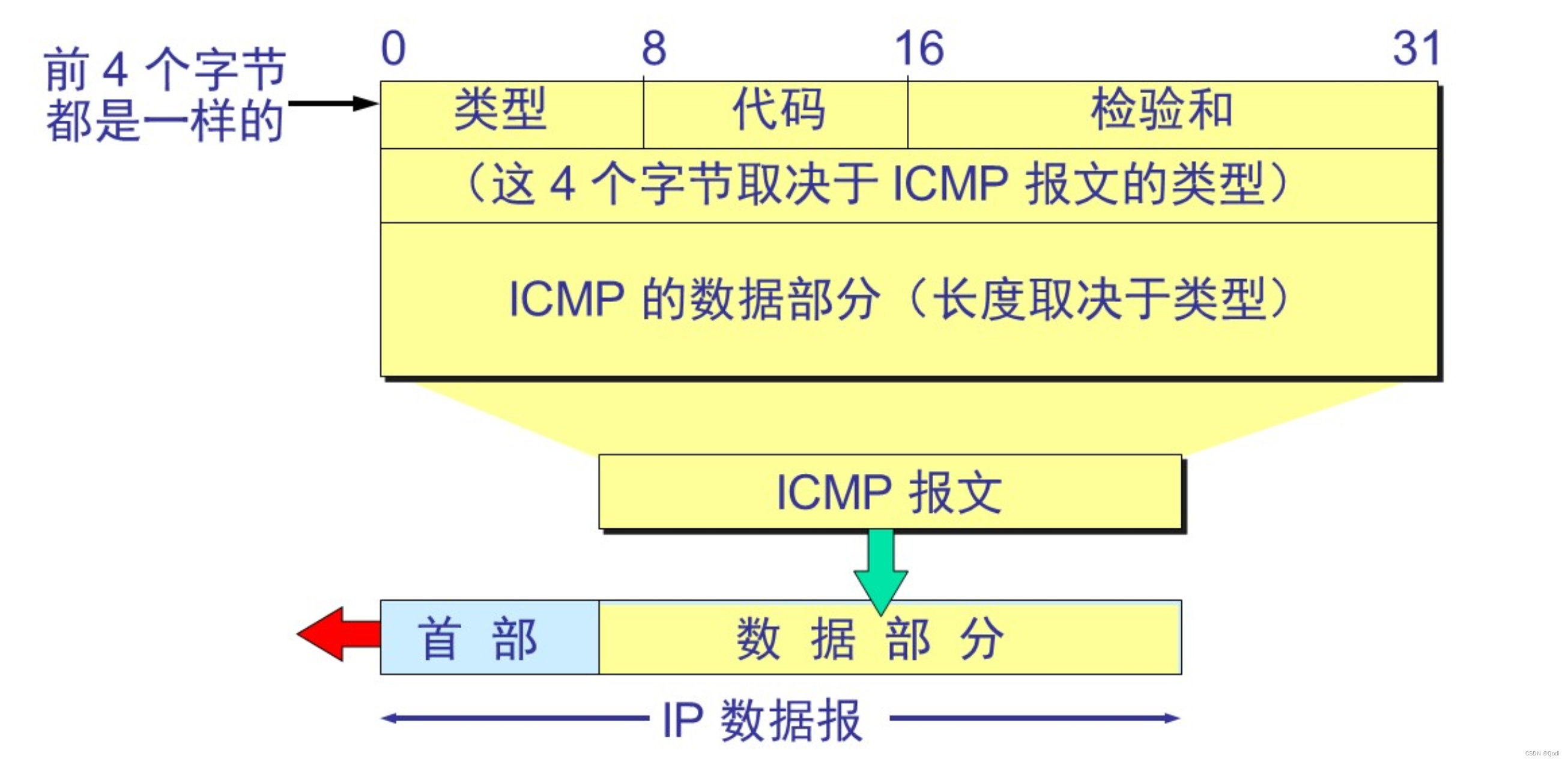
文章目录
- DISC-MedLLM 项目介绍
- 数据集构建
- 重构AI医患对话
- 知识图谱生成问答对
- 医学图谱构建
- 图谱生成QA对
- 人类偏好引导的对话样例
- 其他数据
- MedMCQA
- 通用数据
- 模型微调
- 评估
- 评估方式
- 评估结果
- 总结
DISC-MedLLM 项目介绍
DISC-MedLLM 是一个专门针对医疗健康对话式场景而设计的医疗领域大模型,它可以满足您的各种医疗保健需求,包括疾病问诊和治疗方案咨询等,为您提供高质量的健康支持服务。项目由复旦大学数据智能与社会计算实验室 (Fudan-DISC)开发并开源。
论文:DISC-MedLLM: Bridging General Large Language Models and Real-World Medical Consultation
主页地址:https://med.fudan-disc.com/来试用模型。
效果展示

-
用户在感到身体不适时,可以向模型问诊,描述自身症状,模型会给出可能的病因、推荐的治疗方案等作为参考,在信息缺乏时会主动追问症状的详细描述。
比如:出现腹泻和发烧的症状。可能得了什么病? -
用户还可以基于自身健康状况,向模型提出需求明确的咨询问题,模型会给予详尽有助的答复,并在信息缺乏时主动追问,以增强回复的针对性和准确性。
比如:最近睡眠质量差,有什么改善睡眠的方法? -
用户还可以询问与自身无关的医学知识,此时模型会尽可能专业地作答,使用户全面准确地理解。
比如:抗生素一般是用来治疗感冒还是病毒?
Github 地址:https://github.com/FudanDISC/DISC-MedLLM
该项目包含下列开源资源:
- DISC-Med-SFT 数据集 (不包括行为偏好训练数据)
- DISC-MedLLM 的模型权重
其中 DISC-Med-SFT 数据集包含了约47W的高质量指令数据,数据形式为多轮对话,数据样例如下:
[ { “role”: “user”, “content”:
“颈椎病。主任你好!这两天双肩膀不疼了。现在就是头发胀。我不知道是不是我头动多了引起的。” },
{ “role”:“assistant”, “content”:
“您好,非常高兴听到您的肩膀不再疼痛了。根据您的描述,头发胀可能与颈椎问题有关。颈椎病常常会引起头痛和不适感。建议您进行颈椎治疗,以缓解症状。”},
{ “role”: “user”, “content”:
“你好医生!请问手术后睡觉头要不要垫枕头睡觉,不用枕头睡觉可以吗?” },
{ “role”: “assistant”, “content”:
“手术后的睡眠姿势对颈椎康复很重要。如果您仰卧睡觉,可以不使用枕头,因为这样有助于保持颈椎的正常位置。但如果您侧卧睡觉,建议使用高枕头,以保持肩膀的高度与颈椎的正位。最好是左右各放一枕头,高度与您的肩宽相当,这样可以更好地支撑颈椎。”},
{ “role”: “user”, “content”:
“谢谢。” },
{ “role”: “assistant”,“content”: "
不客气。如果您需要进一步的咨询或治疗,可以咨询南京市中西医结合医院疼痛科的周建斌主任。他会给您提供专业的帮助。" }
]
DISC-MedLLM 有效地对齐了医疗场景下的人类偏好,弥合了通用语言模型输出与真实世界医疗对话之间的差距,这一点在实验结果中有所体现。
得益于以目标为导向的策略,以及基于真实医患对话数据和知识图谱,引入LLM in the loop 和 Human in the loop的多元数据构造机制。
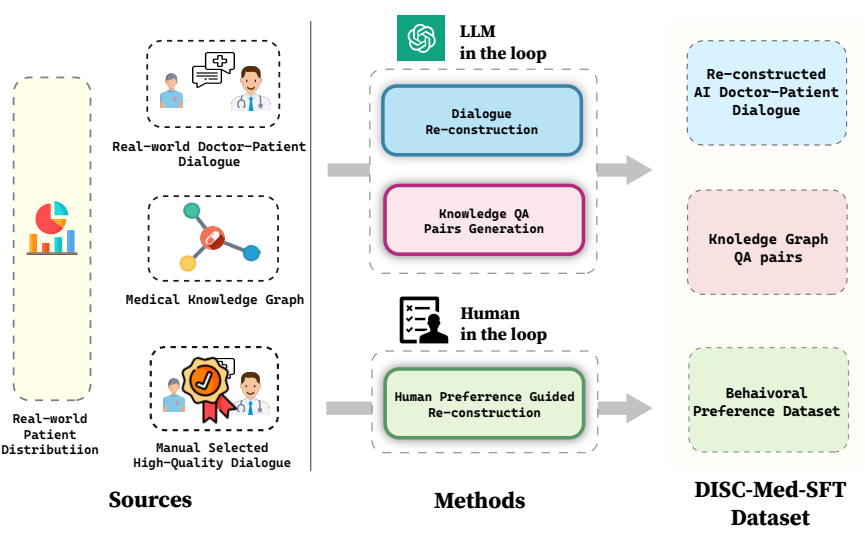
DISC-MedLLM具有的三个显著特点:
1. 可靠丰富的专业知识:将医学知识图谱作为信息源,利用采样三元组的方法,结合通用大模型的语言能力,构建对话样本。这一独特的构建方式赋予了DISC-MedLLM丰富的专业知识,使其能够在医疗对话中提供可靠且充实的信息,满足用户的需求。
2. 多轮对话的问询能力:为了确保DISC-MedLLM能够胜任复杂的多轮医疗对话,以真实咨询对话记录作为信息源,利用大模型进行对话重建。在构建过程中,追求模型对话的完全对齐,特别注重对医学信息的准确呈现。这一特性使DISC-MedLLM成为一个多轮对话的专家,能够深入理解和回应患者的各种疑虑和问题。
3. 对齐人类偏好的回复:在医疗咨询过程中,患者常常期望获得更多的支撑信息和背景知识,然而,人类医生的回答通常较为简洁。为了满足患者的需求,采取了一项创新的举措,通过人工筛选,构建了符合人类偏好的高质量小规模行为微调样本。这使得DISC-MedLLM的回复能够更好地对齐患者的期望,为他们提供更丰富和满意的支持。
总之,DISC-MedLLM以其可靠的专业知识、多轮对话的问询能力和对齐人类偏好的回复而脱颖而出。算是大语言模型在医疗领域的一项创新,为在线问诊和医患交流场景提供了可行的智能化解决方案。
数据集构建
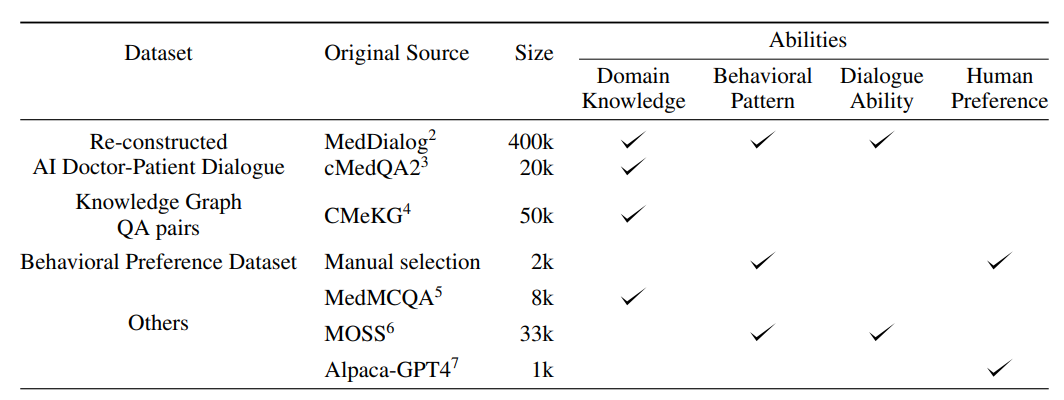
为了训练DISC-MedLLM,项目构建了一个名为DISC-Med-SFT的高质量数据集,包含超过470k个例子,来源于现有的医学数据集。这个综合的数据集包括各种场景,包括单轮医学问答,多轮医学咨询和医学多选题。此外,还加入了超过34k个通用域对话和指令样本。有关所使用的数据集的详细信息如下:
重构AI医患对话
项目选择两个公共数据集作为真实世界对话记录的来源,分别是MedDialog和cMedQA2。MedDialog包含超过300万个医生和患者之间的多轮对话,话题集中在医疗咨询场景上。cMedQA2包含10.8万个单轮对话,包括咨询和指导情况。通过使用关键字过滤和命名实体识别过滤记录后,分别从每个数据集中随机选择40万和2万个样本作为SFT数据集构建的源样本。
真实世界的对话在语言模式和表达风格上具有噪声,而且医生的回答可能不与AI医生的身份一致。为了获得高质量的对话样本,论文中利用通用LLM的语言能力重建整个对话。为GPT-3.5设计的提示,遵循以下几条规则:
• 删除口语表达,解决医生语言使用的不一致性,并从LLM中提炼出更加统一的表达方式。
• 遵循原始医生回答的关键信息,并根据此提供适当的解释和补充,以更详细和逻辑的方式重新表述原始答案。
• 重写或删除AI医生不应作出的回答,例如查看影像材料或要求患者预约挂号等。

下图是一个对话重建的示例。红色文本表示来源于现实世界的知识或行为模式对话记录,而蓝色文本表示重建过程中引入的内容。

知识图谱生成问答对
医学图谱构建
医学知识图谱生成使用了CMeKG项目,它是利用自然语言处理与文本挖掘技术,基于大规模医学文本数据,以人机结合的方式研发的中文医学知识图谱。包含关系抽取、医学实体识别、医学文本分词。
图谱生成QA对
医学知识图谱包含大量组织良好的医学专业知识。基于它生成问答训练样本可以获得比真实世界样本相对较低噪声的数据。项目基于一个包含超过1万种疾病、近2万种药物和超过1万种症状的中文医学知识图谱构建了QA对。以疾病为中心,根据疾病节点的科室信息对知识图进行采样,遵循原始MedDialog数据中的科室分布。通过两步来获得QA对。
步骤1:利用GPT-3.5的强大能力,首先将所选的知识转化为简单的自然语言QA对。关于疾病的信息知识提供给GPT-3.5,并转换为以“指示,知识”格式表示的自然语言。

步骤2:基于这些简单的QA对,GPT-3.5将它们转化为医学场景下的单轮对话,提高了它们的多样性和语言表达的丰富性

人类偏好引导的对话样例
为了进一步提高模型的性能并更紧密地将其响应和行为与人类偏好对齐,需要利用更高质量的数据集,在最终训练阶段的二次监督微调中更紧密地与人类偏好对齐。项目作者从MedDialog和cMedQA2数据集中手动选择大约2,000个高质量、多样化的样本,这些样本在之前的数据构建过程中没有使用。
根据样本的咨询场景、疾病严重程度和其他变量,作者选择几个例子由GPT-4重建,然后手动修改它们以更紧密地与人类对AI医生行为和响应质量的偏好对齐。随后,采用few-shot方法,将这些例子提供给GPT-3.5,在人类监督下生成2,000个高质量的行为调整样本。
其他数据
MedMCQA
是一个英文医学领域的多选题Q&A数据集,并为每个问题提供了专家注释的解释。作者利用它来生成专业的医学QA样本,以增强模型在Q&A能力方面的专业知识。使用GPT-3.5对多选题中的问题和答案进行精炼和纠正,并结合解释生成QA格式样本,然后将其翻译成中文。通过这种方法,构建了大约8k个样本,其中大约2k个样本保留了多选题格式,并直接翻译成中文。
通用数据
项目使用了通用的数据来丰富模型的训练集,减轻了模型在SFT训练阶段基础能力下降的风险。具体而言,借鉴了两个通用领域监督微调数据集:moss-sft-003和alpaca gpt4数据。从moss-sft-003中,提取了来自头脑风暴、角色扮演和无害类别的数据,随机选择了33k个样本。对于alpaca gpt4数据,考虑到它仅在训练的最后阶段使用,样本量已减少,随机采样了1k个实例。
模型微调
DISC-MedLLM 的训练过程分为两个 SFT 阶段。
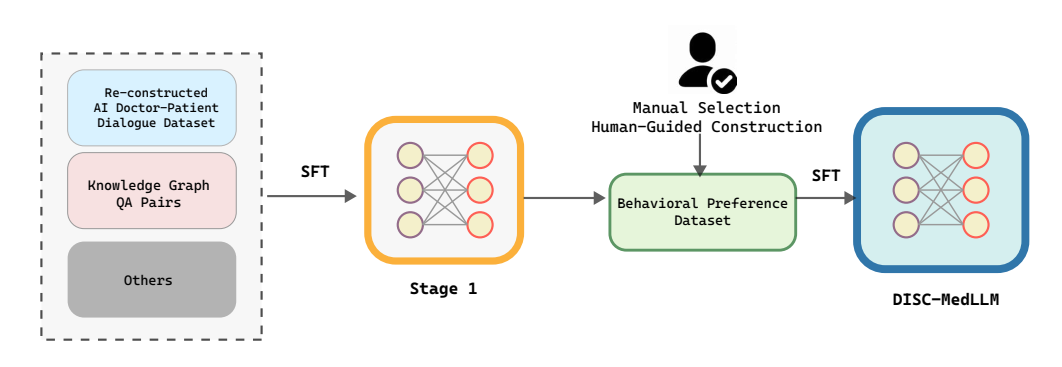
第一阶段:使用大量样本来灌输模型医学知识和对话能力,包括42万调整后的AI医生-患者对话数据集、5万构建的知识图谱QA对、MedMCQA和moss-sft-003数据。此训练过程的超参数设置如下:全局批大小为24,使用AdamW优化器的学习率为1e-5,1个epoch,最大序列长度为2048 tokens, warm up步骤为1800,不使用权重衰减。
• 第二阶段:在此阶段,训练模型以在行为模式、有用性等方面与人类偏好对齐,使它在医学对话场景中表现更好。采用2k精心制作的偏好对齐行为偏好数据集,并将其与1k alpaca gpt4数据数据结合进行训练。此训练过程的超参数设置如下:全局批大小为8,使用AdamW优化器的学习率为5e-6,1个epoch,最大序列长度为2048 tokens,不使用权重衰减。
DISC-MedLLM 是基于Baichuan-13B-Base训练得到的,两个阶段的训练都是在4块A800的GPU上完成的。
评估
评估方式
评测包含单轮和多轮评测
单轮对话评测:
使用公开数据集MLEC-QA和NEEP的多项选择题来评估不同系统,并使用准确度作为度量标准,评测模型在单轮 QA 中的表现。。其中,NMLEC为国家医疗执业医师资格考试,NEEP 306为全国硕士研究生入学考试 西医 306 专业。
多轮对话评测:为了系统性评估模型的对话能力,从三个公共数据集 —— 中文医疗基准评测(CMB-Clin)、中文医疗对话数据集(CMD)和中文医疗意图数据集(CMID)中随机选择样本并由 GPT-3.5 扮演患者与模型对话,提出了四个评测指标 —— 主动性、准确性、有用性和语言质量,由 GPT-4 打分。
- 主动性:当信息不足时,医生能够主动且明确地请求患者提供更多信息。
- 准确性:医生提供的诊断或建议准确无误,没有事实错误。结论不是随意得出的。
- 帮助性:医生能够为患者提供清晰、指导性和实用的帮助,以解决患者的疑虑。
- 语言质量:医生正确理解了患者的查询,回应的表达流畅自然。
评估结果
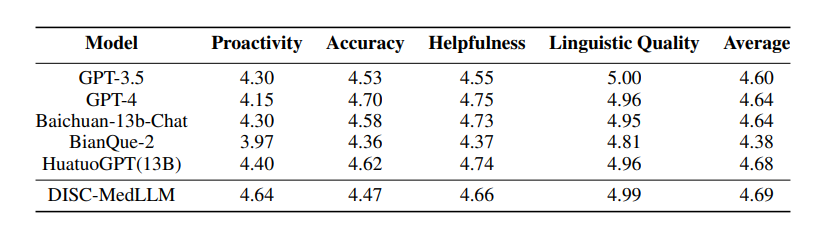
模型对比。将DISC-MedLLM与三个通用 LLM 和两个中文医学对话 LLM 进行比较。包括 OpenAI 的 GPT-3.5, GPT-4, Baichuan-13B-Chat; BianQue-2 和 HuatuoGPT-13B。
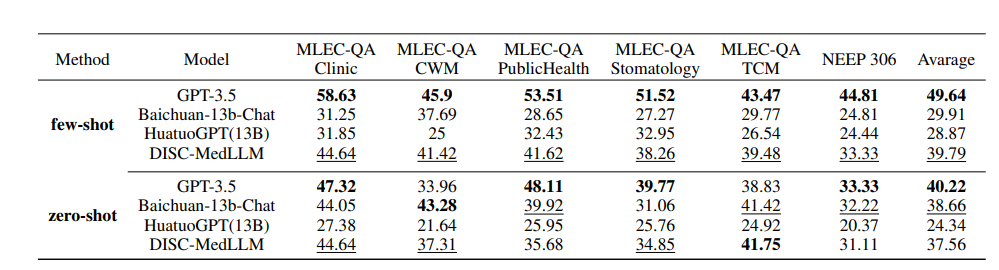
单轮 QA 结果。多项选择题评测的总体结果在下表中。GPT-3.5 展现出明显的领先优势。DISC-MedLLM 在小样本设置下取得第二名,在零样本设置中落后于 Baichuan-13B-Chat,排名第三。其表现还优于采用强化学习设置训练的 HuatuoGPT (13B)。
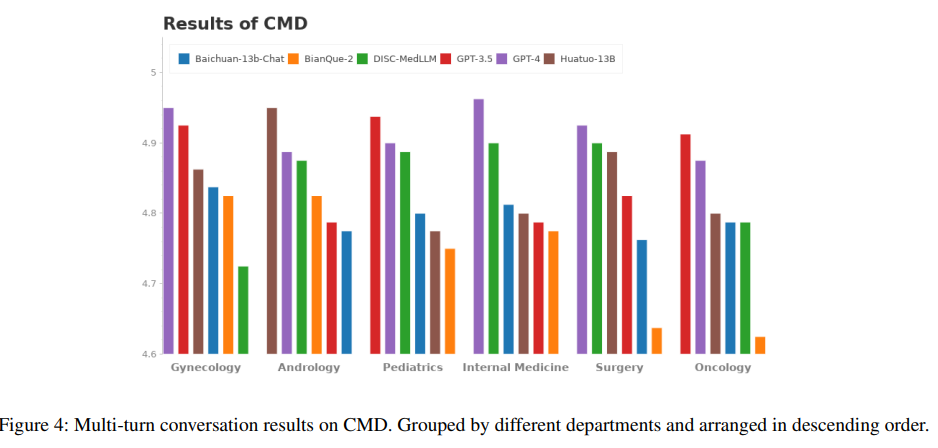
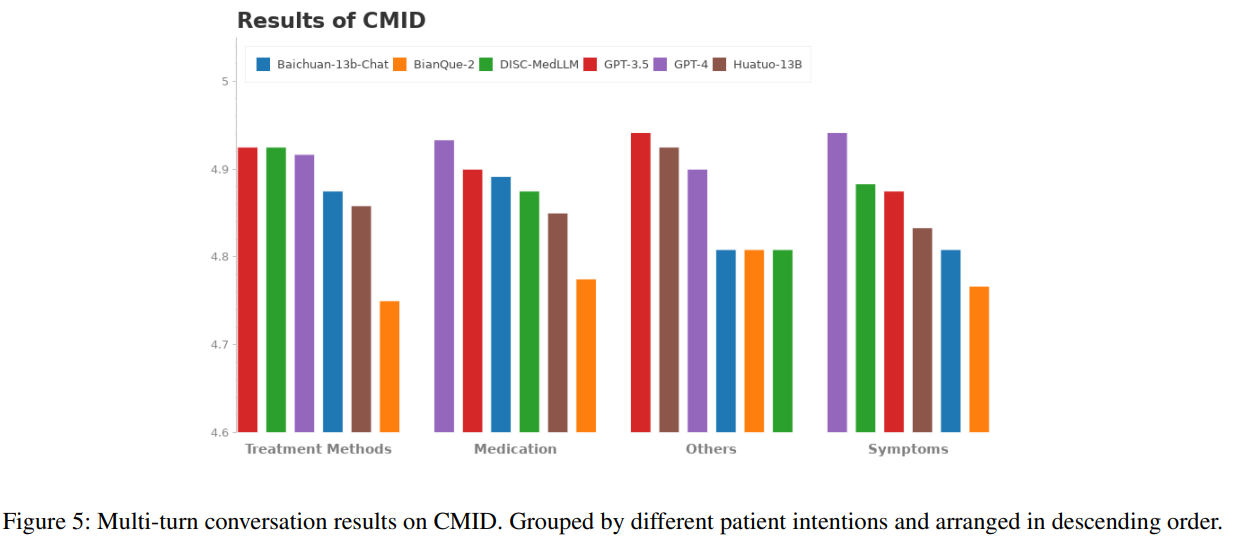
多轮对话结果。DISC-MedLLM在CMB-Clin评估中获得了总分最高的分数,并且在积极性标准方面获得了最高分,这强调了DISC-MedLLM对医学模型行为模式的定制方法的有效性。在CMD和CMID样本中,GPT-4和GPT-3.5保持领先地位,但DISC-MedLLM的表现最好,在症状、治疗计划和药物三个意图类别中优于HuatuoGPT。各种模型在CMB-Clin和CMD/CMID之间的表现不一致可能主要是由三个数据集中不同的数据分布导致的。
总结
DISC-Med-SFT 数据集利用现实世界对话和通用领域 LLM 的优势和能力,对三个方面进行了针对性强化:领域知识、医学对话技能和与人类偏好;高质量的数据集训练了出色的医疗大模型 DISC-MedLLM,在医学交互方面取得了显著的改进,表现出很高的可用性,显示出巨大的应用潜力。
该领域的研究将为降低在线医疗成本、推广医疗资源以及实现平衡带来更多前景和可能性。DISC-MedLLM 将为更多人带来便捷而个性化的医疗服务,为大健康事业发挥力量。
尽管生成模型在医学交互的可用性方面取得了显著的改进,包括语言流畅性、语义理解和推荐的相关性等方面,但准确性仍然是一个令人担忧的问题。特别是在医学领域,传播错误或欺骗性的信息比在其他领域具有更严重的伦理和实际影响。目前,存在明显的差距,缺乏能够加强LLM在医学语境下的精度的稳健方法。使用检索引擎来增强LLM的响应是潜在的途径,但需要克服重大的障碍,如建立全面的文档库和确保检索器和查询语义之间的对齐。提高LLM在医疗保健领域的准确性是一个紧迫的挑战,需要更深入的调查和探索。