为啥我得去考个阿里云大数据工程ACP证书?
首先得声明,这不是因为我对阿里有多痴迷,也不是因为我想把我的简历装饰得花里胡哨。实际上,这更像是一场自我挑战的游戏。我就是一根筋,当时公司要求考阿里云大数据工程师认证,考试费可以报销,我报了,没考过。想想尼玛,不就是个考试嘛,不信,还整不倒你。小样!
标题阿里云大数据工程ACP难不难?
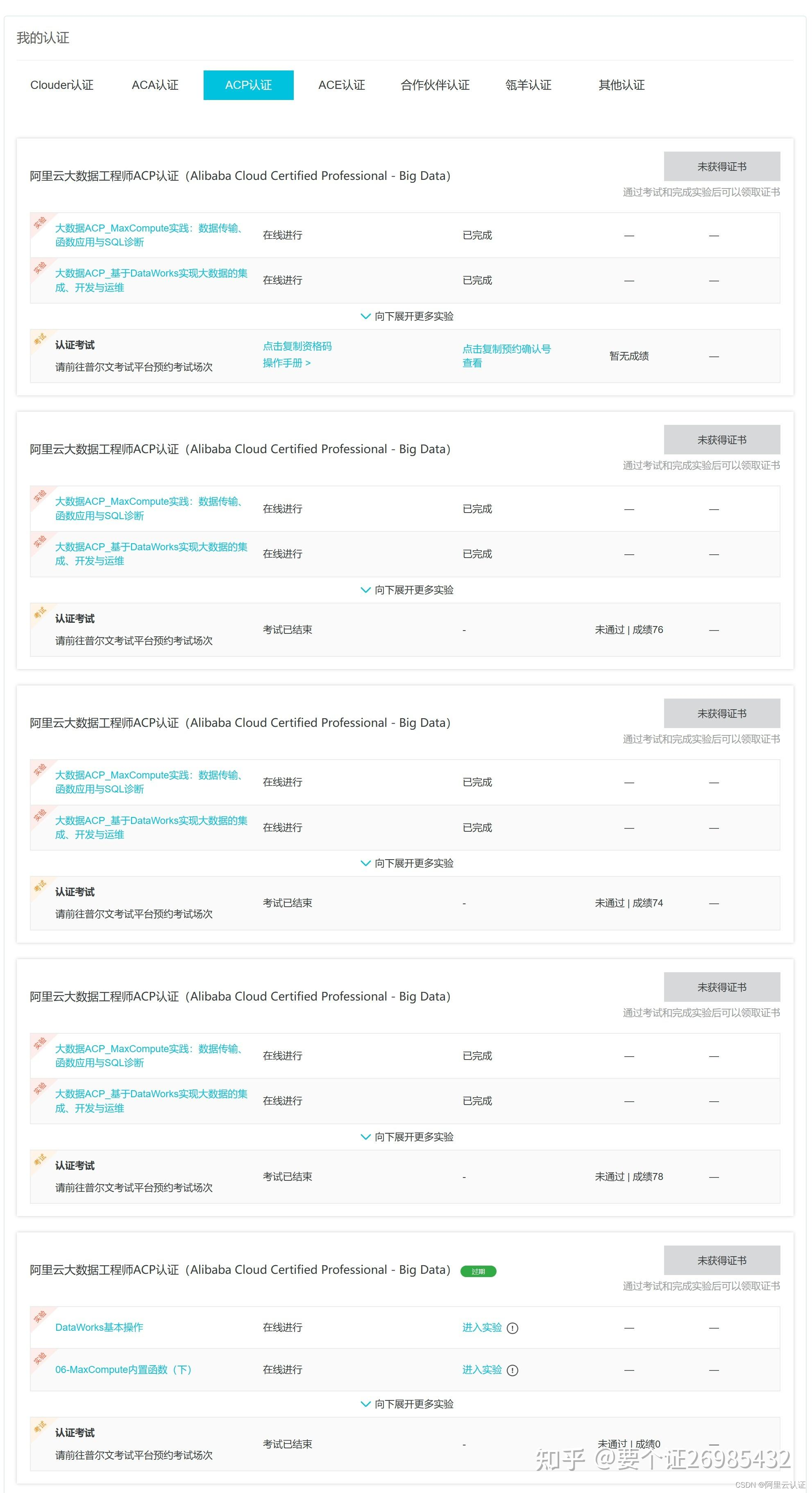
讲真,这东西难度还是有的,不然我也不会特地来聊这个。考试通过率低得像北京的房价一样高,而且题库变化无常,仿佛每天都有新鲜事。你以为你掌握了所有的题目,然后走进考场,发现“呵呵,这都是啥?”答案不稳定得就像我们这代人的情感状态。考了好几次,感觉题都见过,也是按题库里答案填的,但是分数就在70几分票,我滴个去。
备考经历
由于我是一个忙碌的现代人,没时间坐下来刷视频教程。我主要是靠官网的PPT和做题来学习。但是,题库里的答案啊,那准确率真是让人头疼,就像网购的东西和图片不符一样。所以我就动用了我的小伙伴们:chatgpt,通义千问,Copilot,还有老朋友Google搜索。每当我遇到一个不确定的答案,就像侦探一样四处寻找线索。花了好几周时间,我对题库里题,一题一题核对,标上确定的答案,标注的过程,自己也在学习,加强印象
现在呢,我可以自豪地说,我的答案通过率和准备率都超高。就像是在王者荣耀里,我已经准备好升星了
终于升级
今天约了考试,进入答题界面,做下10几题,感觉稳了,跟嘴里嚼了薄荷一样,舒畅,果真,试卷一提交,辛苦没白费,87分,稳稳通过

看看你会几道
单选
406.单选题
关于Hologres产品架构,Hologres采用存储计算分离架构,其中计算层中的存储引擎SE(Storage Engine),主要用于
A.SQL的认证、解析、优化
B.降低存储成本
C.加速数据湖探索
D.管理和处理数据,包括创建、查询、更新和删除(简称 CRUD)数据等
答案:D
407.单选题
在大数据开发治理平台Dataworks数据同步任务中,可以从数据抽取和加载两个方面进行控制。数据抽取控制即数据抽职的过液条件,而数据加载控制即数据写入时的规则。现在需将云数据库RDS MVSQL版的增量数据同步至大数据计算服MaxCompute的非分区表中,加载时清理规则可以配置为
A.同步前清空本表部分数据
B.同步前清空本表全部数据
C.写入前清理已有数据
D.写入前保留已有数据
答案:D
408.单选题
大数据开发治理平台DataWorks中,按天调度的周期性任务task1的定时调度时间设置为2点0分,按天调度的周期性任务task2的定时调度时间设置为0点0分,task1依赖属性的上游任务设置为task2,关于task1以下说法正确的是?
A.每天0点0分开始执行
B.每天只要task2当前周期执行状态为成功,则task1马上开始执行
C.每天2点0分后task2当前周期执行状态为成功,则task1可以开始执行
D.每天2点0分一定开始执行
答案:C
409.单选题
大数据计算服务MaxCompute中的地区维表 dim_region 共三个字段,结构如下 region_id string region_name stringregion desc string inset date datetime 开发人员做数据探查时创建了一张关于地区的临时表 tmp_region,语句如,create table tmp region( reaion id strina. reaion desc strina. region name strina. insert date datetime):dim_region 中的数据导入 tmp_region 中; insert overwrite table tmp_region select* from dim _region; 则对此执行结果描述正确的是
A.数据会根据字段名称对应上,逻辑上正确
B.语句可以执行,但是region_name和region_desc的内容会次序颠倒
C.在SQL语句提交阶段语义分析时会报错
D.两张表字段顺序不一样,会执行出错
答案:B
410.单选题
出于业务需要,要把云数据库RDS中的某张表的数据同步到大数据计算服务MaxCompute的某张表中去,希望通过大数据开发治理平台DataWorks的同步任务来实现,以下关于实现流程的说法正确的是
A.拥有开发角色的成员先配置RDS数据源,然后创建MaxCompute表,再创建、配置数据同步任务
B.拥有项目管理员角色的成员先配置RDS数据源,然后拥有运维角色的成员创建MaxCompute表,再创建、配置数据同步任务
C.拥有开发角色的成员先配置RDS数据源,然后拥有运维角色的成员创建MaxCompute表,再创建、配置数据同步任务
D.拥有项目管理员角色的成员先配置RDS数据源,然后拥有开发角色的成员创建MaxCompute表,再创建、配置数据同步任务
答案:D
411.单选题
大数据计算服务MaxCompute的开发人员在做数据探查时,想要从nginx日志表 nginx_access _log 中取10条记录,可以通过实现。
A.select * from nginx_access_log order by rownum limit 10;
B. select * from nginx_access_log limit 10;
C.select * from nginx access log where rownum<=10
D.select top 10 * from nginx access log;
答案:B
412.单选题
分布式文件系统可以有效的解决大数据存储和管理的难题,阿里云飞天平台中哪个系统提供了这样的功能?
A.盘古
B.大禹
C.女娲
D.伏羲
答案:A
413.单选题
关于阿里云机器学习平台PAI中的组件读数据表与写数据表的说法正确的是
A.写数据组件可以把数据直接写入MaxCompute和RDS MySQL版中
B.两个组件都是只能读写MaxCompute
C.读数据组件如果配置了RDS MySQL版中的表,可以自动感知表结构的变化,如果配置了MaxCompute中的表,则无法感知数据表结构的变化,一旦表结构发生变化,需要重新配置读数据组件
D.读数据组件可以读取MaxCompute和OSS中的数据
答案:B
414.单选题
了解了阿里云Elasticsearch的使用方法后,可以执行如下命令,删除对应索引,避免浪费资源。对于执行删除索引语句DELETE /product info成功后,返回的结果应该是哪个?
A.[“acknowledged” : true }
B.["acknowledg"false }
C.“acknowledg”:true }
D.[“acknowledged” false }
答案:A
415.单选题
Elasticsearch需要对查询性能进行优化。下列哪一个属于Elasticsearch查询优化方案?
A.配置合适的分词器
B.设计mapping配置合适的字段类型
C.通过多进程/线程发送数据
D.配置事务日志参数
答案:A
解析:
2023-12-11专家更新为A
416.单选题
某公司搜集了客户信息、购买历史等数据,想根据其内在规律将客户分为几类,类别个数可以根据数实际情况浮动,每类客户有某些共同特性。上述场景属于___
A.关联分析
B. 聚类分析
C. 时序分析
D. 分类分析
答案:B
单选题
在大数据计算服务MaxCompute的某表中的数据有日期类型(datetime),这批数据每天需要从文本加载到表中,下列日期格式中正确的是
A.202201010000
B.2022-01-01 00:00:00
C.2022/01/01:00:00:00
D.20220101
答案:B
418.单选题
在Hologres中,表是数据存储单元,___指数据存在Hologres中的表,表中的数据类型可以是Hologres支持的任意种类型。
A.实例(Instance)
B.分区表
C.外部表
D.内部表
答案:D
419.单选题
数据质量使用内置模板规则进行规则定义时,以下不支持的数据源监控规则的是?
A.MaxCompute
B.Hologres
C.EMR (E-MapReduce)
D.Oss
答案:D
解析:
使用限制
按模板配置目前支持配置EMR(E-MapReduce)、Hologres、AnalyticDB for PostgreSQL、MaxCompute数据源的监控规则。
420.单选题
阿里云实时计算Flink可以手动配置触发报警的条件内容,配置完成后会在每次间隔指定的时间,对指定的指标值与阀值进行计算比较,下列哪个指标不是阿里云实时计算Flink支持的?
A.restart count in 1 minute
B.attack query in 1 minute
C.emit delay
D.checkpoint count in 5 minutes
答案:B
421.单选题
DataWorks的数据地图功能可以实现对数据的统一管理和血缘的跟踪。以下描述错误的是?
A.在数据地图里可以查看表的基础元模型、字段名称、字段类型等 Schema 详情、数据的产出情况,也可以进行表数据的修改
B.用户可以查看表和字段的上下游血缘关系
C.数据地图提供了全局检索能力,可以让用户通过表、字段、描述等多个元素来快速检索表
D.数据地图提供元数据采集和数据目录构建能力
答案:A
422.单选题
Elasticsearch查询流程通常包括以下几个环节
1.在Query阶段时,查询会广播到索引中每一个分片拷贝(主分片或者副本分片),每个分片在本地执 行搜索并构建一个匹配文档的大小为 from +size 的优先队列。
2.每个分片返回各自优先队列中所有文档的ID和排序值给协调节点,协调节点合并这些值到自己的优 先队列中来产生一个全局排序后的结果列表。
3在Fetch取回阶段,协调节点辨别出哪些文档需要被职回,并向相关分片(primary或replica分片随机选择)提交多个GET请求,接着返回文档给协调节点。一旦所有的文档都被取回了,协调节点返回结果给客户端下列排序中,顺序正确的是哪个?
A.132
B.312
C.321
D.123
答案:D
423.单选题
Elasticsearch进行检索的时候,为了过减不必要的分片,加快查询速度,通常会设定路由字段,下列关于确定条数据是在哪一个分片的描述正确的是哪个?
A.shard id = hash(_routing) % id primary_shards
B.num primary_shards = hash( routing) % shard num
C.shard num = hash( routing)% num primary shards
D.shard num = MD5( routing) % num_primary_shards
答案:C
424.单选题
大数据计算服务MaxCompute中的日志表LOG是一张分区表,分区键是dt每天产生一个分区用于存储当天新增的数据数据是通过tunnel接口上传,运维人员需要在每天上传数据之前生成好当天的分区,假设当前日期是20220301,语句可以创建合适的分区。
A.alter table log add partition(dt='20220301)
B.insert into table log partition(dt=20220301)
C.insert overwrite table log partition(dt='20220301)
D.add partition log (dt=20220301)
答案:A
425.单选题
下列关于Hologres SQL命令的表述中,正确的是
A.Hologres可以对外部表执行TRUNCATE语句
B.INSERTONCONFLICT的执行开销要大于UPDATE语句
C.INSERT ON CONFLICT语句与INSERT命令功能相同
D.TRUNCATE语句用于清空目标表
答案:D
426.单选题
对于阿里云实时计算上下游存储,一般广泛采用___作为流式数据的数据源表和结果表
A.Kafka
B. MongoDB
C.Redis
D.Elasticsearch
答案:A
427.单选题
云原生开源大数据平台E-MapReduce(简称EMR),是运行在阿里云平台上的一种大数据处理的系统解决方案。其中属于自研的计算引擎产品有?
A.Flink
B.Spark
C.JindoFS
D.Shuffle Service
答案:D
428.单选题
连续查询是会一直运行,每当有新的数据到来时,它会持续地增量地更新你的计算结果。关于连续查询的描述正确的是哪?
A.连续查询无法串起整个数据流图
B.每当有新的数据到来时,他会持续地增量地更新你的计算结果
C.得到一次查询结果就结束本次查询
D.连续查询的结果也是一个静态表
答案:B
429.多选
长尾优化的措施包括哪些?
A.通过 skewJoin hint 避免热值倾斜
B.大小表使用map join
C.将数据划分为有热键和非热键的分区,合并处理两个分区的结果
D.赋予NULL值一个新值
答案:ABC
430.多选
Quick Bl是一款全场景消费式的BI产品,服务于有数据化转型和提升智能决策和分析能力诉求的企业。以下哪些选项是Quick BI产品优势?
A.企业级安全管控
B.千亿级数据秒级处理
C.丰富的集成实践
D.移动专属和协同
E.权威认证的可视化
答案:ACDE
431.多选
对于大数据计算服务MaxCompute内置绝对值函数abs 描述正确的有
A.当输入参数是bigint时,返回值是bigint类型
B.当输入参数是double时,返回值是double类型
C.输入类型是boolean则返回值是True
D. 当输入参数是string类型时,一定会导致异常
答案:AB
432.多选
数据质量使用自定义SQL规则,采样可以支持方式
A.count/table count
B.count
C.avg
D. table count
答案:ABD
解析:2023-12-11专家更新为ABD
433.多选
目前开源界形成了三大开源技术流派,其共性特点是要支持流批处理、数据更新、事务、可扩展源数据、多种存储引擎、多种计算引擎等能力,补齐了大数据技术栈之前的短板。这三大流派是?
A.Presto
B.Icebreg
C.Hudi
D.Delta Lake
答案:BCD
434.多选题
数据安全平台的安全中心提供的数据访问控制功能,方便用户以可视化的方式_相关权限,查看审批流程并跟进审批进度,进行权限的管控。
A.修改
B.申请
C.审批
D.审计
答案:BCD
435.多选题
Hologres扩展函数中,计算行为转换率的流量分析函数是____,提供单表固定维度列的预聚合能力的聚合函数是____
A.漏斗分析函数和留存函数
B.聚合视图
C.APPROX COUNT DISTINCT
D.明细圈人函数
答案:AC
436.多选
Hologres 执行引擎侧重优化高并发低延迟的实时查询,其背后主要是基于以下哪些特点?
A.分布式执行模型
B.端到端的全异步处理框架
C.对所有查询进行了深度优化
D.向量化和列处理
答案:ABD
解析:
437.多选
在Elasticsearch写入优化方案中可以通过设置合理的分片数和副本数。下列关于此种方案描述正确的有哪些?
A.写多读少场景下,建议增加索引副本数
B.通常场景下,ES的索引分片数不可以动态修改,索引副本数可以动态修改。
C.读多写少场景下,建议增加索引副本数
D.写多读少场景下,建议增加索引主分片数
答案:BC
438.多选
Maxcompute SQL适用的场景是下列哪个选项?
A.高实时性
B.海量数据
C.实时性不高
D.离线批量计算
答案:BCD
439.多选
大数据计算服务MaxCompute中,表 order lotery 是彩票销售表,order fashion 是女装销售表,order 是汇总的销售表,三张表结构相同,都是非分区表,现在需要把 order lottery和order fashion 表汇总到 order 表中,且汇总前清空表order中的数据,可以采用以下哪些方式?
A.insert overwrite table order select * from (order_lottery, order_fashion):
B.insert overwrite table order select * from order_lottery and order_fashion;
C.insert overwrite table order select * from order lottery,insert into table order select * from order-fashion;
D.insert overwrite table order select * from (select from order lottery union al select * from order-fashion)sub.
答案:AD
解析:
2023-12-11专家更新为AD
440.多选
大数据开发治理平台DataWorks中,任务task1是按天调度的周期任务,task1生成分区表table1,该表每次执行生成的分区(分区名ds)取前一天日期的年月日(格式为yyyymmdd),要使用调度系统提供的时间参数定义table1的分区使得task1每次调度运行时自动替换时间值,task1应该如何配置?
A.task1代码中table1的分区ds=S{bizdate}
B.task1的代码中table1的分区ds=Sfvar},task1的参数配置:var=S[yyyymmdd]
C.task1的代码中table1的分区ds=Sva,task1的参数配置:var=S[yyyymmdd-1]
D.task1的代码中table1的分区ds=S{va,task1的参数配置,var=Sbizdate
答案:AC
解析:
2023-12-11专家更新为AC
441.单选题
大数据计算服务MaxCompute中,用户登录表 user login 的建表语句如下 create tablelogin_date datetime, login ip string)表中包含了近3个月的用户登录信息,为了user login( user id string.统计每天的用户登录次数,可以用实现。
A.select datetrunc(login date hh’), count() from user login group by datetrunc(login date "hh’);
B.select datetrunc(login_date,‘mm’), count() from user_login group by datetrunc(login_date,‘mm’);
C.select datetrunc(login_date,dd’), count(*) from user_login group by datetrunc(login _date’dd’);
D.select datetrunc(login date,yyyy’), count(") from user login group by datetrunc(login-date,yyyy);
答案:C
442.单选题
数据湖对比Lakehouse,下列哪些描述是不正确的?
A.国内市场对于云上统一存储、存算分离接受度高
B.阿里云提供EMR+OSS+DLF+DW产品矩阵,形成云原生数据湖解决方案
C.头部互联网公司大量使用Lakehouse
D.Lakehouse现阶段已经是成熟的解决方案
答案:D
443.单选题
阿里云Elasticsearch致力于打造基于开源生态的、低成本、场景化的云上Elasticsearch解决方案。与自建集群对比,阿里云Elasticsearch能力优势描述正确的是哪个?
A.阿里云Elasticsearch深度定制增强内核引擎,读写性能强大,自建Elasticsearch需自行保障,技术实现难度大
B.阿里云Elasticsearch和自建Elasticsearch均具有x-Pack高级商业特性,且免费使用
C.阿里云Elasticsearch和自建Elasticsearch均支持一键升级集群版本,不需要迁移数据
D.阿里云Elasticsearch和自建Elasticsearch均支持数据自动备份
答案:A
444.单选题
为了提高执行性能,在处理数据量较多时,Elasticsearch可采用批量操作,以下关于批量操作语法描述正确的是哪个?
A.构成为index/create/delete/update 增删改查,其中index和create都代表创建索引的意思,区别在于如果索引库中已经存在该id的索引,使用index会报错,create会覆盖
B.每一个操作都由两行构成,第一行代表数据本身,第二行代表元数据信息
C.通过 bulk批量操作 Elasticsearch文档,高并发写入场景,推荐每批量写入5-15MB数据
D.Elasticsearch不支持批量操作
答案:C
445.单选题
实时计算SQL支持使用STATEMENT SET语法将多个CREATE TABLE AS (CTAS)语作为一个作业一起提交并支持对Source节点的合并复用,降低对数据源的压力。关于CREATE TABLEAS(CTAS)语描述正确的是哪个?
A.执行CREATE TABLEAS(CTAS)语法前,不需要先注册目标端的Catalog
B.通过CREATE TABLEAS(CTAS)语句,在实时同步数据的同时,还能实时将下游表结构的变更同步到上游表
C.多CREATE TABLEAS(CTAS)语句中,支持使用STATEMENT SET语法将多个CREATE TABLEAS(CTAS)语句作为一个作业一起提交
D.CREATE TABLEAS(CTAS)支持进行作业调试
答案:C
446.单选题
DataWorks中,运维中心的“任务管理视图”以___的方式显示调度任务之间的依赖关系和运行约束。
A.平衡树
B.DAG图
C.二叉树
D.双向列表
答案:B
447.单选题
在Elasticsearch写入优化中,_可以设置translog策略为异步
A.index.translog.flush_threshold size:1024mb
B.index.translogdurability:sync
C.index.translogdurability.async
D.indextranslogsyncinterval:120s
答案:C
448.单选题
数据可视化分析平台Quick BI中的___是通过菜单形式组织的仪表板的集合,可以制作复杂的带导航菜单的专题类分析。
A.工作表
B.iFrame
C.仪表板
D.数据门户
答案:D
449.单选题
大数据开发治理平台DataWorks中,SQL任务task1是按天调度的周期性调度任务,每天执行一次,每次执行生成表table1的一个分区。分区ds值取前一天的日期(格式yyyy/mm/dd),要使用调度系统提供的时间参数定义table1的分区使得task1每次调度运行时自动替换时间值,task1应该___
A.task1需要进行参数配置,引入新变量var=
[
y
y
y
y
/
m
m
/
d
d
]
,同时代码中
t
a
b
l
e
1
的分区赋值为
:
d
s
=
[yyyy/mm/dd],同时代码中table1的分区赋值为:ds=
[yyyy/mm/dd],同时代码中table1的分区赋值为:ds={var}
B.task1需要进行参数配置,引入新变量var=
[
y
y
y
y
/
m
m
/
d
d
−
1
]
,同时代码中
t
a
b
l
e
1
的分区赋值为
:
d
s
=
[yyyy/mm/dd-1],同时代码中table1的分区赋值为: ds=
[yyyy/mm/dd−1],同时代码中table1的分区赋值为:ds={var}
C.task1代码中table1的分区ds =
b
d
p
.
s
y
s
t
e
m
.
b
i
z
d
a
t
e
D
.
t
a
s
k
1
代码中
t
a
b
l
e
1
的分区
d
s
=
{bdp.system.bizdate} D.task1代码中table1的分区ds=
bdp.system.bizdateD.task1代码中table1的分区ds={bdp.system.cyctime}
答案:C
450.单选题
企业在建设大数据平台时,可以选择机房自建或者使用云服务,如阿里云开源大数据平台E-MapReduce。和使用云上服务相比,机房自建的方式有哪些痛点?
A.存储计算分离,计算耗时更久
B.资源固定,业务高速增长,硬件无法快速采购扩容
C.组件版本升级复杂,耗时长
D.需要专业运维人员,运维相对复杂
答案:B
451.单选题
在进行资源配置时,建议Source节点并发度和分区数成比例配置。例如Kafka有16个分区,则并发度建议设置为16、8或4,这样做的原因是什么?
A.满足开发规范要求
B.避免数据倾斜
C. 程序默认要求
D. 避免一个Source需要读取太多数据,导致出现入口瓶颈
答案:D
452.单选题
为了减少Flink在state中保存的输入数据行数并优化Jin类型,可以在WHERE子句中定义一个时间约束,使用___关键词可以将两张表Join的时间条件绑定到约束的时间间隔内。
A.BETWEEN
B.FINISH
C.IN
D.LIMIT
答案:A
453.单选题
在Hologres中对目标表操作时,下面所列选项中,哪一项语句用于对表指定列的行数据进行删除?
A.DROP语句
B.TRUNCATE语句
C.DELETE语句
D.UPDATE语句
答案:C
454.单选题
异常值对某些机器学习的算法有较大影响,需要对异常值进行识别、处理。阿里云机器学习平台PAI中的___组件以很好的完成这个任务。
A.经验概率密度图
B.洛伦兹曲线
C.箱线图
D.直方图
答案:C
455.单选题
在Hologres开发工具中,Hologres与___深度集成,支持直接对接开发。可以通过绑定Hologres实例,进行一站式实时数仓开发,包括数据集成、数据开发、数据质量、数据服务等,满足不同的业务场景开发和管理需求。
A.PSQL客户端
B.JDBC
C.DataWorks
D.HoloWeb
答案:C
456.单选题
以下选项中,用于近似数目估算的函数是?
A.APPROX DISTINCT
B.ROW NUMBER
C.DISTINCT
D.LIKE
答案:A
457.单选题
在大数据开发治理平台DataWorks中,用户可以申请哪几种数据类型访问权限?
A.表、函数、资源
B.函数、资源
C.表、函数
D.表、资源
答案:B
458.单选题
在MaxCompute中执行下列SQL,正确的有?
A.from sale_detail
insert overwrite table sale_detail_multi partition(sale date='2022’, region=‘china’)
select shop_name, customer_id, total_price
insert overwrite table sale detail_multi partition(sale date=‘2022’, region=‘china’)
select shop_name,customer_id,total_price;
B.from sale_detail
insert overwrite table sale_detail_multi partition (sale date=‘2021’, region=‘china’)
select shop_name,customer_id, total_price
insert into table sale_detail_multi partition (sale date=’2022’, region=‘china’)
select shop_name, customer_id, total_price
C.insert overwrite table sale_detail_bypart partition(sale date=‘2022’, region)
select shop_name,customer_id,total_price,region from sale_detail;
D.insert overwrite table sales partition (region=‘china’ ,sale_date)
select shop_name,customer_id,total_price,region from sale detail;
E.insert overwrite table sale_detail_insert partition(sale date=‘2022’,region='china’)
select shop_name, customer_id, total_price, sale date, region from sale_detail:
答案:E
459.单选题
大数据计算服务MaxCompute中的订单表 fact order 是一张分区表,有order id 及rder amt 两个字段,分区键是d,每天新增的订单存储在当天的分区中,对应的源表是 ds rder,源表中可能包括多天的订单,需要按照订单生成的日期 (order dt)将数据保存到 fact order 表中,执行以下SQL语句:insert overwrite table fact_orderspartition(dt) selectorder id.order amtorder dt as dt from ods order, 在语句执行之前 fact order 表中有dt=20220301 及dt=20220302 两个分区,在这个语句执行时ds order 表中包含rder dt=20220302及dt='20220303的数据。对这个语句的执行结果,以下说法正确的是
A.执行完以后fact_order表中有两个分区dt=‘20220302、dt=20220303
B.执行完以后fact order表中有三个分区dt=20220301’、dt=20220302及dt= 20220303
C.执行完以后fact_order表中有两个分区dt=20220301dt=‘20220303
D.执行完以后fact order表中有两个分区dt= 20220301’、dt=20220302
答案:A
460.单选题
在Kibana堆栈监测查看Elasticsearch集群节点信息时,API正确的描述是哪个?
A.GET/_cat/indices?v
B.GET/_cat/nodes?v
C.GET/ cat/thread_pool?v
D.GET/ cat/health?v
答案:B
461.单选题
通过Flink+Hologres+MaxCompute组合,支持离线和实时数据的联合分析,助力数据中台、精准营销、实时多维分析等多种场景。实时热点数据通过Flink ETL(Extract Transformation Load)清洗、转换及整理数据后,实时写入___
A.MaxCompute
B.文件系统
C.业务日志系统
D.Hologres
答案:D
462.单选题
关于MaxCompute逻辑层的描述,错误的是?
A.由Fuxi执行逻辑层分配的任务
B.逻辑层负责集群的调度和计算
C.当用户需要功能扩展的时候,可以对逻辑层进行规模的纵向扩展
D.接入层将审核并验证用户的请求
答案:C
463.单选题
在大数据开发治理平台DataWorks,关于数据地图中数据权限申请有效期的表述正确的是?
A.超过申请权限时长时,系统将自动回收该权限
B.申请表权限的时长时,单位为小时级
C.申请表权限的时长,不填则默认为时长为0
D.超过申请权限时长时,系统访问权限将自动释放
答案:A
464.单选题
分区剪裁失败的通常原因是
A.使用了内置函数
B.使用了用户自定义函数
C.SQL使用了复杂条件
D.使用了实现分区剪裁的自定义函数
答案:B