在训练期间,打开绘图窗口(如误差相关图),并观察其动画效果。
-
从命令行使用 plotresponse、ploterrcorr 和 plotperform 等函数绘图。
每次训练神经网络时,由于初始权重和偏置值随机,并且将数据划分为训练集、验证集和测试集的方式也不同,可能会产生不同的解。因此,针对同一问题训练的不同神经网络对同一输入可能给出不同输出。为确保找到准确度良好的神经网络,需要多次重新训练。
如果需要更高的准确度,可以采用几种其他方法来改进初始解。