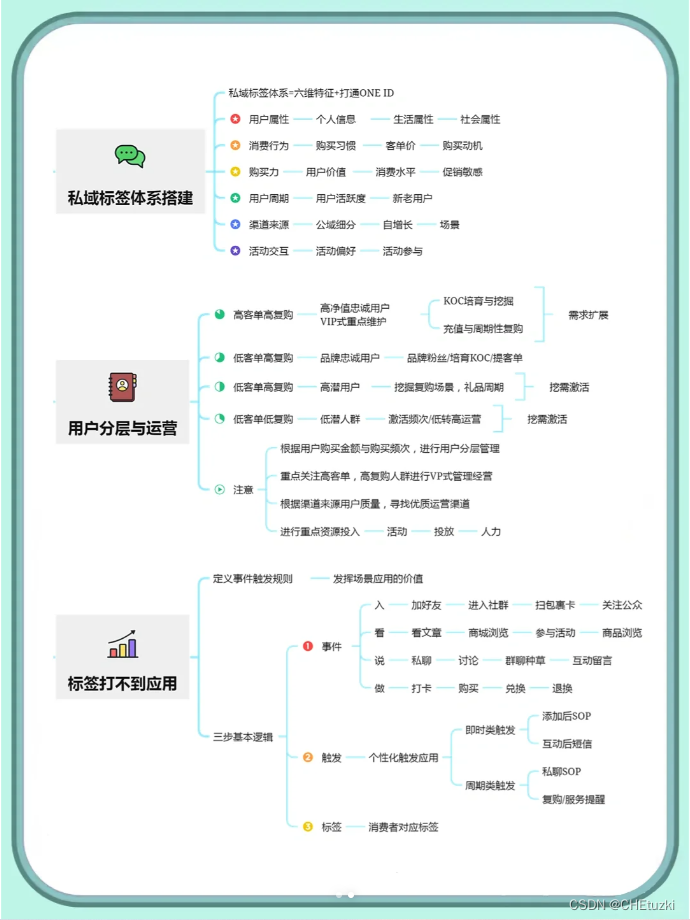
事务回滚
在执行数据库SQL时,如果我们检测到事务提交冲突,那么事务中所有已执行的SQL要进行回滚,目的是防止数据库出现数据不一致。对于单库事务回滚直接使用相关SQL即可。
如果涉及分布式数据库,则要考虑使用分布式事务,最常见的如两阶段提交、三阶段提交协议,这种方式实现事务回滚难度较低,但是对性能影响比较大,因为我们在大多数场景中需要的是最终一致性,而不是强一致性。
因此,可以考虑如事务表、消息队列、补偿机制(执行/回滚)、TCC模式(预占/确认/取消)、Sagas模式(拆分事务+补偿机制)等实现最终一致性。
比如,电商中的单场景,会进行扣减优惠券、预占库存等操作,这涉及非常多的子系统,因此,很难使用分布式事务保证强一致性,我们只要能保证最终一致性即可,下面来看看结算下单序列图。
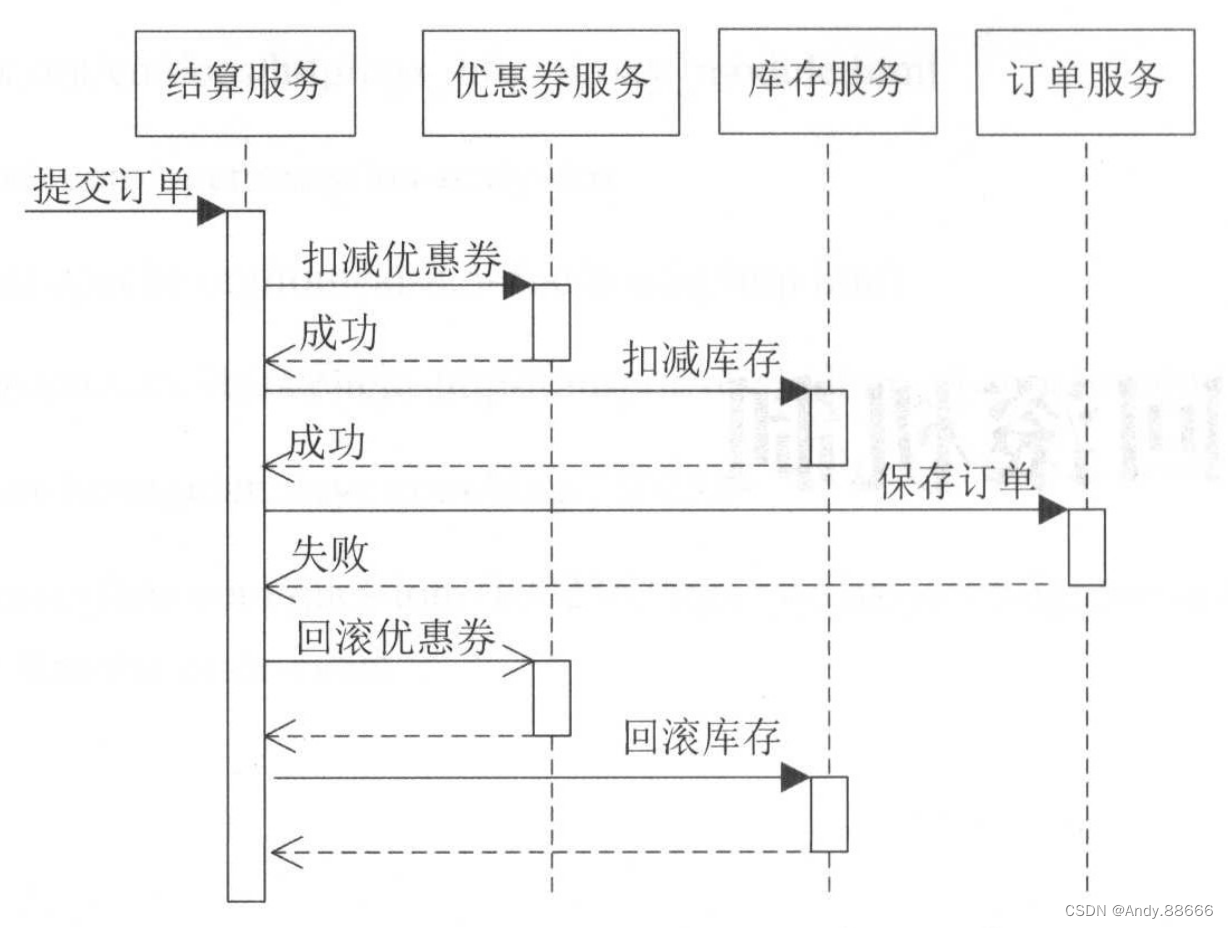
一种情况是当订单出错后,要把之前扣减的优惠券和库存回滚。
但是,当保存订单出错时,JVM实例挂掉了,那么之前扣减的优惠券和库存就没有回滚,这种情况可以考虑在本地记录事务日志,当JVM实例重启后,分析事务日志重新回滚,当然也可以记录事务日志表,或者通过补偿机制,定期扫描优惠券和库存使用表,回滚没有关联订单的或者已取消订单的记录。
还有一种情况是下单后一直没有支付,比如6小时,没有支付的订单要取消,此时就要定期扫描订单表,然后取消订单并回滚优惠券和库存。不管用什么方式,只要保证最终一致性即可。
代码库回滚
在开发项目时,一定要将代码维护到代码仓库,从而进行版本管理。常见的有SVN、Git等,SVN是一款集中版本控制系统,而Git是一款分布式版本控制系统。
有了版本控制系统后就可以记录代码的历史版本,在出问题后可以方便回滚。
当某个代码文件部署出现问题时,可以通过历史版本查看是谁修改的、修改了什么,从而快速定位出BUG。
另外,在实际开发过程中,可能存在多个版本并行开发,此时版本控制系统的分支功能就发挥大作用了,大家在各自分支上开发测试,相互不影响,开发完成后合并分支到主干即可。
部署版本回滚
代码测试完成后,接下来就要进行系统的部署,在部署系统时,要考虑当代码逻辑出现错误后如何快速恢复,总结为部署版本化、小版本增量发布、大版本灰度发布、架构升级并发发布。
部署版本化
每次部署时,应该将上一版本的包记录到部署系统中,在发布时应该采用全量发布,避免增量发布(只发布修改过的类或文件)。如有需要,全量版本可直接回滚,不会受到约束或限制。
小版本增量发布
比如修复BUG,添加一些简单的业务逻辑,这些我们叫作小版本。
增量发布的意思是比如我们有100台服务器,先发布1台验证,如果没问题,则接着发布10台,最后全量发布。
大版本灰度发布
在页面改版、添加新的功能时需要进行灰度发布,一般情况下是两个版本并行跑一段时间,一些用户访问老版本,一些用户访问新版本,功能验证成功后或者新版本效果不错时,再全量发布。比如,我们可以通过类似如下带有版本号的URL来区分新版本和老版本。
https://cd.jd.com/yanbao/v3?skuId=8540736cat=652,654,8326brandId=8983&area=1_2810_51081_06callback=yanbao_jsonp_callback
不同版本其实就是不同的服务,在一套集群部署即可,出问题时要能非常快速地切换回老版本。
架构升级并发发布
架构升级后,我们不太清楚新版本是否功能正常,因此,新老版本部署集群会同时存在一段时间。然后,等所有流量迁移到新版本集群后,老版本集群就可以下线了。
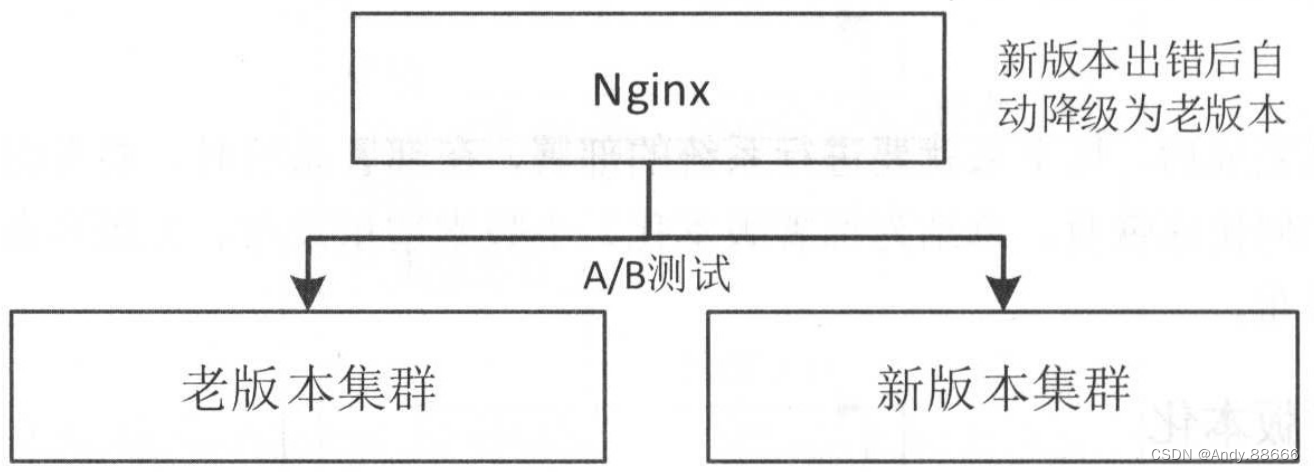
一般前端应用我们会采用Nginx作为接入层,通过A/B方式慢慢地将流量引入到新版本集群,比如1%→10%→50%→100%。如果新版本集群处理出现问题,那么要自动降级到老版本集群继续服务。若新版本出现大面积故障,则要将所有流量引入到老版本集群。因此,接入层要能灵活控制流量方向。
数据版本回滚
有些特定行业业务数据中的商品/价格数据需要进行版本化处理,一方面为了审计需要,另一方面为了出现问题时能及时回滚。版本化设计可以基于下图的架构。

设计版本化数据结构时,有两种思路:全量和增量。
全量版本化是指即使只变更了其中一个字段也将整体记录进行历史版本化,保存的数据量比较多,但是回滚方便。
而增量版本化是指只保存变化的字段,保存的数据量较少,但是回滚起来很麻烦,需要回溯。因此,为了简单化处理一般采用全量版本化机制。
另外,在设计消息队列时,重要业务会对消息进行副本处理,以便万一业务逻辑出现问题能进行历史数据回滚,从而修复问题。
静态资源版本回滚
在前端开发中,静态资源版本也是会经常变更的,如JS/CSS,而每次内容变更时我们都会生成一个全量新版本放到项目的deploy目录中,从而保证版本可追溯,出现问题时能及时回滚。
因为静态资源一般放在CDN上,所以缓存时间设置得比较长,比如1个月。这样若发布的版本有问题,则需要清理CDN缓存,也需要清理浏览器缓存,而且因为存在版本覆盖的问题,所以即使覆盖了也不一定保证操作正确。
- 发布新的静态资源到源服务器。
- 清理CDN缓存,从而可以回源服务器获取最新的静态资源。
- 在新的URL上添加随机数并清理浏览器缓存。