代码:
from bs4 import BeautifulSoup
import requests
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:94.0) Gecko/20100101 Firefox/94.0',
}
id='371' #课程id
html=requests.get('https://coding.imooc.com/class/chapter/'+id+'.html#Anchor',headers=headers).text
print(html)
soup=BeautifulSoup(html,'lxml')
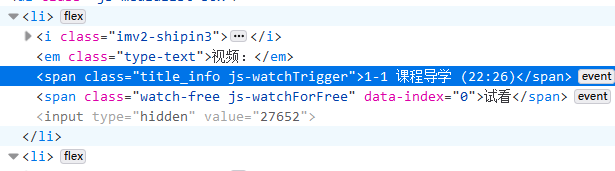
name=soup.find_all("span", "title_info")
for i in name:
print(i.text)
效果:

代码分析:
from bs4 import BeautifulSoup
import requests
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:94.0) Gecko/20100101 Firefox/94.0',
}
引入库
设置请求头
id='371' #课程id
html=requests.get('https://coding.imooc.com/class/chapter/'+id+'.html#Anchor',headers=headers).text
print(html)
soup=BeautifulSoup(html,'lxml')
获取网页 使用BeautifulSoup解析
name=soup.find_all("span", "title_info")
for i in name:
print(i.text)
获取全部 class为title_info的span标签
循环输出标签的text