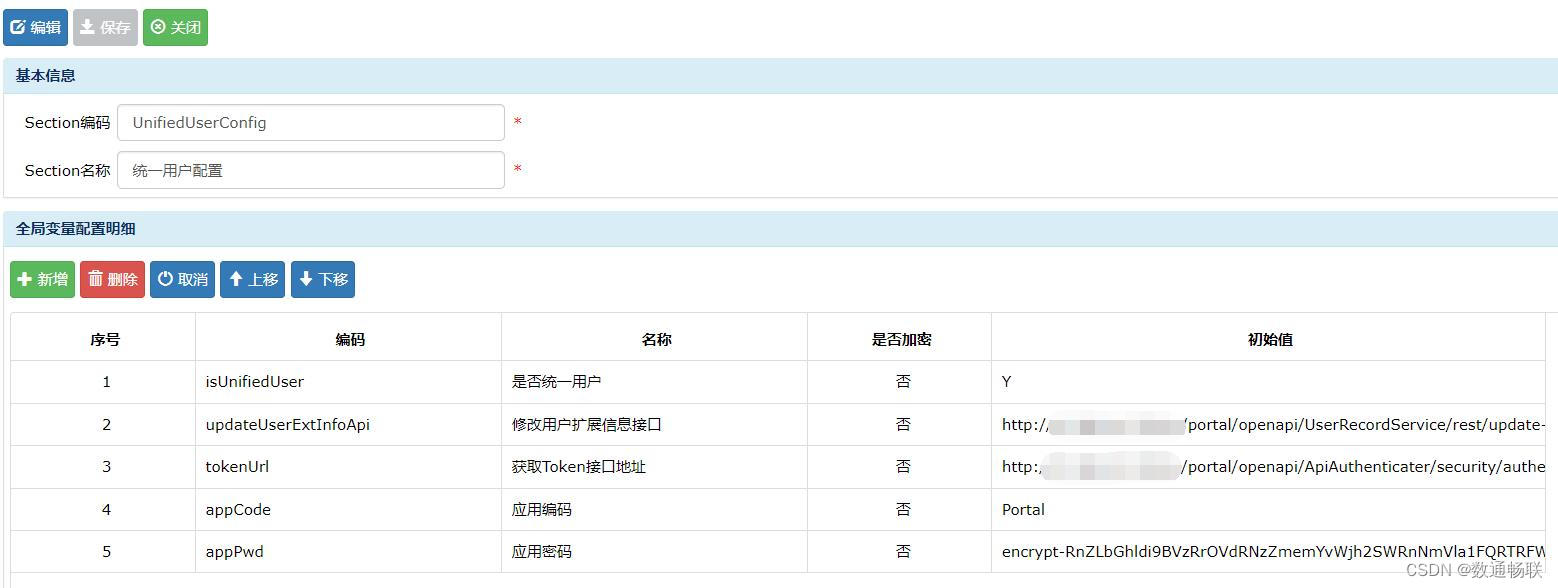
一、背景
由于公司规模较小,大数据相关没有实现平台化,相关的架构都是原生的Apache组件,所以集群的维护和优化都需要人工的参与。根据自己的实践整理一些数仓相关的优化。
二、优化
1、简易架构图

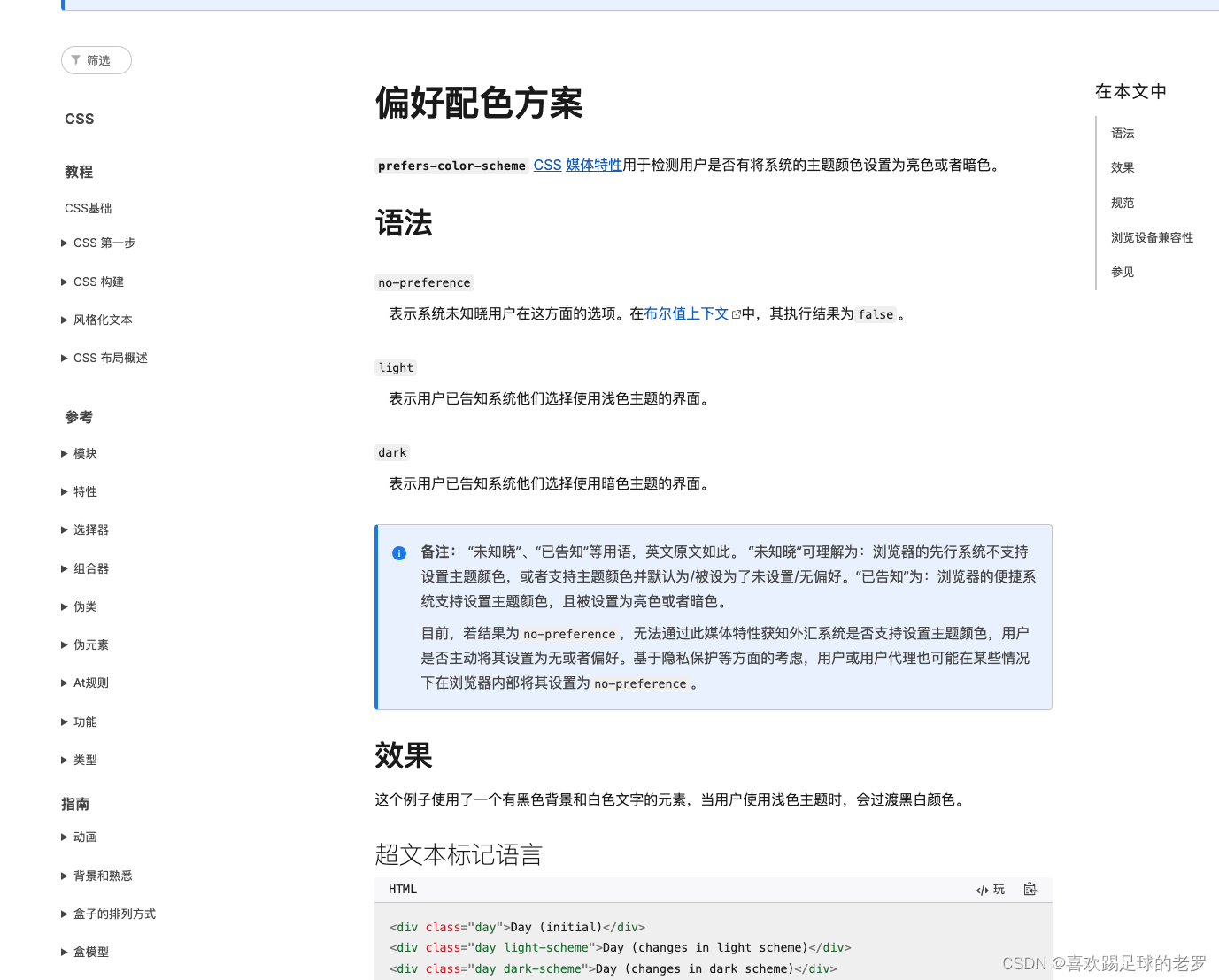
2、ODS层优化
2.1 分段式解析
随着业务增长,数据量也不断增加,凌晨任务经常基线预警、破线,导致数据不能正常产出,影响运营人员分析数据。在不增加成本的情况尽可能的优化。
经过团队研究,发现 t-1 的日志解析占用非常长的时间,且集群资源空闲时间点比较多。
把日志的解析分成两段式,当天0点到22点数据可在22:15进行解析,22点到24点数据在00:15解析,大大节省了时间,还充分利用了集群的资源。有效的缓解了破线问题。
2.2 小文件合并
1.原因:a.读取的数据源文件本身就有大量的小文件
b.动态分区插入数据,每个reduce产生的文件个数为动态分区的个数,产生文件个数=reduce个数*动态分区数
c.reduce/Task个数较多(和文件数是一样的)
2.影响:a.文件的数量决定了Mapreduce/Spark中Mapper/Task数量,小文件越多,Mapper/Task的任务越多,每个Mapper
/task都会对应启动一个JVM/线程来运行,每个Task数据小,个数大,占用资源多,甚至这些任务初始化的时间
可能比执行的时间还要多,影响性能,当然这个问题 可以通过CombinedInputFile和开启JVM重用来解决。
b.文件存储在HDFS上,每个文件的元数据信息(位置、大小、分块信息)大约占150个字节,文件的元数据信息分别存储在
内存和磁盘中。
3.解决方法:通过 DISTRIBUTE BY 控制文件的个数
distribute by 1
distribute by cast(rand()*10 as int)
distribute by dt
distribute by substr(udi,1,2)
2.3 提高数据压缩比率
1.问题描述 :使用 DISTRIBUTE BY INT(RAND()*300) 随机数的方式控制了文件的个数,但是使用的SNAPPY压缩,压缩比原则是十倍左右,目前只能达到两倍左右。
原因:每个文件里面的数据随机,数据的相似性较小,压缩比上不去
2.问题解决:DISTRIBUTE BY SUBSTR(udi,1,2) 使用文本字段进行文件数的控制,文件个数减少了,并且文件的大小也变小了,压缩比变大
说明:udi前两个为(字母+数字),截取前两个组合来作为文件的个数(最多36*36)
原理:将相似的数据放在同一个分区里,数据压缩比增大
2.4 分项目业务数据导入优化
1.问题描述:由于项目数量比较多,并且会持续增加,项目之间的业务表相同,按照sqoop传统导数据的脚本,会编写很多冗余的脚本,费时费力,且增加新项目时,开发成本较高
2.问题解决:将不同的数据库的配置信息(host、IP、账号、密码、脚本路径) 配置到mysql表中,编写相应的脚本,脚本根据给定的参数去读取相应的配置,进行对应项目的数据导入。
3、DWD层优化
3.1 缩减分区
1.问题描述:初始建立二级分区(项目+天),随着老项目的数据量增加,以及新项目上线数据量较少, 导致执行时造成数据倾斜,以及多级分区造成文件数以及分区数成倍增加,造成数据寻址时间过长。 执行时间较短,但是刷盘的时间过长,晚上流程的时间整体拖延。
2.问题解决:将二级分区改为一级分区
3.解决方法:a.建立同样的临时表
b.将历史数据mv导入到临时表中,此时进行核对数据量
c.通过命令修复临时表的分区
d.将旧表删除,建立新的分区表
e.将临时表的数据导入到新的表中,核对数据

![助力城市部件[标石/电杆/光交箱/人井]精细化管理,基于YOLOv7【tiny/yolov7】开发构建生活场景下城市部件检测识别系统](https://img-blog.csdnimg.cn/direct/a89970d90a20493da5b02eed131a370a.png)



![[OCR]Python 3 下的文字识别CnOCR](https://img-blog.csdnimg.cn/direct/65b58a3cdc23427fbe0d9dcdc33baf63.png)