作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO
联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬
前置知识:前后端数据传输格式(下)
新手程序员,尤其是非科班的朋友,往往都非常重视具体技术点的学习,比如多线程、JWT、Redis、甚至Spring源码,但却经常性地忽略数据库表的设计。
为什么会造成这种情况呢?
第一,大部分新手程序员参与到一个项目时,表都已经建好了,他们的工作就是在现有工程下做做CRUD。
第二,不管培训班还是网络上的学习资料,很少会专门去讲怎么设计数据库、为什么要这么设计。
所以,绝大部分非科班程序员都不具备数据库设计能力。这会带来哪些坏处呢?我个人最大的体会是,去甲方开会时,对于甲方提出的各种需求,你基本是懵逼的,完全无法和实际编程联系在一起:
啊?这个需求怎么设计表结构啊,听起来好难啊...
我自己的看法是,数据库设计是整个项目最关键、最难的地方,数据库设计的好坏直接影响编码的质量和效率。
怎么提升自己的数据库设计能力呢?我有两个建议:
- 多观察公司现有项目的某些需求设计,研究它的表结构和编码,然后抽取出几种常见的设计思路
- 自己平时多想、多做、多借鉴,自己给自己出需求,然后考虑如何设计、SQL和代码怎么写,卡住了就百度,借鉴别人的设计思路
我始终觉得数据库设计其实是存在若干种模式的,而每一种模式只要稍微变通一下,又可以用来完成很多看似完全不同的需求。限于篇幅,这里优先介绍树形结构。
树形结构是一种非常经典的表设计模型,看似平凡却又包罗万象,在实际开发中有着非常广泛的应用。
最典型的树形结构就是商品分类:
|-家用电器
|-电视
|-空调
|-洗衣机
|-滚筒洗衣机
|-洗烘一体机
|-...
|-手机/运营商/数码
|-手机通讯
|-运营商
|-手机配件
|-手机壳
|-贴膜
|-...
还有省-市-区级联:
|-浙江省
|-杭州市
|-宁波市
|-温州市
|-...
|-安徽省
|-合肥市
|-黄山市
|-芜湖市
|-...
其他的还包括目录、部门、甚至RBAC权限控制等,随处可见树形结构的设计。
严格来说,真正的树应该只有一个root节点,而上面提到的都有多个root节点,但我还是习惯称为“树形结构”。
设计阶段
如何定义JavaBean
我以前接触过一个前端插件,叫zTree。这个插件的作用是把接口返回的数据以树形结构的形式展示出来:

zTree插件需要后端返回特定的数据格式才能做出上面的效果,官方文档给的demo如下:
<!--1.准备一个Div,设置id-->
<div class="panel-body">
<ul id="permissionTree" class="ztree"></ul>
</div>
// 2.需要的数据
var zNodes =[
{
name:"父节点1 - 展开",
open:true,
children: [
{
name:"父节点11 - 折叠",
children: [
{ name:"叶子节点111"},
{ name:"叶子节点112"},
{ name:"叶子节点113"},
{ name:"叶子节点114"}
]
},
{
name:"父节点12 - 折叠",
children: [
{ name:"叶子节点121"},
{ name:"叶子节点122"},
{ name:"叶子节点123"},
{ name:"叶子节点124"}
]
},
{
name:"父节点13 - 没有子节点",
isParent:true
}
]
},
{
name:"父节点2 - 折叠",
children: [
{...},
{...}
]
},
{
name:"父节点3 - 没有子节点",
isParent:true
}
];
// 3.把数据在指定div渲染成一棵树
$.fn.zTree.init($("#permissionTree"), setting, zNodes);有些字段省略,不用在意,关注外部结构即可
现在的问题是,后端如何返回上面这样的数据结构?
我们由外到内,分两步分析zNodes需要的数据格式!
先观察zNodes最外层:
var zNodes =[
{
name:"父节点1",
open:true,
children: [...]
},
{
name:"父节点2",
children: [...]
},
{
name:"父节点3 - 没有子节点",
isParent:true
}
];我们发现zNode其实是一个JS对象数组,现有三个对象:父节点1,父节点2,父节点3。
等等,这里有个重点!
一起放慢节奏思考一下:
现在我们已经明确zNodes是一个JS对象数组,那么Java中什么类型的数据返回到前端会变成一个数组呢?
答案是:常用List!
来做个试验:
@RestController
public class TestController {
@RequestMapping("/testList")
public List getList() {
ArrayList<User> userList = new ArrayList<>();
userList.add(new User("李健", 18));
userList.add(new User("周杰伦", 20));
userList.add(new User("李雪健", 30));
return userList;
}
@RequestMapping("/testMap")
public Map getMap() {
HashMap<String, User> hashMap = new HashMap<>();
hashMap.put("1号男嘉宾", new User("卡卡罗特", 21));
hashMap.put("2号男嘉宾", new User("贝吉塔", 22));
hashMap.put("3号男嘉宾", new User("雅木茶", 23));
return hashMap;
}
@RequestMapping("/testSet")
public Set getSet() {
HashSet<User> hashSet = new HashSet<>();
hashSet.add(new User("刘备", 33));
hashSet.add(new User("关羽", 32));
hashSet.add(new User("张飞", 31));
return hashSet;
}
}Postman测试(以List为例):
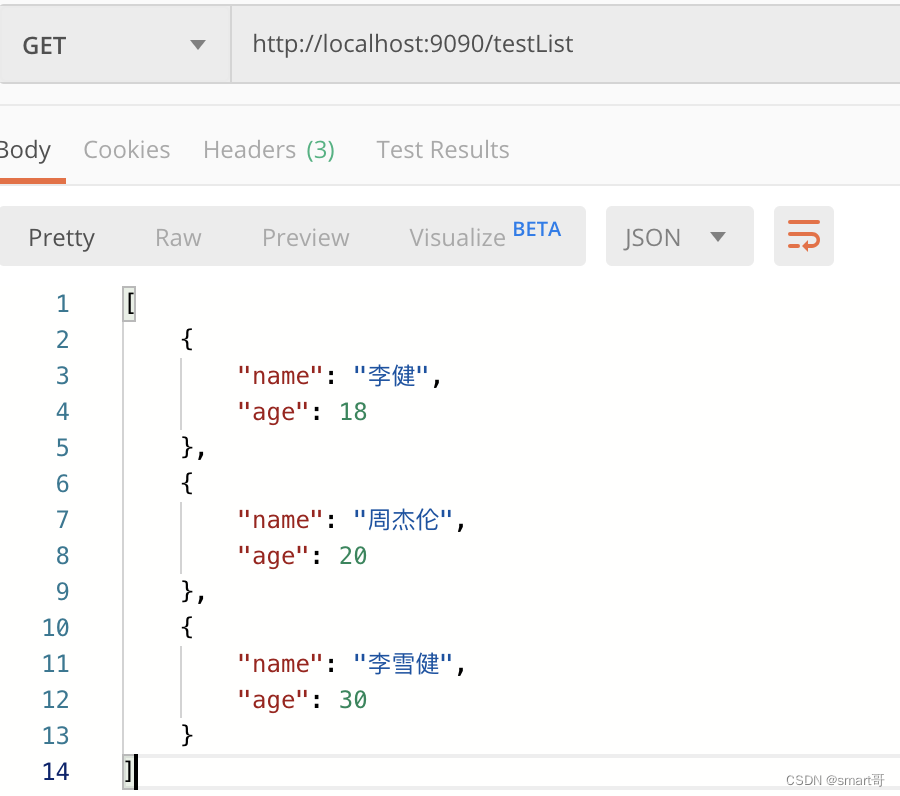
全部测完,对比结果:

后端返回的其实都是JSON,但是本文的视角是前端,所以把JSON和JS对象一同看待
上面只例举了Map、List、Set,其实数组的返回结果和List、Set一样。但通常不用数组,因为数组可用的方法太少,不利于后端通过数组对数据进行操作。
我们发现,Map到了前端对应一个JS对象,而Set和List都是对应一个JS数组。实际开发中,前端如果需要一个数组,我们通常返回List即可,Set的情况较少(除非要去重)。
至此,关于如何设计JavaBean,我们确定了一个大方向:最外层用List返回。
接下来,我们往zNodes的内层走走,分析一下后端的List应该存什么对象,也就是如何设计JavaBean。
var zNodes =[
{
name:"父节点1 - 展开11111",
open:true,
children: [
{
name:"父节点11 - 折叠",
children: [...]
},
{
name:"父节点12 - 折叠",
children: [...]
},
{
name:"父节点13 - 没有子节点",
isParent:true
}
]
},
{
name:"父节点2 - 折叠",
children: [...]
},
{
name:"父节点3 - 没有子节点",
isParent:true
}
];我们发现父节点1的children其实也是一个对象数组,而且内部JS对象的结构和最外面三个父节点JS对象一致。很多新手看到这样的数据,老觉得这里是递归,无穷无尽,后端干脆没法设计...
那么,前端是否是无限递归呢?
我们退回来,慢慢推导。
假设后端List中存的对象叫JsBean,那么JsBean最终传到前端就变成了zNodes对象数组中的JS对象。
List [JsBean, JsBean, JsBean...] ===> zNodes[{...}, {...}, {...}]
这个应该能理解吧?后端List对应前端zNodes的[],JsBean对应zNodes数组内部的JS对象。
后端:JsBean
public class JsBean{
private String name;
private Boolean open;
private Boolean isParent;
// 前端JS对象的children数组(对应List)里存的还是JS对象(对应JsBean),所以是List<JsBean>
private List<JsBean> children;
}前端:JS对象(请和上面JsBean对照,看看这样设计是否合理)
{
name:"父节点1 - 展开11111",
open:true,
children: [
{
name:"父节点11 - 折叠",
children: [...]
},
{
name:"父节点12 - 折叠",
children: [...]
},
{
name:"父节点13 - 没有子节点",
isParent:true
}
]
}先不考虑递归啥的,就暂时当数据只有三级好了~
那么,后端这样设计Bean表示到底对不对呢?做个试验吧:
@RestController
public class TestController {
@RequestMapping("testList")
public List getList() {
// 定义一个List,用来存储最终结果
ArrayList<JsBean> superMen = new ArrayList<>();
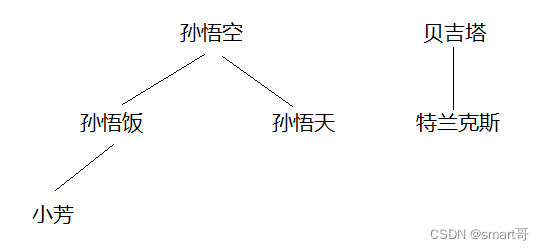
//------------------------七龙珠(从下往上看会好理解些,开枝散叶)------------------------
// 孙悟饭的儿子们:悟饭儿子1、悟饭儿子2
List<JsBean> grandChildren1 = new ArrayList<>();
grandChildren1.add(new JsBean("悟饭儿子1", false, false, null));
grandChildren1.add(new JsBean("悟饭儿子2", false, false, null));
// 孙悟天的儿子们:悟天儿子1、悟天儿子2
List<JsBean> grandChildren2 = new ArrayList<>();
grandChildren2.add(new JsBean("悟天儿子1", false, false, null));
grandChildren2.add(new JsBean("悟天儿子2", false, false, null));
// 孙悟空的儿子:悟饭、悟天
List<JsBean> children = new ArrayList<>();
children.add(new JsBean("悟饭", false, true, grandChildren1));
children.add(new JsBean("悟天", false, true, grandChildren2));
// 孙悟空本人
JsBean wukong = new JsBean("悟空", true, true, children);
//------------------------火影忍者(从下往上看会好理解些,开枝散叶)------------------------
// 鸣人的徒弟们:博人1、博人2
List<JsBean> grandChildren3 = new ArrayList<>();
grandChildren3.add(new JsBean("博人1", false, false, null));
grandChildren3.add(new JsBean("博人2", false, false, null));
// 佐助的徒弟们:佐良娜1、佐良娜2
List<JsBean> grandChildren4 = new ArrayList<>();
grandChildren4.add(new JsBean("佐良娜1", false, false, null));
grandChildren4.add(new JsBean("佐良娜2", false, false, null));
// 卡卡西的徒弟们:鸣人、佐助
List<JsBean> children2 = new ArrayList<>();
children2.add(new JsBean("鸣人", false, true, grandChildren3));
children2.add(new JsBean("佐助", false, true, grandChildren4));
// 卡卡西本人
JsBean kakaxi = new JsBean("卡卡西", true, true, children2);
//------------------------处理结果------------------------
// 只把孙悟空和卡卡西加入List
superMen.add(wukong);
superMen.add(kakaxi);
return superMen;
}
}
Postman得到结果:
[
{
"name": "悟空",
"open": true,
"isParent": true,
"children": [
{
"name": "悟饭",
"open": false,
"isParent": true,
"children": [
{
"name": "悟饭儿子1",
"open": false,
"isParent": false,
"children": null
},
{
"name": "悟饭儿子2",
"open": false,
"isParent": false,
"children": null
}
]
},
{
"name": "悟天",
"open": false,
"isParent": true,
"children": [
{
"name": "悟天儿子1",
"open": false,
"isParent": false,
"children": null
},
{
"name": "悟天儿子2",
"open": false,
"isParent": false,
"children": null
}
]
}
]
},
{
"name": "卡卡西",
"open": true,
"isParent": true,
"children": [
{
"name": "鸣人",
"open": false,
"isParent": true,
"children": [
{
"name": "博人1",
"open": false,
"isParent": false,
"children": null
},
{
"name": "博人2",
"open": false,
"isParent": false,
"children": null
}
]
},
{
"name": "佐助",
"open": false,
"isParent": true,
"children": [
{
"name": "佐良娜1",
"open": false,
"isParent": false,
"children": null
},
{
"name": "佐良娜2",
"open": false,
"isParent": false,
"children": null
}
]
}
]
}
]后端返回一个List,所以前端整体看是一个JS数组。数组最外层是两个JS对象:

展开:

是不是和 zNodes一模一样?
也就是说,后端这样设计JavaBean完全没问题。前端JS对象数组并不是所谓的无限递归,它的层级取决于数据库表中数据设计了多少层。所以在树形结构中,不要去担心前端会不会出现无限递归,而要问后端要设置多少级数据!从后往前设计,由后端来控制整个树形结构的深度。
就好比刚才的程序中,我让悟天孩子不再有孩子,于是返回前端后,悟天儿子1就没有children了:

也就是说,前端是跟着后端走的,不要尝试从前端逆推,那样你会觉得似乎是无限递归,无从下手。
至此,JavaBean设计完毕,后端只要返回Superman的List集合就能刚好满足zNodes的数据格式:
public class Superman{
private String name;
private Boolean open;
private Boolean isParent;
// 前端JS对象的children数组(对应List)里存的还是JS对象(对应Superman),所以是List<Superman>
private List<Superman> children;
}如何设计表
接下来我们考虑下数据库表如何设计(刚才只是验证了Bean的设计,数据是我们在代码里造的)。
对于树形结构,我们最直观的想法自然是为每一级都创建一个对应的表。又由于父可以有多个子,具备一对多的关系。遇到一对多,我首先最直观的想法是使用外键(pid)关联。
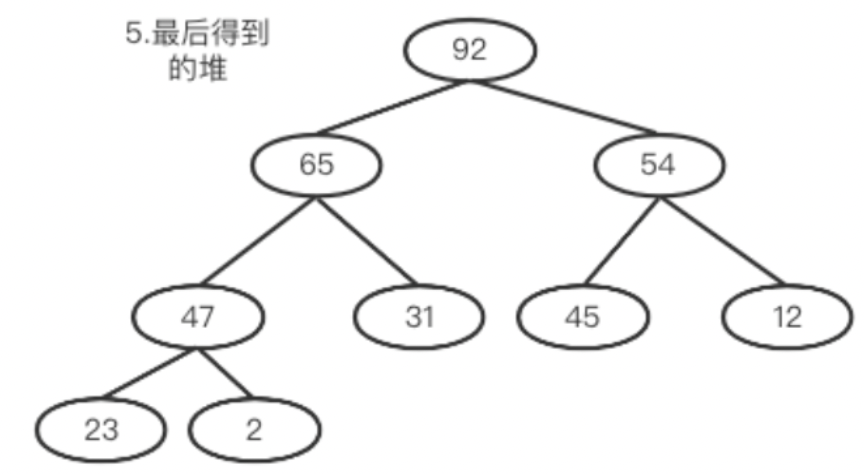
分析龙珠里的人物关系,我发现数据最深层级是3级。
如果每一级都创建一张表,共需设计三张表。比如一级的我都存入t_first,二级的我都存入t_second...然后用外键关联每张表。
t_first
| id | name | open | isParent |
| 1 | 孙悟空 | 0 | 1 |
| 2 | 贝吉塔 | 0 | 1 |
t_second(pid指向t_first,表明他们的父亲)
| id | name | open | isParent | pid |
| 1 | 孙悟饭 | 0 | 1 | 1 |
| 2 | 孙悟天 | 0 | 0 | 1 |
| 3 | 特兰克斯 | 0 | 0 | 2 |
t_third(pid指向t_second,表明她的父亲)
| id | name | open | isParent | pid |
| 1 | 小芳 | 0 | 0 | 1 |
先不说表字段是否合理,这个表本身就不合理...万一小芳再生小孩呢(层级加深)?我需要再建一张表。另外,遇到某些业务场景下数据层级很深的情况,那我要建多少张表?
我们能不能把这些表合并,用一张表表示复杂的父子层级关系?
很容易发现,这三张表字段都是基本相同,合并起来还是比较容易的。我们采用并集。
合并的第一步,是让三张表具有相同的字段(其实就是给t_first补充pid字段):
t_first
| id | name | open | isParent | pid |
| 1 | 孙悟空 | 0 | 1 | ? |
| 2 | 贝吉塔 | 0 | 1 | ? |
t_second(pid指向t_first,表明他们的父亲)
| id | name | open | isParent | pid |
| 1 | 孙悟饭 | 0 | 1 | 1 |
| 2 | 孙悟天 | 0 | 0 | 1 |
| 3 | 特兰克斯 | 0 | 0 | 2 |
t_third(pid指向t_second,表明她的父亲)
| id | name | open | isParent | pid |
| 1 | 小芳 | 0 | 0 | 1 |
万事开头难,我们发现t_first加了pid字段后,竟不知该填什么数据(用?占位)...问题出在哪?因为在我们目前这个设定中,孙悟空和贝吉塔是第1级,他们没有父亲。那就干脆写个0好了。以后看到pid=0的,就知道这是第1级。
嗯?等等。如果用pid表示父亲的id,pid=0代表第1级,那么第2级的pid指向第1级的id,不就形成了一对多的关系了吗?

所以,合并第二步就是把三张表压缩成一张:
| id | name | isParent | open | pid |
| 1 | 孙悟空 | 1 | 0 | 0 |
| 2 | 贝吉塔 | 1 | 0 | 0 |
| 3 | 孙悟饭 | 1 | 0 | 1 |
| 4 | 孙悟天 | 0 | 0 | 1 |
| 5 | 特兰克斯 | 0 | 0 | 2 |
| 6 | 小芳 | 0 | 0 | 3 |
这样一来,原先三张表通过外键关联,现在变成了一张表自关联:pid关联id。
接着,我们尝试一下能否根据这张表查出具有层级关系的数据
- 先找第1级:pid=0,得到孙悟空(id=1)、贝吉塔(id=2)
- 再找第2级:
-
- pid=1的都是孙悟空的孩子
-
-
- 孙悟饭(id=3)
- 孙悟天(id=4)
-
-
- pid=2的都是贝吉塔的孩子
-
-
- 特兰克斯(id=5)
-
- 最后找第3级:
-
- pid=3的都是孙悟饭的孩子
-
-
- 小芳(id=6)
-
-
- pid=4的都是孙悟天的孩子(无)
- pid=5的都是特兰克斯的孩子(无)
- 尝试查找第4级:
-
- pid=6的都是小芳的孩子(无)
嗯,完美,都查出来了,但我们发现查找过程中根本没用到name,isParent,open。
对于一颗树,其实只需要id和pid,相当于树干脉络,其他的都是点缀。
name:前端展示时,显示当前节点的名称
isParent:当前节点下面有没有孩子
open:前端根据它确定是否要展开显示
为了给上面的字段分类,我新创了两个名词:
- 结构字段:pid、id
- 业务字段:name、isParent、open
pid和id属于结构字段,它俩是维持树形结构的必须字段,是根基,而其他3个字段属于业务字段,用于展示数据,或作为前端的判断标识,可以根据业务需求进行增添。
其中isParent蛮有意思的,这里单独说一下。比如我在数据库中随便指着一个节点,你能否马上告诉我他下面有没有孩子?(之所以有这个需求,是因为前端有可能需要把有孩子的节点渲染成文件夹样式)
答案是不能。不要想pid,它只是告诉你当前节点的parent是谁,而不是当前节点有没有子节点。如果没有isParent字段,你必须去数据库查有没有以这个节点的id为pid的数据,这显然很麻烦。所以,我们可以在插入或更新时去维护这个字段(一般这种分类很少会改动,查询居多)。
那么,最终我们得到一个可以表示树形层级结构的表:
t_superman
| id | name | isParent | open | pid |
| 1 | 孙悟空 | 1 | 0 | 0 |
| 2 | 贝吉塔 | 1 | 0 | 0 |
| 3 | 孙悟饭 | 1 | 0 | 1 |
| 4 | 孙悟天 | 0 | 0 | 1 |
| 5 | 特兰克斯 | 0 | 0 | 2 |
| 6 | 小芳 | 0 | 0 | 3 |
一句话总结:
对于多层级的表来说最重要的id和pid,它们决定了数据的层级脉络,其他的属于附属内容。比如该节点是不是父节点(isParent),如果是,前端渲染时是否展开(open)。这些对于数据结构本身是无关紧要的。
但是反过来,从业务内容来讲,pid是其次的,name等附属内容才是最重要的,它们才是数据主体。
读取表中数据
至此我们完成了JavaBean和表的设计,接下来我们学习一下如何查询数据并返回树形结构的数据。一般我们参与开发时,主要做的就是这一步。从这个角度来看,上面的设计固然重要,但学会如何编码才是当务之急。
这里介绍三种方法:
- 递归读取
- for循环读取
- map集合读取
本节介绍的三种方法都是全量嵌套查询,而一般情况下根据pid分步查询更为妥当,既简单又不容易出错。希望大家学了这篇文章后,不要无脑使用全量嵌套。为了炫技而炫技,可能会被打。
环境准备
SQL文件
/*
Navicat Premium Data Transfer
Source Server : learnforfun
Source Server Type : MySQL
Source Server Version : 50719
Source Host : localhost:3306
Source Schema : test
Target Server Type : MySQL
Target Server Version : 50719
File Encoding : 65001
Date: 31/12/2019 10:56:18
*/
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for t_superman
-- ----------------------------
DROP TABLE IF EXISTS `t_superman`;
CREATE TABLE `t_superman` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) COLLATE utf8mb4_bin DEFAULT NULL,
`open` tinyint(2) DEFAULT NULL,
`pid` int(11) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
-- ----------------------------
-- Records of t_superman
-- ----------------------------
BEGIN;
INSERT INTO `t_superman` VALUES (1, '孙悟空', 0, 0);
INSERT INTO `t_superman` VALUES (2, '贝吉塔', 0, 0);
INSERT INTO `t_superman` VALUES (3, '孙悟饭', 0, 1);
INSERT INTO `t_superman` VALUES (4, '孙悟天', 0, 1);
INSERT INTO `t_superman` VALUES (5, '特兰克斯', 0, 2);
INSERT INTO `t_superman` VALUES (6, '小芳', 0, 3);
COMMIT;
SET FOREIGN_KEY_CHECKS = 1;Pom依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>tk.mybatis</groupId>
<artifactId>mapper-spring-boot-starter</artifactId>
<version>2.1.5</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>启动类
@SpringBootApplication
@MapperScan("com.bravo.tree.mapper")
public class SpringbootDemoApplication {
public static void main(String[] args) {
SpringApplication.run(SpringbootDemoApplication.class, args);
}
}
Pojo
@Data
@AllArgsConstructor
@NoArgsConstructor
@Table(name = "t_superman")
public class Superman {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
private String name;
private String isParent;
private Boolean open;
private Integer pid;
// 前端JS对象的children数组(对应List)里存的还是JS对象(对应Superman),所以是List<Superman>
@Transient
private List<Superman> children = new ArrayList<>();
}Controller
@RestController
public class SupermanController {
@Autowired
private SupermanService supermanService;
@RequestMapping("/getAllSuperman")
public List getAllSuperman() {
// supermanService才是重点,接下来演示三种全量嵌套查询的方法
List<Superman> list = supermanService.getAllSuperman();
return list;
}
}递归读取
我个人不是很擅长递归,不知道其他人是否一样。下面3个方法其实可以合并,但是为了降低理解难度,我还是拆开:
@Service
public class SupermanService {
@Autowired
private SupermanMapper supermanMapper;
/**
* 查询所有赛亚人
* @return
*/
public List<Superman> getAllSuperman() {
// 查出所有的根节点:孙悟空、贝吉塔
List<Superman> rootSupermanList = getRootSuperman();
// 分别查出孙悟空和贝吉塔的孩子,并设置
for (Superman superman : rootSupermanList) {
List<Superman> children = queryChildrenByParent(superman);
superman.setChildren(children);
}
// 返回
return rootSupermanList;
}
/**
* 查出根节点(pid=0)
* @return
*/
private List<Superman> getRootSuperman() {
Superman superman = new Superman();
superman.setPid(0);
return supermanMapper.select(superman);
}
/**
* 递归查询孩子
* @param parent
* @return
*/
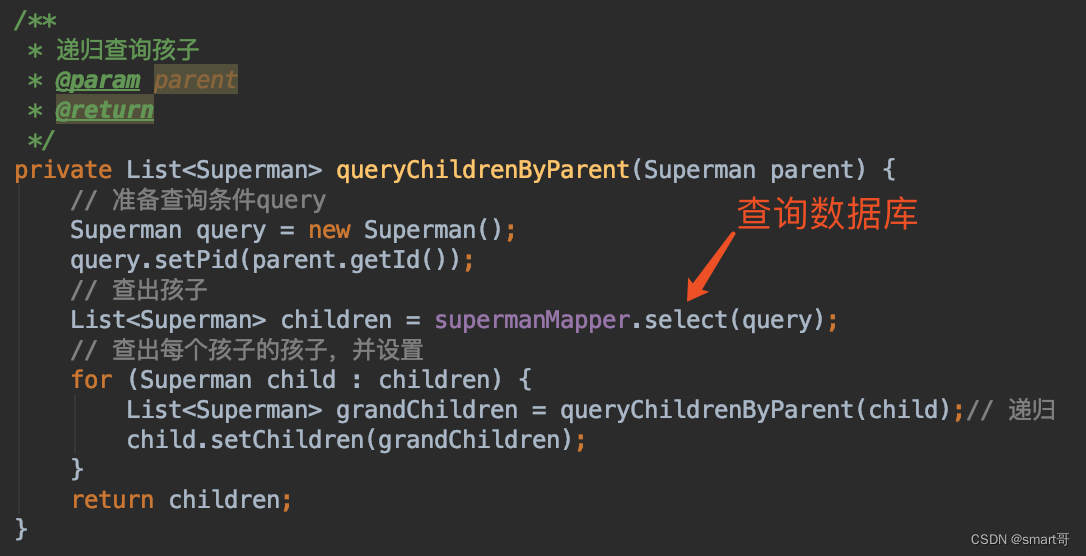
private List<Superman> queryChildrenByParent(Superman parent) {
// 准备查询条件query
Superman query = new Superman();
query.setPid(parent.getId());
// 查出孩子
List<Superman> children = supermanMapper.select(query);
// 查出每个孩子的孩子,并设置
for (Superman child : children) {
List<Superman> grandChildren = queryChildrenByParent(child);// 递归
child.setChildren(grandChildren);
}
return children;
}
}
特别注意递归的结束条件,否则容易出现死递归,造成内存溢出。在当前案例中,叶子节点是没有child的,所以不会再调用查询方法,也就走出递归了。

优点:直观(并没有觉得...递归对我而言很难)
缺点:在我们程序中,每次递归调用都会查询一次数据库,效率非常低
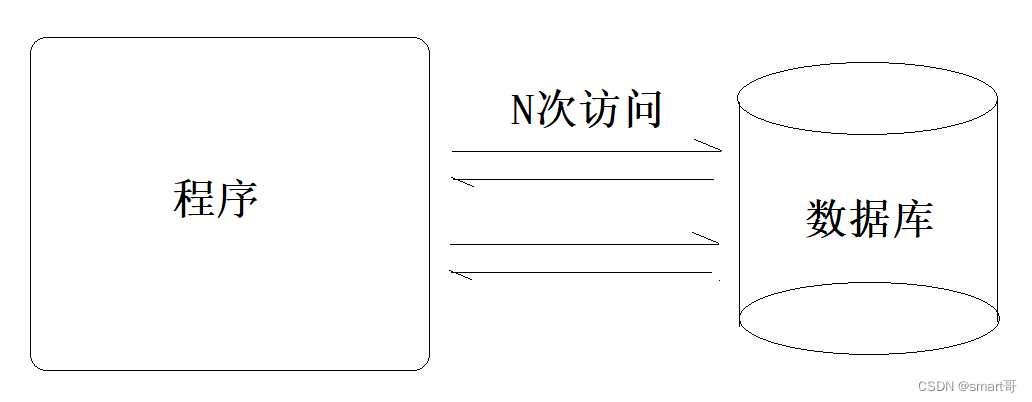
之前提到过,假设查询数据库总耗时10s,那么光是连接数据库就要花3s,也就是说,频繁调用数据库必然会降低性能。
上面递归方式不是重点,所以这里就不继续深入,只给出优化的方向:
- 造一个根节点,简化递归(根节点不止一个,所以上面代码只能配合for,每个根节点来一遍递归,很冗余)
- 先查出全部数据,再递归,而不是每递归一层就查询一次数据库,效率很低
for循环读取
吸取上面递归查询的教训,我们做两点改良:
- 先全量查询数据,再考虑如何组装树形结构
- 用for循环代替递归

/**
* 查询所有赛亚人
* @return
*/
public List<Superman> getAllSuperman() {
// 用来存储最终的结果
List<Superman> list = new ArrayList<>();
// 先查出全部数据
List<Superman> data = supermanMapper.selectAll();
// 双层for循环完成数据组装
for (Superman left : data) {
for (Superman right : data) {
// 如果右边是左边的孩子,就设置进去
if(left.getId() == right.getPid()){
left.getChildren().add(right);
}
}
// 只把第1级加到list
if(left.getPid() == 0){
list.add(left);
}
}
return list;
}示意图
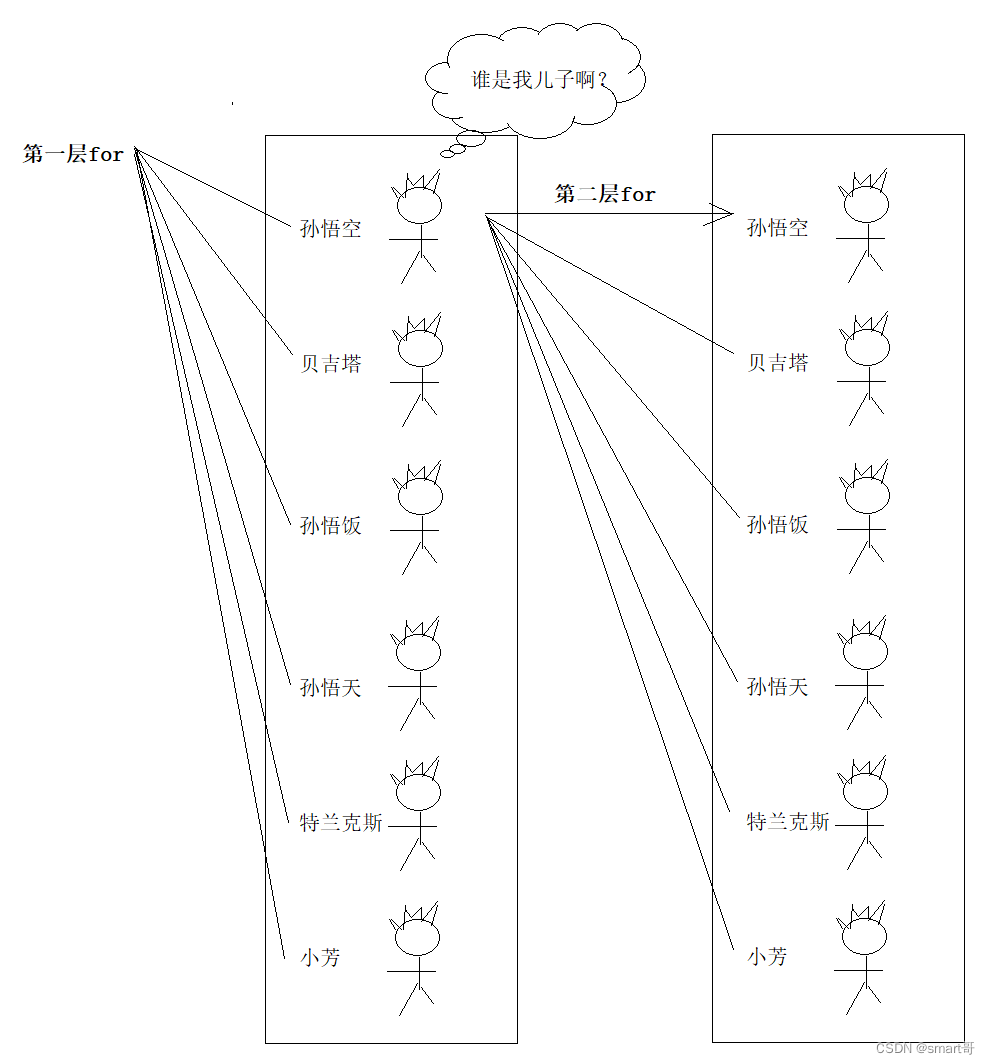
你可能会觉得,不对啊,左边孙悟空全部喊一遍后,设置了孙悟饭、孙悟天。但是此时悟饭没有设置小芳啊!
别忘了,孙悟空设置的其实是孙悟饭的引用。等左边悟饭全部喊一遍,把小芳加进来时,悟空里的悟饭不就有小芳了吗?
关于这点,需要的话可以停下来想想是不是这么回事。
优点:只查询一次数据库,而且很直观(个人觉得比递归直观)
缺点:双层for效率仍然很低,如果list长度为n,那么要循环n2次。也就是说,如果现在这个List表示的是全国的高校(学校-院系-专业),截止至2019年6月15日,教育部公布的全国高等学校共计有2956所,那么需要循环29562次,差不多是30002=900w次...
map集合读取
其实看到上面使用双层for,相信一部分同学已经能想到《实用小算法》了~没错,我们当时说《实用小算法》就是为了解决“数据匹配问题”而生的!
/**
* 查询所有赛亚人
* @return
*/
public List<Superman> getAllSuperman() {
// 用来存储最终的结果
List<Superman> list = new ArrayList<>();
// 源数据,需要处理
List<Superman> data = supermanMapper.selectAll();
// Map,用来转存List
HashMap<Integer, Superman> hashMap = new HashMap<>();
// 先把List转为Map,把Map作为左侧parent
for (Superman superman : data) {
hashMap.put(superman.getId(), superman);
}
// 右边child进行for循环找parent
for (Superman child : data) {
if(child.getPid() == 0){
list.add(child);// 找到第一级(悟空、贝吉塔)
} else {
// 不是第一级,那么肯定有parent,帮它找到parent,并把它自己设置到parent里
Superman parent = hashMap.get(child.getPid());// hash索引!找爸爸很快!
parent.getChildren().add(child);
}
}
return list;
}示意图

优点:查询效率提高了
缺点:空间利用率降低了(List/Array可以只存元素,而Map需要额外存储key)
本次循环次数是2n,双层for循环是n2 ,非要说的话,就是典型的“空间换时间”。
最终代码
Controller
public class SupermanController {
@Autowired
private SupermanService supermanService;
/**
* 全量嵌套查询,数据具备树形结构
* @return
*/
@RequestMapping("/getAllSuperman")
public List getAllSuperman() {
List<Superman> list = supermanService.getAllSuperman();
return list;
}
/**
* 根据pid分步查询(实际开发最常用)
* @param pid
* @return
*/
@RequestMapping("getSupermanByPid")
public List getSupermanByPid(Integer pid) {
List<Superman> list = supermanService.getSupermanByPid(pid);
return list;
}
}Service
@Service
public class SupermanService {
@Autowired
private SupermanMapper supermanMapper;
/**
* 查询所有赛亚人
* @return
*/
public List<Superman> getAllSuperman() {
// 用来存储最终的结果
List<Superman> list = new ArrayList<>();
// 源数据,需要处理
List<Superman> data = supermanMapper.selectAll();
// Map转List
HashMap<Integer, Superman> hashMap = new HashMap<>();
for (Superman superman : data) {
hashMap.put(superman.getId(), superman);
}
// 遍历源数据
for (Superman child : data) {
if(child.getPid() == 0){
list.add(child);// 找到根节点并存储
} else {
// 如果不是根节点,则找到上一级,并把自己设置为上一级的子节点
Superman parent = hashMap.get(child.getPid());
parent.getChildren().add(child);
}
}
return list;
}
/**
* 查询pid对应的下级内容
* @param pid
* @return
*/
public List<Superman> getSupermanByPid(Integer pid) {
Superman query = new Superman();
query.setPid(pid);
return supermanMapper.select(query);
}
}
延伸思考
写到最后,你会突然发现,其实不管业务场景是下面哪种:
- 省-市
- 省-市-区
- 高校-院系-专业-班级
- 商品分类
- ...
其实都是一样的!上面的模式其实就分为两部分:
- 表设计层面
- 代码层面
首先,表结构设计都是一样的,都是树形结构,变化的只是业务字段。
- 结构字段:pid、id
- 业务字段:city_name/school_name/category_name
其次,代码层面也不会因为前端是二级联查、三级联查还是N级联查而改变,双层for可以应付N级联查,代码都不需要改动。
到底前端是几级,和表结构无关,而和表数据有关。
二级(省-市)
| id | name | pid |
| 1 | 浙江省 | 0 |
| 2 | 安徽省 | 0 |
| 3 | 温州市 | 1 |
| 4 | 杭州市 | 1 |
| 5 | 合肥市 | 2 |
| 6 | 芜湖市 | 2 |
三级(省-市-县)
| id | name | pid |
| 1 | 浙江省 | 0 |
| 2 | 安徽省 | 0 |
| 3 | 温州市 | 1 |
| 4 | 杭州市 | 1 |
| 5 | 合肥市 | 2 |
| 6 | 芜湖市 | 2 |
| 7 | 苍南县 | 3 |
| 8 | 平阳县 | 3 |
四级(省-市-县-镇)
| id | name | pid |
| 1 | 浙江省 | 0 |
| 2 | 安徽省 | 0 |
| 3 | 温州市 | 1 |
| 4 | 杭州市 | 1 |
| 5 | 合肥市 | 2 |
| 6 | 芜湖市 | 2 |
| 7 | 苍南县 | 3 |
| 8 | 平阳县 | 3 |
| 9 | 钱库镇 | 7 |
| 10 | 金乡镇 | 7 |
四级(学校-院系-专业-班级)
| id | name | pid |
| 1 | 浙江大学 | 0 |
| 2 | 浙江工业大学 | 0 |
| 3 | 外国语学院 | 1 |
| 4 | 计算机学院 | 1 |
| 5 | 人文学院 | 2 |
| 6 | 土木工程 | 2 |
| 7 | 日语 | 3 |
| 8 | 英语 | 3 |
| 9 | 日语111班 | 7 |
| 10 | 日语112班 | 7 |
一模一样的表结构,但是前端展示出来的分别是二级、三级、四级,也就是说:结构字段决定树形结构,而业务数据决定树的深度。
作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO
进群,大家一起学习,一起进步,一起对抗互联网寒冬