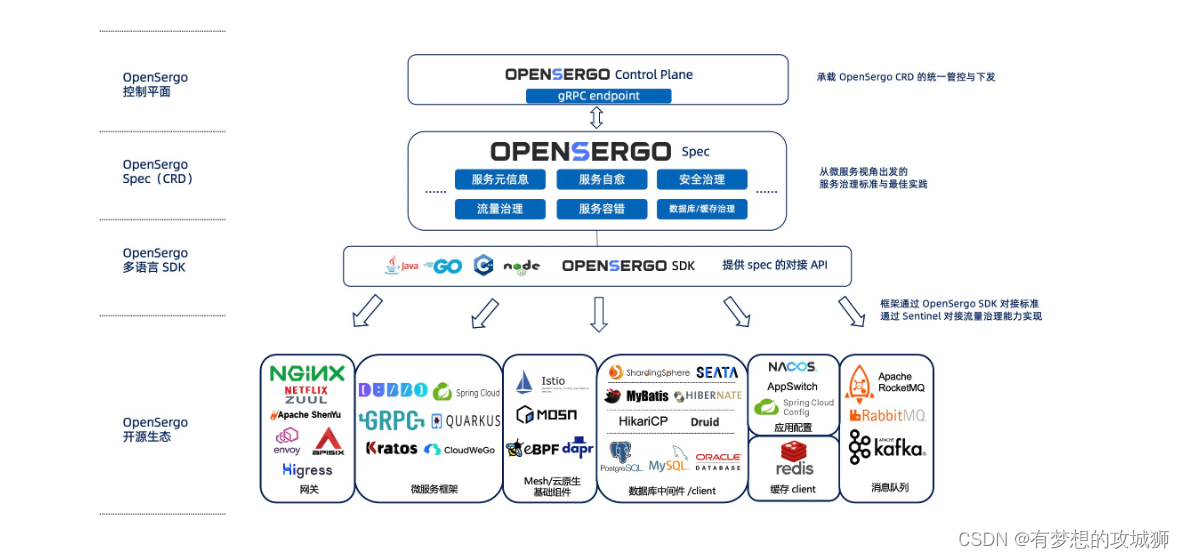
当前提到大语言模型,大家想到的都是动辄百亿规模以上参数量的模型,13B、70B都是稀疏平常入门级的,但是目前从模型层面来看,模型参数量的规模两极分化已经来临,早期各大公司为了效果怼上去,采取了简单粗暴的方法,那就是训练数据越多越好,模型越大越好,事实也确实证明这么发展的路子是对的,撇开医疗、法律等行业应用,但就模型层面多模态的趋势已经非常明显,这属于巨头企业、政府的菜,绝大部分公司还是围绕开源的10B左右做行业应用。模型规模层面接下来的另一个趋势是“小”,往“小”参数了的方向发展。
这一方向的践行者是微软和谷歌,从Phi-1开始,到这个月在Huggingface上发布的Phi-2,都显示着微软在这一方面的信心,从目前的结果来看,国内会有一批公司跟风,尤其是硬件公司也会跟风,就好比15年左右智能音箱刚出来的时候一样,一批硬件公司会涌入这里,包括手机、手表、pc等移动设备。
小语言模型赛道已经开启
Google于12月初发布了Gemini模型,相比我8月份的博客《大语言模型之五 谷歌Gemini》,谷歌不仅仅是给了对标OPenAI的大模型,还给了Gemini Nano小模型,该模型参数量分为1.8B(Nano-1)和3.25B(Nano-2),分别针对低内存和高内存移动设备,采用4bit量化部署。相比而言,微软早在6月份就发布了13亿参数Phi-1的模型,该模型以 Transformer 架构为基础,微软团队使用了包括来自网络的“教科书等级”数据和以 GPT-3.5 经过处理的“逻辑严密的内容”, 8 个英伟达 A100 GPU,在短短 4 天内完成训练。在测试中,phi-1 实现了最先进的Python编码性能。这更加坚定了微软的小模型路线,重点扩展常识推理和语言理解的Phi-1.5也应运而生,Google之后,12月微软再度发布27亿参数具有“杰出”推理和语言理解能力的Phi-2 。

Phi-1.5开源地址:https://huggingface.co/microsoft/phi-1_5
Phi-1开源地址:https://huggingface.co/microsoft/phi-1
Phi-1.5论文地址:https://arxiv.org/abs/2309.05463
Phi-2开源地址:https://huggingface.co/microsoft/phi-2
那么,为什么像微软和谷歌有了大模型,还希望为客户提供更小但计算效率更高的语言模型呢?原因有很多,但也许最重要的是时间和资金成本。成本是训练和运行LLM时最重要的痛点之一。例如,定制OpenAI的GPT-4模型定价从2300万美元开始,训练可能需要几个月的时间,并且需要数十亿的训练token。虽然还没有证实训练GPT-4的费用是多少,但它的前身GPT-3的费用可能超过400万美元,此外ChatGPT每天的运行费用可能高达70万美元。
传言GPT-4已在25,000个Nvidia A100 GPU上进行了90-100天的训练,但Phi-2仅用了14天就在96个A100 GPU上完成了训练。
尽管Phi-2没有达到GPT-4的性能水平,但它已经成功地在多个基准测试中超越了更大的模型。在BBH、常识推理、语言理解(仅Llama)、数学和编码等领域优于Mistral-7B和Llama-2等模型。它还在多个基准测试上优于Gemini Nano 2,包括BBH、BoolQ、MBPP和MMLU。
感谢微软、感谢Google开辟新战场。又能给国内创造就业了,国内大批公司将会在这个方向投入了。
微软如何训练的
在Phi-2的例子中,微软认为SLM成功的关键驱动因素之一是其训练数据的质量。输入模型的数据质量越好,其整体性能就越好。
在Phi-2中,微软使用了1.4T超高质量“教科书质量”训练数据,该数据集结合了合成数据集来训练模型常识推理和一般知识(科学、日常活动、心理理论),然后根据教育价值和内容质量进行过滤的网络上数据扩充之前的数据。
Phi-2和Phi-1.5一样采用了24层的Transformer架构,每个头的维度为64,并使用了旋转嵌入等技术来提升模型性能。
Phi-2没有通过强化学习或微调进行对齐,因此有可能通过这些措施进一步提高其性能。从微软发表的观点来看,如果低参数模型在精心策划的高质量数据集上进行训练,它们可以与大参数模型竞争。
fine-tune
import os
from dataclasses import dataclass, field
from typing import Optional
import torch
from datasets import load_dataset
from datasets import load_from_disk
from peft import LoraConfig
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
HfArgumentParser,
AutoTokenizer,
TrainingArguments,
)
from tqdm.notebook import tqdm
from trl import SFTTrainer
from huggingface_hub import interpreter_login
interpreter_login()
compute_dtype = getattr(torch, "float16")
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type='nf4',
bnb_4bit_compute_dtype='float16',
bnb_4bit_use_double_quant=False,
)
device_map = {"": 0}
#Download model
model = AutoModelForCausalLM.from_pretrained(
"microsoft/phi-2",
quantization_config=bnb_config,
device_map=device_map,
trust_remote_code=True,
use_auth_token=True
)
model.config.pretraining_tp = 1
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=32,
target_modules=['lm_head.linear', 'transformer.embd.wte'], # is this correct?
bias="none",
task_type="CAUSAL_LM",
)
tokenizer = AutoTokenizer.from_pretrained("microsoft/phi-2", trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
training_arguments = TrainingArguments(
output_dir="./results",
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
optim="paged_adamw_32bit",
save_steps=500, #CHANGE THIS IF YOU WANT IT TO SAVE LESS OFTEN. I WOULDN'T SAVE MORE OFTEN BECAUSE OF SPACE
logging_steps=10,
learning_rate=2e-4,
fp16=False,
bf16=True,
max_grad_norm=.3,
max_steps=10000,
warmup_ratio=.03,
group_by_length=True,
lr_scheduler_type="constant",
)
model.config.use_cache = False
dataset = load_dataset("json", data_files="your_dataset.json", split="train")
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=peft_config,
dataset_text_field="text",
max_seq_length=2048,
tokenizer=tokenizer,
args=training_arguments,
packing=False,
)
trainer.train()