DDD领域驱动设计批评文集
做强化自测题获得“软件方法建模师”称号
《软件方法》各章合集
第8章 分析 之 分析类图——知识篇
墙上挂了根长藤,长藤上面挂铜铃
《长藤挂铜铃》;词:元庸,曲:梅翁(姚敏),唱:逸敏,1959
您在阅读《软件方法》时如果发现错误,欢迎通过微信umlchina2告知。如果作者认为有道理,决定在下一次发布时根据您的意见修改,每个错误将付给您5.12元报酬,并在书中说明您的贡献。
(1)任何您认为的错误都可以,包括错别字。
(2)同一错误仅支付最先指正者报酬。
(3)请根据最新版本作指正。
下册内容目前指正人有(按指正时间排序):吴佰钊、王周文、刘学斌、成文华、黄树成、李蜀斌、杨雪鸿、王书伟、高洪江、张志坚、龙燔、陈文飞、郭沼兵、陈自平、张彬、李宏伟、赵志军、孙赛刚、孙军。
从分析工作流开始,我们每个内容都分为两章。一章讲述建模知识,一章讲述建模知识如何应用在本书案例中。这样的分割主要考虑到更符合实际的工作。
例如,在讲解分析类图时,我们讲解知识的顺序是这样的:
(1)识别类和属性
(2)审查类和属性
(3)识别类之间的泛化
(4)识别类之间的关联
如果把案例剖析分解到每个知识点,为了让案例的剖析符合内容的顺序,可能就会出现这样的情况:
讲解完识别类和属性后,案例剖析时,先列出很多类和属性,但没有泛化和关联关系,因为类的关系还没有讲到,所以即使观察到,也故意不画上去;接下来,讲解完类之间的关系后,案例剖析时,再把关系加上。
这不符合实际工作中的情况。实际工作中,以上列出的几项工作看起来是交叉进行的。
我们在识别类和属性的过程中,可能会发现一些类有相同的属性,于是泛化出超类,可能会发现有的属性还可以在同一领域内分解,于是识别出另一个类以及两个类之间的关联……
注意我的用词:【看起来】交叉进行,因为更微小的过程依然遵守上述的推导过程(1)→(2)→(3)(4)。
为了避免造成误解,我们先完整地讲解知识部分,本书案例如果有和所讲解知识相关的内容,会随时引用。然后在案例部分,按照实际工作中的思考方式灵活应用前面所讲解的知识点。
8.1 分析工作流概述
8.1.1 知识的表达和组织
在业务建模和需求工作流,我们一直把目标系统看作是一个整体,想办法推导出涉众在意的整体表现,即系统的需求。
系统为了满足需求,必须封装一定的知识。这些知识不会乖乖地自己从知识的海洋中走出来,而是需要软件开发人员一点点识别出来,并有组织、有次序地把它们封装到系统中。
因此,我们要思考:
(1)如何准确表达系统需要封装的知识,让系统满足需求;
以及
(2)如何合理组织系统这些知识,低成本地让系统满足需求。
如果不能合理组织知识,当新需求到来时,准确表达知识的成本也会越来越高。如果考虑到利润,很难停留在(1)而不追求(2)。
不管是纯粹在大脑里面打转转,还是借助了纸笔或建模工具来协助,以上的思考都是逃不掉的。
如果需要封装的逻辑很简单,人脑的容量和运算速度能够胜任,在大脑里打转转还可以勉强应付,但是,能带来利润的系统都是复杂的(参见第1章),借助纸笔或建模工具来显式表达思考的过程很有必要,毕竟大脑容量和运算速度比一般人高出一个数量级的天才是很稀罕的。
注意区分“在大脑里完成”和“拍脑袋”的区别。
有的人故意不显式表达,声称“大脑思考就够了”,背后的真相可能不是天才而是遮羞——你让他显式表达,他也表达不出来,因为他没有掌握准确表达知识和合理组织知识的方法。
就像考试一样,面对一道有难度的填空题,考生可能有以下三种表现:
学霸:在大脑中迅速完成推导,直接在答卷填写结果。
普生:拿出草稿纸,规规矩矩推导,然后在答卷填写结果。
学渣:拍脑袋蒙一个,直接在答卷填写结果“敏捷试错”。
因为学霸的“在大脑中推导”和学渣的“拍脑袋”有一个容易观察到的共同点:没有草稿纸,所以学渣有时候会用这个共同点来假装自己是学霸,这一点要警惕。
8.1.2 核心域和非核心域
一个信息系统封装了若干领域的知识。其中,有一个领域的知识是该系统不能抛弃或替换的,这个领域称为"核心域",其他领域称为"非核心域"。
图8-1展示了不同系统类型的核心域和非核心域概念。
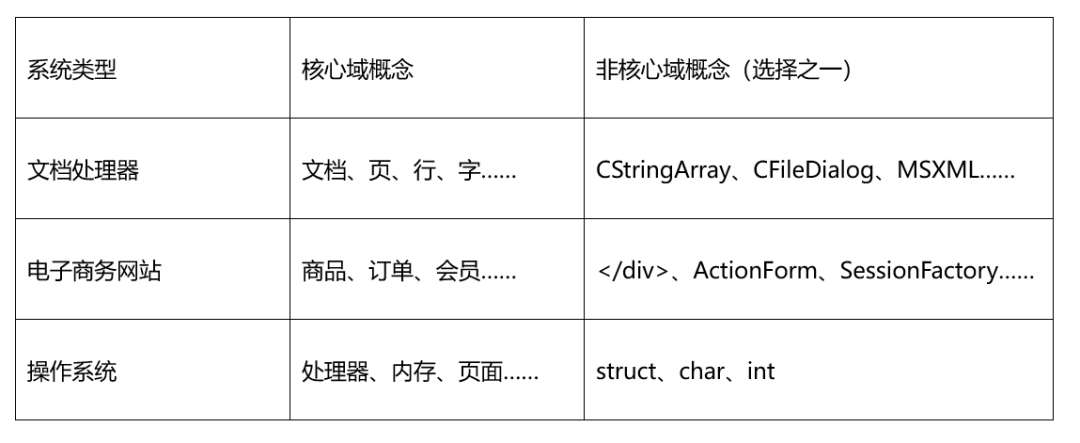
图8-1 不同系统类型的核心域、非核心域概念
以文档处理器为例,开发Microsoft Word和LibreOffice Writer所使用的编程语言和组件不一样,但文档、页、行、字等核心域概念是一样的。即使回到计算机诞生之前或者去到未来,这些概念也依然存在。
还需要注意的是,核心域既可以是非计算机领域,也可以是计算机领域。例如,图8-1中的操作系统,其核心域概念有“处理器”、“内存”等。
关于“核心域”和“非核心域”,一种常用的通俗说法是"业务"和"技术",但"业务"和"技术"的说法不严谨。
有的开发人员在潜意识里用“懂”、“感兴趣”来划分"业务"和"技术":
*我懂且我感兴趣的知识→技术;(我懂Java编码,我对Java编码感兴趣,Java编码是技术)
*我懂但不感兴趣的知识→业务;(下单、收银、配送我懂一些,但不感兴趣,这些是业务)
*我不懂但感兴趣的知识→高科技;(我不懂深度学习,但很感兴趣,哇塞,高科技)
*我不懂且不感兴趣的东东→忽悠。(我不懂UML建模,也不感兴趣,妈的,忽悠)
有的开发人员在潜意识里则用“是否和计算机有关”来划分"业务"和"技术":
*和计算机无关→业务;
*和计算机有关→技术;
【说明1】
本书中的“核心域”和Eric Evans以及DDD(领域驱动设计)话语体系中的“核心域”(Core Domain)意思不同。
本书中的“核心域”指信息系统中不可替换的那部分内容——这个以软件开发人员的知识是可以判断的。
DDD话语体系中,把“领域”(相当于本书中的“核心域”)划分为"核心域"、“通用子域”、“支撑子域”等,例如“Delivery”是核心,“Customer”是通用,“Billing”是支撑——这个划分已经超出了软件开发人员的知识。
一家商场之所以能击败其他对手,原因未必是下单环节有什么不同,倒有可能是在配送环节下了大力气,或者支持的支付渠道多,或者客户服务环节抓得好。没有经过商业竞争的思考,武断地认为某个子领域是系统的“核心”是不合适的。
软件开发人员没有能力和责任做出商业竞争方面的判断。他要做的是,把涉众关于商业竞争方面的思考如实表达,并且用信息系统来封装其中适合封装的部分。
如果发现存在这样的“软件开发人员”,他有责任做出商业竞争方面的判断,那么说明这个人扮演了多个角色,既扮演涉众,也扮演软件开发人员。
【说明2】
另一个可以选择的用词是“问题域(Problem Domain)”,这也是之前大多数面向对象方法学的用语。但近年来,“问题域”和“解决方案域”等用语被领域驱动设计伪创新赶时髦胡乱使用,已经被严重污染。经过考虑,本书使用用语“核心域”和“非核心域”。
8.1.3 域之间映射和协作的套路
我们看一个人员管理系统的核心域类图,如图8-2所示。
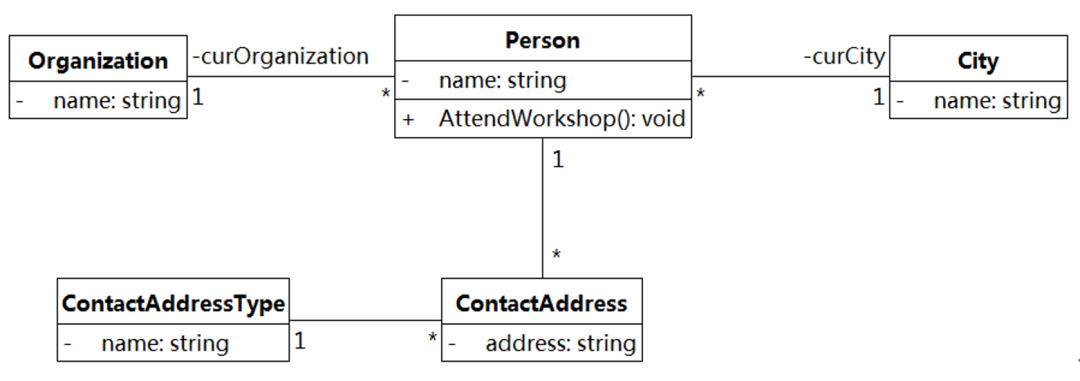
图8-2 人员管理系统的核心域类图
如果将图8-2中的Person类映射为C#实现,可能会得到图8-3的C#代码:

图8-3 类的C#实现(用Enterprise Architect映射)
如果将图8-2中的类映射到关系数据库,会得到图8-4所示的数据库结构:
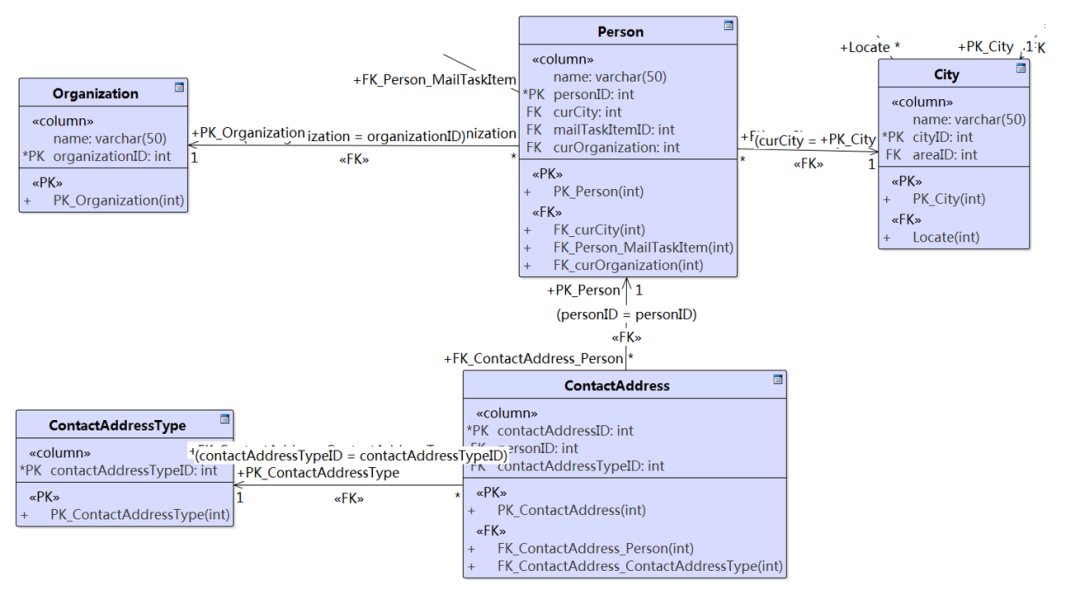
图8-4 将类图映射到数据库模型(用Enterprise Architect映射)
如果采用某种对象-关系映射器框架(例如微软的Entity Framework),Person对象和数据库中的Person表里的一行可能会这样联系起来:
person1=context.Persons.Find(ID)
注意,域和域之间的映射以及协作的套路,与域中的个体并不直接相关。
如果将以上内容中的Person改成Dog,City改成Cat,映射的套路没有变化。即使我们调整了域之间的映射和协作的套路,得到的结果也会按照我们的调整有规律地变化,与域中的个体依然无关。
平时我们看到的一些“架构”,就是域之间映射和协作的一些套路。图8-5列出了现在常被提起的一些“架构”,可能在很多系统中都会观察到,即使这些系统的核心域及非核心域都有不同。
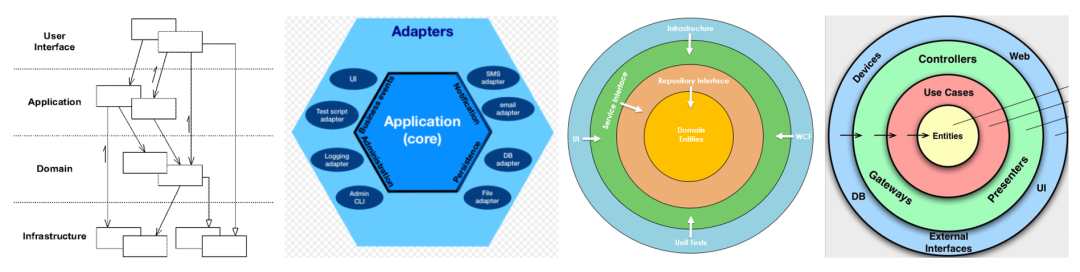
图8-5 一些常见的“架构”
既然域之间的映射和协作有“套路”,过早地混合不同域的知识是不划算的。
如图8-6所示,假设三个域要考虑的知识点分别是a、b、c个,如果分开考虑,然后选择好域和域之间映射的套路,负担最小可以变成a+b+c;如果混在一起考虑,大脑的负担最大会达到a×b×c。只要a、b、c稍微大一些(都大于√3),相乘的结果就会大于相加的结果,随着a、b、c进一步增大,差距会迅速增大。
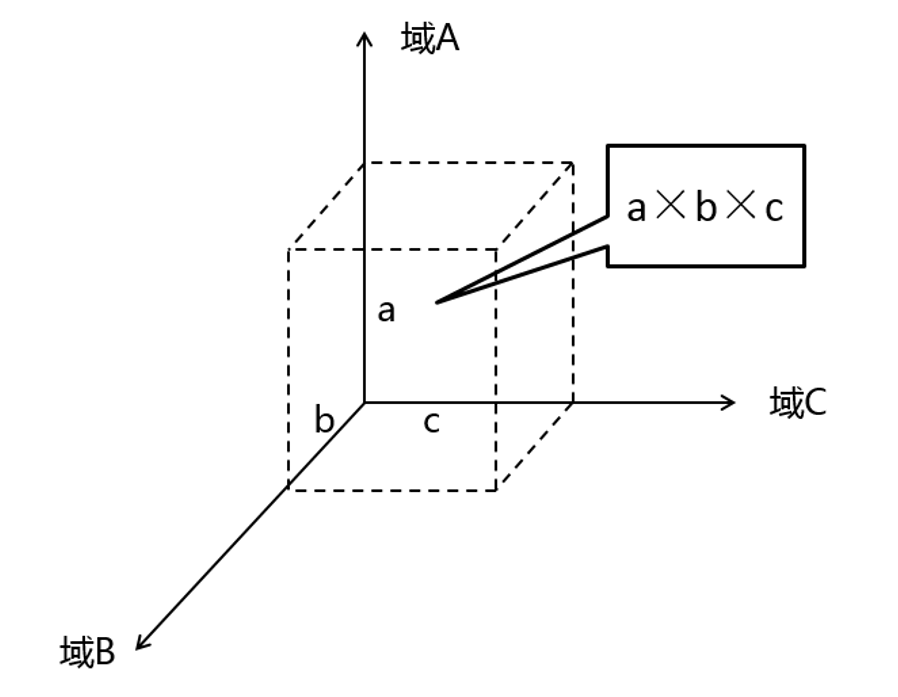
图8-6 过早混合不同域的知识会增加大脑负担
过早地混合不同域的知识,会加重开发人员大脑的负担,导致开发人员腾不出脑力来思考核心域中更深刻的问题,只好稍微折腾一下如图8-5的“域之间的架构”,心里安慰自己,我有“架构”了!却忘了,其实还没有触碰到最需要大脑去思考的核心域概念和逻辑。而这又很可能会被巧妙地当成遮羞布——不是我不思考,而是要想的事情太多了顾不过来啊!
而这种微妙心态的进一步发展,会导致开发人员有意无意地混合不同域的知识,把复杂度弄成a×b×c,以此达成废话刷工作量——以最少的思考得到最多的“成果”。
近年最时髦的就是借DDD话语体系刷工作量了。例如,刚找出一个类Order,然后周围就围上一圈OrderFactory、OrderRepository、OrderService……,洋洋得意地把工作量刷了好几倍。
我经常听软件组织的架构师向我介绍他们所开发系统的“架构”,口沫横飞,说的基本上都是图8-5的“域之间的架构”。好啊,真棒,我知道了。还有呢?没了?
构思那些“域之间的架构”是某些基础设施厂商或者方法学家的工作,我们挑一个适合自己项目的套路用上就行了。有什么问题,可以去请教用这个套路用得好的先行者或者与其合作。
“域内部的架构”,那些核心域概念和复杂逻辑,这是系统最值钱的地方。要是我们没有办法理清楚,别人是帮不到我们的。这才是大脑最该用的地方!
8.1.4 被忽视的核心域
8.1.4.1 鸟类里充兽,兽类里充鸟
当今的软件开发现实,核心域受到的重视远远不够。
我们经常会看到这样的场景:
开发人员张三喜欢研究“底层”。明明他的本职工作是用C#编写生产管理系统,却不好好思考如何吃透核心域把项目做好,而是花时间研究编译器、操作系统甚至硬件。虽然工作是耽搁了,张三给人留下“勤奋好钻研”的印象。
甚至张三还可以写博客或公众号,在网络上成为媒体热爱的“网红程序员”。“网红程序员”很少探讨他当前所开发系统的复杂领域逻辑,更多是谈论某种语言或框架的特性。
张三这是在挑战难度,勇攀科学高峰吗?非也。
脱离自己真正要去解决的问题,热衷于“钻研(其实只是学习)底层”,这样的行为更像是偷懒而不是勤奋。所谓“底层”也只是另一个领域的知识,那个领域自有另外的人去研究。玩票式的“钻研”,在真正专注研究这个领域的研究者看来,实在是不值一提。
但是人性的弱点如此,正如钱钟书所说:“蝙蝠碰见鸟就充作鸟,碰见兽就充作兽。人比蝙蝠就聪明多了。他会把蝙蝠的方法反过来施用:在鸟类里偏要充兽,表示脚踏实地;在兽类里偏要充鸟,表示高超出世。向武人卖弄风雅,向文人装作英雄;”。
比起研究真正需要自己研究的底层(例如质管部和生产部之间的冲突、生产过程中的各种概念之间的关系……),研究(其实只是学习)MSIL的语法等等,要容易和愉快得多。
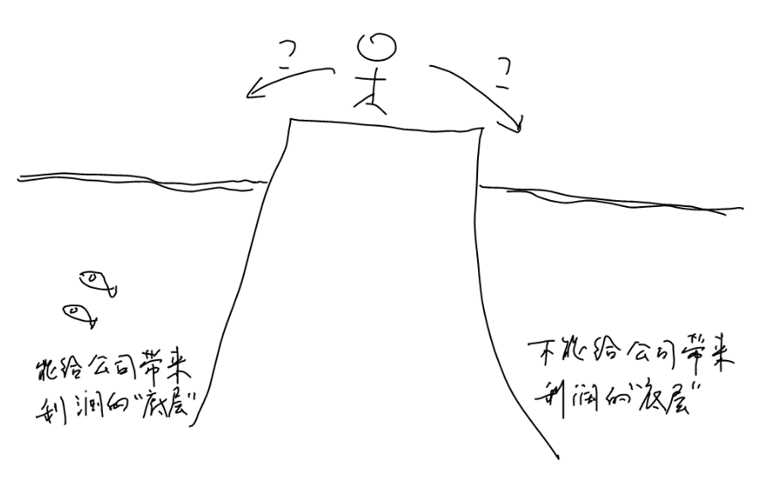
图8-7 真正值得研究的“底层”
8.1.4.2 “技术”、“底层”没什么特别
开发一个基础设施领域的系统,例如操作系统,只需要关注计算机的资源,不需要关注客户、订单、库存、病历等具体某个应用领域的概念。也就是说,“负载”比较低。
另外,基础设施领域有大量已出版教材和先行例子,高校也为计算机和软件相关专业学生开设了相应课程(Linus Torvalds就是在大学教材中MINIX案例的激发下编写了Linux)。这样,开发人员的大脑比较容易把握基础设施领域的复杂性。
在2023年12月10日用"操作系统"为关键字搜索当当网(dangdang.com),得到315132件商品,按1/100来挤水分也有3000多件。其中,一步步教读者如何自己编写操作系统的书也不在少数。

图8-8 当当网搜"操作系统"
市场已经对此做了回答。自己写(抄)一款操作系统并不难,但写一款能带来利润的操作系统太难了——这也同样适用于其他基础设施。
很多能够带来利润的应用系统,就没有基础设施那么好的待遇了。“自己动手写**应用系统”的书也不是没有,但其数量、深度和实用程度很难和基础设施的海量资料相比。
按道理,开发一个库存系统也应该可以不管基础设施,但遗憾的是,当前现实中大多数情况下还是要管。开发团队除了要懂得库存领域的知识,还需要懂MySQL、Apache、Linux……。也就是说,“负载”比较高。
媒体的关注度也不够。一名上班族早上起来,先上厕所用智能马桶冲PP,然后用智能电动牙刷刷牙,用微波炉热牛奶,边刷抖音边吃早餐,坐电梯下楼,开车去公司,用公司的业务系统工作。上面涉及到的七个智能系统中,估计只有抖音的开发人员可能会引起媒体的兴趣。
经常有"知名程序员"在谈到对建模(其实是ABC工作流)和UML的看法时,表示"对我来说不重要",进一步探究会发现,这些"知名程序员"往往开发的是基础设施领域的系统。或者也可以说,如果一名程序员开发的是"操作系统"、"编译器"、“浏览器”等带光环词汇的系统,更容易撩拨媒体从业人员的兴奋点,获得他们的青睐。
市场经济中,不存在哪个领域比其他领域更核心。如果像过去"以粮为纲"、"以钢为纲"一样,扭曲市场信号,硬性指定某个领域(芯片、操作系统)更核高基,造就的多半是骗取纳税人金钱的投机分子。
UMLChina公众号精选(20231208更新)按ABCD工作流分类