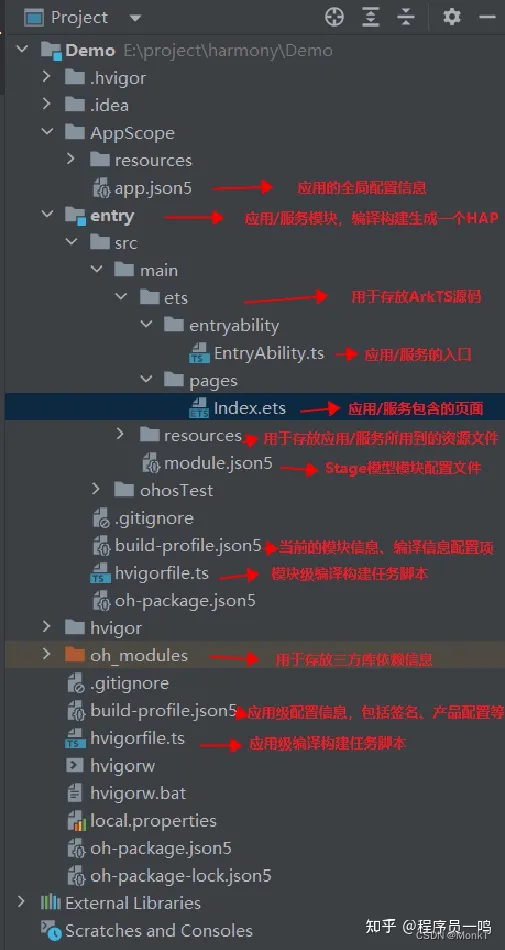
论文导读:
- 论文背景:2023年12月11日,AI科学家李飞飞团队与谷歌合作,推出了视频生成模型W.A.L.T(Window Attention Latent Transformer)——一个在共享潜在空间中训练图像和视频生成的、基于Transformer架构的扩散模型。李飞飞是华裔女科学家、世界顶尖的AI专家,现为美国国家工程院院士、美国国家医学院院士、美国艺术与科学院院士,斯坦福大学终身教授、斯坦福大学人工智能实验室主任,曾任谷歌副总裁和谷歌云首席科学家。
- 面向问题: 视频生成任务中目前主流的方法依然倾向于使用卷积或U-Net作为骨干网络,而没有充分利用Transformer模型的优势。视频的高维度也给Transformer在这一任务上的应用带来了计算和内存上的挑战。
- 解决方法: 提出了一个视频自动编码器,可以将图像和视频映射到一个统一的隐空间。在此基础上,设计了交替使用空间和时空窗口自注意力的Transformer Block,既考虑了计算效率,也允许在图像和视频数据集上进行联合训练。
- 技术亮点:
- 使用了因果3D卷积编码器,空间和时空窗口自注意力,条件批归一化等技术手段来实现高效的视频生成。
- 该方法提供了一个简单、可扩展和高效的基于Transformer的框架,用于图像和视频的联合生成,可以促进这一领域的发展。需要继续扩大模型规模,提高生成视频的分辨率和质量。- 主要贡献:
- 提出了一种联合的图像和视频编码器,可以将图像和视频映射到一个统一的低维隐空间。这使得可以在图像和视频数据集上联合训练单个的生成模型。
- 提出了一种transformer块的新设计,其中空间自注意力层和时空自注意力层交替,可以高效地捕获图像和视频中的空间关系和视频中的时序关系。
- 在公开基准测试集上,没有使用分类器指导的情况下,在视频生成和图像生成任务上都取得了最先进的结果。例如在UCF-101和Kinetics-600视频生成任务,以及ImageNet图像生成任务上。
- 展示了该方法在文本到视频生成任务上的可扩展性和效率。通过级联三个模型,可以生成512 x 896分辨率、每秒8帧的高分辨率、时间一致的照片级真实视频。在UCF-101基准测试上取得了最先进的零样本FVD值。
- 对关键设计选择进行了大量的定量分析,证明了transformer作为视频扩散模型的backbone的有效性。首次证明了transformer可以在联合图像和视频Latent 扩散建模任务上取得很好的性能。- 项目主页: https://walt-video-diffusion.github.io/.
- 论文地址: https://arxiv.org/abs/2312.06662

摘要
我们提出了 W.A.L.T:一种基于 Transformer 的方法,通过扩散建模生成逼真的视频。 我们的方法有两个关键的设计决策:
- 首先,我们使用因果编码器在统一的隐空间内联合压缩图像和视频,从而实现跨模态的训练和生成。
- 其次,为了提高记忆和训练效率,我们使用专为联合空间和时空生成建模而定制的窗口注意力架构。
总而言之,这些设计决策使我们能够在已建立的视频(UCF-101 和 Kinetics-600)和图像(ImageNet)生成基准上实现最先进的性能,而无需使用无分类器指导。 最后,我们还训练了三个用于文本到视频生成任务的级联模型,其中包括一个隐视频扩散基模型和两个用于生成文本到视频的视频超分辨率扩散模型,以生成分辨率为 512 × 896、每秒 8 帧的视频。
引言
Transformer [73] 是高度可扩展和可并行的神经网络架构,旨在赢得“硬件彩票” [39]。 这种理想的特性鼓励研究界越来越青睐 Transformer,而非针对不同领域来研究特定领域架构,例如语言 [26, 55–57]、音频 [1]、语音 [58]、视觉 [18, 30] ]和机器人技术[5,7,89]。 这种统一的趋势使研究人员能够在共享传统意义上不同领域进展的基础上取得进步。 因此,导致有利于Transformer模型设计创新和改进的良性循环。
这一趋势的一个显著例外是视频的生成建模。 扩散模型 [67, 69] 已成为图像 [16, 33] 和视频 [36] 生成建模的领先范例。 然而,由一系列卷积层[46]和自注意力层[73]组成的U-Net架构[33, 62]一直是所有视频扩散方法的主要支柱[16, 33, 36]。 这种偏好源于这样一个事实:Transformer中完全注意机制的记忆需求与输入序列长度呈二次方缩放关系。 在处理视频等高维信号时,这种缩放会导致成本过高。
隐扩散模型(Latent diffusion models,LDMs)[61]通过在从自编码器派生的低维隐空间中运行来降低计算要求[20,72,75]。 在这种情况下,一个关键的设计选择是所使用的隐空间的类型:空间压缩(per frame latents)与时空压缩。 空间压缩通常是首选,因为它可以利用预先训练的图像自编码器和 LDMs,这些图像自编码器和 LDMs 在大型成对图像文本数据集上进行训练。 然而,这种选择增加了网络复杂性并限制了Transformer作为主干网的使用,特别是由于内存限制而生成高分辨率视频。 另一方面,虽然时空压缩可以缓解这些问题,但它妨碍了配对图像文本数据集的使用,这些数据集比视频数据集更大、更多样化。
我们提出了窗口注意力隐Transformer(Window Attention Latent Transformer,W.A.L.T):一种基于Transformer的隐视频扩散模型(latent video dif- fusion models,LVDMs)方法。 我们的方法由两个阶段组成:
- 首先,自编码器将视频和图像映射到统一的低维隐空间。 这种设计选择使得能够在图像和视频数据集上联合训练单个生成模型,并显著减少生成高分辨率视频的计算负担。
- 随后,我们提出了一种用于隐视频扩散建模的Transformer blocks的新设计,Transformer blocks由在非重叠、窗口限制的空间和时空注意力之间交替的自注意力层组成。 这种设计有两个主要好处:首先,使用局部窗口注意力显着降低了计算需求。 其次,它有利于联合训练,其中空间层独立处理图像和视频帧,而时空层致力于对视频中的时间关系进行建模。
虽然概念上很简单,但我们的方法提供了第一个经验证据,证明 Transformer 在公共基准上的隐视频扩散中具有卓越的生成质量和参数效率。 具体来说,我们报告了类条件视频生成(UCF-101 [70])、帧预测(Kinetics-600 [9])和类条件图像生成(ImageNet [15])的最新结果,无需使用分类器免费指导。 最后,为了展示可扩展性和效率,我们还展示了真实感文本到视频生成这一颇具挑战性的任务的结果。 我们训练了由一个隐视频扩散基模型和两个视频超分辨率扩散模型组成的级联模型,以每秒 8 帧的速度生成 512 × 896 分辨率的视频,并在 UCF-101 基准测试中给出了最先进的zero-shot FVD 分数。
相关工作
视频扩散模型
扩散模型在图像 [33,38,52,61,67,68] 和视频生成 [4,24,29,34,36,66] 方面显示出令人印象深刻的结果。 视频扩散模型可以分为像素空间[34,36,66]和隐空间[4,24,31,83]方法,后者在视频建模时带来了重要的效率优势。 Ho等研究者 [36]证明,通过对图像和视频数据进行联合训练可以显著提高文本条件视频生成的质量。 类似地,为了利用图像数据集,隐视频扩散模型通过添加时间层并将其初始化为恒等函数将预先训练的图像模型(通常是 U-Net [62])膨胀为视频模型 [4, 34, 66 ]。 尽管计算效率高,但这种方法将视频和图像模型的设计结合在一起,并且排除了时空压缩。 在本论文中,我们在图像和视频的统一隐空间上进行操作,使我们能够利用大规模图像和视频数据集,同时享受视频时空压缩带来的计算效率增益。
用于生成建模的 Transformer
多类生成模型利用 Transformers [73] 作为主干网,例如生成对抗网络 [42,47,85],自回归 [10,11,20,21,27,59,74,77,78, 80, 81] 和扩散 [2, 22, 41, 50, 53, 87] 模型。 受到大语言模型自回归预训练成功的启发[55-57],Ramesh 等[59]通过预测从图像tokenizer获得的下一个视觉token来训练文本到图像生成模型。 随后,这种方法被应用于多种应用,包括类条件图像生成 [20, 79]、文本到图像 [17, 59, 76, 80] 或图像到图像转换 [21, 77]。 类似地,对于视频生成,基于 Transformer 的模型被提出使用 VQGAN [23,37,78,81] 的 3D 扩展或使用每帧图像latents [27] 来预测下一个标记。 考虑到所涉及的序列很长,视频的自回归采样通常是不切实际的。 为了缓解这个问题,非自回归采样[10, 11],即并行token预测,已被采用作为基于Transformer的视频生成的更有效的解决方案[27, 74, 81]。 最近,社区开始采用 Transformer 作为扩散模型的去噪主干来代替 U-Net [12,38,50,53,87]。 据我们所知,我们的工作是基于Transformer主干网联合训练图像和视频隐扩散模型的首次成功的实证(第5.1节)。
背景
扩散formulation
扩散模型 [33,67,69] 是一类生成模型,它通过迭代地对从噪声分布中提取的样本进行去噪来学习生成数据。 高斯扩散模型假设一个前向噪声过程,逐渐将噪声 (
ϵ
\mathbf{\epsilon}
ϵ) 应用于实际数据 (
x
0
∼
p
d
a
t
a
\mathbf{x}_0 ∼ p_{data}
x0∼pdata)。 具体来说,
x
t
=
γ
(
t
)
x
0
+
1
−
γ
(
t
)
ϵ
,
(1)
\mathbf{x}_t = \sqrt{\gamma(t)}\mathbf{x}_0 + \sqrt{1-\gamma(t)}\mathbf{\epsilon}, \tag{1}
xt=γ(t)x0+1−γ(t)ϵ,(1)
其中
ϵ
∼
N
(
0
,
I
)
\mathbf{\epsilon} \sim \mathcal{N}(\mathbf{0},\mathbf{I})
ϵ∼N(0,I),
t
∈
[
0
,
1
]
t \in [0,1]
t∈[0,1], 并且
γ
(
t
)
\gamma(t)
γ(t)s 是从 1 到 0 的单调递减函数(noise schedule)。扩散模型通过训练来学习反转前向corruptions的反向过程:
E
x
∼
p
d
a
t
a
,
t
∼
U
(
0
,
1
)
,
ϵ
∼
N
(
0
,
I
)
[
∣
∣
y
−
f
θ
(
x
t
;
c
,
t
)
∣
∣
]
,
(2)
\mathbb{E}_{\mathbf{x} ∼ p_{data}, t \sim \mathcal{U}(0,1), \mathbf{\epsilon} \sim \mathcal{N}(\mathbf{0},\mathbf{I})}[||\mathbf{y} - f_{\theta}(\mathbf{x}_t;\mathbf{c},t)||], \tag{2}
Ex∼pdata,t∼U(0,1),ϵ∼N(0,I)[∣∣y−fθ(xt;c,t)∣∣],(2)
其中 f θ f_θ fθ 是由神经网络参数化的降噪器模型, c \mathbf{c} c是条件信息,例如类标签或文本提示,目标 y \mathbf{y} y 可以是随机噪声 ϵ \mathbf{\epsilon} ϵ、降噪输入 x 0 \mathbf{x}_0 x0 或 v = 1 − γ ( t ) ϵ − γ ( t ) x 0 \mathbf{v} = \sqrt{1-\gamma(t)}\mathbf{\epsilon} - \sqrt{\gamma(t)}\mathbf{x}_0 v=1−γ(t)ϵ−γ(t)x0。 遵循 [34, 63],我们在所有实验中都使用 v 预测。
隐扩散模型(LDMs)
使用原始像素处理高分辨率图像和视频需要大量的计算资源。 为了解决这个问题,LDM 在 VQ-VAE 的低维隐空间上运行 [20, 72]。 VQ-VAE 包含编码器$ E(x)$ ,该编码器将输入视频 x ∈ R T × H × W × 3 x \in \mathbb{R}^{T ×H ×W ×3} x∈RT×H×W×3 编码为隐表示 z ∈ R t × h × w × c z ∈ \mathbb{R}^{t×h×w×c} z∈Rt×h×w×c。 编码器通过因子 f s = H / h = W / w f_s=H/h=W/w fs=H/h=W/w以及 f t = T / t f_t=T/t ft=T/t对视频进行下采样,其中 T = t = 1 T=t=1 T=t=1对应于使用图像自编码器。 与原始 VQ-VAE 的一个重要区别是缺乏量化嵌入的码本:扩散模型可以在连续的隐空间上运行。 解码器 D D D 被训练来根据 z z z 预测视频的重建 x ^ \hat{x} x^。 沿着 VQ-GAN [20]的思路 ,可以通过添加对抗性 [25] 和感知损失 [43, 86] 来进一步提高重建质量。
W.A.L.T
视觉Tokens学习
视频生成建模中的一个关键设计决策是隐空间表示的选择。 理想情况下,我们想要一个共享且统一的压缩视觉表示,可用于图像和视频的生成建模[74, 82]。 由于有标注视频数据[34](例如文本视频对)的稀缺,所以联合图像视频学习更可取,这就决定了统一表示很重要。 具体来说,给定视频序列 x ∈ R ( 1 + T ) × H × W × C x \in \mathbb{R}^{(1+T )×H ×W ×C} x∈R(1+T)×H×W×C ,我们的目标是学习执行时空压缩( 空间因子 f s = H / h = W / w f_s=H/h=W/w fs=H/h=W/w,时间因子 $f_t = T/t $)的低维表示 z ∈ R ( 1 + t ) × h × w × c z \in \mathbb{R}^{(1+t)×h×w×c} z∈R(1+t)×h×w×c。 为了实现视频和静态图像的统一表示,第一帧始终独立于视频的其余部分进行编码。 这使得静态图像 x ∈ R 1 × H × W × C x \in \mathbb{R}^{1×H ×W ×C} x∈R1×H×W×C可以被视为具有单帧的视频,即 z ∈ R 1 × h × w × c z \in \mathbb{R}^{1×h×w×c} z∈R1×h×w×c。
我们用MAGVIT-v2 tokenizer [82]的因果 3D CNN 编码器-解码器架构实例化这个设计。 通常,编码器-解码器由3D卷积层组成,无法独立处理第一帧[23, 81]。 这种限制源于以下事实: 大小为 ( k t , k h , k w ) (k_t , k_h , k_w ) (kt,kh,kw)的常规卷积核将在输入帧之前的 ⌊ k t − 1 2 ⌋ \lfloor \frac{k_t -1}{2} \rfloor ⌊2kt−1⌋ 帧和之后的 ⌊ k t 2 ⌋ \lfloor \frac{k_t}{2} \rfloor ⌊2kt⌋帧上运行。 因果 3D 卷积层解决了这个问题,因为卷积核仅对过去的 k t − 1 k_t − 1 kt−1帧进行操作。 这确保了每个帧的输出仅受前面帧的影响,使模型能够独立对第一帧进行tokenize。
在此阶段之后,我们模型的输入是一批潜在张量 z ∈ R ( 1 + t ) × h × w × c z \in \mathbb{R}^{(1+t)×h×w×c} z∈R(1+t)×h×w×c,表示单个视频或一堆 ( 1 + t 1 + t 1+t) 独立图像(图 2)。 与[82]不同,我们的隐表示是实值且无量化的。 在下面的部分中,我们描述我们的模型如何联合处理混合批次的图像和视频。

面向图像及视频生成的学习
Patchify
遵循原始的 ViT [18],我们通过将每个隐帧转换为不重叠的 h p × w p h_p ×w_p hp×wp patches序列来独立地“Patchify”每个隐帧,其中 h p = h / p h_p = h/p hp=h/p, w p = w / p w_p = w/p wp=w/p, p p p 是patch大小 。 我们使用可学习的位置嵌入[73],它是空间和时间位置嵌入的总和。 位置嵌入被添加到patches的线性投影[18]中。 请注意,对于图像,我们只需添加与第一个隐帧相对应的时间位置嵌入。
Window attention
完全由全局自注意力模块组成的 Transformer 模型会产生大量的计算和内存成本,尤其是对于视频任务。 为了提高效率以及联合处理图像和视频,我们基于两种类型的非重叠配置来计算窗口 [27, 73] 中的自注意力:空间(S)和时空(ST),参见图 2。
- 空间窗口 (SW) 注意力仅限于大小为 1 × h p × w p 1×h_p ×w_p 1×hp×wp 的隐帧内的所有tokens(第一个维度是时间)。 SW 对图像和视频中的空间关系进行建模。
- 时空窗口 (STW) 注意力被限制在大小为 ( 1 + t ) × h p ′ × h w ′ (1 + t) × h^′_p × h^′_w (1+t)×hp′×hw′ 的 3D 窗口内,对视频隐帧之间的时间关系进行建模。 对于图像,我们只需使用identity attention mask ,确保与图像帧latents对应的值嵌入按原样通过该层。 最后,除了绝对位置嵌入之外,我们还使用相对位置嵌入[49]。
我们的设计虽然概念上很简单,但实现了计算的高效率并能够对图像和视频数据集进行联合训练。 与基于帧级自编码器的方法相比[4,24,27],我们的方法不会受到闪烁artifacts的影响,而闪烁artifacts通常是由独立编码和解码视频帧造成的。 然而,与 Blattmann 等研究者的工作 [4]类似,我们还可以通过简单地交错 STW 层来利用带有Transformer主干的预训练图像 LDM。
条件生成
为了实现可控视频生成,除了以时间步 t t t 为条件之外,扩散模型通常还以附加条件信息 c \mathbf{c} c 为条件,例如类标签、自然语言、过去的帧或低分辨率视频。 在我们的Transformer主干中,我们采用了三种类型的条件机制,如下所述:
交叉注意力
除了窗口Transformer Blocks中的自注意力层之外,我们还添加了一个用于文本条件生成的交叉注意力层。 当仅在视频上训练模型时,交叉注意力层采用与自注意力层相同的窗口限制注意力,这意味着 S/ST 块将具有 SW/STW 交叉注意力层(图 2)。 然而,对于联合训练,我们仅使用 SW 交叉注意层。 对于交叉注意力,我们将输入信号(query)与条件信号(key、value)连接起来,因为我们的早期实验表明这可以提高性能。
AdaLN-LoRA
自适应归一化层是一系列生成和视觉合成模型的重要组成部分[16,19,44,52-54]。 引入自适应层归一化(adaptive layer normalization)的一个简单方法是为每个层
i
i
i 包含一个 MLP 层,用于回归条件参数向量
A
i
=
M
L
P
(
c
+
t
)
A^i = MLP(\mathbf{c} + \mathbf{t})
Ai=MLP(c+t),其中
A
i
=
c
o
n
c
a
t
(
γ
1
,
γ
2
,
β
1
,
β
2
,
α
1
,
α
2
)
A^i =concat(γ_1,γ_2,β_1, β_2,α_1,α_2)
Ai=concat(γ1,γ2,β1,β2,α1,α2),
A
i
∈
R
6
×
d
m
o
d
e
l
A^i \in \mathbb{R}^{6×d_{model}}
Ai∈R6×dmodel, 并且
c
∈
R
d
m
o
d
e
l
\mathbf{c} \in \mathbb{R}^{d_{model}}
c∈Rdmodel,
t
∈
R
d
m
o
d
e
l
\mathbf{t} \in \mathbb{R}^{d_{model}}
t∈Rdmodel是条件嵌入和时间步嵌入。 在Transformer Blocks中,
γ
γ
γ和
β
β
β分别缩放和移动多头注意力层和MLP层的输入,而
α
α
α则缩放多头注意力层和MLP层的输出。 这些附加 MLP 层的参数计数与层数成线性比例,并与模型的维度大小(
n
u
m
_
b
l
o
c
k
s
×
d
m
o
d
e
l
×
6
×
d
m
o
d
e
l
num\_blocks × d_{model} × 6 × d_{model}
num_blocks×dmodel×6×dmodel)成二次方。 例如,在具有
1
B
1B
1B 个参数的 ViT-g 模型中,MLP 层贡献了额外的
475
M
475M
475M 个参数。 受[40]的启发,我们提出了一个名为 AdaLN-LoRA 的简单解决方案,以减少模型参数。 对于每一层,我们将调节参数回归为
A
1
=
M
L
P
(
c
+
t
)
,
A
i
=
A
1
+
W
b
i
W
a
i
(
c
+
t
)
∀
i
≠
1
,
(3)
A^1 =MLP(\mathbf{c} + \mathbf{t}), \\ A^i =A^1 +W_b^iW_a^i(\mathbf{c} + \mathbf{t}) \ \ \ \forall i\neq1 ,\tag{3}
A1=MLP(c+t),Ai=A1+WbiWai(c+t) ∀i=1,(3)
其中
W
b
i
∈
R
d
m
o
d
e
l
×
r
W_b^i \in \mathbb{R}^{d_{model} \times r}
Wbi∈Rdmodel×r,
W
a
i
∈
R
r
×
(
6
×
d
m
o
d
e
l
)
W_a^i \in \mathbb{R}^{r \times(6×d_{model})}
Wai∈Rr×(6×dmodel)。 当
r
≪
d
m
o
d
e
l
r \ll d_{model}
r≪dmodel 时,这会显着减少可训练模型参数的数量。 例如,
r
=
2
r = 2
r=2 的 ViT-g 模型将 MLP 参数从
475
M
475M
475M 减少到
12
M
12M
12M。
Self-conditioning
除了以外部输入为条件之外,迭代生成算法还可以在推理过程中以自己先前生成的样本为条件[3,13,65]。 具体来说,陈等人 [13]修改扩散模型的训练过程,使得模型以一定的概率 p s c p_{sc} psc 首先生成样本 z ^ 0 = f θ ( z t ; 0 , c , t ) \hat{z}_0 = f_θ (\mathbf{z}_t ; \mathbf{0}, \mathbf{c}, t) z^0=fθ(zt;0,c,t),然后使用另一个前向传递在此初始样本上条件细化该估计 : f θ ( z t ; s t o p g r a d ( z ^ 0 ) , c , t ) f_θ (\mathbf{z}_t ; stopgrad(\hat{\mathbf{z}}_0 ), \mathbf{c}, t) fθ(zt;stopgrad(z^0),c,t)。 概率为 1 − p s c 1 − p_{sc} 1−psc 时,仅完成一次前向传递。 我们将模型估计与输入在通道维度上连接起来,发现这种简单的技术与 v v v 预测结合使用时效果很好。
自回归生成
为了通过自回归预测生成长视频,我们还在帧预测任务上联合训练我们的模型。 这是通过在训练期间以 p f p p_{fp} pfp 概率在过去的帧上为模型条件来实现的。 具体来说,该模型使用 c f p = c o n c a t ( m f p ∘ z t , m f p ) c_{fp} = concat(m_{fp} \circ \mathbf{z}_t , m_{fp}) cfp=concat(mfp∘zt,mfp) 作为条件,其中 m f p m_{fp} mfp 是二进制掩码。 二进制掩码指示用作条件的过往帧数量。 我们以 1 个隐帧(图像到视频生成)或 2 个隐帧(视频预测)为条件。 通过沿着noisy latent输入的通道维度连接,这种条件被集成到模型中。 在推理过程中,我们使用标准的无分类器指导,并以 c f p c_{fp} cfp 作为条件信号。
视频超分辨
使用单一模型生成高分辨率视频在计算上是令人望而却步的。 继[35]之后,我们使用级联方法,三个模型以递增的分辨率运行。 我们的base模型生成 128 × 128 分辨率的视频,随后通过两个超分辨率阶段进行两次上采样。 我们首先使用depth-to-space卷积运算对低分辨率输入 z l r z^{lr} zlr(视频或图像)进行空间升级。 请注意,与可获得ground-truth低分辨率输入的训练不同,推理依赖于前一阶段产生的隐特征(参见 teaching-force)。 为了减少这种差异并提高超分辨率阶段在处理低分辨率阶段产生的artifacts时的鲁棒性,我们使用噪声条件增强[35]。 具体来说,通过将噪声水平采样为 t s r ∼ U ( 0 , t m a x n o i s e ) t_{sr} \sim \mathcal{U}(0, t_{max_noise}) tsr∼U(0,tmaxnoise),根据 γ ( t ) γ(t) γ(t) 来添加噪声,并将其作为输入提供给我们的 AdaLN-LoRA 层。
长宽比精调
为了简化训练并利用具有不同长宽比的广泛数据源,我们使用方形长宽比训练我们的base阶段。 我们在数据子集上对base阶段进行微调,通过插值位置嵌入来生成宽高比为 9:16 的视频。
实验
在本节中,我们在多个任务上评估我们的方法:类条件图像和视频生成、帧预测和文本条件视频生成,并对不同的设计选择进行广泛的消融研究。 有关定性结果,请参见图 1、图 3、图 4 以及我们项目网站上的视频。 请参阅附录了解更多详细信息。


视觉生成
视频生成
我们考虑两个标准视频基准,用于类条件生成的 UCF-101 [70] 和用于具有 5 个条件帧的视频预测的 Kinetics-600 [9]。 我们使用 FVD [71] 作为我们的主要评估指标。 在这两个数据集上,W.A.L.T 显着优于所有先前的工作(表 1)。 与之前的视频扩散模型相比,我们用更少的模型参数实现了最先进的性能,并且需要 50 个 DDIM [68] 推理步骤。

图像生成
为了验证 W.A.L.T 在图像域上的建模能力,我们针对标准 ImageNet 类条件设置训练了 W.A.L.T 版本。 为了进行评估,我们遵循 ADM [16] 并报告根据 50 个 DDIM 步骤生成的 50K 样本计算得出的 FID [32] 和 Inception [64] 分数。 我们将(表 2)W.A.L.T 与最先进的 256 × 256 分辨率图像生成方法进行比较。 我们的模型优于之前的工作,不需要专门的schedules、卷积归纳偏差、改进的扩散损失和无分类器指导。 尽管 VDM++ [45] 的 FID 分数稍好,但该模型的参数明显更多(2B)。

消融研究 (Ablation Studies)
我们消融 W.A.L.T 以了解默认设置下各种设计决策的贡献:模型 L,patch size 1,
1
×
16
×
16
1 × 16 × 16
1×16×16 空间窗口,
5
×
8
×
8
5 × 8 × 8
5×8×8 时空窗口,
p
s
c
=
0.9
p_{sc} = 0.9
psc=0.9,
c
=
8
c = 8
c=8 以及
r
=
2
r = 2
r=2。

patch size
在利用基于 ViT[18] 的模型的各种计算机视觉任务中,较小的patch size p p p 已被证明可以持续增强性能 [8,18,28,84]。 同样,我们的研究结果还表明,减小patch size 可以提高性能(表 3a)。
窗口注意力
我们比较了具有完全自注意力的三种不同的 STW 窗口配置(表 3b)。 我们发现局部自注意力可以实现有竞争力(或更好)的性能,同时速度显著加快(高达 2 倍)并且需要更少的加速器内存。
自条件
在表 3c 中,我们研究了改变自条件率 p s c p_{sc} psc 对生成质量的影响。 我们注意到一个明显的趋势:将自条件率从 0.0(无自条件)增加到 0.9,FVD 分数大幅提高(44%)。
AdaLN-LoRA
扩散模型中的一个重要设计决策是条件机制。 我们研究了在我们提出的 AdaLN-LoRA 层中增加瓶颈维度
r
r
r 的影响(表 3d)。 该超参数提供了一种在模型参数数量和生成性能之间进行权衡的灵活方法。 如表 3d 所示,增加
r
r
r 可以提高性能,但也会增加模型参数。 这凸显了一个重要的模型设计问题:给定固定的参数预算,我们应该如何分配参数——要么使用单独的 AdaLN 层,要么在使用共享 AdaLN-LoRA 层的同时增加基本模型参数? 我们通过比较两种模型配置在表 4 中对此进行探索:具有单独 AdaLN 层的 W.A.L.T-L 和具有 AdaLN-LoRA 且$ r = 2$ 的 W.A.L.T-XL。虽然两种配置产生相似的 FVD 和 Inception 分数,但 W.A.L.T-XL 实现了较低的最终损失 值,表明为base模型分配更多参数并在加速器内存限制内选择适当的
r
r
r 值的优势。

Noise schedule
常见的隐Noise schedule [61]通常不能确保最终时间步长处的零信噪比(SNR),即在 t = 1 t = 1 t=1时, γ ( t ) > 0 γ(t) > 0 γ(t)>0 。这会导致训练和推理阶段的不匹配。 在推理过程中,模型预计从纯高斯噪声开始,而在训练过程中,在 t = 1 t = 1 t=1 时,模型仍然可以访问少量信号信息。 这对于视频生成尤其有害,因为视频具有很高的时间冗余。 即使 t = 1 t = 1 t=1 时的最小信息泄漏也可以向模型揭示大量信息。 通过强制执行zero terminal SNR [48] 来解决这种不匹配问题,可显著提高性能(表 3e)。 请注意,这种方法最初是为了解决图像生成中的过度曝光问题而提出的,但我们发现它对于视频生成也很有效。
自编码器
最后,我们在模型的第一阶段研究了一个关键但经常被忽视的超参数:自编码器latent z z z 的通道维度 c c c。 如表 3f 所示,增加 c c c 可以显着提高重建质量(较低的 rFVD),同时保持相同的空间 f s f_s fs 和时间压缩 f t f_t ft 比率。 根据经验,我们发现较低和较高的 c c c 值都会导致生成过程中的 FVD 得分较差,其中 c = 8 c = 8 c=8 的最佳点在我们评估的大多数数据集和任务中都表现良好。 我们还在通过Transformer 处理 latents 之前对其进行归一化,这进一步提高了性能。
在我们的Transformer模型中,我们使用query-key normalization [14],因为它有助于稳定较大模型的训练。 最后,我们注意到,正如消融研究所示,我们的一些默认设置并不是最佳的。 早期选择这些默认值是为了它们在数据集上的稳健性,尽管进一步调整可能会提高性能。
文本-视频生成
我们在文本-图像和文本-视频对上联合训练文本到视频的 W.A.L.T(第 4.2 节)。 我们使用来自公共互联网和内部来源的~970M 文本-图像对和~89M 文本-视频对的数据集。 我们以分辨率 17 × 128 × 128(3B 参数)训练基本模型,并训练两个 2× 级联超分辨率模型,分别为 17 × 128 × 224 → 17×256×448(L,1.3B,p = 2) 和 17×256×448 → 17×512×896(L,419M,p = 2)。 我们对 9:16 宽高比的base阶段进行微调,以生成分辨率为 128 × 224 的视频。我们对所有文本到视频结果使用无分类器指导。
定量评价
科学地评估文本条件视频生成系统仍然是一个重大挑战,部分原因是缺乏标准化的训练数据集和基准。 到目前为止,我们的实验和分析主要集中在标准学术基准上,这些基准使用相同的训练数据来确保受控和公平的比较。 尽管如此,为了与之前的文本到视频工作进行比较,我们还在表 5 中的零样本评估协议中报告了 UCF-101 数据集的结果[24,37,66]。 参见补充材料。

联合训练。 我们框架的主要优势是它能够同时在图像和视频数据集上进行训练。 在表 5 中,我们消除了这种联合训练方法的影响。 具体来说,我们使用第 5.2 节中指定的默认设置训练了两个版本的 W.A.L.T-L(每个版本有 419M 参数)模型。 我们发现联合训练可以显著改善这两个指标。 我们的结果与 Ho 等人的研究结果一致 [36],该工作展示了使用 U-Net 主干网络联合训练基于像素的视频扩散模型的好处。
Scaling。 Transformer 以其在许多任务中有效扩展的能力而闻名 [5,14,55]。 在表 5 中,我们展示了视频扩散Transformer模型在Scaling方面的好处。Scaling base模型大小可以显着改进这两个指标。 然而,值得注意的是,我们的base模型比领先的文本到视频系统要小得多。 例如,Ho等人 [34]训练有5.7B参数的基础模型。 因此,我们相信进一步Scaling 我们的模型是未来工作的重要方向。
与之前的工作进行比较。 在表 5 中,我们展示了各种文本到视频生成方法的系统级比较。 我们的结果是有希望的; 我们在 FVD 指标方面超越了之前的所有工作。 就 IS 而言,我们的表现具有竞争力,优于除 PYoCo 之外的所有其他工作 [24]。 对于这种差异的一个可能的解释可能是 PYoCo 使用了更强的文本嵌入。 具体来说,他们同时使用 CLIP [57] 和 T5-XXL [60] 编码器,而我们仅使用 T5-XL [60] 文本编码器。
定性结果
正如第 4.4 节中提到的,我们在以 1 或 2 个隐帧为条件的帧预测任务上联合训练我们的模型。 因此,我们的模型可用于动画图像(图像到视频)并生成具有一致相机运动的较长视频(图 4)。 请参阅我们项目网站上的视频。
结论
在这项工作中,我们介绍了 W.A.L.T,这是一种简单、可扩展且高效的基于Transformer的隐视频扩散模型框架。 我们展示了使用带有窗口注意力的 Transformer 主干来生成图像和视频的最先进结果。 我们还在图像和视频数据集上联合训练了三个 W.A.L.T 模型的级联,以根据自然语言描述合成高分辨率、时间一致的真实感视频。 虽然生成模型最近在图像方面取得了巨大进步,但视频生成方面的进展却大大滞后了。 我们希望scaling我们的图像和视频生成统一框架将有助于缩小这一差距。