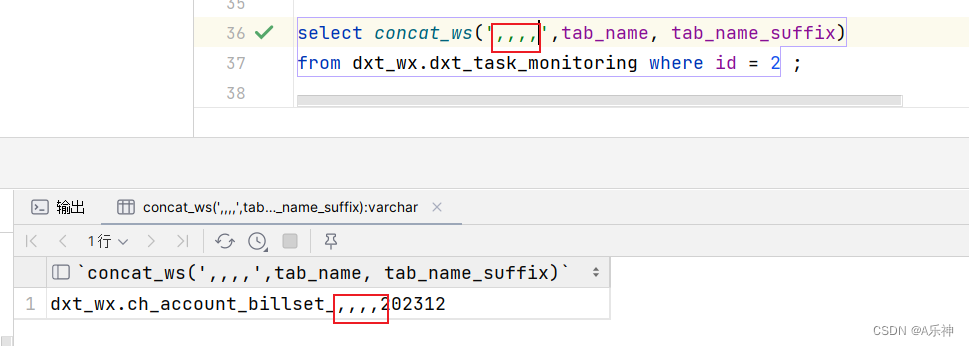
concurrent.futures 提供的线程池
concurrent.futures模块提供了线程池和进程池简化了多线程/进程操作。
线程池原理是用一个任务队列让多个线程从中获取任务执行,然后返回结果。
常见的用法是创建线程池,提交任务,等待完成并获取结果:
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
futures = [executor.submit(count, item) for item in number_list] # count是一个函数,item是其参数
for future in concurrent.futures.as_completed(futures):
print(future.result())
concurrent.futures.ThreadPoolExecutor(max_workers=5)创建了一个线程池,max_workers指定了线程数量上限。通过线程池可以创建和执行任务。concurrent.futures使用Future类表示(未来的)任务。调用.submit()时会创建并执行一个任务(Future)。.as_completed(futures)是一个迭代器,当futures中有任务完成时会产出该future.
Python最广为使用的并发处理库futures使用入门与内部原理 - 知乎 (zhihu.com)对这个过程做了比较好的说明:
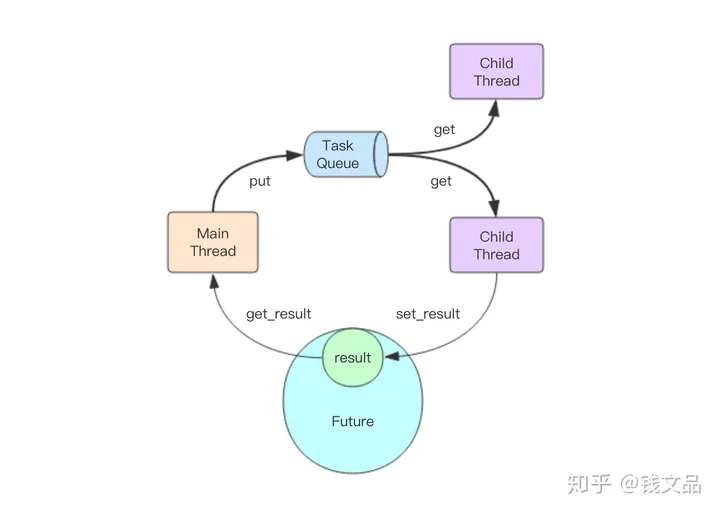
主线程是通过队列将任务传递给多个子线程的。一旦主线程将任务塞进任务队列,子线程们就会开始争抢,最终只有一个线程能抢到这个任务,并立即进行执行,执行完后将结果放进Future对象就完成了这个任务的完整执行过程。
python-parallel-programming-cookbook-cn 1.0 文档 中的一个例子对使用顺序执行、线程池、进程池三种方式进行计算的时间进行了比较:
import concurrent.futures
import time
# 一个耗时的计算
def count(number) :
for i in range(0, 10000000):
i=i+1
return i * number
if __name__ == "__main__":
number_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 顺序执行
start_time = time.time()
for item in number_list:
print(count(item))
print("Sequential execution in " + str(time.time() - start_time), "seconds")
# 线程池
start_time_1 = time.time()
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
futures = [executor.submit(count, item) for item in number_list]
for future in concurrent.futures.as_completed(futures):
print(future.result())
print("Thread pool execution in " + str(time.time() - start_time_1), "seconds")
# 进程池
start_time_2 = time.time()
with concurrent.futures.ProcessPoolExecutor(max_workers=5) as executor:
futures = [executor.submit(count, item) for item in number_list]
for future in concurrent.futures.as_completed(futures):
print(future.result())
print("Process pool execution in " + str(time.time() - start_time_2), "seconds")
结果为:
Sequential execution in 7.095552206039429 seconds
Thread pool execution in 7.140377998352051 seconds
Process pool execution in 4.240718126296997 seconds
竞争和锁
由于共享内存,多线程程序容易遇到竞争问题:两个内存对同一个变量进行修改可能导致意想不到的问题。
看下面这个计数的例子:
我们创建了一个全局变量thread_visits,在visit_counter()中修改这个变量值。
from threading import Thread
thread_visits = 0
def visit_counter():
global thread_visits
for _ in range(100_000):
thread_visits += 1 # thread_visits = thread_visits + 1
if __name__ == "__main__":
thread_count = 100
threads = [
Thread(target=visit_counter)
for _ in range(thread_count)
]
for thread in threads:
thread.start()
for thread in threads:
thread.join()
print(f"thread_count={thread_count}, thread_visits={thread_visits}")
执行结果:
第1次 :thread_count=100, thread_visits=7227793
第2次 :thread_count=100, thread_visits=9544020
第3次 :thread_count=100, thread_visits=9851811
执行该程序会发现每次运行thread_visits的值都不一样。
因为在 thread_visits 变量上的读取和写入操作之间有一段时间,另一个线程可以介入并操作结果。这导致了竞争。
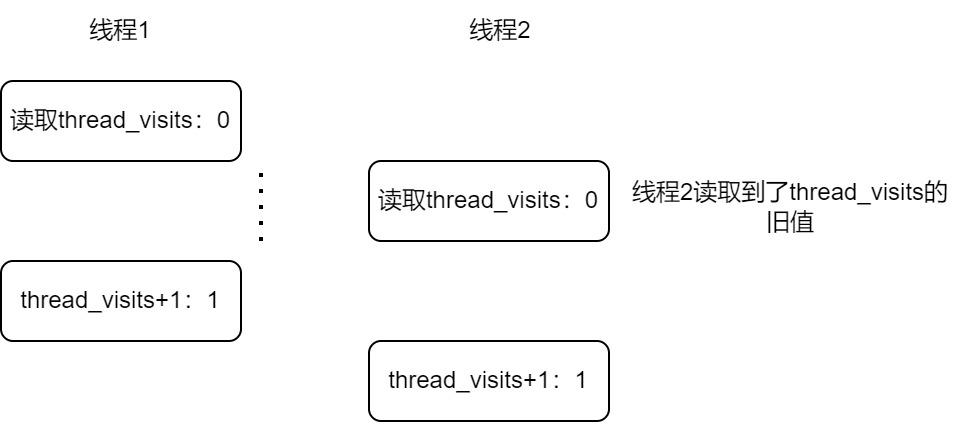
(线程1和线程2对变量thread_visits的竞争。两个线程都对thread_visits执行了+1的操作,但最后thread_visits的是1,而不是2。)
thread_visits += 1实际包含读写两个操作,它等价于
thread_visits = thread_visits + 1,先读取thread_visits的值并+1,再写入到thread_visits。
正确方法是使用锁保证一次只有一个线程可以处理单个代码块

from threading import Thread
from threading import Lock
thread_visits = 0
thread_visits_lock = Lock()
def visit_counter():
global thread_visits
for _ in range(100_000):
with thread_visits_lock:
thread_visits += 1 # thread_visits = thread_visits + 1
运行结果:
thread_count=100, thread_visits=10000000
这次我们得到了正确的结果,但花费了接近一分钟的时间。因为受保护的块不能并行运行。此外,获取和释放锁是需要一些额外操作。
将锁放在外面的时候,会发现花费的时间减少了很多。因为减少了获取和释放锁的消耗。
with thread_visits_lock:
for _ in range(100_000):
thread_visits += 1