背景
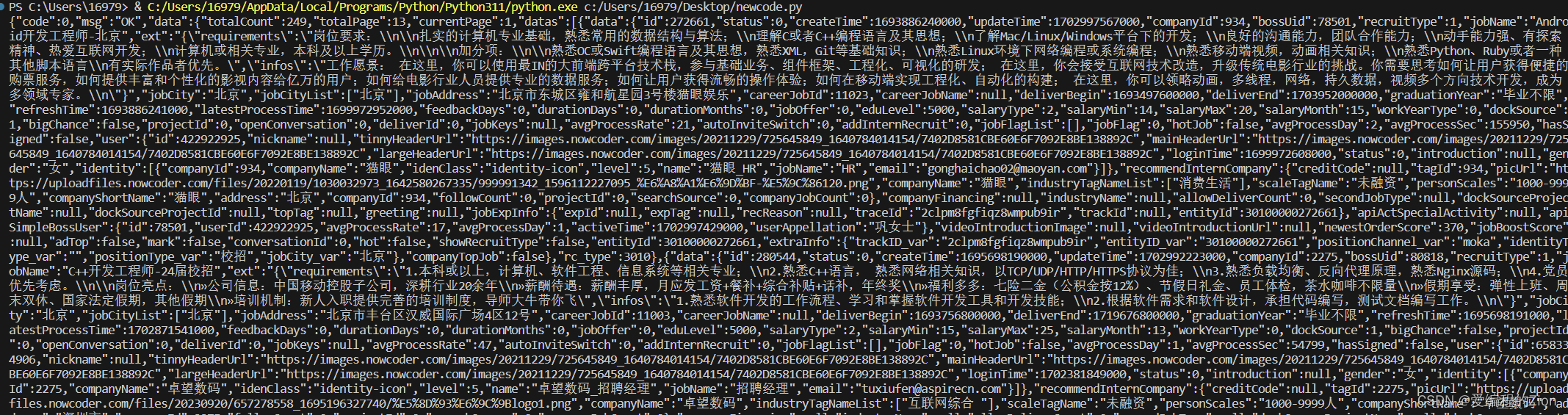
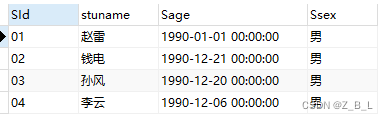
闲来无事想爬一下牛客网的校招薪资水平及城市分布,最后想做一个薪资水平分布的图表出来
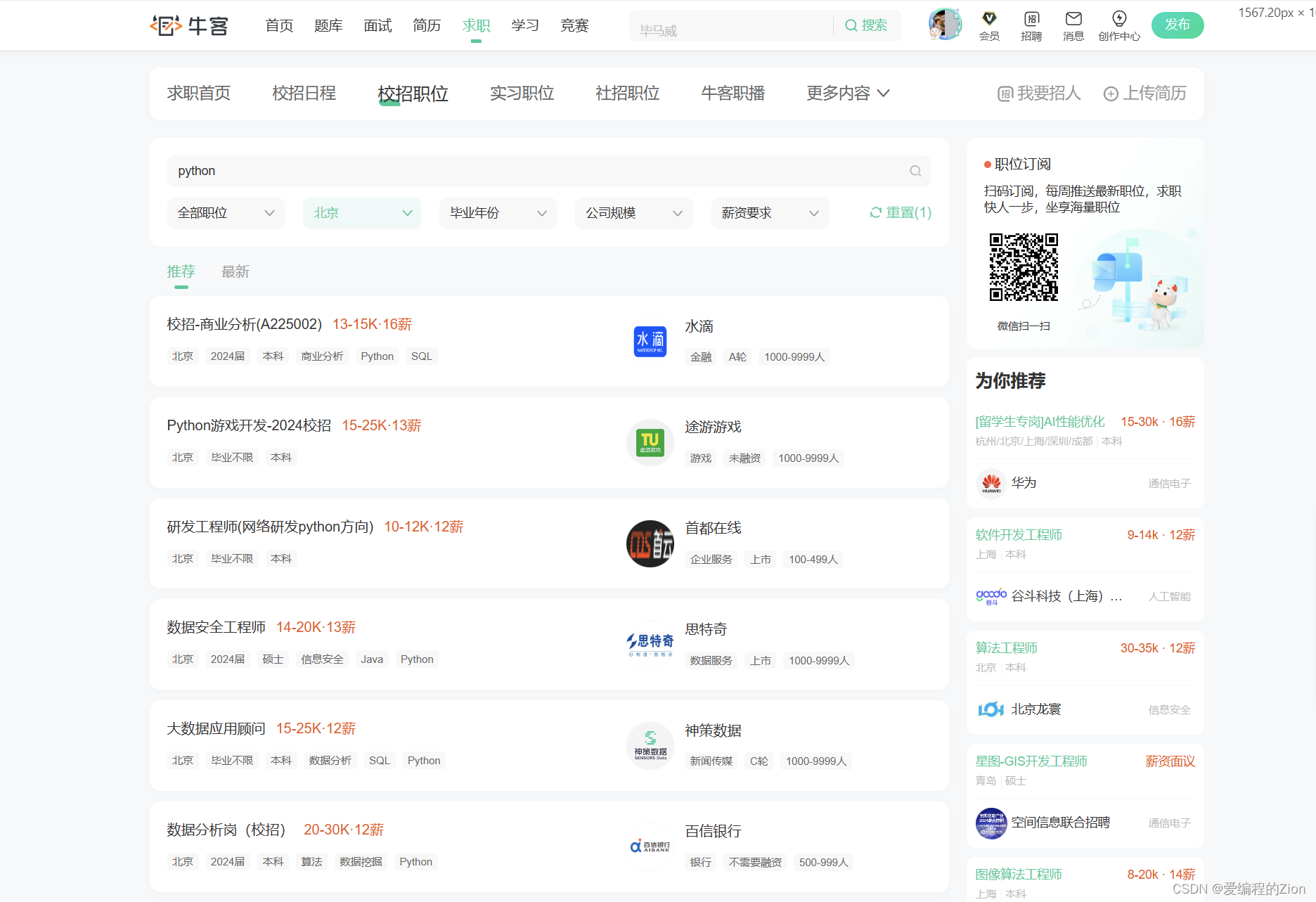 于是发现牛客使用的是application/x-www-form-urlencoded的格式
于是发现牛客使用的是application/x-www-form-urlencoded的格式
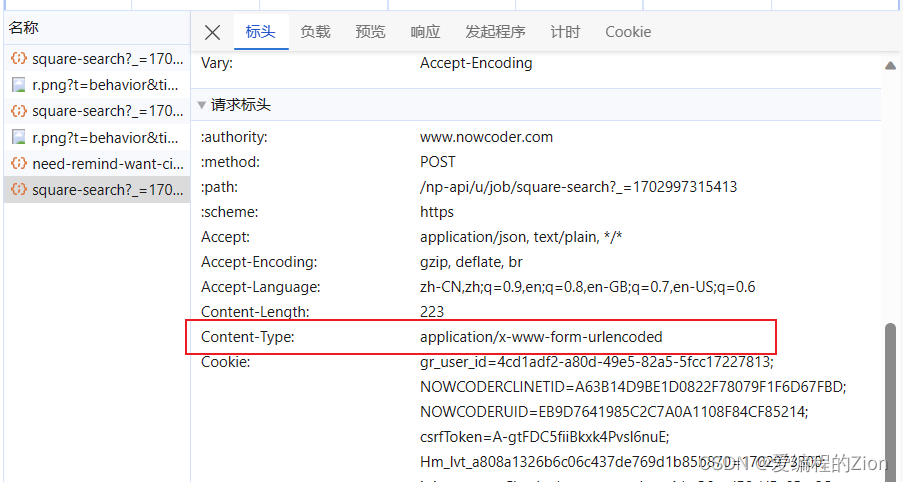
测试
首先可以先用apipost等测试工具先测试一下是否需要cookie之类的,发现是不需要的,通过urlencode编码的方式也能够请求到数据

于是开始写代码
coding
这里给出两种方式:
首先使用错误的编码格式肯定是拿不到数据的

①通过urllib
import requests
import time
import json
from urllib.parse import urlencode
import urllib.request
timestamp = time.time()
timestamp_milliseconds = int(timestamp*1000)
newcode_job_url = f"https://www.nowcoder.com/np-api/u/job/square-search?_={timestamp_milliseconds}"
form_data = {
"careerJobId": "",
"jobCity": "",
"page": 1,
"query": "开发",
"random": "true",
"recommend": "false",
"recruitType": 1,
"salaryType": 2,
"pageSize": 20,
"requestFrom": 1,
"order": 0,
"pageSource": 5001,
"visitorId": "4cd1adf2-a80d-49e5-82a5-5fcc17227813"
}
form_data["jobCity"] = "北京"
# 需要手动编码
form_data = urlencode(form_data).encode()
request = urllib.request.Request(newcode_job_url)
response = urllib.request.urlopen(request,form_data)
print(response.read().decode())②通过requests(建议)
通过requests简直不要太方便,因为requests会自动使用合适的编码格式进行编码
import requests
import time
import json
from urllib.parse import urlencode
import urllib.request
timestamp = time.time()
timestamp_milliseconds = int(timestamp*1000)
newcode_job_url = f"https://www.nowcoder.com/np-api/u/job/square-search?_={timestamp_milliseconds}"
form_data = {
"careerJobId": "",
"jobCity": "",
"page": 1,
"query": "开发",
"random": "true",
"recommend": "false",
"recruitType": 1,
"salaryType": 2,
"pageSize": 20,
"requestFrom": 1,
"order": 0,
"pageSource": 5001,
"visitorId": "4cd1adf2-a80d-49e5-82a5-5fcc17227813"
}
form_data["jobCity"] = "北京"
response = requests.post(newcode_job_url, data=form_data)
print(response.text)结果