Redis基础系列-主从复制
文章目录
- Redis基础系列-主从复制
- 1. 什么是 Redis 主从复制?
- 2. 主从复制有什么好处?
- 3. 如何配置 Redis 主从复制?
- 4. 主从复制的验证
- 4.1 如何查看主从搭建成功
- 4.2 主从常见疑问
- 4.3 主从常见命令
- 5. 主从复制的原理和工作流程
- 6. 特殊的主从复制(薪火相传)
- 7. 总结
- 8. 参考和感谢
1. 什么是 Redis 主从复制?
Redis 主从复制是一种数据复制机制,通过该机制,我们可以将 Redis 数据库的数据从一个主 Redis 实例复制到多个从 Redis 实例,从而实现数据的备份和读写分离。主 Redis 实例负责写入操作,而从 Redis 实例则负责读取操作,从而提供更好的性能和可扩展性。
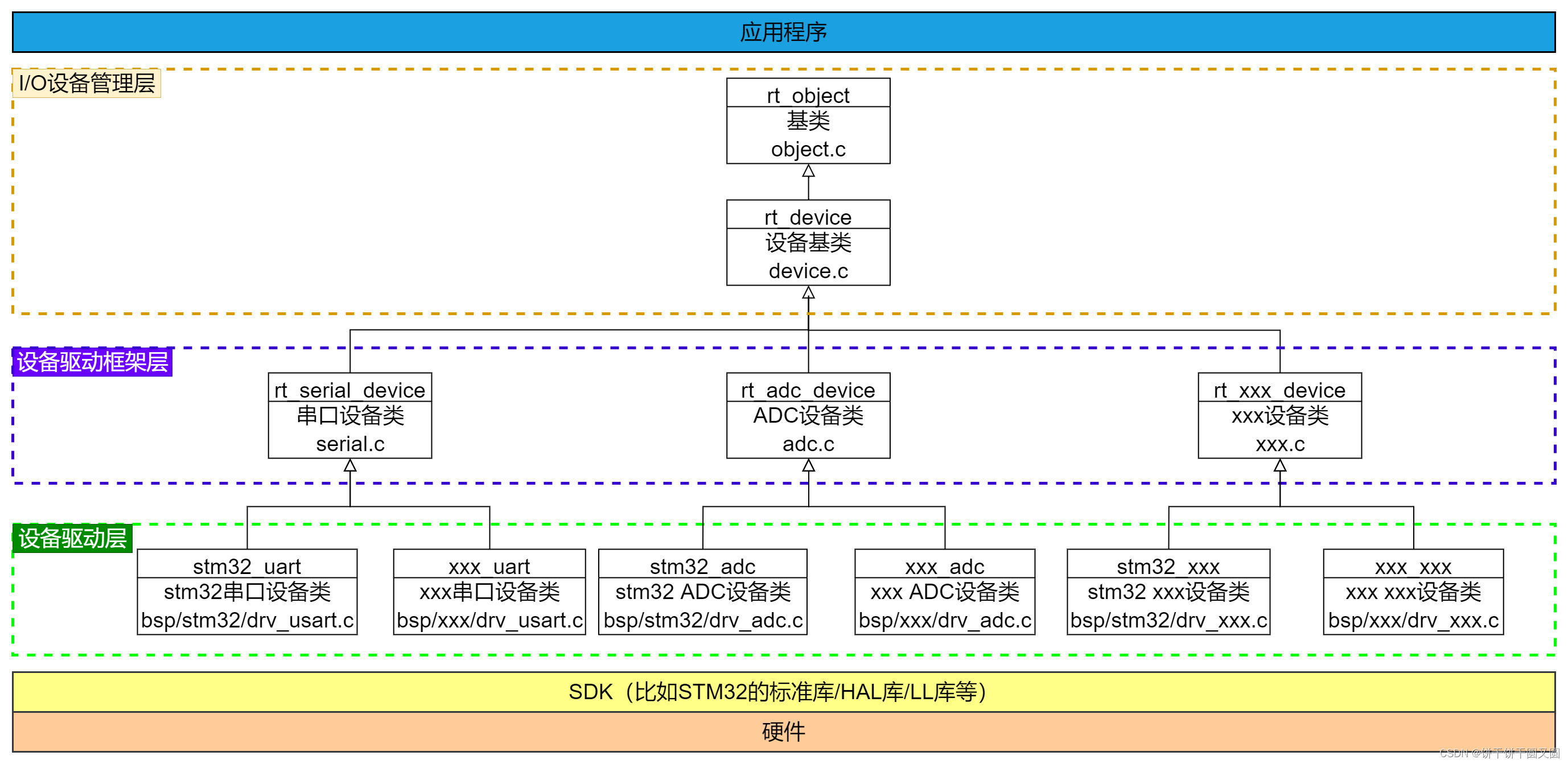
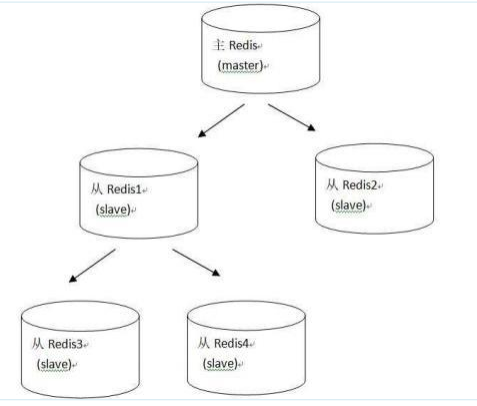
下面是经典的主从架构(一主二仆)

2. 主从复制有什么好处?
- 读写分离
- 容灾恢复
- 数据备份
- 水平扩容支撑高并发
3. 如何配置 Redis 主从复制?
- 配置主 Redis 实例(示例:redis6379.conf)
# 1. 开启后台模式
daemonize yes
# 2.注释掉回环地址限制
#bind 127.0.0.1@
# 3.关闭保护模式
protected-mode no
# 4.指定端口
port 6379
# 5.指定当前工作目录(配置文件和快照文件路径)
dir /myredis
# 6.pid进程文件名字
pidfile /var/run/redis_6379.pid
# 7.log文件名字
logfile "/myredis/6379.log"
# 8.redis密码
requirepass 123456
# 9.快照文件路径
dbfilename dump6379.rdb
- 配置第一个从 Redis 实例(示例:redis6380.conf)
按照上述redis6379.conf进行配置,需要调整以下配置
# 4.指定端口
port 6380
# 6.pid进程文件名字
pidfile /var/run/redis_6380.pid
# 7.log文件名字
logfile "/myredis/6380.log"
新增加以下配置(这才是主从复制的关键配置)
# 1.设置主 Redis 实例的信息
replicaof 192.168.10.110 6379
# 2.设置主 Redis 认证信息
masterauth "123456"
- 配置第二个从 Redis 实例(示例:redis6381.conf)
按照上述redis6379.conf进行配置,需要调整以下配置
# 4.指定端口
port 6381
# 6.pid进程文件名字
pidfile /var/run/redis_6381.pid
# 7.log文件名字
logfile "/myredis/6381.log"
新增加以下配置(这才是主从复制的关键配置)
# 1.设置主 Redis 实例的信息
replicaof 192.168.10.110 6379
# 2.设置主 Redis 认证信息
masterauth "123456"
从上述配置来看,我们可以清晰的了解到,主从配置的关键信息配置在slave上
4. 主从复制的验证

按照上述步骤配置配置好主从rdis,要求三台服务器两两能互相访问,先启动主机,然后启动两台从机
4.1 如何查看主从搭建成功
- 使用命令查看
info replication
主机

从机1

从机2

- 日志查看
主机日志

从机1日志

从机2日志

4.2 主从常见疑问
-
从机可以执行写命令吗?
严格的读写分离,主机负责写数据(也可以读数据),从机负责读数据

-
从机切入点问题
从机首次启动,主机的数据覆盖掉从机的数据,后续主机写,从机跟着同步写入
-
主机shutdown后,从机会上位吗?
从机不动,原地待命,从机数据可以正常使用;等待主机重启
-
主机shutdown后,重启后主从关系还在吗?从机还能否顺利复制?
存在,能顺利复制(青山依旧在)
-
某台从机down后,master继续,从机重启后它能跟上大部队吗?
可以
4.3 主从常见命令
可以查看复制节点的主从关系和配置信息
info replication
从机在运行的状况下,通过命令设置主机(改换门庭)
slaveof 主机ip 主机port
从机在运行的状况下,通过命令断掉与主机的关系(自立为王)
slaveof no one
5. 主从复制的原理和工作流程
- slave启动,同步初请(发送同步的初始化请求)
slave启动成功连接到master后会发送一个sync命令
slave首次全新连接master,一次完全同步 (全量复制)将被自动执行,slave自身原有数据会被master数据覆盖清除
- 首次连接,全量复制
master节点收到sync命令后会开始在后台保存快照(即RDB持久化,主从复制时会触发RDB),同时收集所有接收到的用于修改数据集的命令缓存起来,master节点执行RDB持久化完后,master将rdb快照文件和所有缓存的命令发送到所有slave,以完成一次完全同步
而slave服务在接收到数据库文件数据后,将其存盘并加载到内存中,从而完成复制初始化
- 心跳持续,保持通信
# 10s发送一次心跳
repl-ping-replica-period 10
- 进入平稳,增量复制
Master继续将新的所有收集到的修改命令自动依次传给slave,完成同步
- 从机下线,重连续传
master会检查backlog里面的offset,master和slave都会保存一个复制的offset还有一个masterId,offset是保存在backlog中的。Master只会把已经复制的offset后面的数据复制给Slave,类似断点续传
在 Redis 主从复制中,backlog(复制积压缓冲区)是一个用于存储主节点未能及时传递给从节点的写命令的缓冲区。当主节点生成 RDB 快照或 AOF 日志文件时,或者主从节点之间的网络连接出现故障时,主节点上新接收到的写命令将会存储在 backlog 中,等待后续的传输。
backlog 的作用是确保在主节点和从节点之间的复制过程中数据的准确性和一致性。当连接恢复时,从节点会获取 backlog 中的命令,执行它们以补充在复制过程中可能丢失的数据。
backlog 的大小是通过 `repl-backlog-size` 参数来配置的,默认情况下是 1MB。如果 backlog 中缓存的命令数量超过了配置的大小,最早的命令将被丢弃。
值得注意的是,backlog 只用于短暂的数据流失或网络中断情况下的数据恢复,而不是用于持久化的数据备份。因此,当出现较长时间的故障或大量数据丢失时,可能需要使用其他策略或手段进行数据恢复和同步。
6. 特殊的主从复制(薪火相传)
- 上一个slave可以是下一个slave的master,slave同样可以接收其他slaves的连接和同步请求,那么该slave作为了链条中下一个的master.可以有效减轻主master的写压力
- 中途变更转向:会清除之前的数据,重新建立拷贝最新的

7. 总结
主从复制虽然可以实现读写分离,很大程度上提高redis的使用性能,但是它的缺点也是显而易见的:
- 由于所有的写操作都是先在Master上操作,然后同步更新到Slave上,所以从Master同步到Slave机器有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave机器数量的增加也会使这个问题更加严重。
- master宕机了,从机不会竞选master,此时只能读,不能写
8. 参考和感谢
尚硅谷Redis零基础到进阶,最强redis7教程,阳哥亲自带练





![字符统计[c]](https://img-blog.csdnimg.cn/direct/668e548426d54c01a8fdfe422d955621.png)