一键抠图2:C/C++实现人像抠图 (Portrait Matting)
目录
一键抠图2:C/C++实现人像抠图 (Portrait Matting)
1. 前言
2. 抠图算法
3. 人像抠图算法MODNet
(1)模型训练
(2)将Pytorch模型转换ONNX模型
(3)将ONNX模型转换为TNN模型
4. 模型C++部署
(1)项目结构
(2)配置开发环境(OpenCV+OpenCL+base-utils+TNN)
(3)部署TNN模型
(4)CMake配置
(5)main源码
(6)源码编译和运行
5. 人像抠图效果
6. 项目源码下载
7. 人像抠图Python版本
8. 人像抠图Android版本
1. 前言
这是一键抠图项目系列之《C/C++实现人像抠图 (Portrait Matting)》;本篇主要分享将Python训练后的matting模型转写成C/C++代码。我们将开发一个简易的、可实时运行的人像抠图C/C++ Demo。C/C ++版本人像抠图模型推理支持CPU和GPU加速,在GPU(OpenCL)加速下,可以达到头发细致级别的人像抠图效果,为了方便后续模型工程化和Android平台部署,项目提供高精度版本人像抠图和轻量化快速版人像抠图,并提供Python/C++/Android多个版本;

【尊重原创,转载请注明出处】https://blog.csdn.net/guyuealian/article/details/134790532
Android Demo APP下载地址:https://download.csdn.net/download/guyuealian/63228759
先展示一下一键人像抠图效果:

更多项目《一键抠图》系列文章请参考:
- 一键抠图1:Python实现人像抠图 (Portrait Matting)https://blog.csdn.net/guyuealian/article/details/134784803
- 一键抠图2:C/C++实现人像抠图 (Portrait Matting)https://blog.csdn.net/guyuealian/article/details/134790532
- 一键抠图3:Android实现人像抠图 (Portrait Matting) https://blog.csdn.net/guyuealian/article/details/134801795

2. 抠图算法
基于深度学习的Matting分为两大类:
-
一种是基于辅助信息输入。即除了原图和标注图像外,还需要输入其他的信息辅助预测。最常见的辅助信息是Trimap,即将图片划分为前景,背景及过度区域三部分。另外也有以背景或交互点作为辅助信息。
-
一种是不依赖任何辅助信息,直接对Alpha进行预测。如本博客复现的MODNet
第一种方法,需要加入辅助信息,而辅助信息一般较难获取,这也限制其应用,为了提升Matting的应用性,针对Portrait Matting领域MODNet摒弃了辅助信息,直接实现Alpha预测,实现了实时Matting,极大提升了基于深度学习Matting的应用价值。
更多抠图算法(Matting),请参考我的一篇博客《图像抠图Image Matting算法调研》:
图像抠图Image Matting算法调研_image matting调研-CSDN博客文章浏览阅读4.3k次,点赞8次,收藏68次。1.Trimap和StrokesTrimap和Strokes都是一种静态图像抠图算法,现有静态图像抠图算法均需对给定图像添加手工标记以增加抠图问题的额外约束。Trimap,三元图,是对给定图像的一种粗略划分,即将给定图像划分为前景、背景和待求未知区域Strokes则采用涂鸦的方式在图像上随意标记前景和背景区域,剩余未标记部分则为待求的未知区域Trimap是最常用的先验知识,多数抠图算法采用了Trimap作为先验知识,顾名思义Trimap是一个三元图,每个像素取值为{0,128,..._image matting调研https://blog.csdn.net/guyuealian/article/details/119648686可能,有小伙伴搞不清楚分割(segmentation)和抠图(matting)有什么区别,我这里简单说明一下:
- 分割(segmentation):从深度学习的角度来说,分割本质是像素级别的分类任务,其损失函数最简单的莫过于是交叉熵CrossEntropyLoss(当然也可以是Focal Loss,IOU Loss,Dice Loss等);对于前景和背景分割任务,输出Mask的每个像素要么是0,要么是1。如果拿去直接做图像融合,就很不自然,Mask边界很生硬,这时就需要使用抠图算法了
- 抠图(matting): 而抠图本质是一种回归任务,其损失函数可以是MSE Loss,L1 Loss,L2 Loss等,对于前景和背景抠图任务,输出Mask的每个像素是0~1之间的连续值,可看作是对图像透明通道(Alpha)的回归预测。可以用公式表示为C = αF + (1-α)B ,其中α(不透明度)、F(前景色)和B(背景色),alpha是[0, 1]之间的连续值,可以理解为像素属于前景的概率。在人像分割任务中,alpha只能取0或1,而抠图任务中,alpha可取[0, 1]之间的连续值,
- 本质上就是一句话:分割是分类任务,而抠图是回归任务。
3. 人像抠图算法MODNet
本文主要在MODNet人像抠图算法基础上进行模型压缩和优化,关于《MODNet: Trimap-Free Portrait Matting in Real Time》,请参考:
- Paper: https://arxiv.org/pdf/2011.11961.pdf
- 官方Github: GitHub - ZHKKKe/MODNet: A Trimap-Free Solution for Portrait Matting in Real Time
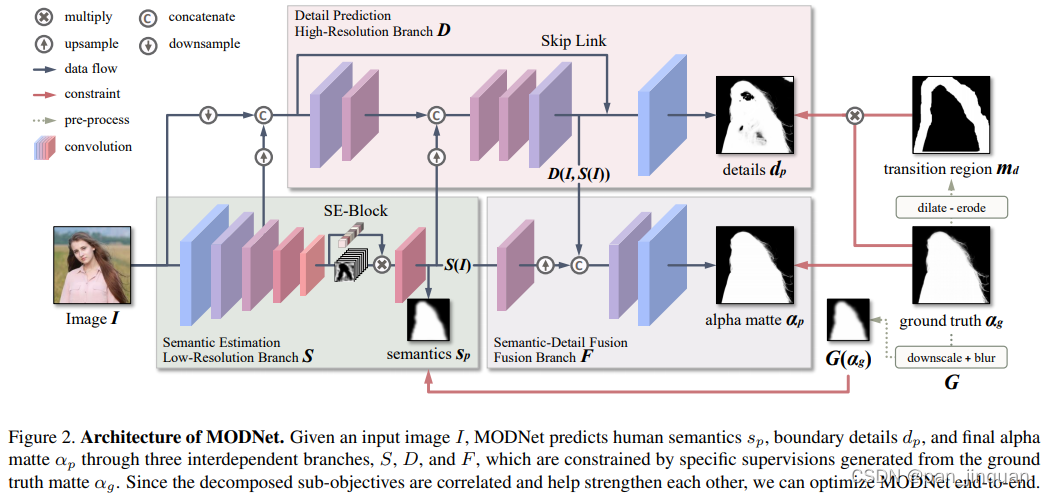
MODNet模型学习分为三个部分,分别为:语义部分(S),细节部分(D)和融合部分(F)。
- 在语义估计中,对high-level的特征结果进行监督学习,标签使用的是下采样及高斯模糊后的GT,损失函数用的L2-Loss,用L2loss应该可以学到更soft的语义特征;
- 在细节预测中,结合了输入图像的信息和语义部分的输出特征,通过encoder-decoder对人像边缘进行单独地约束学习,用的是交叉熵损失函数。为了减小计算量,encoder-decoder结构较为shallow,同时处理的是原图下采样后的尺度。
- 在融合部分,把语义输出和细节输出结果拼起来后得到最终的alpha结果,这部分约束用的是L1损失函数。
(1)模型训练
官方GitHub仅仅放出推理代码,并未提供训练代码和数据处理代码 ;鄙人参考原论文花了几个星期的时间,总算复现了其基本效果,并做了一些轻量化和优化的工作,主要有:
- 复现Pytorch版本的MODNet训练过程和数据处理
- 增加了数据增强方法:如多尺度随机裁剪,Mosaic(拼图),随机背景融合等方法,提高模型泛化性
- 对MODNet骨干网络backbone进行轻量化,减少计算量
- 模型压缩,目前提供三个版本:高精度人像抠图modnet+快速人像抠图modnet0.75+超快人像抠图modnet0.5
- 转写模型推理过程,实现C++版本人像抠图算法
- 实现Android版本人像抠图算法,支持CPU和GPU
- 提供高精度版本人像抠图,可以达到精细到发丝级别的抠图效果(Android GPU 150ms, CPU 500ms左右)
- 提供轻量化快速版人像抠图,满足基本的人像抠图效果,可以在Android达到实时的抠图效果(Android GPU 60ms, CPU 140ms左右)
高精度人像抠图modnet+快速人像抠图modnet0.75+超快人像抠图modnet0.5的模型参数量和计算量:
| 模型 | input size | FLOPs and Params |
| modnet | 416×416 | Model FLOPs 10210.24M, Params 6.44M |
| modnet0.75 | 320×320 | Model FLOPs 3486.23M, Params 3.64M |
| modnet0.5 | 320×320 | Model FLOPs 1559.07M, Params 1.63M |
(2)将Pytorch模型转换ONNX模型
训练好模型后,你需要先将Pytorch模型转换为ONNX模型,并使用onnx-simplifier简化网络结构,Python版本的已经提供了ONNX转换脚本,终端输入命令如下:
# 导出ONNX模型
python export.py --model_type "modnet" --model_file "work_space/modnet_416/model/best_model.pth"GitHub: https://github.com/daquexian/onnx-simplifier
Install: pip3 install onnx-simplifier
(3)将ONNX模型转换为TNN模型
目前在C++端上,CNN模型有多种部署方式,可以采用TNN,MNN,NCNN,以及TensorRT等部署工具,鄙人采用TNN进行Android端上部署
TNN转换工具:
- (1)将ONNX模型转换为TNN模型,请参考TNN官方说明:TNN/onnx2tnn.md at master · Tencent/TNN · GitHub
- (2)一键转换,懒人必备:一键转换 Caffe, ONNX, TensorFlow 到 NCNN, MNN, Tengine (可能存在版本问题,这个工具转换的TNN模型可能不兼容,建议还是自己build源码进行转换,2022年9约25日测试可用)
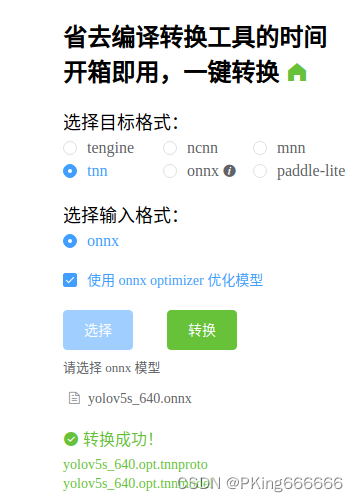
转换成功后,会生成两个文件(*.tnnproto和*.tnnmodel) ,下载下来后面会用到
4. 模型C++部署
项目IDE开发工具使用CLion,相关依赖库主要有OpenCV,base-utils以及TNN和OpenCL(可选),其中OpenCV必须安装,OpenCL用于模型加速,base-utils以及TNN已经配置好,无需安装;
项目仅在Ubuntu18.04进行测试,Windows系统下请自行配置好开发环境。
(1)项目结构

(2)配置开发环境(OpenCV+OpenCL+base-utils+TNN)
项目仅在Ubuntu18.04进行测试,Windows系统下请自行配置和编译
- 安装OpenCV:图像处理
图像处理(如读取图片,图像裁剪等)都需要使用OpenCV库进行处理
安装教程:Ubuntu18.04安装opencv和opencv_contrib
OpenCV库使用opencv-4.3.0版本,opencv_contrib库暂时未使用,可不安装
- 安装OpenCL:模型加速
安装教程:Ubuntu16.04 安装OpenCV&OpenCL
OpenCL用于模型GPU加速,若不使用OpenCL进行模型推理加速,纯C++推理模型,速度会特别特别慢
- base-utils:C++库
GitHub:https://github.com/PanJinquan/base-utils (无需安装,项目已经配置了)
base_utils是个人开发常用的C++库,集成了C/C++ OpenCV等常用的算法
- TNN:模型推理
GitHub:https://github.com/Tencent/TNN (无需安装,项目已经配置了)
由腾讯优图实验室开源的高性能、轻量级神经网络推理框架,同时拥有跨平台、高性能、模型压缩、代码裁剪等众多突出优势。TNN框架在原有Rapidnet、ncnn框架的基础上进一步加强了移动端设备的支持以及性能优化,同时借鉴了业界主流开源框架高性能和良好拓展性的特性,拓展了对于后台X86, NV GPU的支持。手机端 TNN已经在手机QQ、微视、P图等众多应用中落地,服务端TNN作为腾讯云AI基础加速框架已为众多业务落地提供加速支持。
(3)部署TNN模型
项目模型推理采用TNN部署框架(支持多线程CPU和GPU加速推理);图像处理采用OpenCV库,模型加速采用OpenCL,在普通电脑设备即可达到实时处理。
如果你想在这个 C++ Demo部署你自己训练的模型,你可以将训练好的Pytorch模型转换ONNX ,再转换成TNN模型,然后把原始的模型替换成你自己的TNN模型即可。
(4)CMake配置
这是CMakeLists.txt,其中主要配置OpenCV+OpenCL+base-utils+TNN这四个库,Windows系统下请自行配置和编译
cmake_minimum_required(VERSION 3.5)
project(Detector)
add_compile_options(-fPIC) # fix Bug: can not be used when making a shared object
set(CMAKE_CXX_FLAGS "-Wall -std=c++11 -pthread")
#set(CMAKE_CXX_FLAGS_RELEASE "-O2 -DNDEBUG")
#set(CMAKE_CXX_FLAGS_DEBUG "-g")
if (NOT CMAKE_BUILD_TYPE AND NOT CMAKE_CONFIGURATION_TYPES)
# -DCMAKE_BUILD_TYPE=Debug
# -DCMAKE_BUILD_TYPE=Release
message(STATUS "No build type selected, default to Release")
set(CMAKE_BUILD_TYPE "Release" CACHE STRING "Build type (default Debug)" FORCE)
endif ()
# opencv set
find_package(OpenCV REQUIRED)
include_directories(${OpenCV_INCLUDE_DIRS} ./src/)
#MESSAGE(STATUS "OpenCV_INCLUDE_DIRS = ${OpenCV_INCLUDE_DIRS}")
# base_utils
set(BASE_ROOT 3rdparty/base-utils) # 设置base-utils所在的根目录
add_subdirectory(${BASE_ROOT}/base_utils/ base_build) # 添加子目录到build中
include_directories(${BASE_ROOT}/base_utils/include)
include_directories(${BASE_ROOT}/base_utils/src)
MESSAGE(STATUS "BASE_ROOT = ${BASE_ROOT}")
# TNN set
# Creates and names a library, sets it as either STATIC
# or SHARED, and provides the relative paths to its source code.
# You can define multiple libraries, and CMake builds it for you.
# Gradle automatically packages shared libraries with your APK.
# build for platform
# set(TNN_BUILD_SHARED OFF CACHE BOOL "" FORCE)
if (CMAKE_SYSTEM_NAME MATCHES "Android")
set(TNN_OPENCL_ENABLE ON CACHE BOOL "" FORCE)
set(TNN_ARM_ENABLE ON CACHE BOOL "" FORCE)
set(TNN_BUILD_SHARED OFF CACHE BOOL "" FORCE)
set(TNN_OPENMP_ENABLE ON CACHE BOOL "" FORCE) # Multi-Thread
#set(TNN_HUAWEI_NPU_ENABLE OFF CACHE BOOL "" FORCE)
add_definitions(-DTNN_OPENCL_ENABLE) # for OpenCL GPU
add_definitions(-DTNN_ARM_ENABLE) # for Android CPU
add_definitions(-DDEBUG_ANDROID_ON) # for Android Log
add_definitions(-DPLATFORM_ANDROID)
elseif (CMAKE_SYSTEM_NAME MATCHES "Linux")
set(TNN_OPENCL_ENABLE ON CACHE BOOL "" FORCE)
set(TNN_CPU_ENABLE ON CACHE BOOL "" FORCE)
set(TNN_X86_ENABLE OFF CACHE BOOL "" FORCE)
set(TNN_QUANTIZATION_ENABLE OFF CACHE BOOL "" FORCE)
set(TNN_OPENMP_ENABLE ON CACHE BOOL "" FORCE) # Multi-Thread
add_definitions(-DTNN_OPENCL_ENABLE) # for OpenCL GPU
add_definitions(-DDEBUG_ON) # for WIN/Linux Log
add_definitions(-DDEBUG_LOG_ON) # for WIN/Linux Log
add_definitions(-DDEBUG_IMSHOW_OFF) # for OpenCV show
add_definitions(-DPLATFORM_LINUX)
elseif (CMAKE_SYSTEM_NAME MATCHES "Windows")
set(TNN_OPENCL_ENABLE ON CACHE BOOL "" FORCE)
set(TNN_CPU_ENABLE ON CACHE BOOL "" FORCE)
set(TNN_X86_ENABLE ON CACHE BOOL "" FORCE)
set(TNN_QUANTIZATION_ENABLE OFF CACHE BOOL "" FORCE)
set(TNN_OPENMP_ENABLE ON CACHE BOOL "" FORCE) # Multi-Thread
add_definitions(-DTNN_OPENCL_ENABLE) # for OpenCL GPU
add_definitions(-DDEBUG_ON) # for WIN/Linux Log
add_definitions(-DDEBUG_LOG_ON) # for WIN/Linux Log
add_definitions(-DDEBUG_IMSHOW_OFF) # for OpenCV show
add_definitions(-DPLATFORM_WINDOWS)
endif ()
set(TNN_ROOT 3rdparty/TNN)
include_directories(${TNN_ROOT}/include)
include_directories(${TNN_ROOT}/third_party/opencl/include)
add_subdirectory(${TNN_ROOT}) # 添加外部项目文件夹
set(TNN -Wl,--whole-archive TNN -Wl,--no-whole-archive)# set TNN library
MESSAGE(STATUS "TNN_ROOT = ${TNN_ROOT}")
# Detector
include_directories(src)
set(SRC_LIST
src/segment.cpp
src/Interpreter.cpp)
add_library(dlcv SHARED ${SRC_LIST})
target_link_libraries(dlcv ${OpenCV_LIBS} base_utils)
MESSAGE(STATUS "DIR_SRCS = ${SRC_LIST}")
add_executable(Detector src/main_for_segment.cpp)
target_link_libraries(Detector dlcv ${TNN} -lpthread)
(5)main源码
主程序src/main_for_segment.cpp中提供行手势识别的Demo,支持图片,视频和摄像头测试
//
// Created by Pan on 2020/6/24.
//
#include "segment.h"
#include <iostream>
#include <string>
#include <vector>
#include <image_utils.h>
#include "file_utils.h"
#include "debug.h"
using namespace dl;
using namespace vision;
using namespace std;
const int num_thread = 1;
DeviceType device = GPU; // 使用GPU运行,需要配置好OpenCL
// DeviceType device = CPU; // 使用CPU运行
// 高精度人像抠图
const char *model_file = (char *) "../data/tnn/segment/matting1.00_416_416_sim.opt.tnnmodel";
const char *proto_file = (char *) "../data/tnn/segment/matting1.00_416_416_sim.opt.tnnproto";
SegmentParam model_param = MATTING416;
//超快人像抠图
//const char *model_file = (char *) "../data/tnn/segment/matting0.50_320_320_sim.opt.tnnmodel";
//const char *proto_file = (char *) "../data/tnn/segment/matting0.50_320_320_sim.opt.tnnproto";
//SegmentParam model_param = MATTING320;
Segment *detector = new Segment(model_file,
proto_file,
model_param,
num_thread,
device);
// 背景图像
string bg_file = "../data/bg2.png";
cv::Mat bg_image = cv::imread(bg_file);
void test_image_file() {
string image_dir = "../data/test_images";
std::vector<string> image_list = get_files_list(image_dir);
for (string image_path:image_list) {
cv::Mat bgr_image = cv::imread(image_path);
if (bgr_image.empty()) continue;
printf("%s\n", image_path.c_str());
// 开始抠图,返回matte图(即前景和背景的分割图)
cv::Mat matte;
detector->detect(bgr_image, matte);
// 融合图像
cv::Mat fusion;
image_fusion(bgr_image, matte, fusion, bg_image);
//image_fusion(bgr_image, matte, fusion);
// 可视化代码
detector->visualizeResult(bgr_image, matte, fusion, 0);
}
printf("FINISHED.\n");
}
/***
* 测试视频文件
* @return
*/
int test_video_file() {
string video_file = "../data/video/video-test1.mp4"; //视频文件
cv::VideoCapture cap;
bool ret = get_video_capture(video_file, cap);
cv::Mat frame;
while (ret) {
cap >> frame;
if (frame.empty()) break;
// 开始抠图,返回matte图(即前景和背景的分割图)
cv::Mat matte;
detector->detect(frame, matte);
// 融合图像
cv::Mat fusion;
image_fusion(frame, matte, fusion, bg_image);
//image_fusion(bgr_image, matte, fusion);
// 可视化代码
detector->visualizeResult(frame, matte, fusion, 10);
}
cap.release();
printf("FINISHED.\n");
return 0;
}
/***
* 测试摄像头
* @return
*/
int test_camera() {
int camera = 0; //摄像头ID号(请修改成自己摄像头ID号)
cv::VideoCapture cap;
bool ret = get_video_capture(camera, cap);
cv::Mat frame;
while (ret) {
cap >> frame;
if (frame.empty()) break;
// 开始抠图,返回matte图(即前景和背景的分割图)
cv::Mat matte;
detector->detect(frame, matte);
// 融合图像
cv::Mat fusion;
image_fusion(frame, matte, fusion, bg_image);
//image_fusion(bgr_image, matte, fusion);
// 可视化代码
detector->visualizeResult(frame, matte, fusion,10);
}
cap.release();
printf("FINISHED.\n");
return 0;
}
int main() {
//test_image_file();
test_video_file();
//test_camera();
return 0;
}
(6)源码编译和运行
编译脚本,或者直接:bash build.sh
#!/usr/bin/env bash
if [ ! -d "build/" ];then
mkdir "build"
else
echo "exist build"
fi
cd build
cmake ..
make -j4
sleep 1
./Detector
- 如果你要测试CPU运行的性能,请修改src/main_for_segment.cpp
DeviceType device = CPU;
- 如果你要测试GPU运行的性能,请修改src/main_for_segment.cpp (需配置好OpenCL)
DeviceType device = GPU; //默认使用GPU
纯C++推理模式需要耗时几秒的时间,而开启OpenCL加速后,GPU模式耗时仅需十几毫秒,性能极大的提高。
5. 人像抠图效果
C++版本人像抠图效果与Python版本的效果几乎一致:



实际使用中,建议你:
- 背景越单一,抠图的效果越好,背景越复杂,抠图效果越差;建议你实际使用中,找一比较单一的背景,如墙面,天空等
- 上半身抠图的效果越好,下半身或者全身抠图效果较差;本质上这是数据的问题,因为训练数据70%都是只有上半身的
- 白种人抠图的效果越好,黑人和黄种人抠图效果较差;这也是数据的问题,因为训练数据大部分都是隔壁的老外
下图是高精度版本人像抠图和快速人像抠图的测试效果,相对而言,高精度版本人像抠图可以精细到发丝级别的抠图效果;而快速人像构图目前仅能实现基本的抠图效果
| 高精度版本人像抠图 | 快速人像抠图 |
 |  |
 |  |
 |  |
6. 项目源码下载
源码下载:C/C++实现人像抠图 (Portrait Matting)
内容包含:
- 提供高精度版本人像抠图模型(modnet_416),可以达到精细到发丝级别的抠图效果
- 提供轻量化快速版人像抠图模型(modnet0.75_320和modnet0.5_320),满足基本的人像抠图效果
C/C++项目源码支持图片,视频,摄像头测试
项目配置好了base-utils和TNN,而OpenCV和OpenCL需要自行编译安装,开发工具推荐使用CLion
7. 人像抠图Python版本
一键抠图1:Python实现人像抠图 (Portrait Matting)https://blog.csdn.net/guyuealian/article/details/134784803
8. 人像抠图Android版本
- 一键抠图3:Android实现人像抠图 (Portrait Matting) https://blog.csdn.net/guyuealian/article/details/134801795
-
Android Demo APP下载地址: https://download.csdn.net/download/guyuealian/63228759