大数据NoSQL数据库HBase集群部署
简介
HBase 是一种分布式、可扩展、支持海量数据存储的 NoSQL 数据库。
和Redis一样,HBase是一款KeyValue型存储的数据库。
不过和Redis设计方向不同
- Redis设计为少量数据,超快检索
- HBase设计为海量数据,快速检索
HBase在大数据领域应用十分广泛,现在我们来在node1、node2、node3上部署HBase集群。
安装
-
HBase依赖Zookeeper、JDK、Hadoop(HDFS),请确保已经完成前面
- 集群化软件前置准备(JDK)
- Zookeeper
- Hadoop
- 这些环节的软件安装
-
【node1执行】下载HBase安装包
# 下载 wget http://archive.apache.org/dist/hbase/2.1.0/hbase-2.1.0-bin.tar.gz # 解压 tar -zxvf hbase-2.1.0-bin.tar.gz -C /export/server # 配置软链接 ln -s /export/server/hbase-2.1.0 /export/server/hbase -
【node1执行】,修改配置文件,修改
conf/hbase-env.sh文件# 在28行配置JAVA_HOME export JAVA_HOME=/export/server/jdk # 在126行配置: # 意思表示,不使用HBase自带的Zookeeper,而是用独立Zookeeper export HBASE_MANAGES_ZK=false # 在任意行,比如26行,添加如下内容: export HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP="true" -
【node1执行】,修改配置文件,修改
conf/hbase-site.xml文件# 将文件的全部内容替换成如下内容: <configuration> <!-- HBase数据在HDFS中的存放的路径 --> <property> <name>hbase.rootdir</name> <value>hdfs://node1:8020/hbase</value> </property> <!-- Hbase的运行模式。false是单机模式,true是分布式模式。若为false,Hbase和Zookeeper会运行在同一个JVM里面 --> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <!-- ZooKeeper的地址 --> <property> <name>hbase.zookeeper.quorum</name> <value>node1,node2,node3</value> </property> <!-- ZooKeeper快照的存储位置 --> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/export/server/apache-zookeeper-3.6.0-bin/data</value> </property> <!-- V2.1版本,在分布式情况下, 设置为false --> <property> <name>hbase.unsafe.stream.capability.enforce</name> <value>false</value> </property> </configuration> -
【node1执行】,修改配置文件,修改
conf/regionservers文件# 填入如下内容 node1 node2 node3 -
【node1执行】,分发hbase到其它机器
scp -r /export/server/hbase-2.1.0 node2:/export/server/ scp -r /export/server/hbase-2.1.0 node3:/export/server/ -
【node2、node3执行】,配置软链接
ln -s /export/server/hbase-2.1.0 /export/server/hbase -
【node1、node2、node3执行】,配置环境变量
# 配置在/etc/profile内,追加如下两行 export HBASE_HOME=/export/server/hbase export PATH=$HBASE_HOME/bin:$PATH source /etc/profile -
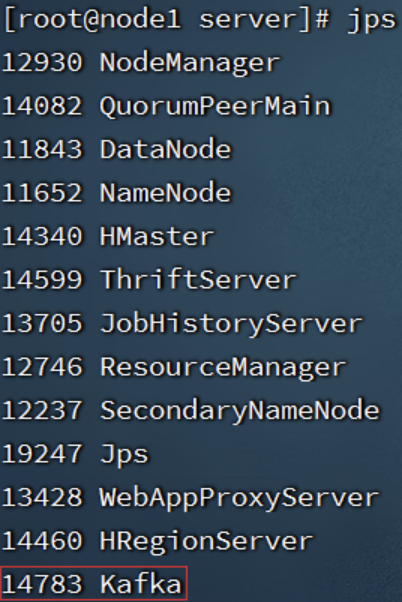
【node1执行】启动HBase
请确保:Hadoop HDFS、Zookeeper是已经启动了的
start-hbase.sh # 如需停止可使用 stop-hbase.sh由于我们配置了环境变量export PATH= P A T H : PATH: PATH:HBASE_HOME/bin
start-hbase.sh即在$HBASE_HOME/bin内,所以可以无论当前目录在哪,均可直接执行
-
验证HBase
浏览器打开:http://node1:16010,即可看到HBase的WEB UI页面
-
简单测试使用HBase
【node1执行】
hbase shell # 创建表 create 'test', 'cf' # 插入数据 put 'test', 'rk001', 'cf:info', 'itheima' # 查询数据 get 'test', 'rk001' # 扫描表数据 scan 'test'
分布式内存计算Spark环境部署
注意
本小节的操作,基于:大数据集群(Hadoop生态)安装部署环节中所构建的Hadoop集群
如果没有Hadoop集群,请参阅前置内容,部署好环境。
简介
Spark是一款分布式内存计算引擎,可以支撑海量数据的分布式计算。
Spark在大数据体系是明星产品,作为最新一代的综合计算引擎,支持离线计算和实时计算。
在大数据领域广泛应用,是目前世界上使用最多的大数据分布式计算引擎。
我们将基于前面构建的Hadoop集群,部署Spark Standalone集群。
安装
-
【node1执行】下载并解压
wget https://archive.apache.org/dist/spark/spark-2.4.5/spark-2.4.5-bin-hadoop2.7.tgz # 解压 tar -zxvf spark-2.4.5-bin-hadoop2.7.tgz -C /export/server/ # 软链接 ln -s /export/server/spark-2.4.5-bin-hadoop2.7 /export/server/spark -
【node1执行】修改配置文件名称
# 改名 cd /export/server/spark/conf mv spark-env.sh.template spark-env.sh mv slaves.template slaves -
【node1执行】修改配置文件,
spark-env.sh## 设置JAVA安装目录 JAVA_HOME=/export/server/jdk ## HADOOP软件配置文件目录,读取HDFS上文件和运行YARN集群 HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop YARN_CONF_DIR=/export/server/hadoop/etc/hadoop ## 指定spark老大Master的IP和提交任务的通信端口 export SPARK_MASTER_HOST=node1 export SPARK_MASTER_PORT=7077 SPARK_MASTER_WEBUI_PORT=8080 SPARK_WORKER_CORES=1 SPARK_WORKER_MEMORY=1g -
【node1执行】修改配置文件,
slavesnode1 node2 node3 -
【node1执行】分发
scp -r spark-2.4.5-bin-hadoop2.7 node2:$PWD scp -r spark-2.4.5-bin-hadoop2.7 node3:$PWD -
【node2、node3执行】设置软链接
ln -s /export/server/spark-2.4.5-bin-hadoop2.7 /export/server/spark -
【node1执行】启动Spark集群
/export/server/spark/sbin/start-all.sh # 如需停止,可以 /export/server/spark/sbin/stop-all.sh -
打开Spark监控页面,浏览器打开:http://node1:8081
-
【node1执行】提交测试任务
/export/server/spark/bin/spark-submit --master spark://node1:7077 --class org.apache.spark.examples.SparkPi /export/server/spark/examples/jars/spark-examples_2.11-2.4.5.jar
分布式内存计算Flink环境部署
注意
本小节的操作,基于:大数据集群(Hadoop生态)安装部署环节中所构建的Hadoop集群
如果没有Hadoop集群,请参阅前置内容,部署好环境。
简介
Flink同Spark一样,是一款分布式内存计算引擎,可以支撑海量数据的分布式计算。
Flink在大数据体系同样是明星产品,作为最新一代的综合计算引擎,支持离线计算和实时计算。
在大数据领域广泛应用,是目前世界上除去Spark以外,应用最为广泛的分布式计算引擎。
我们将基于前面构建的Hadoop集群,部署Flink Standalone集群
Spark更加偏向于离线计算而Flink更加偏向于实时计算。
安装
-
【node1操作】下载安装包
wget https://archive.apache.org/dist/flink/flink-1.10.0/flink-1.10.0-bin-scala_2.11.tgz # 解压 tar -zxvf flink-1.10.0-bin-scala_2.11.tgz -C /export/server/ # 软链接 ln -s /export/server/flink-1.10.0 /export/server/flink -
【node1操作】修改配置文件,
conf/flink-conf.yaml# jobManager 的IP地址 jobmanager.rpc.address: node1 # JobManager 的端口号 jobmanager.rpc.port: 6123 # JobManager JVM heap 内存大小 jobmanager.heap.size: 1024m # TaskManager JVM heap 内存大小 taskmanager.heap.size: 1024m # 每个 TaskManager 提供的任务 slots 数量大小 taskmanager.numberOfTaskSlots: 2 #是否进行预分配内存,默认不进行预分配,这样在我们不使用flink集群时候不会占用集群资源 taskmanager.memory.preallocate: false # 程序默认并行计算的个数 parallelism.default: 1 #JobManager的Web界面的端口(默认:8081) jobmanager.web.port: 8081 -
【node1操作】,修改配置文件,
conf/slavesnode1 node2 node3 -
【node1操作】分发Flink安装包到其它机器
cd /export/server scp -r flink-1.10.0 node2:`pwd`/ scp -r flink-1.10.0 node3:`pwd`/ -
【node2、node3操作】
# 配置软链接 ln -s /export/server/flink-1.10.0 /export/server/flink -
【node1操作】,启动Flink
/export/server/flink/bin/start-cluster.sh -
验证Flink启动
# 浏览器打开 http://node1:8081 -
提交测试任务
【node1执行】
/export/server/flink/bin/flink run /export/server/flink-1.10.0/examples/batch/WordCount.jar