前言
最近在实现yolov8的剪枝,所以有找相关的工作作为参考,用以完成该项工作。
- 先细读了 Torch-Pruning,个人简单记录了下 【剪枝】torch-pruning的基本使用,有框架完成的对网络所有结构都自适应剪枝是最佳的,但这里没有详细记录torch-pruning的yolov8的剪枝,是因为存在不解 对其yolov8具体的剪枝代码中操作:“比较疑惑 replace_c2f_with_c2f_v2(model.model) 这句注释掉了代码就跑不通了。是tp不支持原本 c2f 吗,我如果想使用c2f进行剪枝,应该怎么办呢”。待解决该问题,然后在记录。
- 然后另外参考博客 Jetson nano部署剪枝YOLOv8,该方法的代码实现仅针对yolov8 的剪枝,但可从中借鉴如何利用bn对模型进行剪枝,举一反三应用到其它工程中。bn剪枝的原理可以在 3.1 常用的结构化剪枝原理 简单记录。
1. 剪枝工程搭建
yolov8工程下载
本地有个版本 Ultralytics 8.0.81,所以该篇博客基于该版本记录。不同版本可能带来的影响,所以当使用最新版本出bug时,又无法定位和解决,可先尝试8.0.81版本。我们剪枝过程在VOC数据集上完成尝试。
这里添加两个代码文件
分别为【LL_pruning.py、LL_train.py】存放于根目录下
LL_train.py的内容为from ultralytics import YOLO import os # os.environ["CUDA_VISIBLE_DEVICES"]="0,1" root = os.getcwd() ## 配置文件路径 name_yaml = os.path.join(root, "ultralytics/datasets/VOC.yaml") name_pretrain = os.path.join(root, "yolov8s.pt") ## 原始训练路径 path_train = os.path.join(root, "runs/detect/VOC") name_train = os.path.join(path_train, "weights/last.pt") ## 约束训练路径、剪枝模型文件 path_constraint_train = os.path.join(root, "runs/detect/VOC_Constraint") name_prune_before = os.path.join(path_constraint_train, "weights/last.pt") name_prune_after = os.path.join(path_constraint_train, "weights/last_prune.pt") ## 微调路径 path_fineturn = os.path.join(root, "runs/detect/VOC_finetune") def else_api(): path_data = "" path_result = "" model = YOLO(name_pretrain) metrics = model.val() # evaluate model performance on the validation set model.export(format='onnx', opset=11, simplify=True, dynamic=False, imgsz=640) model.predict(path_data, device="0", save=True, show=False, save_txt=True, imgsz=[288,480], save_conf=True, name=path_result, iou=0.5) # 这里的imgsz为高宽 def step1_train(): model = YOLO(name_pretrain) model.train(data=name_yaml, device="0,1", imgsz=640, epochs=50, batch=32, workers=16, save_period=1, name=path_train) # train the model def step2_Constraint_train(): model = YOLO(name_train) model.train(data=name_yaml, device="0,1", imgsz=640, epochs=50, batch=32, workers=16, save_period=1,name=path_constraint_train) # train the model def step3_pruning(): from LL_pruning import do_pruning do_pruning(os.path.join(name_prune_before, name_prune_after)) def step4_finetune(): model = YOLO(name_prune_after) # load a pretrained model (recommended for training) model.train(data=name_yaml, device="0,1", imgsz=640, epochs=50, batch=32, workers=16, save_period=1, name=path_fineturn) # train the model step1_train() # step2_Constraint_train() # step3_pruning() # step4_finetune()LL_pruning.py的内容为from ultralytics import YOLO import torch from ultralytics.nn.modules import Bottleneck, Conv, C2f, SPPF, Detect import os # os.environ["CUDA_VISIBLE_DEVICES"] = "2" class PRUNE(): def __init__(self) -> None: self.threshold = None def get_threshold(self, model, factor=0.8): ws = [] bs = [] for name, m in model.named_modules(): if isinstance(m, torch.nn.BatchNorm2d): w = m.weight.abs().detach() b = m.bias.abs().detach() ws.append(w) bs.append(b) print(name, w.max().item(), w.min().item(), b.max().item(), b.min().item()) print() # keep ws = torch.cat(ws) self.threshold = torch.sort(ws, descending=True)[0][int(len(ws) * factor)] def prune_conv(self, conv1: Conv, conv2: Conv): ## a. 根据BN中的参数,获取需要保留的index================ gamma = conv1.bn.weight.data.detach() beta = conv1.bn.bias.data.detach() keep_idxs = [] local_threshold = self.threshold while len(keep_idxs) < 8: ## 若剩余卷积核<8, 则降低阈值重新筛选 keep_idxs = torch.where(gamma.abs() >= local_threshold)[0] local_threshold = local_threshold * 0.5 n = len(keep_idxs) # n = max(int(len(idxs) * 0.8), p) print(n / len(gamma) * 100) # scale = len(idxs) / n ## b. 利用index对BN进行剪枝============================ conv1.bn.weight.data = gamma[keep_idxs] conv1.bn.bias.data = beta[keep_idxs] conv1.bn.running_var.data = conv1.bn.running_var.data[keep_idxs] conv1.bn.running_mean.data = conv1.bn.running_mean.data[keep_idxs] conv1.bn.num_features = n conv1.conv.weight.data = conv1.conv.weight.data[keep_idxs] conv1.conv.out_channels = n ## c. 利用index对conv1进行剪枝========================= if conv1.conv.bias is not None: conv1.conv.bias.data = conv1.conv.bias.data[keep_idxs] ## d. 利用index对conv2进行剪枝========================= if not isinstance(conv2, list): conv2 = [conv2] for item in conv2: if item is None: continue if isinstance(item, Conv): conv = item.conv else: conv = item conv.in_channels = n conv.weight.data = conv.weight.data[:, keep_idxs] def prune(self, m1, m2): if isinstance(m1, C2f): # C2f as a top conv m1 = m1.cv2 if not isinstance(m2, list): # m2 is just one module m2 = [m2] for i, item in enumerate(m2): if isinstance(item, C2f) or isinstance(item, SPPF): m2[i] = item.cv1 self.prune_conv(m1, m2) def do_pruning(modelpath, savepath): pruning = PRUNE() ### 0. 加载模型 yolo = YOLO(modelpath) # build a new model from scratch pruning.get_threshold(yolo.model, 0.8) # 获取剪枝时bn参数的阈值,这里的0.8为剪枝率。 ### 1. 剪枝c2f 中的Bottleneck for name, m in yolo.model.named_modules(): if isinstance(m, Bottleneck): pruning.prune_conv(m.cv1, m.cv2) ### 2. 指定剪枝不同模块之间的卷积核 seq = yolo.model.model for i in [3,5,7,8]: pruning.prune(seq[i], seq[i+1]) ### 3. 对检测头进行剪枝 # 在P3层: seq[15]之后的网络节点与其相连的有 seq[16]、detect.cv2[0] (box分支)、detect.cv3[0] (class分支) # 在P4层: seq[18]之后的网络节点与其相连的有 seq[19]、detect.cv2[1] 、detect.cv3[1] # 在P5层: seq[21]之后的网络节点与其相连的有 detect.cv2[2] 、detect.cv3[2] detect:Detect = seq[-1] last_inputs = [seq[15], seq[18], seq[21]] colasts = [seq[16], seq[19], None] for last_input, colast, cv2, cv3 in zip(last_inputs, colasts, detect.cv2, detect.cv3): pruning.prune(last_input, [colast, cv2[0], cv3[0]]) pruning.prune(cv2[0], cv2[1]) pruning.prune(cv2[1], cv2[2]) pruning.prune(cv3[0], cv3[1]) pruning.prune(cv3[1], cv3[2]) # ***step4,一定要设置所有参数为需要训练。因为加载后的model他会给弄成false。导致报错 # pipeline: # 1. 为模型的BN增加L1约束,lambda用1e-2左右 # 2. 剪枝模型,比如用全局阈值 # 3. finetune,一定要注意,此时需要去掉L1约束。最终final的版本一定是去掉的 for name, p in yolo.model.named_parameters(): p.requires_grad = True # 1. 不能剪枝的layer,其实可以不用约束 # 2. 对于低于全局阈值的,可以删掉整个module # 3. keep channels,对于保留的channels,他应该能整除n才是最合适的,否则硬件加速比较差 # n怎么选,一般fp16时,n为8; int8时,n为16 # cp.async.cg.shared yolo.val() torch.save(yolo.ckpt, savepath) yolo.model.pt_path = yolo.model.pt_path.replace("last.pt", os.path.basename(savepath)) yolo.export(format="onnx") ## 重新load模型,修改保存命名,用以比较剪枝前后的onnx的大小 yolo = YOLO(modelpath) # build a new model from scratch yolo.export(format="onnx") if __name__ == "__main__": modelpath = "runs/detect1/14_Constraint/weights/last.pt" savepath = "runs/detect1/14_Constraint/weights/last_prune.pt" do_pruning(modelpath, savepath)


2 剪枝全流程
剪枝的流程可分为
- 正常训练:我们可以通过模型得到未剪枝时的精度,方便剪枝前后进行精度对比
- 稀疏训练:bn的参数约等于0的并不多,所以需要稀疏训练,使得部分参数接近0,然后再对卷积核进行裁剪,这样可以减小剪枝对网络输出的影响。
- 剪枝:根据bn中参数对相应的卷积进行剪枝。
- 微调:剪枝后模型必然会降低精度,所以需要再微调使其恢复精度。
2.1 正常训练
- 设置yaml文件:该工程使用VOC数据集,若已下载,在yaml文件中设置好数据路径。若无下来,运行训练代码时,工程会在一开始自动下载数据集,但下载速度可能会慢。
LL_train.py中设置:
ultralytics/datasets/VOC.yaml中如下::LL_train.py脚本中,调用step1_train(),注释其它的函数调用,如下图。
- 激活相应环境,进行训练。运行
python LL_train.py,训练结束指标如下:
2.2 稀疏训练
在
./ultralytics/yolo/engine/trainer.py代码中修改:
在[反向传播]和[梯度更新] 之间添加[bn的L1正则],使得bn参数在训练时变得稀疏。# Backward self.scaler.scale(self.loss).backward() ## add start============================= ## add l1 regulation for step2_Constraint_train l1_lambda = 1e-2 * (1 - 0.9 * epoch / self.epochs) for k, m in self.model.named_modules(): if isinstance(m, nn.BatchNorm2d): m.weight.grad.data.add_(l1_lambda * torch.sign(m.weight.data)) m.bias.grad.data.add_(1e-2 * torch.sign(m.bias.data)) ## add end ============================== # Optimize - https://pytorch.org/docs/master/notes/amp_examples.html if ni - last_opt_step >= self.accumulate: self.optimizer_step() last_opt_step = ni
LL_train.py中修改:
然后进行训练,结束后的验证指标如下图。
可以在以下截屏看到最顶行,此时模型共168层、参数量11133324、计算量28.5GFLOPs
2.3 模型剪枝
- 修改
LL_train.py并训练:
- 看下剪枝后的文件
终端输入命名如下,可查看文件大小。可以看到其中剪枝前后的pt的du -sh ./runs/detect/VOC_Constraint/weights/last*last.pt/last_prune.pt,对应的onnx模型为last.onnxlast_prune.onnx,可以看剪枝后的pt增大了,但onnx减小了,我们只需要关注onnx的大小即可,由43M 剪枝为36M。
2.4 微调
- 将第二步的约束训练添加的bn限制注释掉
- 加载剪枝后的模型作为训练时的网络结构。在
ultralytics/yolo/engine/trainer.py中修改内容:
370行的self.trainer.model是从yaml中加载的模型( 未剪枝前的) 以及其它的配置信息,从pt文件中加载的权重( 剪枝后的)。所以只需将该变量中的网络结构更新为剪枝后的网络结构即可,增加代码可解决问题。
否则训练出来的模型参数不会发生变化。self.trainer.model.model = self.model.model
- 在
ultralytics/yolo/engine/trainer.py中增加内容如下:
将model.22.dfl.conv.weight的梯度置为Fasle,是因为该层是解析box时的一个向量,具体的为 [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15],为了便捷的将该处理保存在模型中,所以就定义成一个卷积,卷积的权重为该向量。所以该卷积不需要梯度、不需要反向传播,所以该层的param.requires_grad = False。
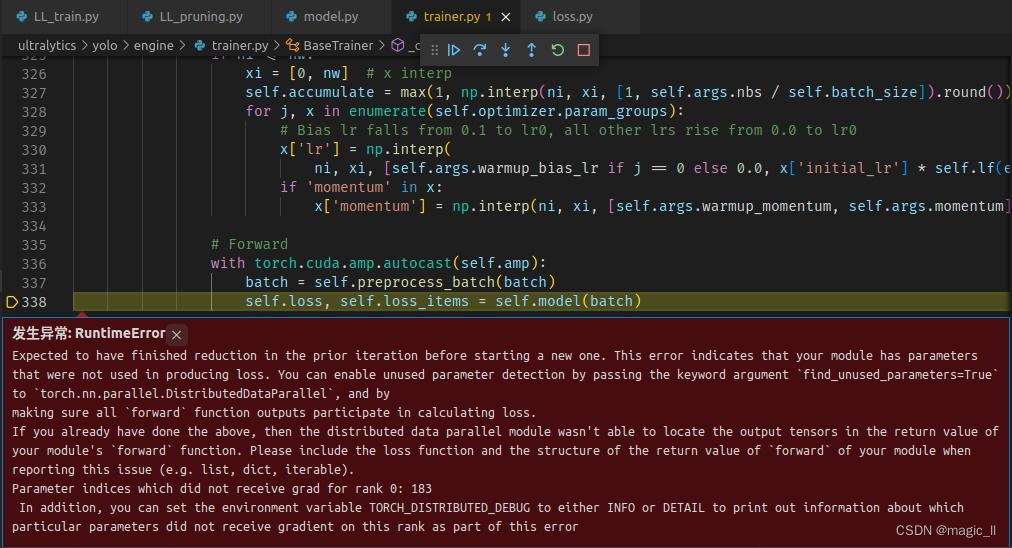
否则训练过程中会报错:debug时报错如下图
至此,就可微调训练。训练结果如下:
若不进行修改,依然会从modeld的yaml文件中加载模型。参数量和计算量不会有任何变化。下图是未做更多的修改训练后的信息。这样不是我们想要的状态。
2.5 剪枝完成后的分析
剪枝过程中的所有训练mAP、准召日志,使用tensorboard打开查看对应变化曲线:本次0.8的剪枝率下剪枝前后的指标变化并不大。在错误微调时指标整体偏低。
- 正常训练:参数量 11133324、计算量28.5GFLOPs、验证集上的准召:0.812、0.727
- 剪枝微调后:参数量9261550、计算量19.3GFLOPs、验证集上的准召:0.811、0.699
可以看出在0.8的剪枝率下,剪枝后的模型与原本模型的验证集上的准召相差不大。运行时间上,若在高性能GPU上不会有明显加速,在端侧会有加速。具体的数值,后面有空测试后附上。