模型亮点
- 模型文件:
damo/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-pytorch - Paraformer-large长音频模型集成VAD、ASR、标点与时间戳功能,可直接对时长为数小时音频进行识别,并输出带标点文字与时间戳:
- ASR模型:Parformer-large模型结构为非自回归语音识别模型,多个中文公开数据集上取得SOTA效果,可快速地基于ModelScope对模型进行微调定制和推理。
- 热词版本:Paraformer-large热词版模型支持热词定制功能,基于提供的热词列表进行激励增强,提升热词的召回率和准确率。
FunASR介绍
GitHub源码地址: https://github.com/alibaba-damo-academy/FunASR
FunASR是由阿里巴巴通义实验室语音团队开源的一款语音识别基础框架,集成了语音端点检测、语音识别、标点断句等领域的工业级别模型,吸引了众多开发者参与体验和开发。为了解决工业落地的最后一公里,将模型集成到业务中去,我们开发了社区软件包。 支持以下几种服务部署:
- 中文离线文件转写服务(CPU版本),已完成
- 中文流式语音识别服务(CPU版本),已完成
- 英文离线文件转写服务(CPU版本),已完成
- 中文离线文件转写服务(GPU版本),进行中
- 更多支持中
中文离线文件转写服务(CPU版本)
中文语音离线文件服务部署(CPU版本),拥有完整的语音识别链路,可以将几十个小时的长音频与视频识别成带标点的文字,而且支持上百路请求同时进行转写。
最新动态
2023/11/08: 中文离线文件转写服务 3.0 发布,支持标点大模型、支持Ngram模型、支持fst热词(更新热词通信协议)、支持服务端加载热词、runtime结构变化适配(FunASR/funasr/runtime->FunASR/runtime),dokcer镜像版本funasr-runtime-sdk-cpu-0.3.0 (caa64bddbb43),原理介绍文档(点击此处)
模型下载
- 模型介绍:
https://modelscope.cn/models/damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-onnx/summary - 模型下载
# 安装git&git-lfs
yum install git
yum install git-lfs
git lfs install
git clone https://www.modelscope.cn/damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-onnx.git
拉取镜像并推送到私有harbor
# 从公网拉取镜像
docker pull registry.cn-hangzhou.aliyuncs.com/funasr_repo/funasr:funasr-runtime-sdk-cpu-0.3.0
# 公有镜像重新打个私有tag
docker tag registry.cn-hangzhou.aliyuncs.com/funasr_repo/funasr:funasr-runtime-sdk-cpu-0.3.0 harbor.xxx.com:443/base/funasr:funasr-runtime-sdk-cpu-0.3.0
# 推送到私有harbor
docker push harbor.xxx.com:443/base/funasr:funasr-runtime-sdk-cpu-0.3.0
Docker运行
# 创建挂载目录
mkdir -p funasr-runtime-resources/models
# 如果已安装docker,忽略本步骤
docker run -d -p 10096:10096 -it --privileged=true \
-v $PWD/funasr-runtime-resources/models:/workspace/models -v $PWD/funasr-runtime-resources/models/run_server.sh:/workspace/FunASR/runtime/run_server.sh \
harbor.xxx.com:443/base/funasr:funasr-runtime-sdk-cpu-0.3.0
# 把一步命令返回的container_id放到下面命令中
docker exec -it <container_id> bash
服务端启动
docker启动之后,启动 funasr-wss-server服务程序:
cd FunASR/runtime
# 会在./funasr-runtime-resources/damo目录下下载模型文件
nohup bash run_server.sh \
--download-model-dir /workspace/models \
--vad-dir damo/speech_fsmn_vad_zh-cn-16k-common-onnx \
--model-dir damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-onnx \
--punc-dir damo/punc_ct-transformer_cn-en-common-vocab471067-large-onnx \
--lm-dir damo/speech_ngram_lm_zh-cn-ai-wesp-fst \
--itn-dir thuduj12/fst_itn_zh \
--hotword /workspace/models/hotwords.txt > log.out 2>&1 &
tail -fn200 log.out
run_server.sh命令参数介绍
--download-model-dir 模型下载地址,通过设置model ID从Modelscope下载模型
--model-dir modelscope model ID 或者 本地模型路径
--quantize True为量化ASR模型,False为非量化ASR模型,默认是True
--vad-dir modelscope model ID 或者 本地模型路径
--vad-quant True为量化VAD模型,False为非量化VAD模型,默认是True
--punc-dir modelscope model ID 或者 本地模型路径
--punc-quant True为量化PUNC模型,False为非量化PUNC模型,默认是True
--lm-dir modelscope model ID 或者 本地模型路径
--itn-dir modelscope model ID 或者 本地模型路径
--port 服务端监听的端口号,默认为 10095
--decoder-thread-num 服务端线程池个数(支持的最大并发路数),
脚本会根据服务器线程数自动配置decoder-thread-num、io-thread-num
--io-thread-num 服务端启动的IO线程数
--model-thread-num 每路识别的内部线程数(控制ONNX模型的并行),默认为 1,
其中建议 decoder-thread-num*model-thread-num 等于总线程数
--certfile ssl的证书文件,默认为:../../../ssl_key/server.crt,如果需要关闭ssl,参数设置为0
--keyfile ssl的密钥文件,默认为:../../../ssl_key/server.key
--hotword 热词文件路径,每行一个热词,格式:热词 权重(例如:阿里巴巴 20),
如果客户端提供热词,则与客户端提供的热词合并一起使用,服务端热词全局生效,客户端热词只针对对应客户端生效。
客户端测试与使用
- 下载客户端测试工具
cd funasr-runtime-resources
curl -O https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/sample/funasr_samples.tar.gz
# 解压
tar -zxvf funasr_samples.tar.gz
cd samples/python
python3 funasr_wss_client.py --host "127.0.0.1" --port 10095 --mode offline --audio_in "../audio/asr_example.wav"
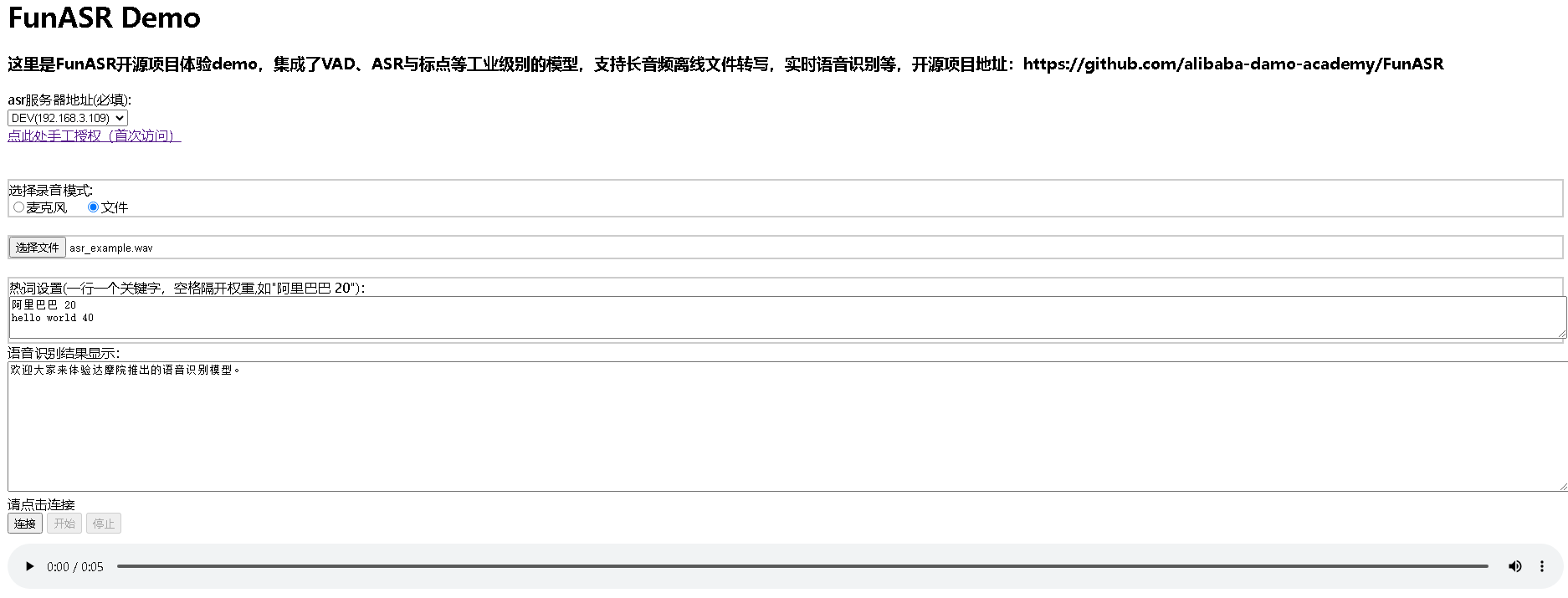
- 使用nginx搭建web访问
- 把
funasr-runtime-resources/samples/html下的static目录重命名为asr- 在nginx已有域名转发下添加如下配置:
server {
listen 80;
server_name xxx.com;
location /asr {
root /home/funasr-runtime-resources/samples/html;
index index.html;
}
}



![[每周一更]-(第27期):HTTP压测工具之wrk](https://img-blog.csdnimg.cn/direct/800cd1e59a0643529eb7db15b273b540.jpeg#pic_center)