作者提出了一种新的基于注意尺度序列融合的YOLO框架(ASF-YOLO),该框架结合了空间和尺度特征,实现了准确快速的细胞实例分割。基于YOLO分割框架,我们使用尺度序列特征融合(SSFF)模块来增强网络的多尺度信息提取能力,并使用三重特征编码器(TPE)模块来融合不同尺度的特征图以增加详细信息。我们进一步引入了一种通道和位置注意机制(CPAM)来集成SSFF和TPE模块,该模块专注于信息通道和空间位置相关的小对象,以提高检测和分割性能。在两个细胞数据集上的实验验证表明,所提出的ASFYOLO模型具有显著的分割精度和速度。在2018年数据科学碗数据集上,它实现了0.91的盒mAP、0.887的掩码mAP和47.3 FPS的推理速度,优于最先进的方法。
首先看下实例效果:
官方论文在这里,如下所示:

YOLO框架一般由backbone、neck和head三个主要组件构成。backbone网络是卷积神经网络,用于从不同的粒度下提取图像特征。CSPDarknet53是基于YOLOv4进行改进的backbone网络,被用作YOLOv5的主干网络。它包含了C3模块(包括3个卷积层)和ConvBNSiLU模块。在YOLOv5和YOLOv8的backbone中,有5个级别的特征提取分支:P1、P2、P3、P4和P5,与YOLO网络的输出相关联。YOLOv5 v7和YOLOv8是基于YOLO的主流架构之一,不仅可以用于检测和分类任务,还可以处理分割任务。

作者开发了一种新颖的特征融合网络架构,由两个主要组件网络组成,可以提供小目标分割的互补信息:
SSSF模块,它将来自多个尺度图像的全局或高级语义信息组合在一起;
TFE模块,它可以捕捉小目标目标的局部精细细节。将局部和全局特征信息相结合可以产生更准确的分割图。

为了识别密集重叠的小目标,一种方法是通过放大图像以参考和比较不同尺度下的形状或外观变化。然而,由于YOLO的backbone网络中的不同特征层具有不同的尺寸,传统的FPN融合机制只对小尺寸特征图进行上采样,并将其添加到前一层特征中,从而忽略了较大尺寸特征层中丰富的详细信息。为此,研究人员提出了TFE(Texture Feature Enhancement)模块,它将大、中、小尺寸的特征进行分离,并添加了较大尺寸的特征图,然后进行特征放大以增强详细特征信息。

为了整合详细特征信息和多尺度特征信息,研究人员提出了CPAM(Channel and Position Attention Module)。CPAM的结构如图5所示,它由两个部分组成。第一个部分是通道注意网络,它从TFE(输入1)接收输入,用于提取不同通道中包含的代表性特征信息。第二个部分是位置注意网络,它接收来自通道注意网络和SSFF(输入2)的输出,并进行叠加,用于引入位置信息。通过这种方式,CPAM能够融合不同注意力机制,综合利用通道和位置信息,以提高目标识别的性能。

想要进一步了解论文详情,建议还是自行移步阅读原论文,这里就不再赘述了。
作者同时开源了项目,地址在这里,如下所示:
目前还没有什么热度。
这里主要是基于两个医学场景下的数据集来进行实验的,简单看下数据集:
【BCC】
【DSB2018】

使用如下训练参数设置进行训练:
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='weights/yolov5l-seg.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='models/segment/asf-yolo.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/bcc.yaml', help='dataset.yaml path')
parser.add_argument('--hyp', type=str, default='data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=100, help='total training epochs')
parser.add_argument('--batch-size', type=int, default=8, help='total batch size for all GPUs, -1 for autobatch')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--noval', action='store_true', help='only validate final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
parser.add_argument('--noplots', action='store_true', help='save no plot files')
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='image --cache ram/disk')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
parser.add_argument('--project', default='runs/train-seg', help='save to project/name')
parser.add_argument('--name', default='improve', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--cos-lr', action='store_true', help='cosine LR scheduler')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2')
parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
parser.add_argument('--seed', type=int, default=0, help='Global training seed')
parser.add_argument('--local_rank', type=int, default=-1, help='Automatic DDP Multi-GPU argument, do not modify')
# Instance Segmentation Args
parser.add_argument('--mask-ratio', type=int, default=4, help='Downsample the truth masks to saving memory')
parser.add_argument('--no-overlap', action='store_true', help='Overlap masks train faster at slightly less mAP')
return parser.parse_known_args()[0] if known else parser.parse_args()
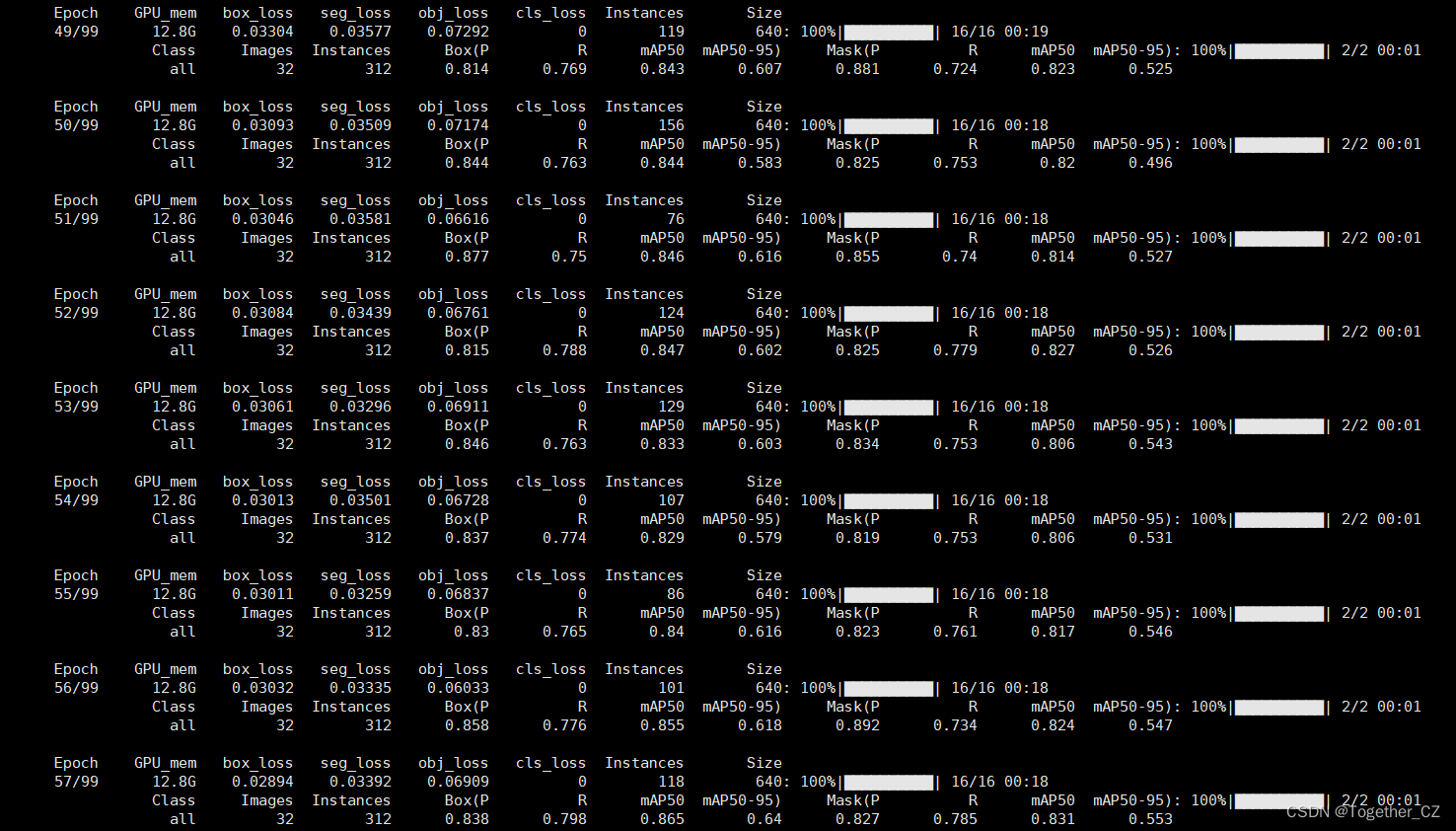
训练启动,日志输出如下:

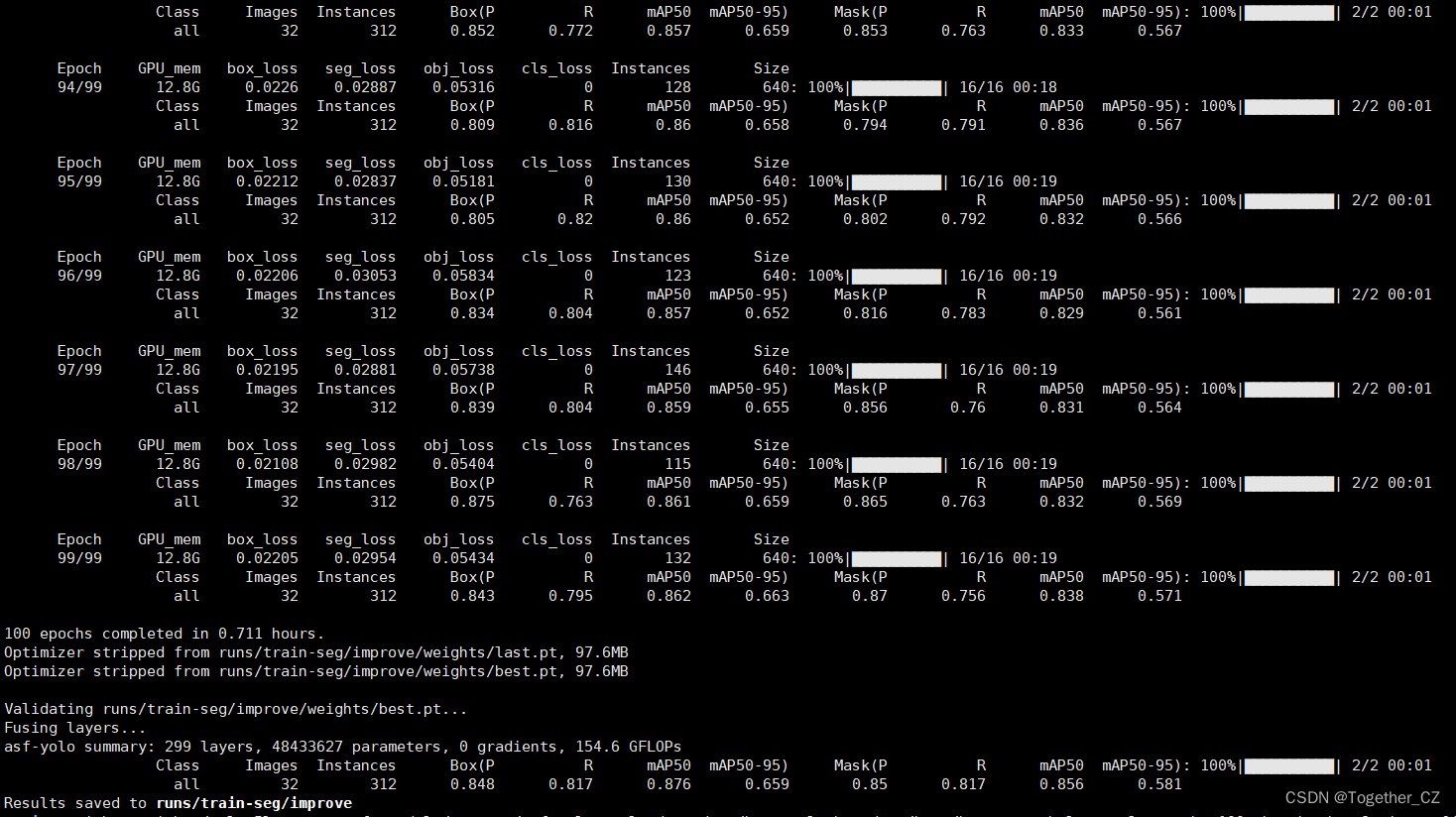
训练完成截图如下所示:
等待训练完成后我们来看下具体的结果内容。
【BCC实验结果】
【F1】
F1分数是精确率和召回率的调和平均值,它综合考虑了两者的性能指标。F1值曲线可以帮助我们确定在不同精确率和召回率之间找到一个平衡点,以选择最佳的阈值。

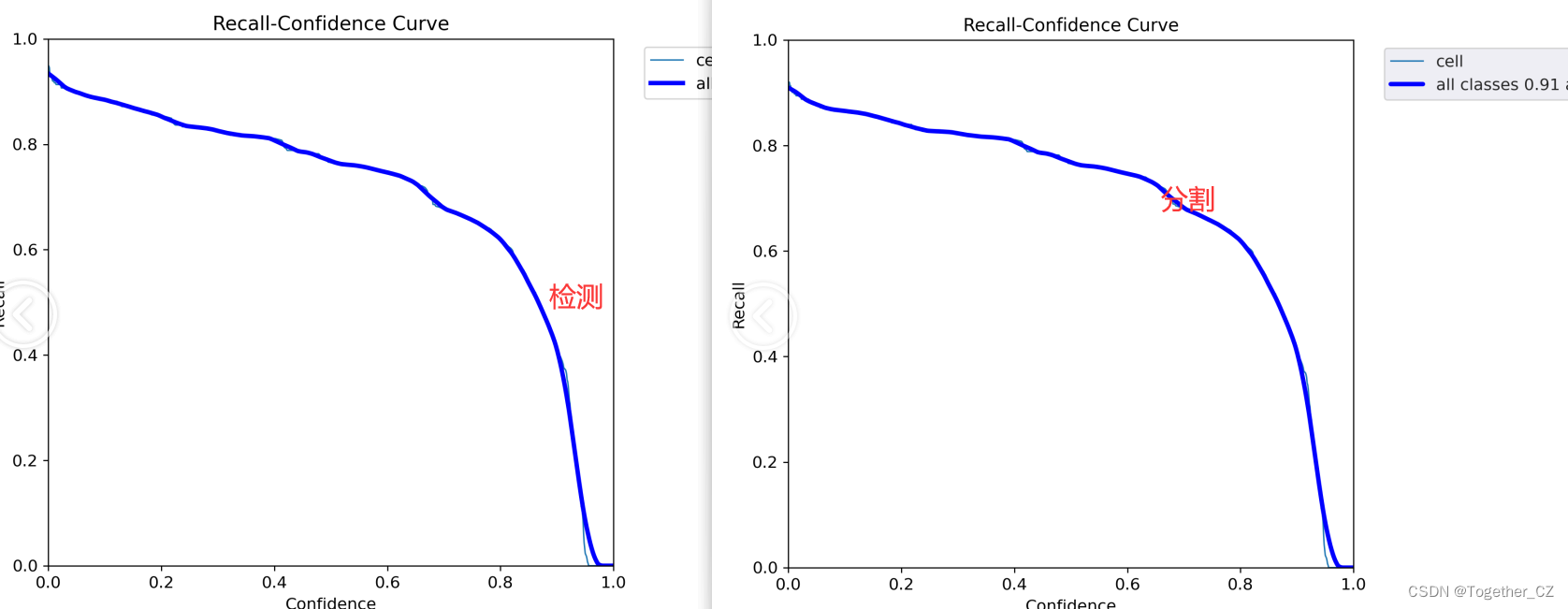
【Recall】
召回率曲线(Recall Curve)是一种用于评估二分类模型在不同阈值下的召回率性能的可视化工具。它通过绘制不同阈值下的召回率和对应的精确率之间的关系图来帮助我们了解模型在不同阈值下的表现。
召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。召回率也被称为灵敏度(Sensitivity)或真正例率(True Positive Rate)。
【Precision】
精确率曲线(Precision-Recall Curve)是一种用于评估二分类模型在不同阈值下的精确率性能的可视化工具。它通过绘制不同阈值下的精确率和召回率之间的关系图来帮助我们了解模型在不同阈值下的表现。
精确率(Precision)是指被正确预测为正例的样本数占所有预测为正例的样本数的比例。召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。

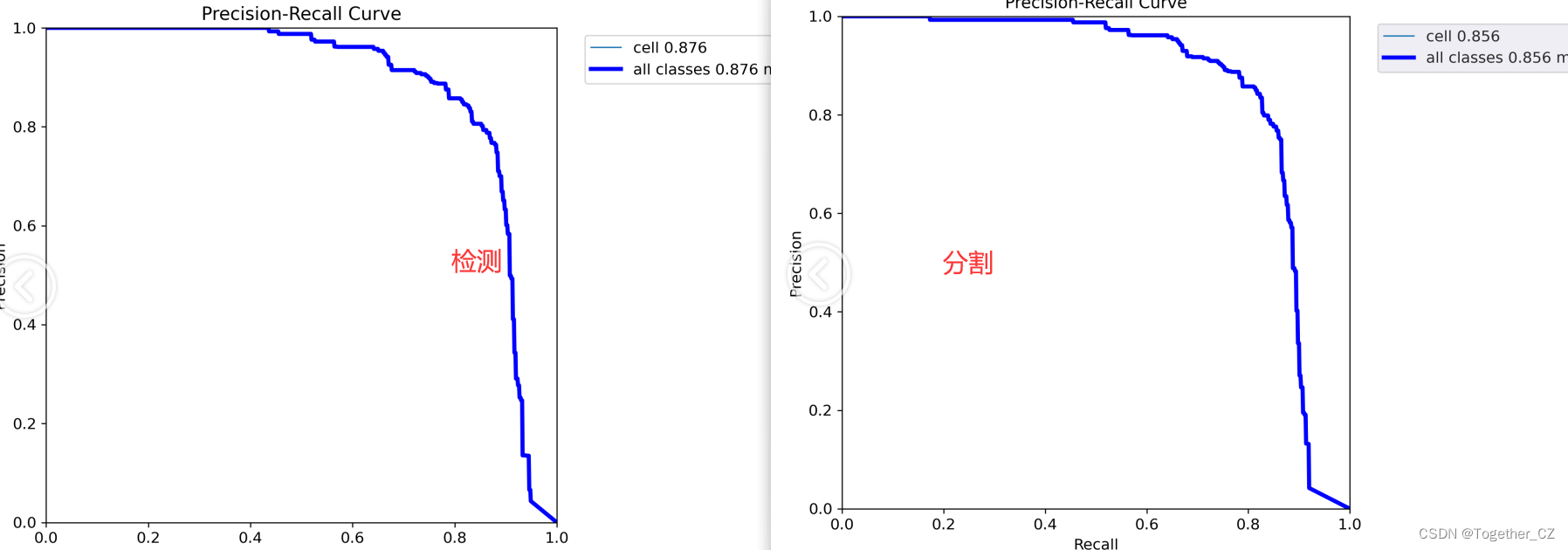
【PR】
精确率-召回率曲线(Precision-Recall Curve)是一种用于评估二分类模型性能的可视化工具。它通过绘制不同阈值下的精确率(Precision)和召回率(Recall)之间的关系图来帮助我们了解模型在不同阈值下的表现。
精确率是指被正确预测为正例的样本数占所有预测为正例的样本数的比例。召回率是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。
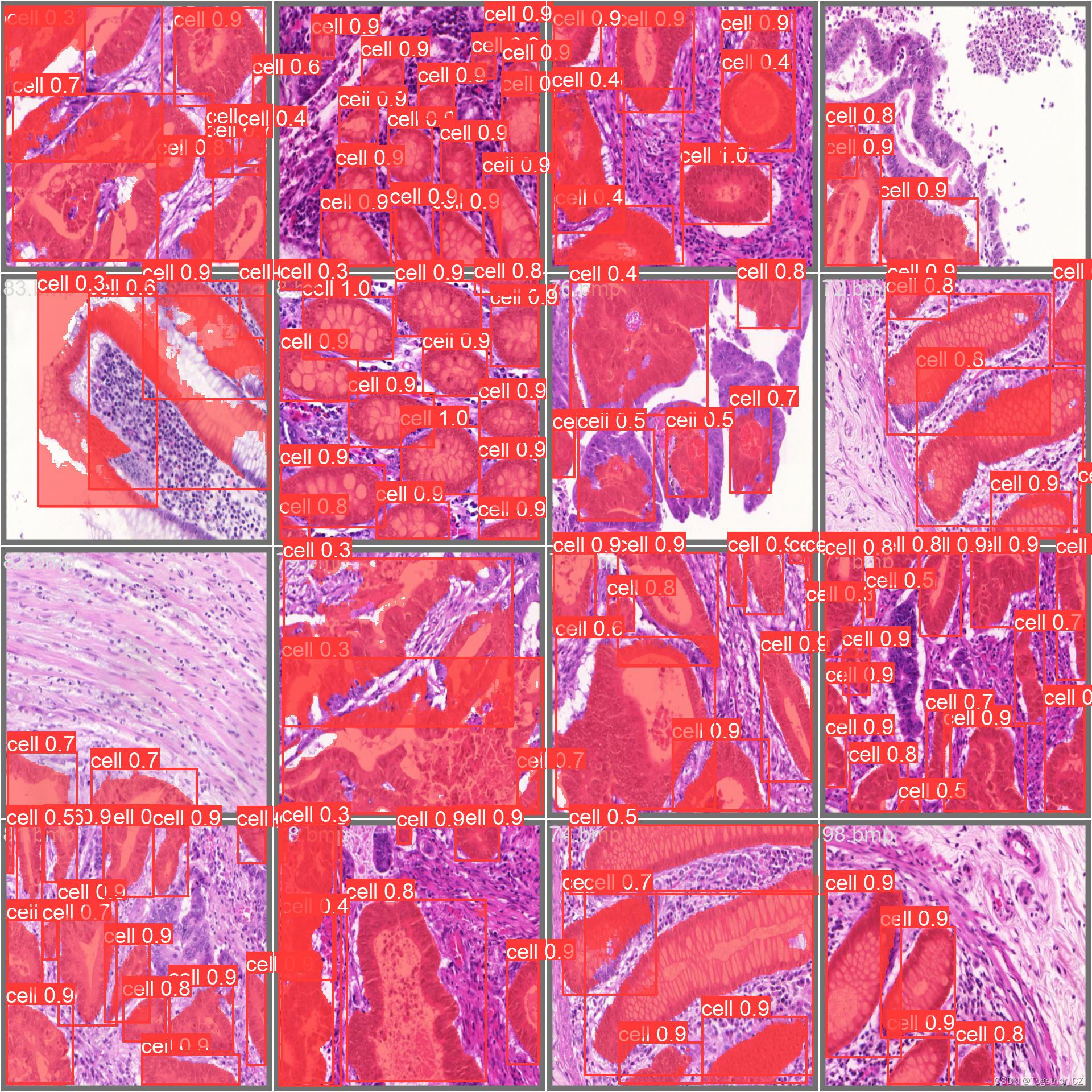
【Batch实例】

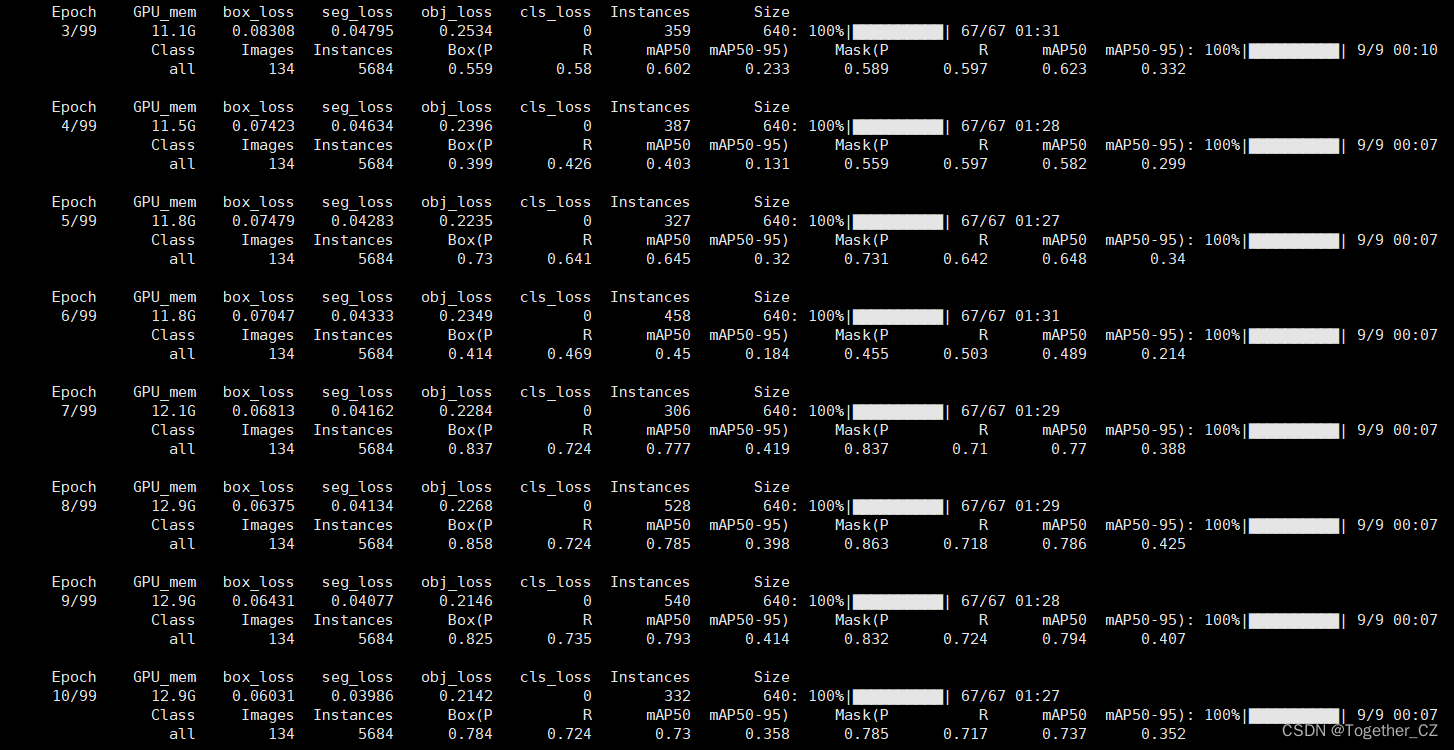
到这里我们完成了在BCC数据集的完整实验内容,接下来我们开始构建基于DSB2018数据集上的实验内容,由于整体的建模操作过程同BCC数据集是完全一致的,所以这里就不再赘述相关节点的内容,直接来看对应的实践,训练输出如下:


训练完成截图如下:

等待训练完成后我们来看下具体的结果内容。
【DSB2018实验结果】
【F1】
F1分数是精确率和召回率的调和平均值,它综合考虑了两者的性能指标。F1值曲线可以帮助我们确定在不同精确率和召回率之间找到一个平衡点,以选择最佳的阈值。

【Recall】
召回率曲线(Recall Curve)是一种用于评估二分类模型在不同阈值下的召回率性能的可视化工具。它通过绘制不同阈值下的召回率和对应的精确率之间的关系图来帮助我们了解模型在不同阈值下的表现。
召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。召回率也被称为灵敏度(Sensitivity)或真正例率(True Positive Rate)。

【Precision】
精确率曲线(Precision-Recall Curve)是一种用于评估二分类模型在不同阈值下的精确率性能的可视化工具。它通过绘制不同阈值下的精确率和召回率之间的关系图来帮助我们了解模型在不同阈值下的表现。
精确率(Precision)是指被正确预测为正例的样本数占所有预测为正例的样本数的比例。召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。

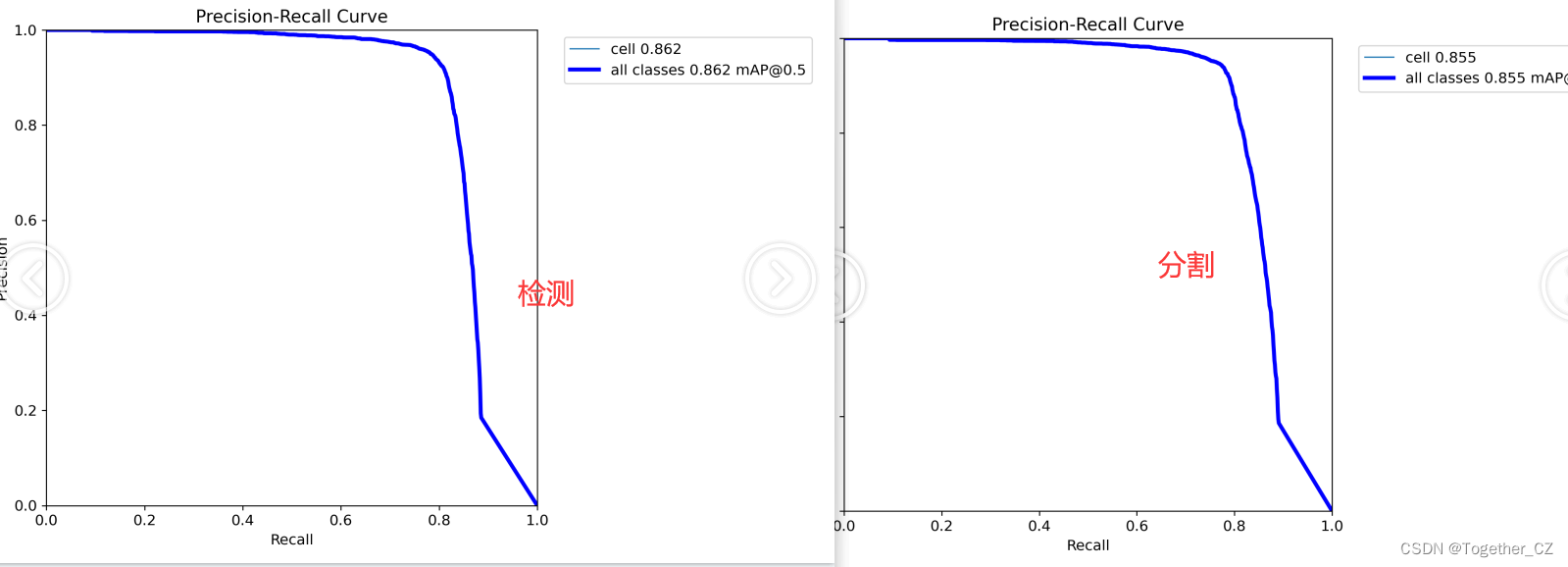
【PR】
精确率-召回率曲线(Precision-Recall Curve)是一种用于评估二分类模型性能的可视化工具。它通过绘制不同阈值下的精确率(Precision)和召回率(Recall)之间的关系图来帮助我们了解模型在不同阈值下的表现。
精确率是指被正确预测为正例的样本数占所有预测为正例的样本数的比例。召回率是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。
【Batch实例】


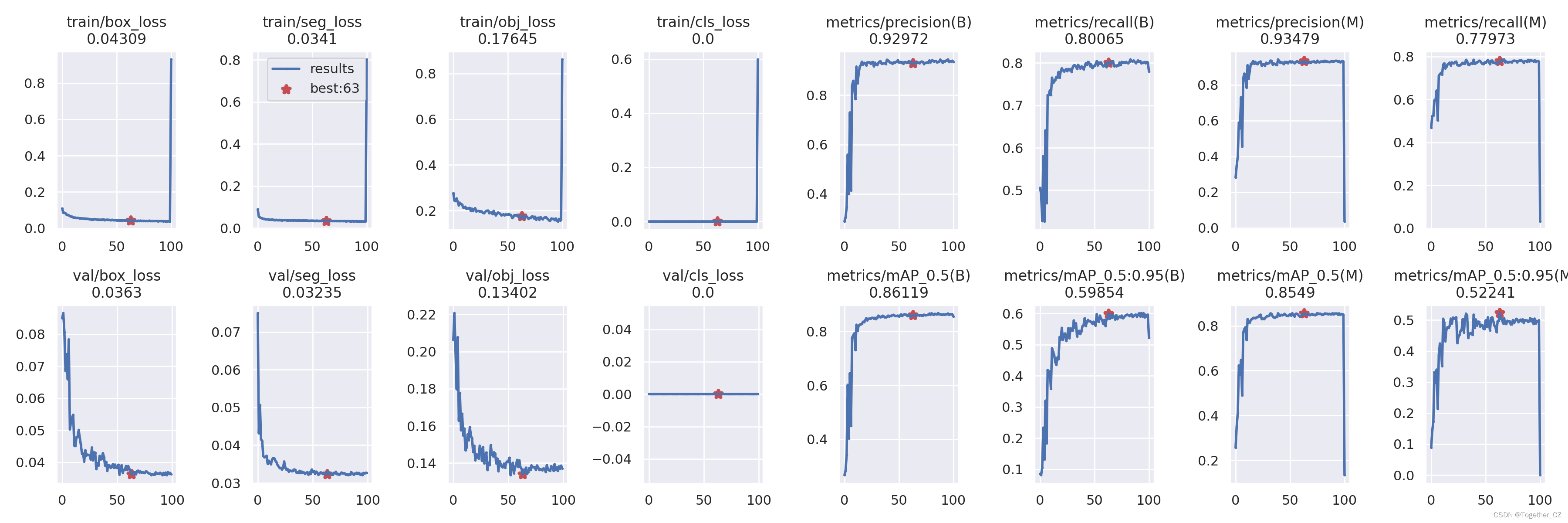
整体训练可视化如下:
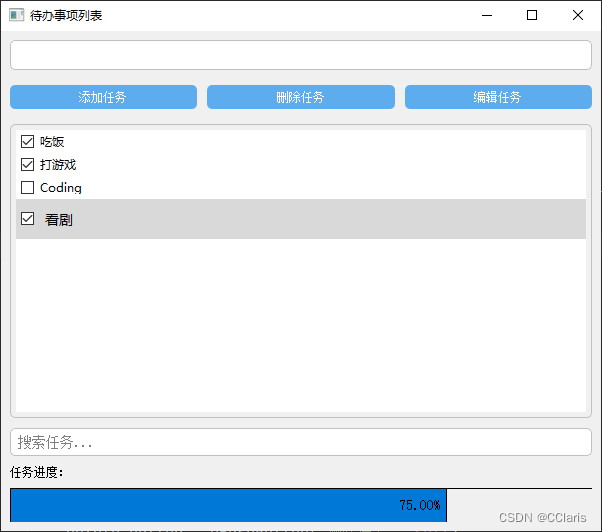
为了使用方便,这里也开发了对应的可视化界面系统,实例推理效果如下所示:

到这里本文的实践学习就全部结束了,感兴趣的话也都可以自己动手实践一下!