前言
下半年以来,我全力推动我司大模型项目团队的组建,我虽兼管整个项目团队,但为了并行多个项目,最终分成了三个项目组,每个项目都有一个项目负责人,分别为霍哥、阿荀、朝阳
- 在今年Q4,我司第一项目组的第一个项目「AIGC模特生成平台」得到CSDN蒋总的大力支持,并亮相于CSDN举办的1024程序员节,一上来就吸引了很多市里领导、媒体、观众的关注,如今该平台的入口链接已在七月官网右上角
- 而第二项目组的论文审稿GPT,我和阿荀则一直全程推动整个流程的开发(第一版详见此文的第三部分、第二版详见:七月论文审稿GPT第2版:从Meta Nougat、GPT4审稿到Mistral、LongLora Llama)
到12月中旬,进入了模型训练阶段,选型的时候最开始关注的两个模型,一个Mistral 7B,一个Llama-LongLora,但考虑到前者的上下文长度是8K,面对一些论文时可能长度还是不够,于是我们便考虑让Mistral结合下YaRN
所以本文重点介绍下YaRN,顺带把位置编码外推ALiBi、线性插值等相关的方法一并总结下 - 至于第三项目组的知识库问答项目则也一直在并行推进,核心还是一系列各种细节问题的优化,而这个优化过程还是比较费时的
YaRN本质上是一种新的RoPE扩展方法(至于RoPE详见此文),可以比较高效的扩展大模型的上下文窗口,本文的写就基于YaRN论文:YaRN: Efficient Context Window Extension of Large Language Models,且为方便大家更好的理解本文,特地再列下本文重要的几个参考文献(当下文出现带中括号的[6]、[7]、[9]时,便特指的以下相关文献)
-
[6] bloc97. NTK-Aware Scaled RoPE allows LLaMA models to have extended (8k+) context size without any fine-tuning and minimal perplexity degradation., 2023.
URL https://www.reddit.com/r/LocalLLaMA/comments/14lz7j5/ntkaware_ scaled_rope_allows_llama_models_to_have/ -
[7] bloc97. Add NTK-Aware interpolation "by parts" correction, 2023. URL https://github.com/jquesnelle/scaled-rope/pull/1 .
-
[9] S. Chen, S. Wong, L. Chen, and Y. Tian. Extending context window of large language models via positional interpolation, 2023. arXiv: 2306.15595.
该研究团队来自Meta
有何问题 欢迎随时留言评论,thanks
第一部分 背景知识:从进制表示谈到直接外推、线性内插、ALiBi
1.1 从进制表示到直接外推
注,本节内容援引自苏剑林博客中的部分内容
1.1.1 进制表示
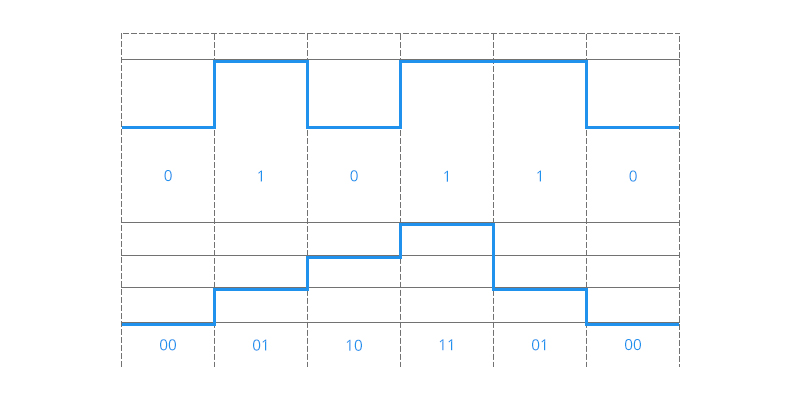
假设我们有一个1000以内(不包含1000)的整数要作为条件输入到模型中,那么要以哪种方式比较好呢?
- 最朴素的想法是直接作为一维浮点向量输入,然而0~999这涉及到近千的跨度,对基于梯度的优化器来说并不容易优化得动。那缩放到0~1之间呢?也不大好,因为此时相邻的差距从1变成了0.001,模型和优化器都不容易分辨相邻的数字
- 进一步,对于一个整数,比如759,这是一个10进制的三位数,每位数字是0~9。既然我们自己都是用10进制来表示数字的,为什么不直接将10进制表示直接输入模型呢?也就是说,我们将整数n以一个三维向量[a,b,c]来输入,a,b,c分别是n的百位、十位、个位
至于如果想要进一步缩小数字的跨度,我们还可以进一步缩小进制的基数,如使用8进制、6进制甚至2进制,代价是进一步增加输入的维度
1.1.2 直接外推
苏剑林说,假设我们还是用三维10进制表示训练了模型,模型效果还不错。然后突然来了个新需求,将n上限增加到2000以内,那么该如何处理呢?
如果还是用10进制表示的向量输入到模型,那么此时的输入就是一个四维向量了。然而,原本的模型是针对三维向量设计和训练的,所以新增一个维度后,模型就无法处理了。可能有读者想说,为什么不能提前预留好足够多的维度呢?
没错,是可以提前预留多几维,训练阶段设为0,推理阶段直接改为其他数字,这就是外推(Extrapolation)
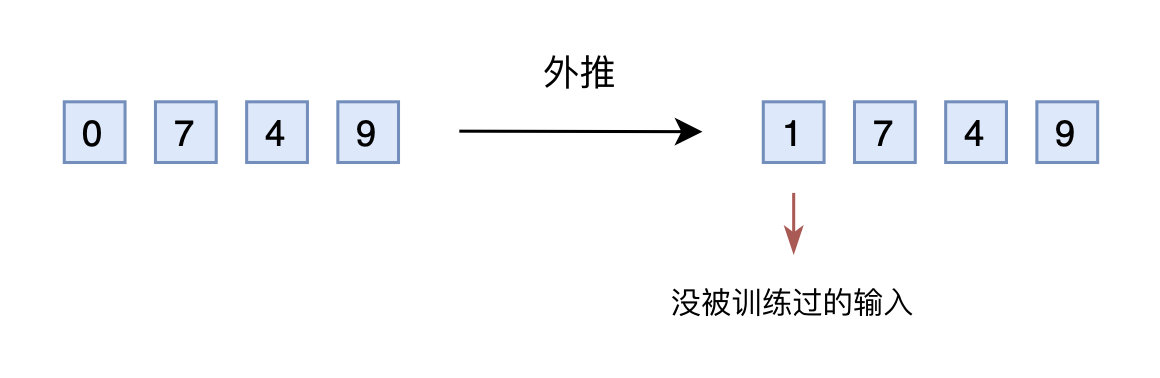
然而,训练阶段预留的维度一直是0,如果推理阶段改为其他数字,效果不见得会好,因为模型对没被训练过的情况不一定具有适应能力。也就是说,由于某些维度的训练数据不充分,所以直接进行外推通常会导致模型的性能严重下降。
1.1.3 线性内插
于是,有人想到了将外推改为内插(Interpolation),简单来说就是将2000以内压缩到1000以内
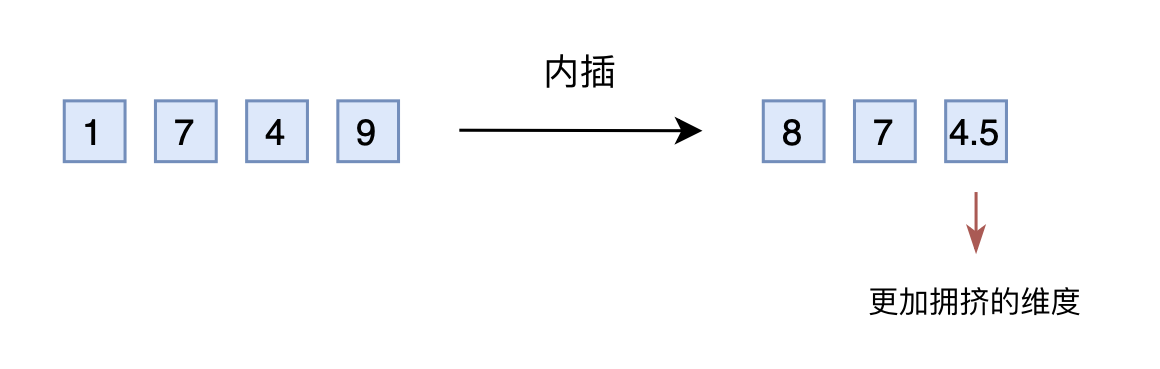
- 比如通过除以2,1749就变成了874.5,然后转为三维向量[8,7,4.5]输入到原来的模型中
从绝对数值来看,新的[7,4,9]实际上对应的是1498,是原本对应的2倍,映射方式不一致;
从相对数值来看,原本相邻数字的差距为1,现在是0.5,最后一个维度更加“拥挤” - 所以,做了内插修改后,通常都需要微调训练,以便模型重新适应拥挤的映射关系
当然,有读者会说外推方案也可以微调。是的,但内插方案微调所需要的步数要少得多
- 因为很多场景(比如位置编码)下,相对大小(或许说序信息)更加重要,换句话说模型只需要知道874.5比874大就行了,不需要知道它实际代表什么多大的数字。而原本模型已经学会了875比874大,加之模型本身有一定的泛化能力,所以再多学一个874.5比874大不会太难
- 不过,内插方案也不尽完美,当处理范围进一步增大时,相邻差异则更小,并且这个相邻差异变小集中在个位数,剩下的百位、十位,还是保留了相邻差异为1。换句话说,内插方法使得不同维度的分布情况不一样,每个维度变得不对等起来,模型进一步学习难度也更大
1.2 直接外推之ALiBi
简言之,是对Transformers进行长度外推,即在短上下文窗口上进行训练,并在较长的上下文窗口上进行推理
// 待更..
第二部分 上下文窗口扩展史:从RoPE到位置插值、NTK-aware Scaled RoPE
基于transformer的大型语言模型(llm)已经成为许多自然语言处理(NLP)任务的选择,其中远程能力(如上下文学习(ICL))至关重要。在执行NLP任务时,其上下文窗口的最大长度一直是预训练LLM的主要限制之一。能够通过少量的微调(或不进行微调)来动态扩展上下文窗口已经变得越来越受关注。为此,transformer的位置编码是核心焦点
- 最初的Transformer架构使用了绝对正弦位置编码,后来被改进为可学习的绝对位置编码[Convolutional sequence to sequence learning]。此后,相对位置编码方案[Self-attention with relative position representations]进一步提升了transformer的性能。目前,最流行的相对位置编码是T5 relative Bias[Exploring the limits of transfer learning with a unified text-to-text transformer]、RoPE[34]、XPos[35]和ALiBi[Attention with linear biases enables input length extrapolation]
- 位置编码的一个反复出现的限制是无法对「训练期间看到的上下文窗口之外的情况」进行泛化
One reoccurring limitation with positional encodings is the inability to generalize past the context window seen during training
虽然ALiBi等一些方法能够进行有限的泛化,但没有一种方法能够泛化到明显长于预训练长度的序列 - 好在已经有一些工作正在尝试克服这种限制。比如位置插值(Position Interpolation, PI)[Extending context window of large language models
via positional interpolation]通过对RoPE进行轻微修改,并对少量数据进行微调,从而扩展上下文长度 - 作为一种替代方案,Reddit一网友bloc97通过该帖子,提出了“NTK-aware”插值方法[NTK-Aware Scaled RoPE allows LLaMA models to have extended(8k+) context size without any fine-tuning and minimal perplexity degradation],该方法考虑到高频信号的损失
此后,对“NTK感知”插值提出了两项改进
- 无需微调的预训练模型的“动态NTK”插值方法[14]
- 在对少量较长的上下文数据进行微调时表现最佳的“NTK-by-parts”插值方法[7]
“NTK感知”插值和“动态NTK”插值已经在开源模型中出现,如Code Llama[31](使用“NTK感知”插值)和Qwen 7B[2](使用“动态NTK”)。
在本文中,除了对先前未发表的关于“NTK感知”、“动态NTK”和“NTK-by-parts”插值的技术进行完整的描述外,我还将介绍YaRN(另一种RoPE扩展方法),这是一种改进的方法,可以有效地扩展使用旋转位置嵌入(RoPE)训练的模型的上下文窗口,包括LLaMA[38]、GPT-NeoX[5]和PaLM[10]家族的模型
在对不到0.1%的原始预训练数据进行微调后,YaRN在上下文窗口扩展中达到了最先进的性能。同时,通过与称为动态缩放的推理时间技术相结合,Dynamic- yarn允许超过2倍的上下文窗口扩展,而无需任何微调
2.1 旋转位置嵌入
YaRN的基础是[RoFormer: Enhanced transformer with rotary position embedding]中介绍的旋转位置嵌入(RoPE)
考虑到本博客内已有另一篇文章详细阐述了位置编码与RoPE,所以如果你对本节有任何疑问,可进一步参考此文《一文通透位置编码:从标准位置编码、欧拉公式到旋转位置编码RoPE》
所以下面只参照YaRN论文做个最简单的回顾
- 首先,我们在一个隐藏层上工作,隐藏神经元的集合用
表示。给定向量序列
,遵循RoPE的表示法,注意力层首先将向量转换为查询向量和关键向量:
- 接下来,注意力权重被计算为
其中、
被认为是列向量,因此
就是简单的欧氏内积。在RoPE中,我们首先假设
是偶数,并将嵌入空间和隐藏状态识别为complex vector spaces
其中内积转化为
的实部「where the inner product q T k becomes the real part of the standard Hermitian inner product Re(q ∗k),如对该点有疑问的,请参见此文的3.2.1节」,更具体地说,同构将实数部分和复数部分交织在一起(the isomorphisms interleave the real part and the complex part)
- 为了将嵌入
、
转换为查询向量和键向量,我们首先给出了R-linear算子
在复坐标中,函数,
由
这样做的好处是,查询向量和关键向量之间的点积只取决于如下所示的相对距离
在实坐标中,RoPE可以用下面的函数来表示
如此,便有
2.2 位置插值:基于Positional Interpolation扩大模型的上下文窗口
由于语言模型通常是用固定的上下文长度进行预训练的,自然会问如何通过在相对较少的数据量上进行微调来扩展上下文长度
对于使用RoPE作为位置嵌入的语言模型,Chen等人[9]和kaiokendev[21]同时提出了位置插值(position Interpolation, PI),将上下文长度扩展到预训练极限之外
对于后者,(Super-HOT kaiokendev(2023)),它也在RoPE中插入了位置编码,将上下文窗口从2K扩展到8K
对于前者,按照该篇论文《Extending context window of large language models via positional interpolation》,可知
- 关键思想是,我们不是进行外推,而是直接将位置索引缩小,使最大位置索引与预训练阶段的先前上下文窗口限制相匹配
we directly down-scale the position indices so that the maximum position index matches the previous context window limit in the pre-training stage - 如下图所示,为了容纳更多的输入标记,我们在相邻的整数位置上对位置编码进行插值,利用位置编码可以应用于非整数位置的事实(而非对训练外的位置进行外推,因为那样可能导致灾难性的数值)
we interpolate the position encodings at neighboring integer positions,utilizing the fact that position encodings can be applied on non-integer positions, as opposed toextrapolating outside the trained positions, which may lead to catastrophic values.

虽然直接外推在大于预训练极限的序列
上的表现并不好,但他们发现,在预训练极限内插入位置指标,并进行少量微调可以显著提高效果
While a direct extrapolation does not perform well on sequences w1, · · · , wL with L larger than the pre-trained limit, they discovered that interpolating the position indicies with in the pre-trained limit works well with the help of a small amount of fine-tuning
- 具体来说,给定一个带有RoPE的预训练语言模型,他们通过
其中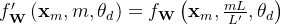
是超出预训练限制的新上下文窗口。通过原始的预训练模型加上修改的RoPE公式,他们在几个数量级更少的token上进一步微调了语言模型,并成功实现了上下文窗口扩展
- 考虑到扩展的上下文长度与原始上下文长度之间的比例一直特别重要,我们以此定义
有了这个定义,我们便可以将公式
重写并简化为以下一般形式(其中
,
):
最终,通过位置插值方法,将预训练的7B、13B、33B和65B LLaMA模型(Touvron等人,2023)扩展到大小为32768的各种上下文窗口,除了重新缩放使用位置插值扩展的模型的位置索引外,我们没有以任何方式修改LLaMA模型架构
2.3 从“NTK-aware”插值到“NTK-by-parts”插值、"Dynamic NTK"插值
2.3.1 “NTK-aware”插值
为了解决RoPE嵌入插值时丢失高频信息(losing high frequency information when interpolating the RoPE embeddings)的问题,Reddit一网友通过[NTK-Aware Scaled RoPE allows LLaMA models to have extended (8k+) context size without any fine-tuning and minimal perplexity degradation]开发了“NTK-aware”插值
- 我们不是将RoPE的每个维度平均缩放一个因子
- 虽然人们可以通过许多方法获得这样的变换,但最简单的方法是对θ的值进行基础更改(One can obtain such a transformation in many ways, but the simplest would be to perform a base change on the value of θ)
“NTK-aware”的内插方案如下
“NTK-aware”插值是对RoPE的修改,使用
和以下函数
且
与PI[Extending context window of large language models via positional interpolation]相比,该方法在扩展非微调模型的上下文大小方面表现得更好。然而,这种方法的一个主要缺点是,由于它不仅仅是一种插值方案,一些维度被轻微外推到“超出边界”的值,因此使用“NTK-aware”插值[6]进行微调的结果不如PI[9]。此外,由于存在“越界”值,理论尺度因子并不能准确描述真实的上下文扩展尺度。在实践中,对于给定的上下文长度扩展,尺度值s必须设置得高于预期尺度
我们注意到,在本文发布前不久,Code Llama[31]发布了,并通过手动将基数b扩展到1M来使用“NTK-aware”扩展。
2.3.2 相对局部距离的损失-“NTK-by-parts”插值
在像PI和“NTK-aware”插值这样的盲插值方法中,我们平等地对待所有RoPE隐藏维度(因为它们对网络有相同的影响)。然而,有强有力的线索指向我们需要有针对性的插值方法。
在本节中,我们将着重考虑RoPE中定义的波长。为简单起见,我们省略了
中的下标d,并将λ视为任意周期函数的波长
我们定义λd为RoPE嵌入在第d隐维处的波长:
波长描述了在维d上嵌入的RoPE执行完整旋转(2π)所需的标记长度
假设一些插值方法(例如。(PI)不关心波长的维数,我们将这些方法称为“盲”插值方法,而其他方法(如YaRN),我们将其归类为“有针对性的”插值方法。
关于RoPE嵌入的一个有趣的观察是,给定上下文大小L,有一些维度d的波长长于预训练期间看到的最大上下文长度(λ > L),这表明一些维度的嵌入可能在旋转域中不均匀分布。在这种情况下,我们假设拥有所有唯一的位置对意味着绝对的位置信息保持完整。相反,当波长较短时,只有相对位置信息可以被网络访问。
此外,当我们将RoPE的所有维度以的比例或使用
的基数进行拉伸时,所有标记都变得更接近彼此,因为两个向量的点积旋转较小的量更大。这种缩放严重损害了LLM理解其内部嵌入之间的小型和局部关系的能力。我们假设,这种压缩导致模型在邻近标记的位置顺序上被混淆,从而损害模型的能力
2.3.2 "Dynamic NTK"插值
// 待更
第三部分 YaRN全面解析
// 待更
参考文献与推荐阅读
- 了解几种外推方案做了什么
https://zhuanlan.zhihu.com/p/647145964
https://zhuanlan.zhihu.com/p/642398400 - 苏剑林文章
https://kexue.fm/archives/9675