模型系列:增益模型Uplift Modeling原理和案例
目录
- 1. 简介
- 1. 第一步
- 2. 指标
- 3. 元学习器
- 3.1 S-学习器
- 3.2 T-学习器
- 3.3 T-学习器相关模型
简介
Uplift是一种用于用户级别的治疗增量效应估计的预测建模技术。每家公司都希望增加自己的利润,而其中一个选择是激励客户购买/点击/消费或识别理想的客户。

1. 类似模型 Look-alike model
基本情况是使用类似建模。我们可以通过与具有相同特征的先前客户进行比较来了解客户的行为,例如年龄、教育(我们对他们了解的内容以及他们愿意透露的内容)。这种方法需要我们的消费者数据和完成的操作以及一些随机数据,例如在我们的商店中没有购买任何东西但在其他商店中购买了东西的客户的数据。使用这种方法和机器学习,我们试图在新数据中找到与我们类似的客户,他们将成为我们促销的主要目标。
2. 响应模型 Response model
响应建模评估可能在治疗后完成行动的客户。因此,我们收集了治疗(沟通)后的数据,并知道积极和消极的观察结果。有些人购买了我们的产品,其他人没有。使用这些数据和机器学习,我们试图获得客户在治疗后完成所需行动的概率。
3. Uplift建模 Uplift model
最后但并非最不重要的是增益模型。与响应模型相比,增益模型评估沟通(治疗)的净效应,并尝试仅选择在治疗后才完成行动的客户。这组模型估计了具有沟通(治疗)和没有治疗的客户之间行为差异。我们将详细介绍这些模型。
首先,我们将行动表示为 Y(1 - 行动,0 - 无行动),治疗表示为 W(1 - 治疗,0 - 无治疗)

我们可以将客户分为4个具有相同行为的群体:
🤷 将采取行动 - 这群人无论如何都会采取行动(Y=1, W=1和Y=1, W=0)
🙋 可说服的 - 这群人只有在治疗后才会采取行动(Y=1, W=1和Y=0, W=0)
🙅 不要打扰 - 这群人会在没有治疗的情况下执行某个行动,但在治疗后可能会结束(Y=1, W=0和Y=0, W=1)
🤦 永远不会回应 - 这群人不在乎治疗(Y=0, W=1和Y=0, W=0)
对于客户来说,因果效应是其在有治疗和无治疗情况下结果的差异:
$ \tau_i = Y^1_i - Y^0_i $
对于更有趣的目的,对于客户群体来说,因果效应是有治疗和无治疗情况下该群体预期结果的差异 - CATE(条件平均处理效应):
$ CATE = E[Y^1_i|X_i] - E[Y^0_i|X_i] $
然而,我们不能同时观察这两种情况,只能在不同的宇宙中。这就是为什么我们只能估计
C
A
T
E
^
\widehat{CATE}
CATE
像往常一样:
$ \widehat{CATE} (uplift) = E[Y_i|X_i = x, W_i = 1] - E[Y_i|X_i = x, W_i = 0] $,其中 $ Y^1_i = Y_i = Y^1_i if W_i = 1$ and Y i 0 Y^0_i Yi0 where $W_i = 0 $
注意! W i W_i Wi 应该在给定 X i X_i Xi 的条件下与 Y i 1 Y^1_i Yi1 和 Y i 0 Y^0_i Yi0 独立。
有两种类型的增益模型:
-
元学习器- 转换问题并使用经典的机器学习模型 -
直接增益模型- 直接预测增益的算法。
1. 初步步骤
返回目录
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from tqdm.notebook import tqdm
import seaborn as sns
from statsmodels.graphics.gofplots import qqplot
!pip install scikit-uplift -q
from sklift.metrics import uplift_at_k, uplift_auc_score, qini_auc_score, weighted_average_uplift
from sklift.viz import plot_uplift_preds
from sklift.models import SoloModel, TwoModels
import xgboost as xgb
[33mWARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv[0m
# 读取csv文件,并将其存储在train变量中
train = pd.read_csv('../input/megafon-uplift-competition/train (1).csv')
我们看到了许多隐藏的特征X_1-X_50,二元处理(以对象格式)和二元转换
# 查看训练数据的前几行
train.head()
| id | treatment_group | X_1 | X_2 | X_3 | X_4 | X_5 | X_6 | X_7 | X_8 | ... | X_42 | X_43 | X_44 | X_45 | X_46 | X_47 | X_48 | X_49 | X_50 | conversion | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | control | 39.396577 | -0.186548 | 19.524505 | 21.250208 | 55.291264 | 182.966712 | -5.385606 | 144.573379 | ... | 134.363458 | -213.584582 | -2.092461 | -93.973258 | -0.155597 | -312.130733 | 44.798182 | -125.682413 | 16.231365 | 0 |
| 1 | 1 | control | 38.987694 | 0.819522 | -42.064512 | -48.270949 | -33.171257 | 179.459341 | -87.151810 | -162.693257 | ... | 72.864779 | 559.783584 | 1.142391 | 80.037124 | -1.216185 | -111.473936 | -127.737977 | -117.501171 | 10.732234 | 0 |
| 2 | 2 | treatment | -16.693093 | 1.844558 | -8.615192 | -18.818740 | -22.271188 | -116.290369 | -63.816746 | -38.340763 | ... | 2.480242 | 96.998504 | 1.100962 | -33.275159 | 0.920926 | -679.492242 | -91.009397 | -18.173358 | 14.367636 | 0 |
| 3 | 3 | treatment | -72.040154 | -0.226921 | 39.802607 | 16.441262 | -1.112509 | 68.128008 | 23.073147 | 4.688858 | ... | 83.951551 | -323.642557 | -0.369182 | 93.221948 | -1.962380 | -442.466684 | -22.298302 | -75.916603 | 11.634299 | 0 |
| 4 | 4 | treatment | 18.296973 | 0.996437 | 24.465307 | -34.151971 | 24.623458 | -155.455558 | -12.159787 | 26.705778 | ... | -208.531112 | 118.902324 | -0.808578 | -117.497906 | 1.770635 | 627.395611 | 122.019189 | 194.091195 | -11.883858 | 0 |
5 rows × 53 columns
# 对训练数据集进行信息描述
train.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 600000 entries, 0 to 599999
Data columns (total 53 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 600000 non-null int64
1 treatment_group 600000 non-null object
2 X_1 600000 non-null float64
3 X_2 600000 non-null float64
4 X_3 600000 non-null float64
5 X_4 600000 non-null float64
6 X_5 600000 non-null float64
7 X_6 600000 non-null float64
8 X_7 600000 non-null float64
9 X_8 600000 non-null float64
10 X_9 600000 non-null float64
11 X_10 600000 non-null float64
12 X_11 600000 non-null float64
13 X_12 600000 non-null float64
14 X_13 600000 non-null float64
15 X_14 600000 non-null float64
16 X_15 600000 non-null float64
17 X_16 600000 non-null float64
18 X_17 600000 non-null float64
19 X_18 600000 non-null float64
20 X_19 600000 non-null float64
21 X_20 600000 non-null float64
22 X_21 600000 non-null float64
23 X_22 600000 non-null float64
24 X_23 600000 non-null float64
25 X_24 600000 non-null float64
26 X_25 600000 non-null float64
27 X_26 600000 non-null float64
28 X_27 600000 non-null float64
29 X_28 600000 non-null float64
30 X_29 600000 non-null float64
31 X_30 600000 non-null float64
32 X_31 600000 non-null float64
33 X_32 600000 non-null float64
34 X_33 600000 non-null float64
35 X_34 600000 non-null float64
36 X_35 600000 non-null float64
37 X_36 600000 non-null float64
38 X_37 600000 non-null float64
39 X_38 600000 non-null float64
40 X_39 600000 non-null float64
41 X_40 600000 non-null float64
42 X_41 600000 non-null float64
43 X_42 600000 non-null float64
44 X_43 600000 non-null float64
45 X_44 600000 non-null float64
46 X_45 600000 non-null float64
47 X_46 600000 non-null float64
48 X_47 600000 non-null float64
49 X_48 600000 non-null float64
50 X_49 600000 non-null float64
51 X_50 600000 non-null float64
52 conversion 600000 non-null int64
dtypes: float64(50), int64(2), object(1)
memory usage: 242.6+ MB
特征没有标准化或归一化
# 使用describe()函数对训练数据集进行描述性统计分析
train.describe()
| id | X_1 | X_2 | X_3 | X_4 | X_5 | X_6 | X_7 | X_8 | X_9 | ... | X_42 | X_43 | X_44 | X_45 | X_46 | X_47 | X_48 | X_49 | X_50 | conversion | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 600000.000000 | 600000.000000 | 600000.000000 | 600000.000000 | 600000.000000 | 600000.000000 | 600000.000000 | 600000.000000 | 600000.000000 | 600000.000000 | ... | 600000.000000 | 600000.000000 | 600000.000000 | 600000.000000 | 600000.000000 | 600000.000000 | 600000.000000 | 600000.000000 | 600000.000000 | 600000.000000 |
| mean | 299999.500000 | -3.758503 | 0.000405 | 0.356208 | -1.004378 | 3.376919 | -6.396371 | -2.253712 | -6.432606 | -0.061507 | ... | -6.632834 | 8.454493 | 0.001296 | 0.007967 | -0.000966 | -22.259600 | -5.759041 | 6.241130 | -1.176456 | 0.204190 |
| std | 173205.225094 | 54.881882 | 0.999419 | 31.804123 | 45.291429 | 53.397644 | 140.873734 | 59.810396 | 74.840857 | 44.912292 | ... | 137.025868 | 262.840194 | 1.000368 | 71.553713 | 0.999902 | 500.900364 | 130.952113 | 141.211999 | 21.363662 | 0.403109 |
| min | 0.000000 | -271.659497 | -4.372119 | -148.870768 | -244.446728 | -302.574049 | -683.126343 | -322.731683 | -506.202937 | -218.466369 | ... | -633.575178 | -1345.838757 | -4.756720 | -360.713742 | -4.516004 | -2506.960013 | -687.526201 | -702.184241 | -98.094323 | 0.000000 |
| 25% | 149999.750000 | -40.693313 | -0.673108 | -20.758308 | -30.644608 | -31.865404 | -100.762161 | -42.313674 | -54.840796 | -30.327330 | ... | -99.033996 | -167.634846 | -0.673780 | -48.250836 | -0.675549 | -357.547278 | -93.163915 | -88.803657 | -15.580688 | 0.000000 |
| 50% | 299999.500000 | -3.954771 | 0.000915 | 0.372583 | -0.585368 | 3.720738 | -6.357443 | -2.263690 | -6.416419 | -0.103742 | ... | -6.784760 | 8.773280 | 0.001639 | 0.045537 | -0.002251 | -20.695017 | -5.774627 | 6.286783 | -1.199895 | 0.000000 |
| 75% | 449999.250000 | 33.174835 | 0.673056 | 21.495530 | 29.027860 | 38.988940 | 88.159514 | 37.709780 | 41.962767 | 30.144501 | ... | 85.621324 | 185.382370 | 0.675779 | 48.221733 | 0.673638 | 313.295748 | 81.636824 | 101.558007 | 13.230410 | 0.000000 |
| max | 599999.000000 | 250.812280 | 5.062006 | 170.053291 | 235.095937 | 284.915947 | 656.482242 | 293.909622 | 550.525780 | 219.628423 | ... | 689.626208 | 1488.759454 | 4.727996 | 384.665348 | 5.086304 | 2534.503855 | 595.321844 | 630.727101 | 112.233293 | 1.000000 |
8 rows × 52 columns
然而,很有可能这些特征已经被清除。每个特征分布看起来都很正常。
# 给代码添加中文注释
# 设置行数和列数
rows, cols = 10, 5
# 创建一个包含多个子图的图形对象,并设置图形的大小
f, axs = plt.subplots(nrows=rows, ncols=cols, figsize=(20, 25))
# 设置图形的背景颜色为白色
f.set_facecolor("#fff")
# 设置特征数量为1
n_feat = 1
# 遍历每一行
for row in tqdm(range(rows)):
# 遍历每一列
for col in range(cols):
try:
# 绘制核密度估计图,并设置填充、透明度、线宽、边缘颜色等参数
sns.kdeplot(x=f'X_{n_feat}', fill=True, alpha=1, linewidth=3,
edgecolor="#264653", data=train, ax=axs[row, col], color='w')
# 设置子图的背景颜色为深绿色,并设置透明度
axs[row, col].patch.set_facecolor("#619b8a")
axs[row, col].patch.set_alpha(0.8)
# 设置子图的网格颜色和透明度
axs[row, col].grid(color="#264653", alpha=1, axis="both")
except IndexError: # 隐藏最后一个空图
axs[row, col].set_visible(False)
# 特征数量加1
n_feat += 1
# 显示图形
f.show()
0%| | 0/10 [00:00<?, ?it/s]

只是为了确保,请看qq图。
# 设置子图的行数和列数
rows, cols = 10, 5
# 创建一个包含子图的图像对象
f, axs = plt.subplots(nrows=rows, ncols=cols, figsize=(20, 25))
# 设置图像的背景颜色为白色
f.set_facecolor("#fff")
# 设置特征数量为1
n_feat = 1
# 遍历每一行
for row in tqdm(range(rows)):
# 遍历每一列
for col in range(cols):
try:
# 绘制核密度估计图
# sns.kdeplot(x=f'X_{n_feat}', fill=True, alpha=1, linewidth=3,
# edgecolor="#264653", data=train, ax=axs[row, col], color='w')
# 绘制QQ图
qqplot(train[f'X_{n_feat}'], ax=axs[row, col], line='q')
# 设置网格线的颜色为深绿色
axs[row, col].grid(color="#264653", alpha=1, axis="both")
# 如果索引超出范围,则隐藏最后一个空图
except IndexError:
axs[row, col].set_visible(False)
# 特征数量加1
n_feat += 1
# 显示图像
f.show()
0%| | 0/10 [00:00<?, ?it/s]

接下来让我们集中精力进行建模。
2. 指标
由于我们在研究之前没有Uplift,我们不能使用经典的Meta-Learners指标。然而,我们需要比较模型并了解它们的准确性。
1. Uplift@k
我们所需要做的就是对值进行排序(降序),并计算治疗组和对照组中目标变量(Y)的平均差异:
U
p
l
i
f
t
@
k
=
m
e
a
n
(
Y
t
r
e
a
t
m
e
n
t
@
k
)
−
m
e
a
n
(
Y
c
o
n
t
r
o
l
@
k
)
Uplift@k = mean(Y^{treatment}@k) - mean(Y^{control}@k)
Uplift@k=mean(Ytreatment@k)−mean(Ycontrol@k)
Y
@
k
Y@k
Y@k - 前k%的目标变量
2. 按百分位数(十分位数)计算Uplift
相同的方法,但这里我们分别计算每个十分位数的差异
使用按百分位数计算的Uplift,我们可以计算加权平均Uplift:
加权平均Uplift$ = \frac{N^T_i * uplift_i}{\sum{N^T_i}} $
N
i
T
N^T_i
NiT - i百分位数中治疗组的大小
3. Uplift曲线和AUUC
Uplift曲线是一个依赖于对象数量的累积Uplift函数:
uplift curve
i
=
(
Y
t
T
N
t
T
−
Y
t
C
N
t
C
)
(
N
t
T
+
N
t
C
)
\text{uplift curve}_i = (\frac{Y^T_t}{N^T_t}-\frac{Y^C_t}{N^C_t}) (N^T_t + N^C_t)
uplift curvei=(NtTYtT−NtCYtC)(NtT+NtC)
其中
t
−
累积对象数量
,
N
−
T和C组的大小
\text{其中 } t - \text{累积对象数量}, N - \text{T和C组的大小}
其中 t−累积对象数量,N−T和C组的大小
AUUC - Unplift曲线下的面积是随机Uplift曲线和模型曲线之间的面积,通过理想Uplift曲线下的面积进行归一化
4. Qini曲线和AUQC
Qini曲线是另一种累积函数的方法:
qini curve
i
=
Y
t
T
−
Y
t
C
N
t
T
N
t
C
\text{qini curve}_i = Y^T_t-\frac{Y^C_tN^T_t}{N^C_t}
qini curvei=YtT−NtCYtCNtT
AUQC或Qini系数 - Qini曲线下的面积是随机Qini曲线和模型曲线之间的面积,通过理想Qini曲线下的面积进行归一化
train.columns
Index(['id', 'treatment_group', 'X_1', 'X_2', 'X_3', 'X_4', 'X_5', 'X_6',
'X_7', 'X_8', 'X_9', 'X_10', 'X_11', 'X_12', 'X_13', 'X_14', 'X_15',
'X_16', 'X_17', 'X_18', 'X_19', 'X_20', 'X_21', 'X_22', 'X_23', 'X_24',
'X_25', 'X_26', 'X_27', 'X_28', 'X_29', 'X_30', 'X_31', 'X_32', 'X_33',
'X_34', 'X_35', 'X_36', 'X_37', 'X_38', 'X_39', 'X_40', 'X_41', 'X_42',
'X_43', 'X_44', 'X_45', 'X_46', 'X_47', 'X_48', 'X_49', 'X_50',
'conversion'],
dtype='object')
# 获取'treatment_group'列的唯一值
train['treatment_group'].unique()
array(['control', 'treatment'], dtype=object)
# 将'treatment_group'列中的值转换为0或1,如果值为'treatment'则转换为1,否则转换为0
train['treatment_group'] = train['treatment_group'].apply(lambda x: 1 if x=='treatment' else 0)
# 从sklearn库中导入train_test_split函数
from sklearn.model_selection import train_test_split
# 将train数据集的前100000行赋值给train变量
train = train[:100000]
# 从train数据集中选取名为'X_i'的特征列,其中i的取值范围为1到50,并将结果赋值给X变量
X = train[[f'X_{i}' for i in range(1, 51)]]
# 从train数据集中选取名为'treatment_group'的特征列,并将结果赋值给treatment变量
treatment = train['treatment_group']
# 从train数据集中选取名为'conversion'的特征列,并将结果赋值给y变量
y = train['conversion']
# 使用train_test_split函数将X、y和treatment按照指定的比例划分为训练集和验证集,并将划分结果分别赋值给X_train、X_val、y_train、y_val、treatment_train和treatment_val变量
X_train, X_val, y_train, y_val, treatment_train, treatment_val = train_test_split(X, y, treatment, test_size=0.2)
3. 元学习者
3.1 S-Learner
3.1 S-学习者
返回目录
S-learner的主要思想是使用特征、二进制处理(W)和二进制目标动作(Y)训练一个模型。然后使用常数W=1和W=0对测试数据进行预测。差异即为提升效果。
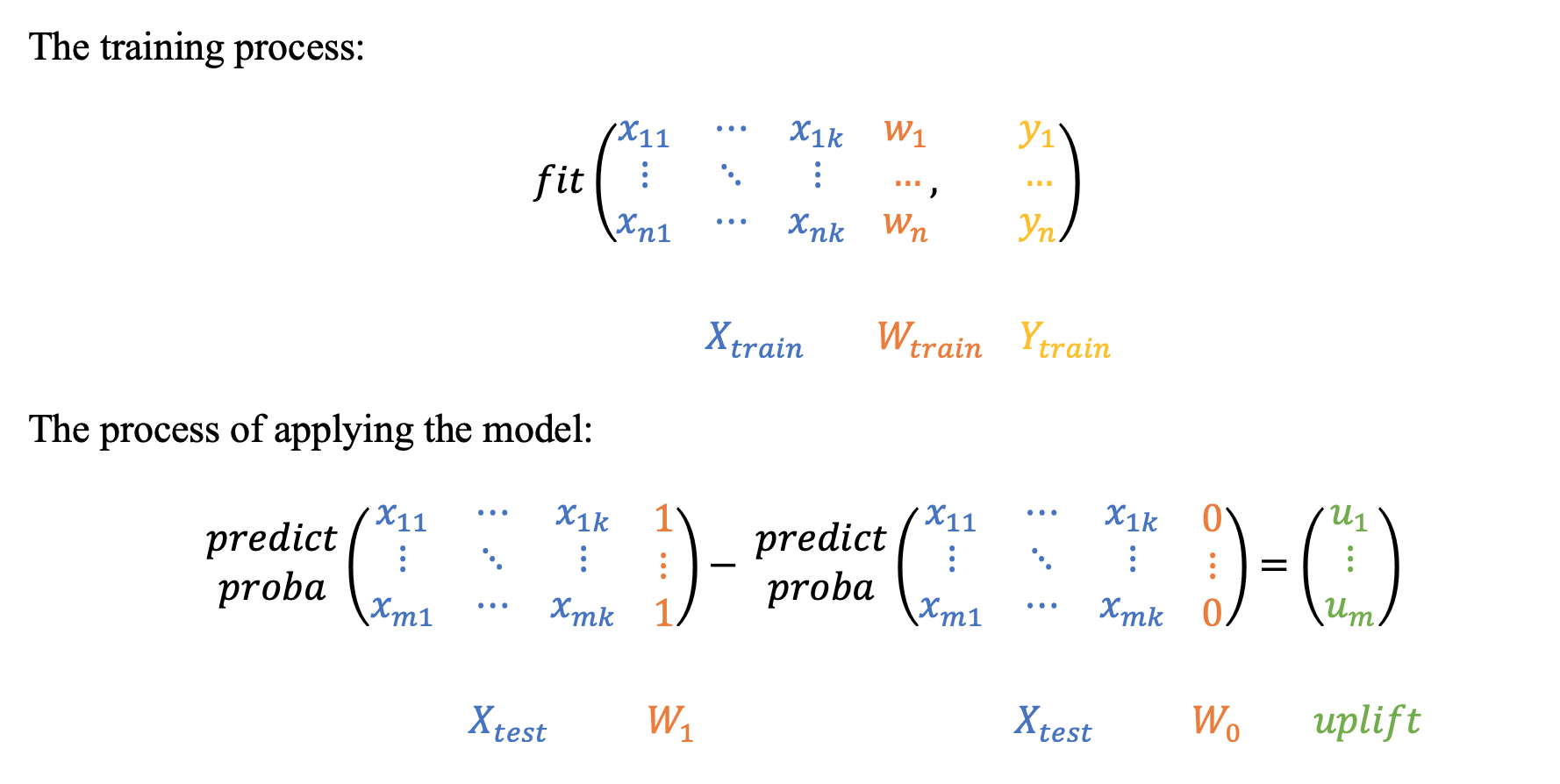
好消息是我们可以使用经典的机器学习分类器!让我们使用xgboost来做吧。你也可以尝试其他分类器并比较结果。
# 定义一个函数get_metrics,接受三个参数y_val, uplift, treatment_val
def get_metrics(y_val, uplift, treatment_val):
# 计算指标
# 计算前30%的提升值。按照组别排序控制组和处理组。整体排序。
upliftk = uplift_at_k(y_true=y_val, uplift=uplift, treatment=treatment_val, strategy='by_group', k=0.3)
upliftk_all = uplift_at_k(y_true=y_val, uplift=uplift, treatment=treatment_val, strategy='overall', k=0.3)
# 计算Qini系数
qini_coef = qini_auc_score(y_true=y_val, uplift=uplift, treatment=treatment_val)
# 默认策略 - 整体排序
# 计算提升曲线下面积
uplift_auc = uplift_auc_score(y_true=y_val, uplift=uplift, treatment=treatment_val)
# 计算加权平均提升值
wau = weighted_average_uplift(y_true=y_val, uplift=uplift, treatment=treatment_val, strategy='by_group')
wau_all = weighted_average_uplift(y_true=y_val, uplift=uplift, treatment=treatment_val)
# 打印结果
print(f'uplift at top 30% by group: {upliftk:.2f} by overall: {upliftk_all:.2f}\n',
f'Weighted average uplift by group: {wau:.2f} by overall: {wau_all:.2f}\n',
f'AUUC by group: {uplift_auc:.2f}\n',
f'AUQC by group: {qini_coef:.2f}\n')
# 返回一个包含指标结果的字典
return {'uplift@30': upliftk, 'uplift@30_all': upliftk_all, 'AUQC': qini_coef, 'AUUC': uplift_auc,
'WAU': wau, 'WAU_all': wau_all}
# 创建一个XGBoost分类器模型,设置随机种子为42,目标函数为二元逻辑回归,禁用标签编码
xgb_sm = xgb.XGBClassifier(random_state=42, objective='binary:logistic', use_label_encoder=False)
# 创建一个SoloModel对象,使用上面创建的XGBoost分类器模型作为估计器
sm = SoloModel(estimator=xgb_sm)
# 使用训练数据集X_train、y_train和treatment_train来拟合SoloModel模型
sm = sm.fit(X_train, y_train, treatment_train, estimator_fit_params={})
# 使用拟合好的SoloModel模型对验证数据集X_val进行预测
uplift_sm = sm.predict(X_val)
# 使用get_metrics函数计算验证数据集的评估指标,包括y_val、uplift_sm和treatment_val
res = get_metrics(y_val, uplift_sm, treatment_val)
[12:14:57] WARNING: ../src/learner.cc:1115: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
uplift at top 30% by group: 0.18 by overall: 0.18
Weighted average uplift by group: 0.04 by overall: 0.04
AUUC by group: 0.15
AUQC by group: 0.21
3.2 T-Learner
3.2 T学习器
跳转到目录
T-learner的主要思想是训练两个独立的模型:一个基于治疗后的观察数据(T),另一个基于对照组数据(C)。提升效果是模型T和模型C在数据上的预测差异。
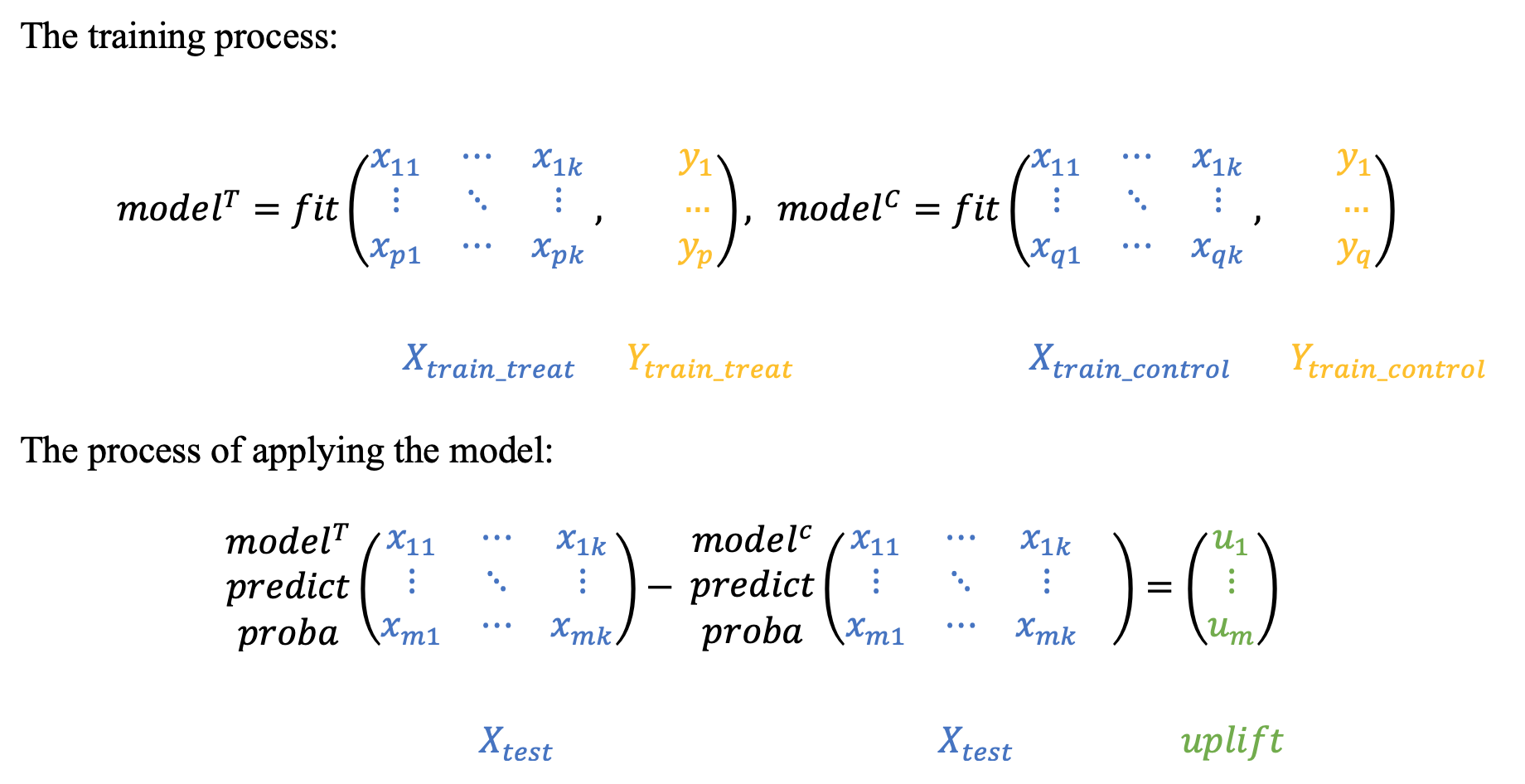
# 初始化两个xgboost分类器,分别用于处理treatment组和control组
xgb_T = xgb.XGBClassifier(random_state=42, objective='binary:logistic', use_label_encoder=False)
xgb_C = xgb.XGBClassifier(random_state=42, objective='binary:logistic', use_label_encoder=False)
# 初始化TwoModels类,将treatment组和control组的分类器传入
sm = TwoModels(estimator_trmnt=xgb_T, estimator_ctrl=xgb_C)
# 使用训练数据拟合模型
sm = sm.fit(X_train, y_train, treatment_train, estimator_trmnt_fit_params={}, estimator_ctrl_fit_params={})
# 对验证集进行预测
uplift_sm = sm.predict(X_val)
# 计算模型的评估指标
res = get_metrics(y_val, uplift_sm, treatment_val)
[12:15:47] WARNING: ../src/learner.cc:1115: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
[12:16:11] WARNING: ../src/learner.cc:1115: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
uplift at top 30% by group: 0.17 by overall: 0.17
Weighted average uplift by group: 0.04 by overall: 0.04
AUUC by group: 0.13
AUQC by group: 0.18
结果比S-learner稍差。
3.3 T-Learner依赖模型
T-learner与依赖模型的主要思想是使用相反模型的预测(概率)来训练T或C模型。
这种方法是从分类器链方法中采用的:https://scikit-learn.org/stable/auto_examples/multioutput/plot_classifier_chain_yeast.html
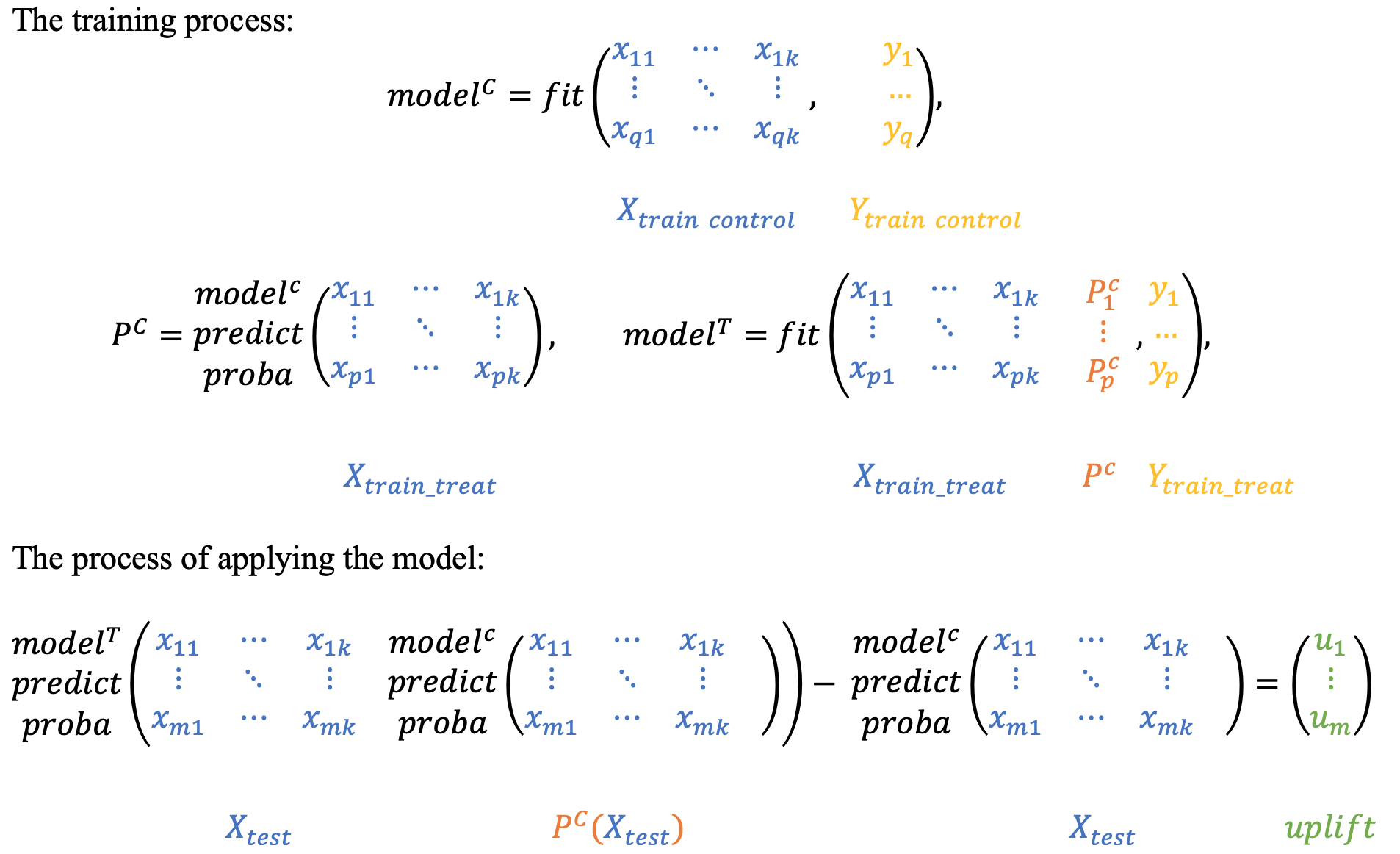
这种方法有两种可能的实现方式:基于C模型中的T-probs和基于T模型中的C-probs:
- u p l i f t i = P T ( x i , P C ( X ) ) − P C ( x i ) uplift_i = P^T(x_i, P^C(X)) - P^C(x_i) uplifti=PT(xi,PC(X))−PC(xi)
- u p l i f t i = P T ( x i ) − P C ( x i , P T ( x i ) ) uplift_i = P^T(x_i) - P^C(x_i, P^T(x_i)) uplifti=PT(xi)−PC(xi,PT(xi))
第一种方法:
# 创建两个XGBClassifier对象,分别作为treatment模型和control模型
xgb_T = xgb.XGBClassifier(random_state=42, objective='binary:logistic', use_label_encoder=False)
xgb_C = xgb.XGBClassifier(random_state=42, objective='binary:logistic', use_label_encoder=False)
# 创建TwoModels对象,将treatment模型和control模型传入,并指定方法为'ddr_control'
sm = TwoModels(estimator_trmnt=xgb_T, estimator_ctrl=xgb_C, method='ddr_control')
# 使用训练数据拟合TwoModels对象
sm = sm.fit(X_train, y_train, treatment_train, estimator_trmnt_fit_params={}, estimator_ctrl_fit_params={})
# 使用拟合好的TwoModels对象对验证数据进行预测
uplift_sm = sm.predict(X_val)
# 使用预测结果和验证数据计算评估指标
res = get_metrics(y_val, uplift_sm, treatment_val)
[12:16:37] WARNING: ../src/learner.cc:1115: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
[12:17:02] WARNING: ../src/learner.cc:1115: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
uplift at top 30% by group: 0.17 by overall: 0.17
Weighted average uplift by group: 0.04 by overall: 0.04
AUUC by group: 0.12
AUQC by group: 0.18
第二种方法:
# 创建两个XGBoost分类器,用于处理treatment组和control组
xgb_T = xgb.XGBClassifier(random_state=42, objective='binary:logistic', use_label_encoder=False)
xgb_C = xgb.XGBClassifier(random_state=42, objective='binary:logistic', use_label_encoder=False)
# 创建TwoModels对象,使用xgb_T和xgb_C作为估计器,并选择ddr_treatment方法
sm = TwoModels(estimator_trmnt=xgb_T, estimator_ctrl=xgb_C, method='ddr_treatment')
# 使用训练数据拟合TwoModels对象
sm = sm.fit(X_train, y_train, treatment_train, estimator_trmnt_fit_params={}, estimator_ctrl_fit_params={})
# 对验证数据进行预测
uplift_sm = sm.predict(X_val)
# 计算模型的评估指标
res = get_metrics(y_val, uplift_sm, treatment_val)
[12:17:27] WARNING: ../src/learner.cc:1115: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
[12:17:51] WARNING: ../src/learner.cc:1115: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
uplift at top 30% by group: 0.17 by overall: 0.17
Weighted average uplift by group: 0.04 by overall: 0.04
AUUC by group: 0.13
AUQC by group: 0.19
参考资料:
https://www.uplift-modeling.com/en/latest/