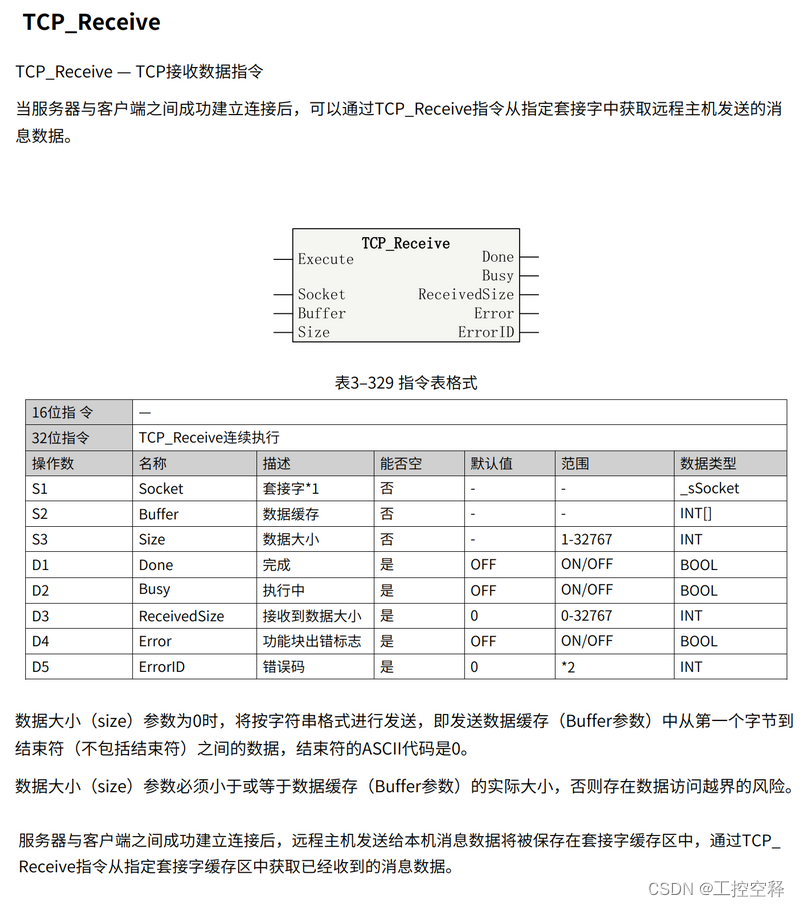
Hutool树结构工具-TreeUtil快速构建树形结构的两种方式 + 数据排序
- 一、业务场景
- 二、Hutool官网树结构工具
- 2.1 介绍
- 2.2 使用
- 2.2.1 定义结构
- 2.2.2 构建Tree
- 2.2.3 自定义字段名
- 2.3 说明
- 三、具体的使用场景
- 3.1 实现的效果
- 3.2 业务代码
- 3.3 实现自定义字段的排序
- 四、踩过的坑
- 4.1 坑1:weight权重属性 类型异常
- 4.2 坑2:weight权重属性 字符串只能根据首字母排序
一、业务场景
Springboot + vue 开发;
想实现树结构业务,并在树结构节点有业务功能,比如根据树结构节点排序、节点的状态显示等功能。
在开发过程中,必定会遇到树形结构的数据,一般都是后端直接从库里查询出来然后自定义方法去封装成树形树形返回给前端。这里就会用到递归、封装再返回,非常麻烦。后来发现 HutoolUtil 中有个工具类 TreeUtil 可以完成本次项目的需求,非常便捷,使用方式很简单,本次就使用它来实现。
二、Hutool官网树结构工具
如果想查询Hutool官网最新的树结构工具,请各位看官移步至传送门:官网树结构工具-TreeUtil。
以下是当时使用此 TreeUtil 时的官网介绍。
2.1 介绍
考虑到菜单等需求的普遍性,有用户提交了一个扩展性极好的树状结构实现。这种树状结构可以根据配置文件灵活的定义节点之间的关系,也能很好的兼容关系数据库中数据。实现 关系型数据库数据 <-> Tree <-> JSON 树状结构中最大的问题就是关系问题,在数据库中,每条数据通过某个字段关联自己的父节点,每个业务中这个字段的名字都不同,如何解决这个问题呢?
PR的提供者提供了一种解决思路:自定义字段名,节点不再是一个bean,而是一个map,实现灵活的字段名定义。
2.2 使用
2.2.1 定义结构
我们假设要构建一个菜单,可以实现系统管理和店铺管理,菜单的样子如下:
系统管理
|- 用户管理
|- 添加用户
店铺管理
|- 商品管理
|- 添加商品
那这种结构如何保存在数据库中呢?一般是这样的:
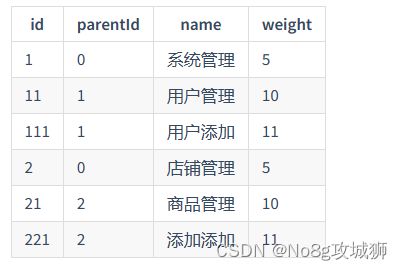
2.2.2 构建Tree
// 构建node列表
List<TreeNode<String>> nodeList = CollUtil.newArrayList();
nodeList.add(new TreeNode<>("1", "0", "系统管理", 5));
nodeList.add(new TreeNode<>("11", "1", "用户管理", 222222));
nodeList.add(new TreeNode<>("111", "11", "用户添加", 0));
nodeList.add(new TreeNode<>("2", "0", "店铺管理", 1));
nodeList.add(new TreeNode<>("21", "2", "商品管理", 44));
nodeList.add(new TreeNode<>("221", "2", "商品管理2", 2));
TreeNode表示一个抽象的节点,也表示数据库中一行数据。 如果有其它数据,可以调用setExtra添加扩展字段。
// 0表示最顶层的id是0
List<Tree<String>> treeList = TreeUtil.build(nodeList, "0");
因为两个Tree是平级的,再没有上层节点,因此为List。
2.2.3 自定义字段名
//配置
TreeNodeConfig treeNodeConfig = new TreeNodeConfig();
// 自定义属性名 都要默认值的
treeNodeConfig.setWeightKey("order");
treeNodeConfig.setIdKey("rid");
// 最大递归深度
treeNodeConfig.setDeep(3);
//转换器
List<Tree<String>> treeNodes = TreeUtil.build(nodeList, "0", treeNodeConfig,
(treeNode, tree) -> {
tree.setId(treeNode.getId());
tree.setParentId(treeNode.getParentId());
tree.setWeight(treeNode.getWeight());
tree.setName(treeNode.getName());
// 扩展属性 ...
tree.putExtra("extraField", 666);
tree.putExtra("other", new Object());
});
通过TreeNodeConfig我们可以自定义节点的名称、关系节点id名称,这样就可以和不同的数据库做对应。
2.3 说明
官网上描述的是最通用和最简单的使用方法,但是在实际开发中,我们的业务场景都会比实际的复杂很多,所以结合业务场景实现此功能。
三、具体的使用场景
3.1 实现的效果
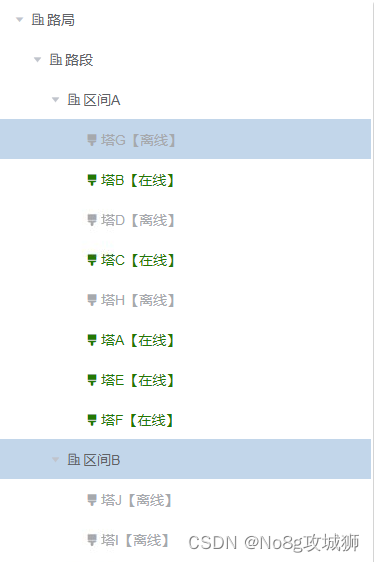
3.2 业务代码
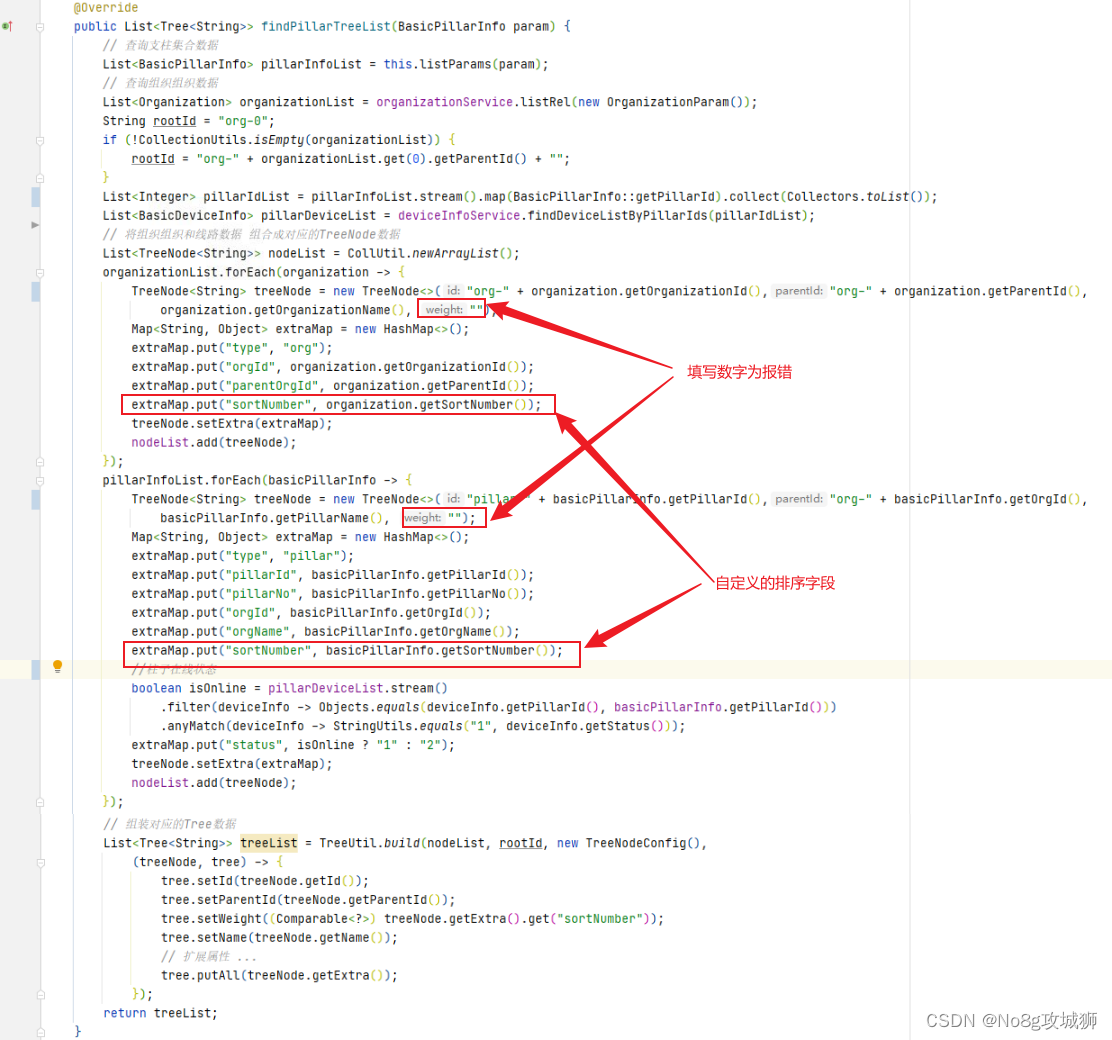
3.3 实现自定义字段的排序
使用官网推荐的方法排序
TreeNodeConfig treeNodeConfig = new TreeNodeConfig();
// 自定义属性名 都要默认值的
treeNodeConfig.setWeightKey("order");
然后在转换器中取出此自定义的排序字段时,无论怎么配置和设置都是无法使用自定义的字段。
在网上搜索的自定义方法都是与官网上一样,通过 TreeNodeConfig 配置类设置,然后在转换器 treeNode 类中获取。在我所使用的项目中始终不生效。所以只能靠自己解决了。
通过自己的摸索和研究,如3.2中的代码通过拓展字段可以实现。
然后在转换器中,通过拓展字段把自定义的排序字段取出然后再赋值给 Tree 类中的 weight 属性即可。
四、踩过的坑
4.1 坑1:weight权重属性 类型异常
官网中的weight权重属性不能使用 int 类型的字段,项目启动正常,调用接口时会报类型转换异常错误。
4.2 坑2:weight权重属性 字符串只能根据首字母排序
如果此字段设置为字符串类型的排序字段时,TreeUtil 只会根据首字母排序,限制了我们使用的情况,所以此种情况也不符合我们的期望。
本文完结!