本文字数:6686字
预计阅读时间:35分钟
01
背景
1、业务背景
在传统视频审核场景中,审核人员需要对进审视频中的文字内容进行逐一审核,避免在文字上出现敏感词、违禁词或者广告等相关词汇。这种人工审核费时费力,并且由于审核人员存在个体差异,审核尺度很难在整体上保持一致。针对当前问题我们提出以下解决方案:
首先,使用OCR对视频帧进行文字识别;
其次,使用审核系统当前关键词库对识别出来的文字进行关键词匹配;
然后,当匹配到关键词时,暂时将此视频进行屏蔽(机器审核拒绝),并纪录此文字对应视频截图,再对截图进行命中关键词标注;
最后,当人工审核时,参考OCR审核结果 输出最后人工审核结果。
当然,在实现上述OCR关键词检测方案的过程中,还有以下几个问题急需去解决:
视频帧数据量巨大:一般视频帧率为24fps,即每秒24帧图片。平均视频时长130s,而每天平均进审20万视频。所以,平均一天的图片处理量大概为794,950,148(7.9亿),数据量特别大;
OCR识别算力要求高、耗时长:OCR算法本身需要一定算力,导致每张图片处理时间较长,审核系统当前人工审核平均时间 30分钟内可以完成,所以OCR识别要在人审之前完成,才能产生效果;
OCR识别算法需要不断升级:随着使用会逐渐发现OCR在文字识别上的错误,OCR模型需要提供纠错、升级的能力。
2、技术选型
1)OCR技术背景
目前OCR技术普遍有两种实现方式:
端到端: 即将整个文本图像作为一个序列输入到神经网络中,直接输出识别结果。常见模型例如pgnet:
1)它的优势是检测一步到位,不需要格外的字符检测,并且对字符的图像质量要求较低,具有较好的鲁棒性;
2) 劣势在于训练难度较高,需要大量训练数据。识别结果也不够准确,尤其是字符间距较小或字形复杂的情况下。二阶段:即将OCR过程分成 文本检测、文本识别两个阶段。常见模型例如EasyOcr、chineseOcr、PaddleOcr:
1)它的优势是训练难度低,不需要大量的训练数据。同时识别准确度也较高;
2)劣势在于需要额外的文字检测过程,过程复杂。
在实际测试中我们也发现pgnet的预训练权重文件大部分都是基于英文训练集的,少有高质量中文与训练文件,同时中文识别能力也较弱,并且这种方案更适合文字分布密集的业务场景,例如:车牌、仪表识别等。同我们现有的视频审核场景应用并不符合,所以我们不采用pgnet方案。
2)OCR推理效果对比
基于我们的业务场景,我们针对市面上常见的开源支持中文的OCR算法进行效果对比:
| OCR框架 | 精确率 | 召回率 | 推理时间(ms) | 支持自定义训练 | 开发语言 |
|---|---|---|---|---|---|
| EasyOcr | 88.15% | 86.26% | 42.76 ms | 否 | Python |
| ChineseOcr(lite) | 91.61% | 92.82% | 21.85 ms | 是 | Python,C |
| PaddleOcr | 98.90% | 95.23% | 17.51 ms | 是 | Python,Java |
对比三种方案:
EasyOcr由于不支持 自定义训练,每次都需要全参数重新全量训练模型,导致模型迭代周期过长 ,先将他排除。PaddleOcr的性能和准确性比ChineseOcr和ChineseOcrLite略好一些,同时最重要的是,模型支持ONNX(Open Neural Network Exchange)转换使得 模型可以直接在Java平台使用DJL(Deep Java Library)框架进行加载推理。而Java是我们部门常用技术栈,系统监控、问题排查工具较为全面,所以我们也比较倾向于使用PaddleOcr作为项目的OCR模型。
3)OCR模型进一步分析
带着上述对比效果,我们进一步分析了PaddleOcr、ChineseOcr两种OCR模型的具体差异。
ChineseOcr整体流程图如下:
 PaddleOcr整体流程图如下:
PaddleOcr整体流程图如下:
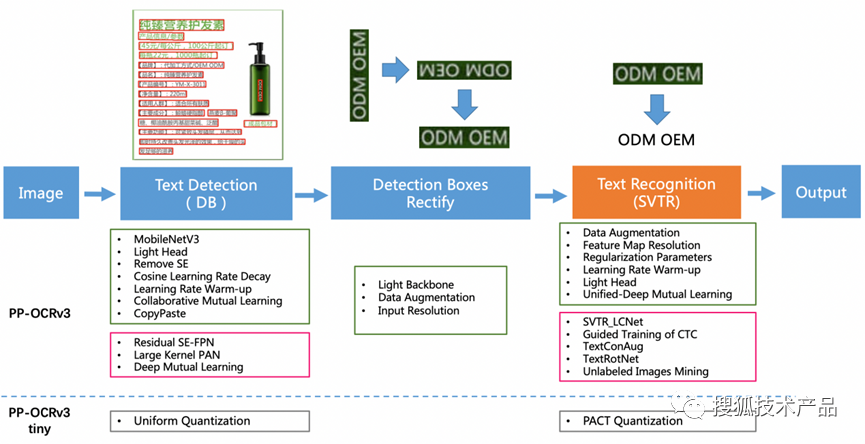
整体架构上两者非常相似,ChineseOcr是先使用VGG进行文本方向检测,然后交给Yolo3进行文本识别,由于Yolo3识别的是单个文字,则需要将Yolo3识别出来的文字进行合并整理,然后传给CRNN模型进行文本识别。而PaddleOcr使用DB模型进行文字检测,检测后进行了文字方向调整,调整后送入SVTR模型进行文字识别。
具体对比下他们使用的文字检测、文字识别模型。
文字检测模型对比:
YOLOv3是目标检测算法,可以检测包括文字在内的各种物体。YOLOv3的检测原理是将图像划分为多个网格,每个网格负责检测一个物体。如果网格内检测到物体,则会输出物体的类别和边界框。
DB是基于递归神经网络的文字检测算法,可以检测任意形状的文字。DB的检测原理是先使用卷积神经网络提取图像中的文字特征,然后使用递归神经网络预测文字的边界框。
YOLOv3和DB的区别在于:
检测原理不同。YOLOv3 使用目标检测的原理,DB使用递归神经网络的原理;
检测效果不同。YOLOv3的检测效果在一般应用中较好,DB的检测效果在复杂场景下较好;
速度不同。YOLOv3的速度较快,DB的速度较慢。
结合审核业务中,由于审核的视频场景较为复杂 同时我们的最终目的是使用OCR减轻人力成本,处理速度很重要但是相比于准确性来说,我们更加注重复杂场景中的文字识别能力。
所以,文字检测模型上,我们更倾向于DB模型。
文字识别模型对比:
CRNN是端到端的文字识别算法,将文字识别视为一个序列学习问题,将整个文本图像作为一个序列输入到神经网络中,直接输出识别结果。CRNN的优势在于:简洁易实现,不需要额外的字符分割等步骤。
SVTR是基于变分自编码器的文字识别算法,可以有效地捕捉字符之间的相关性。模型首先使用卷积神经网络提取图像中的字符特征,然后使用变分自编码器对字符特征进行编码。编码后的特征表示了字符的形状、位置和相关性。最后,使用线性回归模型将编码后的特征映射到文本序列。SVTR的优势在于:识别效果准确,尤其是在字符间距较小或字符形状复杂的情况下。
在查询资料的过程中,我们发现早期PaddleOcr版本在文本识别上使用的正式CRNN模型,但从PaddleOcrV3版本开始, 文字识别模型被替换成了SVTR模型。从官网的测试数据来看,替换后模型的文字识别率从74.8%增加到了80.1%增加了5.3%。
所以,在文字识别模型上,我们也是更倾向于SVTR。
综上所述,在进一步了解PaddleOcr和ChineseOcr各自文字检测、文字识别模型后,我们最终选择了准确率更高的PaddleOcr模型。
02
项目解决方案
确定了paddleOcr的技术选型之后,我们针对目前面临的问题逐一进行解决。
1、视频帧去重-解决视频帧数据量大的问题
使用Md5对视频级别进行去重:通过对视频内容进行Md5散列,对视频整体进行去重。这部分去重平均可以过滤掉当天28%重复视频数据;
提取关键帧:使用帧间差分法对视频进行关键帧提取。使用此方式,平均每个视频只需要取31帧关键帧图片,而每个视频平均137.2秒,如果取全部帧的话则需要3288帧图片,此方式 平均可以过滤掉 99.1% 的帧画面;
关键帧特征提取去重:使用chinese_clip模型提取关键帧的特征信息,存储到Milvus数据库中,进行topK查询,如果前K条数据特征余弦相似度 小于阈值,则认为这两张图片重复,去掉重复的关键帧。经测算,使用此方法平均可以过滤掉30%的帧画面。
如此一来,经过上述三种去重方式,我们将一天的计算量 由7.9亿张图片,缩减到了360万左右。(794,950,148 * 72%*0.9%*70% ≈ 3,605,893)
2、使用工程化算法-解决OCR响应慢问题
1)当前技术背景
在描述如何解决响应时间的问题前,我们先来同步一下当前的技术背景:
当前我们使用的OCR技术,会把OCR过程分为两个步骤:
1)文字检测即找到图片中可能是文字的部分;2)文字识别即针对划定范围的图片,识别出对应的文字。
当前OCR在CPU上单核心识别一张图,检测耗时在700ms左右,识别耗时平均300ms左右,平均一张图有3处可识别的文字,线性处理一张图片耗时700+1200 ≈ 1900ms。
2)审核场景下的需求
在审核场景下对OCR使用有两个核心需求:
对视频关键帧进行OCR希望尽量的快;
如果计算资源无法达到要求,则需要尽可能的对最新的视频完整的进行OCR检测。因为如果排队检测,往往队列先进先出,OCR处理的都是旧数据,拖延的时间过长之后,可能人工都已经审核完成了,再出OCR结果,这时候意义就不大了。另外,OCR检测的最小单位是一个视频的所有截图,因为如果检测不完整,漏掉了可能出现问题的截图,导致给出错误机审建议,那其实还不如不检测。
3)审核场景下OCR加速方案
整体思路:
利用cpu多核心尽量并行化处理文字检测和文字识别;
尽快完成新进审的一个视频,而不是将cpu算力分散给每个视频,因为 在算力有限的前提下,相同时间内即使完成少量视频的OCR,也比每个视频都进行一部分OCR检测要好。
具体方案:
控制入口:
1)使用MQ对OCR任务解耦: 视频进审时,发送待OCR数据到MQ,OCR服务通过订阅MQ接收任务。利用MQ可以在特殊审核时期(两会)或流量突增(搜狐活动)时,随时增减机器,快速应对突发流量;
2)跟据自身算力优先处理近期OCR任务:
(1)同过MQ收到消息后,缓存到Redis ZSet集合中,使用时间戳作为score进行排序,并维护队列最大长度淘汰时间久远且没来得及处理的OCR任务;
(2)在服务实例内,从redis ZSet集合中轮询OCR任务进行处理。保证使用所有算力处理最新视频,但不受流量和算力程度影响。并行处理任务:
1)配置线程池,保证cpu每个核心上只有一个计算任务执行,最大化利用cpu;
2)每个计算线程既可以处理文字检测又可以处理文字识别,避免图像中文字数量导致线程需要线程等待,无法及时识别;
举例:由于文字检测、文字识别存在先后顺序,如果按照传统方式 使用生产者消费者模式,配置文字检测、文字识别使用的线程数比例R,按比例执行的话,一旦出现比例同预期不同的话,会影响执行效果。
比如:如果文字检测出来的任务多于预期文字识别的任务,这会导致 文字识别线程数少,无法及时识别;如果文字检测出来的任务少于预期文字识别的任务,这会导致文字识别线程池空闲,浪费资源,图片无法及时检测。
3) 任务队列中,每当处理完一张图片的文字检测后,所有线程优先处理文字识别,保证图片顺序上 每张图片即时处理,当出现命中屏蔽词的情况后,无需针对后续图片进行OCR,节约时间;
4)在队列接近队尾时,即剩余图片数少于线程数时,优先处理文字检测。避免队列末尾时,出现只有一个线程在处理文字检测,其他线程等待文字检测结果再处理文字识别的情况,最大化利用计算资源。
4)方案效果
图片集合:https://monitor.bjcnc.scs.sohucs.com/ocr/files/433044128.zip (共11张图片,需要55次文字识别)
测试代码:https://monitor.bjcnc.scs.sohucs.com/ocr/files/OcrTimeTest.java
| 文字检测总耗时 | 文字识别总耗时 | OCR识别耗时 | 耗时减少 | |
|---|---|---|---|---|
| 单线程 | 8028 | 18923 | 27014 | |
| 文字检测-文字识别 生产消费模式 根据单线程效果,线程比例为1:3 | 8345 | 19725 | 10797 | 相较于单线程耗时减少 60.03% |
| 当前优化方案 4个线程 | 10723 | 23921 | 8748 | 相较于单线程耗时减少 67.62% 相较于生产消费模式 耗时减少19% |
可以看到在文字检测、文字识别均比生产者-消费者模式耗时多的情况下,整体耗时上仍然较生产-消费模式有速度提升。
5)加速原因分析
分别比较生产消费、当前方案两种代码执行方式都以4个线程并发执行,假设文字检测、文字识别单独任务耗时相同,只比较方案带来的影响,如下图:
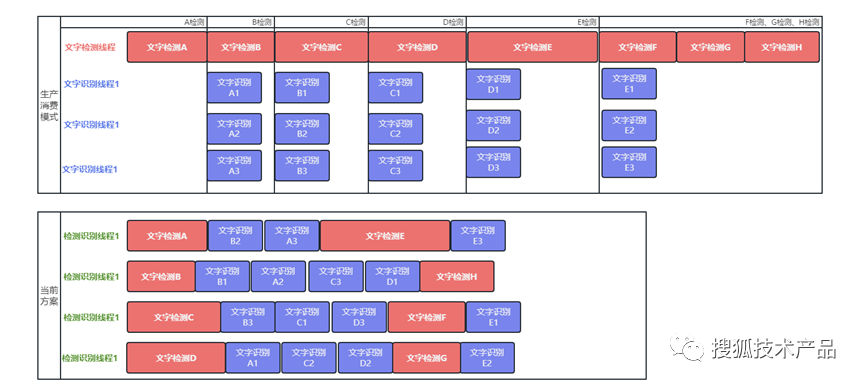
可以非常直观的看到:
生产消费模式由于其固定的生产消费模型,整体执行效率必然会被较慢的一方拖垮整体速度(图示中文字检测较慢,如果是文字识别较慢,效果也是一样的)。
整体速度收到了较慢的一方影响,导致线程执行时,会有一段时间的等待任务,从而导致时间浪费。
而当前方案中,
每个线程既可以执行文字检测,又可以执行文字识别,无论真实数据是哪个步骤耗时长都不影响整体执行效率,提高执行效率;
在任务快结束时,会优先处理文字检测(文字检测FGH是在文字识别前面执行的),以避免出现识别任务完成后,剩余线程都在等待识别结果的情况,提高资源利用率;
文字识别时,优先处理有检测结果的任务,以保证一旦识别出来的文字内容命中审核屏蔽策略时,即时停止后续流程,避免资源浪费。
3、提供完整模型微调方案-提升OCR垂直领域精度
当前审核应用OCR的方式是在审核过程中对场景截图进行OCR检测,生成文字后进行关键词检测。如果命中关键词,会对视频进行机审风险处置,后续还会再进行一次人工审核。
我们每天会使用定时任务从前一天的审核记录中找出OCR机审风险但人审通过的数据,结合审核记录中的截图打包成待重新校对的数据包。微调时,人工从这些数据包中筛选出OCR漏检、误检的数据,进行微调。
1)数据标注
由于人工标注成本较高,所以我们在数据标注中采取了两种方式:
针对普通场景,如字幕、视频中的画外音、店铺名称等。我们截取典型的背景图,并使用程序在这些背景图片中自动化生成随机文字,包括随机文字大小、颜色、倾斜角度、文字数等。这样可以大大降低数据标注成本,快速增强模型针对普通场景时OCR的能力。
例如:原图为

我们通过程序,在这个背景图中增加随机文字 包括了图片中随机文字数、随机文字内容、随机文字位置:
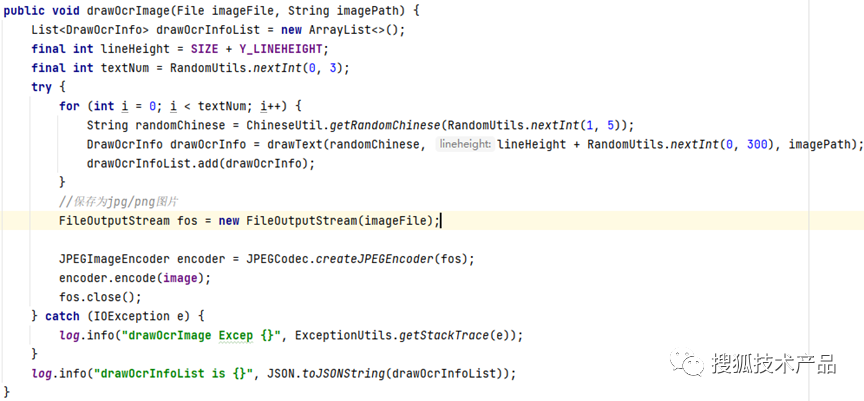
img5
随机文字颜色,随机文字倾斜角度:
最终生成:

并且由于是程序生成的文字,文字标注信息也会一并生成:

如此一来,大大降低了人工标注的成本。
对于一些出现场景不多,但是文体和文字背景质地非常贴合,例如:锦旗、标语、跑马灯上的文字,程序就比较难模仿生成了。同时我们对于这些文字也是需要加强审核能力的,这种情况下,我们就会从审核记录中抽取针对性的图片,对图片进行标注。对于图片搜索,我们使用Clip模型对进审图片生成特征向量存储到Milvus向量库中,使用Clip是为了对齐文本和图片特征,这样我们搜索时,可以同时使用文字、图片进行搜索。
文字搜索:
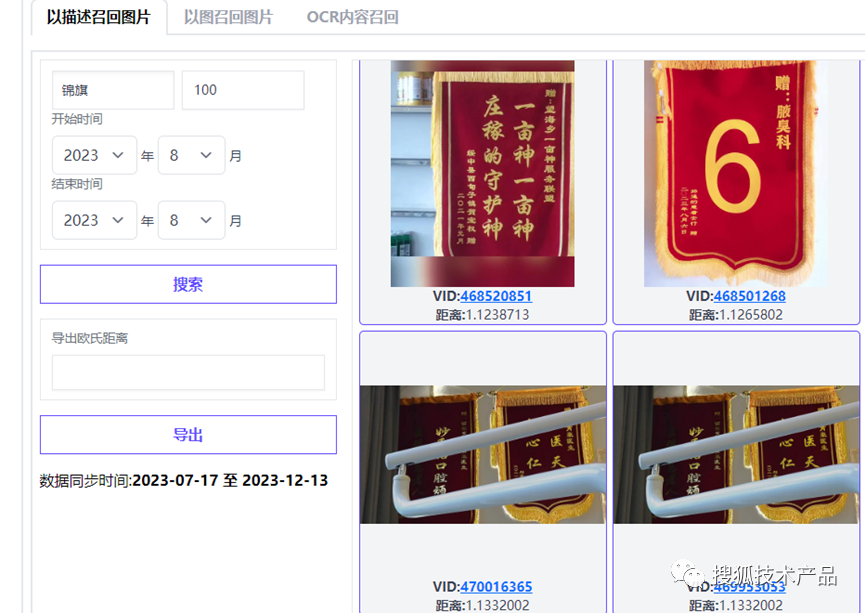
图片搜索:
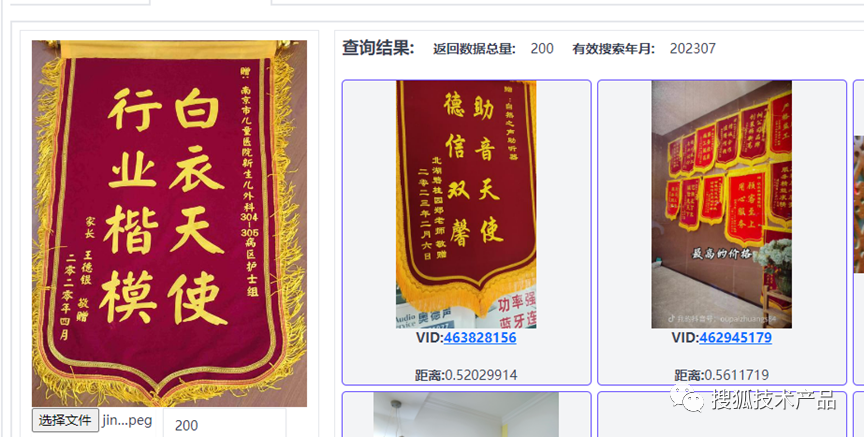
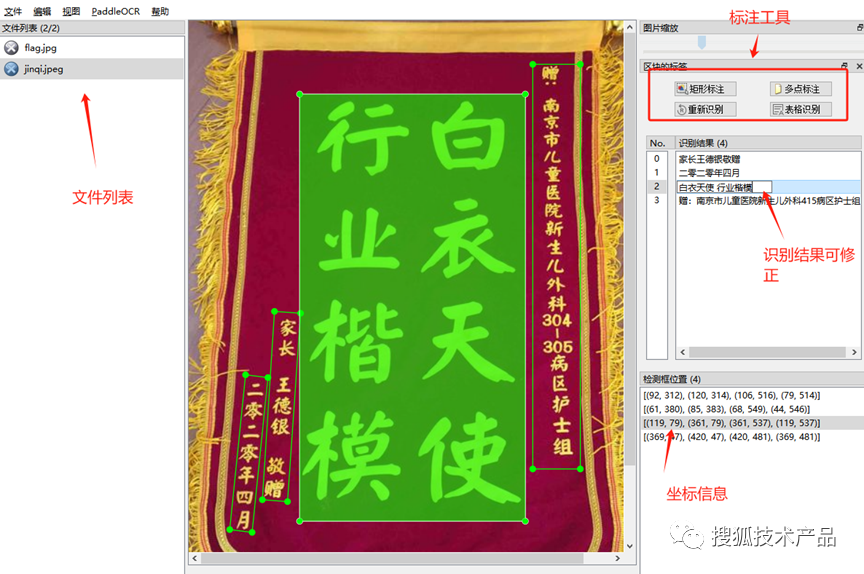
有了这些召回图片后,我们使用PPOCRLabel工具对数据进行半自动化标注,标注完成后,标注人员可以针对已标注的数据进行图片调整、文字内容调整,自动化生成可训练数据文件。
2)模型微调
1 文本检测模型
1.1数据选择
数据量:我们准备5000张的文本检测数据集用于模型微调;
数据标注:人工标注时检测框与实际语义内容一致。如在火车票场景中,姓氏与名字可能离得较远,但是它们在语义上属于同一个检测字段,这里也需要将整个姓名标注为1个检测框。
模型上使用官方预训练模型进行微调,其精度与泛化性能是目前提供的最优预训练模型。
1.2 训练参数说明
Global:
pretrained_model: XXX.pdparams # 预训练模型路径
Optimizer:
lr:
name: Cosine
learning_rate: 0.001 # 学习率
warmup_epoch: 2 #预热轮次
regularizer:
name: 'L2' # 使用L2正则化 防止过拟合
factor: 0 #学习率衰减系数
Train:
loader:
shuffle: True
drop_last: False #是否丢弃因数据集样本数不能被 batch_size 整除而产生的最后一个不完整的mini-batch
batch_size_per_card: 4 # 单卡batch size
num_workers: 4 #用于加载数据的子进程个数,若为0即为不开启子进程,在主进程中进行数据加载如果是单卡训练 一般由于显存限制batch size设置为4就可以了学习率可以调整为5e-5左右。
1.3 微调流程
我们将标注好的数据以6:2:2 的比例分成三组,分别为训练集、验证集、测试集。
执行模型训练
在paddleocr release根目录下执行;
python tools/train.py -c configs/det/xxx.yml -o Global.pretrained_model="./pretrain_models/"训练完成后进行评估模型
python tools/eval.py -c configs/det/xxx.yml -o Global.checkpoints="./output/det/best_accuracy"评估会从Precision、Recall、Hmean(F-Score)多个角度进行评估。
执行模型导出
python tools/export_model.py -c ./output/det/xxx.yml -o Global.pretrained_model="./output/det/best_accuracy" Global.save_inference_dir="./output/det_inference/"导出到./output/det_inference/ 目录下 就可以进行后续推理了。
1.4 微调成果
审核系统通过近5000条数据的微调后,新版本在实际数据验证中文字检测能力有了一定的提升。
原始图片:


微调前:


微调后:


红色箭头为方便标注 后续添加。可以看到对于一些在特定质地下的文字,文字检测的能力有了一定的提升。
2 文本识别模型
2.1 数据选择
数据量:我们准备了5000张的文本识别数据集用于模型微调;
数据标注:文本识别时,需要按照以上标注好的数据按照图片坐标进行截图,即一张图唯一对应一段文字。
2.2 训练参数说明
Global:
pretrained_model: XXX.pdparams # 预训练模型路径
Optimizer:
lr:
name: Piecewise # 分段常熟衰减
decay_epochs : [700, 800] #衰减轮次
values : [0.001, 0.0001] # 学习率
warmup_epoch: 5 #预热轮次
regularizer:
name: 'L2' # 使用L2正则化 防止过拟合
factor: 0 #学习率衰减系数
Train:
dataset:
name: SimpleDataSet
data_dir: ./train_data/
label_file_list:
- ./train_data/train_list.txt
ratio_list: [1.0] # 采样比例,默认值是[1.0]
loader:
shuffle: True
drop_last: False
batch_size_per_card: 4 # 单卡batch size
num_workers: 4 #用于加载数据的子进程个数,若2.3 微调流程
同文字检测一样,我们将标注好的数据以6:2:2的比例分成三组,分别为训练集、验证集、测试集。流程同文本检测一样。
执行模型训
在paddleocr release根目录下执行:
python tools/train.py -c configs/rec/xxx.yml -o Global.pretrained_model="./pretrain_models/"训练完成后进行评估模型
python tools/eval.py -c configs/rec/xxx.yml -o Global.checkpoints="./output/rec/best_accuracy"评估会从Precision、Recall、Hmean(F-Score)多个角度进行评估。
执行模型导出
python tools/export_model.py -c ./output/rec/xxx.yml -o Global.pretrained_model="./output/rec/best_accuracy" Global.save_inference_dir="./output/rec_inference/"导出到./output/rec_inference/ 目录下就可以进行后续推理了。
2.4 微调成果
审核系统通过近5000条数据的微调后,新版本在实际数据验证中文字识别能力有了一定的提升。
原始图片:


微调前后识别能力:
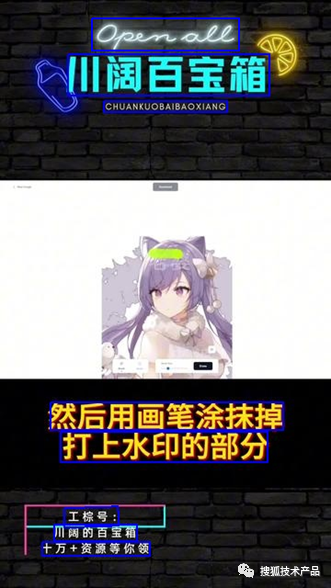

| 图片序号 | 微调前 | 微调后 |
|---|---|---|
| 1 | pem all 川阔的百宝箱工棕号 CHUANKUOBAIBAOXIANG 然后用画笔涂抹掉 打上水印的部分 工棕号: 阔的百宝箱 十万+资源等你领 | Open all 川阔的百宝箱工棕号 CHUANKUOBAIBAOXIANG 然后用画笔涂抹掉 打上水印的部分 工棕号: 川阔的百宝箱 十万+资源等你领 |
| 2 | 羽生结弦宣布结 chang2018.com 羽生结弦和他的妻子可能会 被媒体过度追踪 | 羽生结弦宣布结 OLYMPICCHANNEL chang2018.com 羽生结弦和他的妻子可能会 被媒体过度追踪 |
可以看到在文字识别微调后,对一些艺术字、特殊背景下的文字 识别能力也有一些增强。
03
项目成果与未来展望
1、项目成果
截止2023年9月累计OCR识别904606个视频,日均处理视频7K+, 相当于人工3个人每日审核量,日均检测出异常视频230+。
2、未来展望
当前审核系统对OCR的应用较为保守,后续业务稳定运行后还有以下几点需要跟进:
提高OCR速度 ,使用GPU代替当前CPU版本,保留CPU的调度逻辑,但是执行逻辑由GPU执行,利用GPU的多个Cuda核心加速OCR识别;
当前CPU调度能力局限于同一个实例内,当视频时长较长,(例如直播回放类视频),关键帧较多,导致一个实例的算力全都集中到了一个视频上,影响整体进度。后续考虑升级OCR调度能力,一来实现跨实例GRPC调度,充分利用集群算力,二来根据视频时长实现快慢队列,将较长的视频隔离开,避免影响整体OCR识别速度。