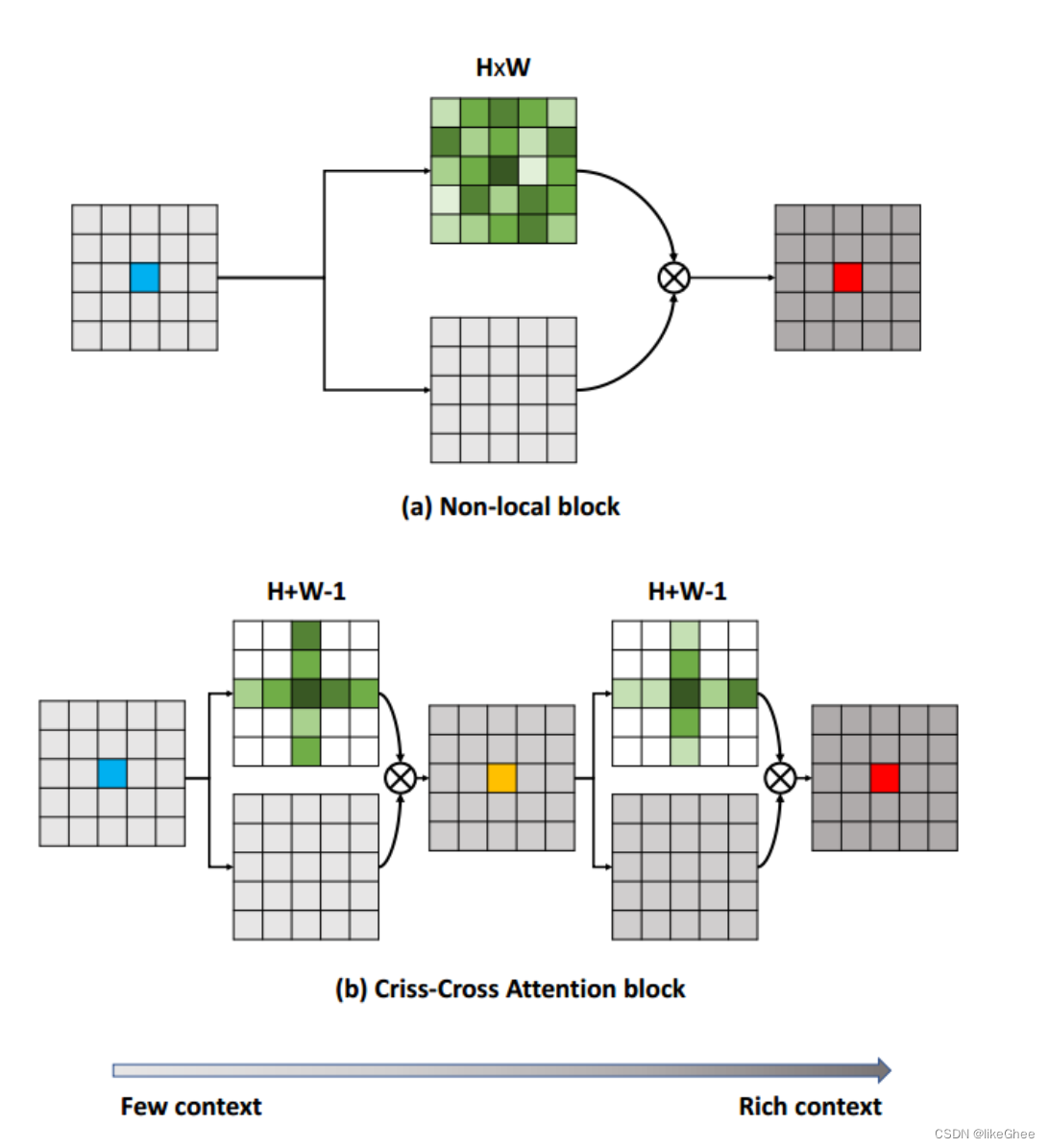
1 tranforms概述
1.1 torchvision介绍
torchvision是pytorch的计算机视觉工具包,主要有以下三个模块:
-
torchvision.transforms:提供了常用的一系列图像预处理方法,例如数据的标准化,中心化,旋转,翻转等。
-
torchvision.datasets:定义了一系列常用的公开数据集的datasets,比如MNIST,CIFAR-10,ImageNet等。
-
torchvision.model:提供了常用的预训练模型,例如AlexNet,VGG,ResNet,GoogLeNet等。
1.2 tranforms介绍
对于视觉方向的图像处理方面,PyTorch提供了很好的预处理接口,对于图像的转换处理,使用 torchvision.tranforms 模块使得这些操作非常高效。torchvision.transforms常用的图像预处理方法
-
数据中心化,数据标准化
-
缩放,裁剪,旋转,翻转,填充
-
噪声添加,灰度变换,线性变换,仿射变换
-
亮度、饱和度及对比度变换
深度学习是由数据驱动的,数据的数量以及分布对模型的优劣起到决定性作用,所以需要对数据进行一定的预处理以及数据增强,用来提升模型的泛化能力。

上图是1张原始图片经过数据增强之后生成的一系列数据,一共有64张图片。对图片进行数据增强可以丰富训练数据,提高模型的泛化能力。因为如果数据增强生成了与测试样本很相似的图片,那么模型的泛化能力自然可以得到提高。
使用上一节中介绍的二分类实验的代码的数据预处理部分:
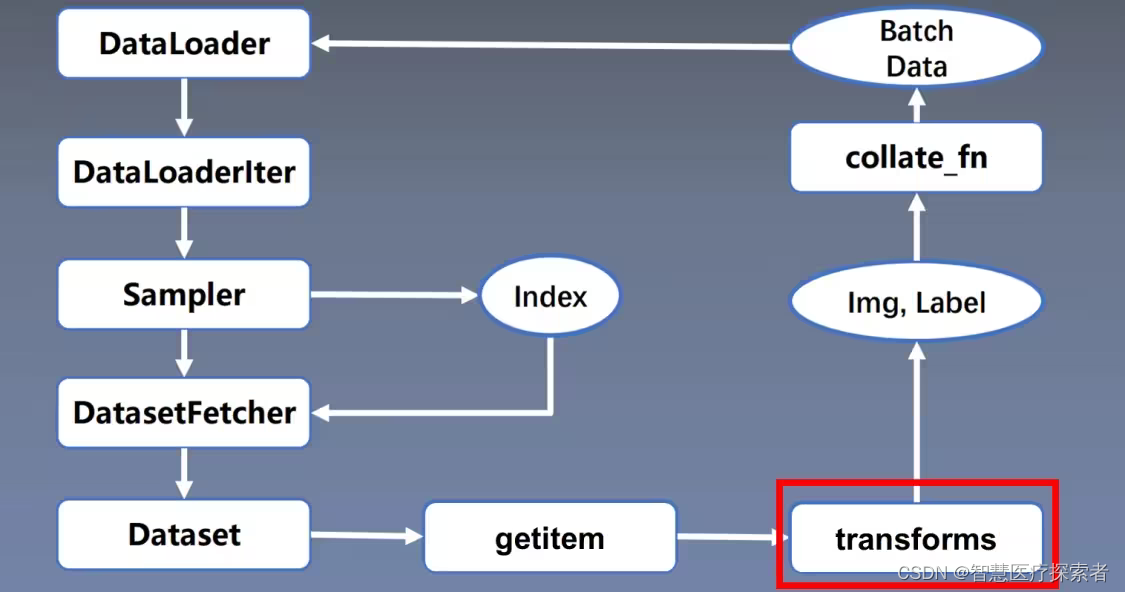
2 tranforms图像裁剪
2.1 随机裁剪
函数原型:
torchvision.transforms.RandomCrop(size,padding = None,pad_if_needed = False,fill = 0,padding_mode ='constant' )参数:
-
size(sequence 或int) - 作物的所需输出大小。如果size是int而不是像(h,w)这样的序列,则进行正方形裁剪(大小,大小)
-
padding(int或sequence ,optional) - 图像每个边框上的可选填充。默认值为None,即无填充。如果提供长度为4的序列,则它用于分别填充左,上,右,下边界。如果提供长度为2的序列,则分别用于填充左/右,上/下边界
-
pad_if_needed(boolean) - 如果小于所需大小,它将填充图像以避免引发异常。由于在填充之后完成裁剪,因此填充似乎是在随机偏移处完成的。
-
fill - 恒定填充的像素填充值。默认值为0.如果长度为3的元组,则分别用于填充R,G,B通道。仅当padding_mode为常量时才使用此值.
-
padding_mode-填充类型。应该是:恒定,边缘,反射或对称。默认值是常量。
常量:具有常量值的焊盘,该值用填充指定
edge:填充图像边缘的最后一个值
反射:具有图像反射的垫(不重复边缘上的最后一个值),填充[1,2,3,4]在反射模式下两侧有2个元素将导致[3,2,1,2,3,4,3,2]
对称:具有图像反射的垫(重复边缘上的最后一个值),填充[1,2,3,4]在对称模式下两侧有2个元素将导致[2,1,1,2,3,4,4,3]
示例代码:
import torchvision.transforms as transform
from PIL import Image
import matplotlib.pyplot as plt
img0 = Image.open('../data/dog01.jpg')
img1 = transform.RandomCrop((512, 512))(img0)
img2 = transform.RandomCrop((512, 512), padding=25, fill=125, padding_mode="edge")(img0)
axs = plt.figure().subplots(1, 3)
axs[0].imshow(img0)
axs[0].set_title('src')
axs[0].axis('off')
axs[1].imshow(img1)
axs[1].set_title('RandomCrop')
axs[1].axis('off')
axs[2].imshow(img2)
axs[2].set_title('padding_mode')
axs[2].axis('off')
plt.show()运行代码显示:

2.2 中心裁剪
函数原型:
torchvision.transforms.CenterCrop(size) 参数:
-
依据给定的size从中心裁剪 参数: size- (sequence or int),若为sequence,则为(h,w),若为int,则(size,size)
示例代码:
import torchvision.transforms as transform
from PIL import Image
import matplotlib.pyplot as plt
img0 = Image.open('../data/dog01.jpg')
img1 = transform.CenterCrop(512)(img0)
img2 = transform.CenterCrop((512, 256))(img0)
axs = plt.figure().subplots(1, 3)
axs[0].imshow(img0)
axs[0].set_title('src')
axs[0].axis('off')
axs[1].imshow(img1)
axs[1].set_title('CenterCrop')
axs[1].axis('off')
axs[2].imshow(img2)
axs[2].set_title('CenterCrop2')
axs[2].axis('off')
plt.show()运行代码显示:

2.3 随机长宽比裁剪
将给定的PIL图像裁剪为随机大小和宽高比。将原始图像大小变成随机大小(默认值:是原始图像的0.08到1.0倍)和随机宽高比(默认值:3/4到4/3倍)。这种方法最终调整到适当的大小。这通常用于训练Inception网络。
函数原型:
torchvision.transforms.RandomResizedCrop(size, scale=(0.08, 1.0), ratio=(0.75, 1.3333333333333333), interpolation=2)参数:
-
size - 每条边的预期输出大小
-
scale - 裁剪的原始尺寸的大小范围
-
ratio - 裁剪的原始宽高比的宽高比范围
-
interpolation - 默认值:PIL.Image.BILINEAR
2.4 上下左右中心裁剪
将给定的PIL图像裁剪为四个角和中央裁剪。此转换返回图像元组,并且数据集返回的输入和目标数量可能不匹配。对图片进行上下左右以及中心裁剪,获得5张图片,返回一个4D-tensor 。
函数原型:
torchvision.transforms.FiveCrop(size)参数:
-
size- (sequence or int),若为sequence,则为(h,w),若为int,则(size,size)
2.5 上下左右中心裁剪后翻转
将给定的PIL图像裁剪为四个角,中央裁剪加上这些的翻转版本(默认使用水平翻转)。
此转换返回图像元组,并且数据集返回的输入和目标数量可能不匹配。
函数原型:
torchvision.transforms.TenCrop(size, vertical_flip=False) 参数:
-
size(sequence 或int) -作物的所需输出大小。如果size是int而不是像(h,w)这样的序列,则进行正方形裁剪(大小,大小)。
-
vertical_flip(bool) - 使用垂直翻转而不是水平翻转
3 transforms翻转和旋转
3.1 依概率p水平翻转
以给定的概率随机水平翻转给定的PIL图像。
函数原型:
torchvision.transforms.RandomHorizontalFlip(p=0.5)参数:
-
p- 概率,默认值为0.5
3.2 依概率p垂直翻转
以给定的概率随机垂直翻转给定的PIL图像。
函数原型:
torchvision.transforms.RandomVerticalFlip(p=0.5)参数:
-
p(浮点数) - 图像被翻转的概率。默认值为0.5
3.3 随机旋转
按角度旋转图像。
函数原型:
torchvision.transforms.RandomRotation(degrees, resample=False, expand=False, center=None)参数:
-
degrees(sequence 或float或int) -要选择的度数范围。如果degrees是一个数字而不是像(min,max)这样的序列,则度数范围将是(-degrees,+ degrees)。
-
resample({PIL.Image.NEAREST ,PIL.Image.BILINEAR ,PIL.Image.BICUBIC} ,可选) - 可选的重采样过滤器。请参阅过滤器以获取更多信 如果省略,或者图像具有模式“1”或“P”,则将其设置为PIL.Image.NEAREST。
-
expand(bool,optional) - 可选的扩展标志。如果为true,则展开输出以使其足够大以容纳整个旋转图像。如果为false或省略,则使输出图像与输入图像的大小相同。请注意,展开标志假定围绕中心旋转而不进行平移。
-
center(2-tuple ,optional) - 可选的旋转中心。原点是左上角。默认值是图像的中心。
4 transforms图像变换
4.1 调整size
将输入PIL图像的大小调整为给定大小。
函数原型:
torchvision.transforms.Resize(size, interpolation=2)参数:
-
size(sequence 或int) -所需的输出大小。如果size是类似(h,w)的序列,则输出大小将与此匹配。如果size是int,则图像的较小边缘将与此数字匹配。即,如果高度>宽度,则图像将重新缩放为(尺寸*高度/宽度,尺寸)
-
interpolation(int,optional) - 所需的插值。默认是 PIL.Image.BILINEAR
示例代码:
import torchvision.transforms as transform
from PIL import Image
img0 = Image.open('../data/dog01.jpg')
img1 = transform.Resize((512, 512))(img0)
print('source image shape: ', img0.size)
print('resize image shape: ', img1.size)运行代码显示:
source image shape: (1920, 1080)
resize image shape: (512, 512)4.2 转为tensor
将PIL Image或者 ndarray 转换为tensor,并且归一化至[0-1] 注意事项:归一化至[0-1]是直接除以255,若自己的ndarray数据尺度有变化,则需要自行修改。
函数原型:
torchvision.transforms.ToTensor()示例代码:
import torchvision.transforms as transforms
from PIL import Image
img0 = Image.open('../data/dog01.jpg')
tensor_img = transforms.ToTensor()(img0)
4.3 标准化
Normalize()函数的作用是将数据转换为标准高斯分布,即逐个channel的对图像进行标准化(均值变为0,标准差为1),可以加快模型的收敛。输入(channel,height,width)形式的tensor。
函数原型:
torchvision.transforms.Normalize(mean, std)参数:
-
mean(sequence) - 每个通道的均值序列。
-
std(sequence) - 每个通道的标准偏差序列。
-
inplace:是否原地操作
output[channel]=(input[channel]−mean[channel])/ std[channel]
经常看到的mean=[0.485,0.456,0.406], std=[0.229,0.224,0.225]表示的是从数据集中随机抽样计算得到的。
示例代码:
import torchvision.transforms as transforms
from PIL import Image
img0 = Image.open('../data/dog01.jpg')
tensor_img = transforms.ToTensor()(img0)
norm_img = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
4.4 填充
使用给定的“pad”值在所有面上填充给定的PIL图像。
函数原型:
torchvision.transforms.Pad(padding, fill=0, padding_mode='constant')参数:
-
padding(int或tuple) -每个边框上的填充。如果提供单个int,则用于填充所有边框。如果提供长度为2的元组,则分别为左/右和上/下的填充。如果提供长度为4的元组,则分别为左,上,右和下边框的填充。
-
fill(int或tuple) - 常量填充的像素填充值。默认值为0.如果长度为3的元组,则分别用于填充R,G,B通道。仅
-
padding_mode为常量时才使用此值
-
padding_mode(str)
填充类型。应该是:恒定,边缘,反射或对称。默认值是常量。
常量:具有常量值的焊盘,该值用填充指定
edge:填充图像边缘的最后一个值
反射:具有图像反射的焊盘,而不重复边缘上的最后一个值.例如,在反射模式下在两侧填充2个元素的填充[1,2,3,4]将导致[3,2,1,2,3,4,3,2]
对称:具有图像反射的垫,重复边缘上的最后一个值.例如,在对称模式下填充两侧带有2个元素的[1,2,3,4]将导致[2,1,1,2,3,4,4,3]
4.5 修改亮度、对比度和饱和度
随机更改图像的亮度,对比度和饱和度。
函数原型:
torchvision.transforms.ColorJitter(brightness=0, contrast=0, saturation=0, hue=0)参数:
-
亮度(浮点数或python的元组:浮点数(最小值,最大值)) - 抖动亮度多少。从[max(0,1-brightness),1 +brightness]或给定[min,max]均匀地选择brightness_factor。应该是非负数。
-
对比度(浮点数或python的元组:浮点数(最小值,最大值)) - 抖动对比度多少。contrast_factor从[max(0,1-contrast),1 + contrast]或给定[min,max]中均匀选择。应该是非负数。
-
饱和度(浮点数或python的元组数:float (min ,max )) - 饱和度抖动多少。饱和度_因子从[max(0,1-saturation),1 + saturation]或给定[min,max]中均匀选择。应该是非负数。
-
色调(浮点数或python的元组:浮点数(最小值,最大值)) - 抖动色调多少。从[-hue,hue]或给定的[min,max]中均匀地选择hue_factor。应该有0 <= hue <= 0.5或-0.5 <= min <= max <= 0.5。
4.6 转灰度图
将图片转换为灰度图
函数原型:
torchvision.transforms.Grayscale(num_output_channels=1)参数:
-
num_output_channels- (int) ,当为1时,正常的灰度图,当为3时, 3 channel with r == g == b
4.7 线性变换
使用方形变换矩阵和离线计算的mean_vector变换张量图像。给定transformation_matrix和mean_vector,将使矩阵变平。从中拉伸并减去mean_vector,然后用变换矩阵计算点积,然后将张量重新整形为其原始形状。
白化转换:假设X是列向量零中心数据。然后torch.mm计算数据协方差矩阵[D x D],对该矩阵执行SVD并将其作为transformation_matrix传递。
函数原型:
torchvision.transforms.LinearTransformation(transformation_matrix) 参数:
-
transformation_matrix(Tensor) - 张量[D x D],D = C x H x W.
-
mean_vector(Tensor) - 张量[D],D = C x H x W.
4.8 仿射变换
图像保持中心不变的随机仿射变换。
函数原型:
torchvision.transforms.RandomAffine(degrees, translate=None, scale=None, shear=None, resample=False, fillcolor=0) 参数:
-
degrees(sequence 或float或int) -要选择的度数范围。如果degrees是一个数字而不是像(min,max)这样的序列,则度数范围将是(-degrees,+degrees)。设置为0可停用旋转。
-
translate(元组,可选) - 水平和垂直平移的最大绝对分数元组。例如translate =(a,b),然后在范围-img_width * a <dx <img_width * a中随机采样水平移位,并且在-img_height * b <dy <img_height * b范围内随机采样垂直移位。默认情况下不会翻译。
-
scale(元组,可选) - 缩放因子间隔,例如(a,b),然后从范围a <= scale <= b中随机采样缩放。默认情况下会保持原始比例。
-
shear(sequence 或float或int,optional) - 要选择的度数范围。如果degrees是一个数字而不是像(min,max)这样的序列,则度数范围将是(-degrees,+ degrees)。默认情况下不会应用剪切
-
resample({PIL.Image.NEAREST ,PIL.Image.BILINEAR ,PIL.Image.BICUBIC} ,可选) - 可选的重采样过滤器。请参阅过滤器以获取更多信 如果省略,或者图像具有模式“1”或“P”,则将其设置为PIL.Image.NEAREST。
-
fillcolor(int) - 输出图像中变换外部区域的可选填充颜色。(Pillow> = 5.0.0)
4.9 依概率p转为灰度图
依概率p将图片转换为灰度图,若通道数为3,则3 channel with r == g == b
函数原型:
torchvision.transforms.RandomGrayscale(p=0.1)4.10 将数据转换为PILImage
将tensor 或者 ndarray的数据转换为 PIL Image 类型数据
函数原型:
torchvision.transforms.ToPILImage(mode=None)参数:
-
mode- 为None时,为1通道, mode=3通道默认转换为RGB,4通道默认转换为RGBA。
4.11 Lambda函数
将用户定义的lambda应用为变换。
函数原型:
torchvision.transforms.Lambda(lambd )参数:
-
lambd(函数) - 用于转换的Lambda /函数。
5 transforms操作
5.1 RandomChoice
从给定的一系列transforms中选一个进行操作,randomly picked from a list
函数原型:
torchvision.transforms.RandomChoice(transforms)5.2 RandomApply
给一个transform加上概率,以一定的概率执行该操作
函数原型:
torchvision.transforms.RandomApply(transforms, p=0.5)参数:
-
transforms(列表或元组) - 转换列表
-
p(浮点数) - 概率
5.3 RandomOrder
将transforms中的操作顺序随机打乱。
函数原型:
torchvision.transforms.RandomOrder(transforms)6 transforms.Compose
用于将多个transforms组合起来使用,相当于一个组合器,可以将多个transforms按照顺序组合,然后一次性对数据进行处理。
函数原型:
transforms (list of ``Transform`` objects): list of transforms to compose.示例代码:
from torchvision import models, transforms
# 数据转换
image_transform = transforms.Compose([
# 将输入图片resize成统一尺寸
transforms.Resize([224, 224]),
# 将PIL Image或numpy.ndarray转换为tensor,并除255归一化到[0,1]之间
transforms.ToTensor(),
# 标准化处理-->转换为标准正太分布,使模型更容易收敛
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])