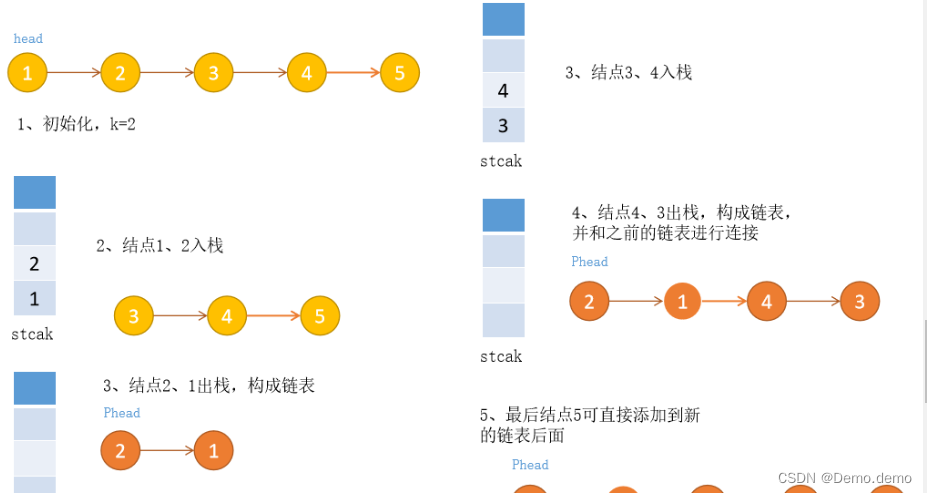
目录
- 前言
- 0. 简述
- 1. 算法动机&开创性思路
- 2. 主体结构
- 3. 损失函数
- 4. 性能对比
- 总结
- 下载链接
- 参考
前言
自动驾驶之心推出的《国内首个BVE感知全栈系列学习教程》,链接。记录下个人学习笔记,仅供自己参考
本次课程我们来学习下课程第四章——基于环视Camera的BEV感知算法,一起去学习下 DETR3D 感知算法
课程大纲可以看下面的思维导图

0. 简述
从 4.4 节开始我们会对纯视觉感知算法进行详细的介绍,本节内容和大家一起学习一下一篇非常火的工作叫 DETR3D,我们还是围绕以下四个方面展开包括算法动机&开创性思路、主体结构、损失函数和性能对比
首先从算法动机开始
1. 算法动机&开创性思路
我们在开始之前先复习一下 BEV 感知算法设计的核心是什么呢,是视角转换模块,那有哪些视角转换方法呢,一种是我们讲的从 2D 到 3D 到 BEV 的方案,如下图所示:

2D 图像中的每个像素点可以理解成世界空间中某个点所发出的一条射线,那仅用图像不能确定此像素具体来自于射线上的哪个位置,也就是说我们不知道像素的深度值,所以从 2D 到 3D 视角转换的第一步是尝试恢复 深度信息,具体是怎么做呢,其实是为每个像素生成所有可能深度分布的一系列概率位置,在每一个位置去做一个特征,那这个特征是一个加权特征,比如某一个像素点映射在某个深度的概率可能偏高一点,那这个特征它基本就是像素的原始特征,比如投影到另一个深度的概率偏低一点,那我们这个特征乘上权重之后它就不太明显了。所有像素都投影完之后就是用原始 2D 像素特征对 3D 空间去进行的重构,那相比于特征点赋予单一的深度值,采用所有可能深度的好处在于可以提高鲁棒性,它在一些深度具有歧义的像素点上就表现得更好
那我们也讲过另外一种从 2D 到 3D 的转换方法是通过预测的深度图,如下图所示:

上图中的 Depth Map 就是我们预测的深度图,那这个深度是为每一个像素赋予单一的深度值,是确定性深度,每个像素对应映射到 3D 空间呢,那就是一一对应的关系,可以生成一系列的伪点云,那自然可以通过 3D 网络进行处理,那这种深度分布与我们上面讲的离散深度分布不同,它属于连续深度分布
OK,以上其实都是从 2D 空间出发,2D 图像上面每个像素点映射到 3D 空间,那也就是说我这个像素放到这个位置,那个像素放到那个位置,所有像素都放完之后,3D 空间其实就是用 2D 图像特征进行了重构性的表征,那这个方向我们要明白是从 2D 到 3D 的方向。
那 DETR3D 考虑的是什么问题呢,它其实不是从 2D 图像中出发而是从 3D 的 Object Query 出发再投影到 2D 图像上去取特征,那也就是说物体要什么我们拿什么,而不是把所有的 2D 图像像素特征都投影到 3D 平面上,有一些表述中把这种方式称为 top-down 或者 top-bottom 的方法,那相比于 2D 到 3D 的方法它们有什么区别呢,其实是少了深度预测模型的,无论是深度分布预测还是深度图预测 DETR3D 里面是不需要这个额外模块的,所以它自然就少引入了一点复合误差
OK,我们接下来看一下 DETR3D 是怎么做的
2. 主体结构
我们看一下网络的主体结构,如下图所示:

那老套路还是从输入输出看起,输入是什么呢,在这里是多视角图像,输出是什么呢,那对于 3D 检测任务而言,输出是 3D 的 Bounding box,是 3D 检测边界框,所以从功能性描述来讲的话,我们这里提到的 DETR3D 应该表述为输入的是多视角图像输出 3D 检测结果。所以 DETR3D 属于什么,属于纯视觉框架
输入的是图像,那怎么处理图像呢,需要图像处理网络了,图像处理网络有很多,我们讲过有 ResNet 这种的传统框架,也有 ViT 和 Swin Transformer 这种基于 Transformer-Based 的框架,DETR3D 的作者还是沿用的传统框架,我们看到是 ResNet 加 FPN,FPN 是特征金字塔的结构,主要是用于处理多尺度的特征,有了图像特征之后我们怎么用这些特征呢,我们在动机阐述中也一直在强调先有 Object Query,以 Query 为基础去图像中拿特征,通过这种方式呢,2D 特征其实被采样成一系列的 Object Query,物体特征有了自然可以拿来做预测得到 3D 检测结果
OK,我们再来具体看一下每个模块流程是怎么做的,先从图像特征提取模块看起,如下图所示:

我们先简单总结下图像特征提取模块的设计流程:
- 输入:多视角图像,相机内外参
- 步骤 1:2D Backbone 提取基础图像特征
- 步骤 2:FPN 进行多尺度特征融合
- 输出:Camera Features
我们按照网络前向流程来看输入是多视角网络,主干网络是什么,图像处理框架,编码图像特征,那就好比输入的如果是点云数据,那么主干网络自然就是 3D 处理网络,编码 3D 特征,那 DETR3D 中用的图像处理框架写得也很清楚了是 ResNet+FPN,ResNet 是 kaiming 老师比较早期的工作,在第二章开头我们也流程性的讲解过,大家如果忘记了可以去复习一下,主要是通过一个残差结构从而减轻梯度消失的影响
另外一个是 FPN 我们叫特征金字塔网络,也是一个非常常见的网络结构,包括我们在第三章中提到的 BEVFusion 也是使用了金字塔结构的,上图右侧就是一个 FPN 的结构,可以看到非常形象,很像一个金字塔,偏底层的特征尺寸比较大,偏顶层的特征尺寸比较小,大家可以想象一下,特征为什么会产生那么大的尺寸差异呢,尺寸差异会带来什么影响呢
那首先第一点尺寸差异其实是来源于卷积或者池化操作,当我们卷积核的步长比较大,特征其实呈现的是下采样的一个状态,额外的池化操作特征也是下采样的;那么第二点尺寸不一样有什么影响呢,越底层的特征我们能看到特征尺寸越接近于原始图像尺寸,那自然图像上更多的细节信息可以被保留,随着下采样越来越多特征图尺寸越来越小,那这些细节信息在这个下采样过程中就慢慢丢失了,从而保留更多的偏向共性的特征也就是顶层特征,特征更偏向共性。所以底层特征更偏向细节信息,顶层特征更偏向共性信息,FPN 我们讲的特征金字塔网络提供的是一种融合的方案,融合顶层的共性特征和底层细节特征,我们认为融合生成的特征图是具有多尺度特征优势的,因此可以有利于后续的检测任务,
后续大家可能注意到尺寸不同的特征图可以直接相加吗?顶层特征图和底层特征图可以直接加吗?不行的,因为你直接相加会产生一定的位置偏差,所以 FPN 先上采样然后再相加,放缩到统一尺寸后再做融合,ResNet 和 FPN 合在一起是 DETR3D 图像处理框架的整体内容,其实大家也能看到图像处理模块其实都是通用处理网络,无论是 ResNet 也好还是 FPN 也好,均是已有的方法没有什么特殊的地方
那 OK,有了图像特征之后怎么用图像特征呢,这才是核心内容。那我们看下一个模块,特征转换模块,如下图所示:

我们先简单总结下特征转换模块的设计流程:
- 输入:多视角图像特征以及 Object Queries
- 步骤 1:提取 reference points
- 步骤 2:points ➡ image pixels
- 步骤 3:图像特征提取
- 步骤 4:2D 特征优化 3D 物体表征
- 输出:Object Features
我们一直强调先有什么呢,先有 Object Query,通过 Query 去取图像特征,要什么我们拿什么,那首先第一点我们要做的第一件事情,什么是 Object Query,Query 是什么意思呢?Query 其实是预先设置的向量,比如 2D 的 DETR 当中 Query 是 100 个或者 300 个,像 DETR3D 一般是取 300 或者 600 或者 900 个。每一个 Query 是 256 维的一个 Embedding 向量,那怎么去理解 Object Query 的意义呢,它其实这个词翻译过来叫目标查询,查询什么意思呢,我们就要去找,那我们要找什么,去找目标,所以说 Query 提供了一种找目标的方式
那说到这里是不是觉得和 Anchor 的思路很类似呢,在 2D 检测当中 Anchor 作为模板是遍历一整张图像的,2D 我们去预测的时候是去预测这个 Anchor 内有物体还是没有物体,物体偏移到什么位置。其实这 Object Query 从理解上和 Anchor 的动机类似,提供了一个预设位,按照预设位去找物体,那不同点在于 Anchor 一般是有先验信息的比如先验尺寸,但 Object Query 是直接 Embedding 初始化的。
我们说了这么多,其实大家理解 Query 的作用是什么呢,是随机初始化的一系列查询向量,用于查询空间当中哪里有物体,那我们怎么查,网络预测查,Query 通过 Transformer 结构预测生成一系列的 reference points,我们叫参考点,是 3D 的参考点,3D 参考点换一个词来表述的话其实是 3D Box 中心点坐标,也就是图中的 c l i \bold{c}_{li} cli,那么为什么叫参考点,像 DETR3D 其实是以 3D Reference Points 为基准点投影回多视角的 2D 特征图上采样 2D 特征,拿到特征之后与上一层我们输入的 Query 相加得到一个新的 Object Query,通过多次迭代这个过程 Query 是多次更新多次预测的
OK,我们再来理解一下这个过程,首先第一步是什么,是初始化一系列的 Object Query,我们给定 Query 数目比如说 300 或者 600 或者 900 个,给定 Query 的特征维度一般是多少,256 维的 Embedding 向量,直接对 Object Query 进行初始化,完事之后有了 Object Query 怎么和图像之间建立联系呢,通过 Object Query 我们可以算出一系列的参考点叫 3D Reference Points 即图中的 c l i \bold{c}_{li} cli, c l i \bold{c}_{li} cli 投影回 2D 图像平面,比如投影到了 c l m i \bold{c}_{lmi} clmi 这个点去对应的 2D 特征上采样 2D 特征,然后把多尺度的特征拼接成一个完整的特征向量返回到 f l i \bold{f}_{li} fli(图中未标注)上,用 f l i \bold{f}_{li} fli 去做当前 Object Query 的预测,通过这样一个迭代优化的过程拿到对应的图像特征之后再加上输入的 Query 特征得到迭代后的 Object Query,重复这个步骤然后输出最终的结果
所以其实 DETR3D 网络结构比较简单,它归纳来讲只包含两个模块,一个模块 Encoder 做图像特征编码模块,一个模块其实是做 Decoder,也就是我们这里花费了很大篇幅来尝试解释的一件事情,是做解码模块,基于 Query 的 Box 预测。
3. 损失函数
那下面我们来看一下网络框架明白了,损失函数是怎么计算的

我们知道 Object Query,一个 Query 对应的是一个预测结果,那么比如我们初始化了 900 个 Query,是不是就有 900 个预测结果,那这预测出来的 900 个结果怎么和我们的 GT(Ground Truth) 做损失函数的计算呢,那 DETR3D 和 DETR 2D 的部分是一致的,无非是把二分图匹配损失扩展到三维了,我们这里简单说下二分图匹配是怎么做的
以上图为例,二分图匹配是集合和集合之间的一个对应关系,比如上图中我们有一个预测集合,还有一个真值集合。我们比如有 900 个预测结果,那它组成一个预测量的集合,那我们真值中的数量也就是 GT 的数量其实是远远小于预测量的,也就是说我们 GT 的个数远远小于 900 个,两个集合量不一样我们怎么做比较呢,所以首先第一步把原本的 GT 集合去进行补齐,把 GT 的数量补全到预测集的数量,那当然补得时候也不能随便给一个 GT 值,所以是用空集去做补全的,其实可以认为是无关背景。此时我们得到两个等量集合,预测集 900 个,我们的真值集也有 900 个数目,然后用匈牙利算法对两个集合一一对应的匹配,使得匹配的损失最小,我们这里要注意的是它是一一对应的关系,那也就是说一个 GT 只能唯一确定一个预测结果,那这样做有什么好处呢
举个例子,我们当前有个 GT,它旁边有很多个预测结果,以前通用的 detector 是为了保证我们一个 GT 只对应一个结果,采用 NSM 算法也就是非极大值抑制方法,那顾名思义就是抑制不是极大值的元素从而保留置信度最高的框,比如一个 GT 我们对应了三个检测结果,我们最后可能只保留它检测置信度最高的唯一的一个,所以通过额外后处理的手段去保留我们需要的框,二分图匹配的好处是什么呢,它是两个集合元素内的一一对应关系,用了二分图匹配之后就不存在一个 GT 和多个预测结果之间的对应关系,一个 GT 只会和一个预测对应,它不存在歧义问题,所以说我们也不需要额外的后处理方法去处理一个 GT 和多个预测结果之间的对应关系
我们刚才讲的是 DETR2D 的二分图匹配损失过程,其实 3D 也是一样的,无非是 2D DETR 是 2D 结果,3D DETR 是 3D 的二分图匹配方法
那我们这里再给大家对 DETR 和 DETR3D 做一个简单对比,如下图所示:


图中上半部分是 DETR 的流程,以单张图像作为输入通过 Encoder 模块,一个 Transformer 的图像编码器可以得到图像特征,那也就是图像 Feature,那 Decoder 拿到图像特征和 Object Query 可以得到 2D 检测结果;图中下半部分是 DETR3D 的流程,DETR3D 同样也是以图像为输入,它的图像是多视角图像,一个 Multi-view images 通过 ResNet+FPN 得到图像特征,后续的 Decoder 模块拿到图像特征和 Object Query 得到最后 3D 结果
所以大家看到 DETR 和 DETR3D 结构非常相似,输入图像通过图像编码器通过解码器初始化一系列的 Object Query 就可以得到检测结果,无非区别在哪呢,图像编码器有点区别,一个是 Transformer 的结构一个是我们传统的结构,另外一个 DETR3D 需要适配 3D 任务,所以说怎么为 Object Query 补充 3D 特征,也就是说怎么去关注 2D 和 3D 之间特征点的匹配关系是 DETR3D 需要额外考虑的事情,那至于其他我们怎么去解码怎么去预测核心思想其实都是一样的
4. 性能对比
那我们接下来再来看一下性能对比,训练设置 DETR3D 的作者迭代次数设置的是 12 个 epoch,设备是 8 张 3090,然后它的 batch 是等于 1

表 1 是 nuScenes 验证集的结果,表 2 是测试集的结果,那作为纯视觉方案来讲 DETR3D 的性能还是可以的,我们还是重点来看一下它的消融实验部分是怎么做的

表 3 讨论的是 overlap region 的问题,什么叫 overlap region 呢,它翻译过来叫重复的区域,重叠区域,我们知道 nuScenes 是一个多视角的数据集,比如我们有个前视角,旁边可能也有一个前左视视角,两个视角之间存在一定的重叠区域我们叫 overlap。传统的做法它对于多视角图像是怎么处理呢,比如我的视角 1 有一个预测值,视角 2 也有一个预测值,两个视角是独立工作的,每个视角均有一个预测值,那么显然它是没有办法对重叠区域采用多视角的特征进行预测的,因为它对每个视角是独自处理的
但相反我们的 DETR3D 是不是可以做到利用重复特征去预测呢,我们讲的 3D reference point 是对多视角分别投影,比如我有一个 3D reference point,投影回视角 1 的时候投影在重叠区域我们拿一次特征,投影回视角 2 的时候又投影到这个重叠区域了我们再拿一次特征,是可以通过多视角特征进行融合的,所以对于重叠区域 DETR3D 的检测融合的是多视角的特征,相比可能单一视角的检测而言性能自然是有明显提升的
那表 4 是一个 pseudo-LiDAR 的方法,那这个方法我们在基础模块中也讲过 pseudo-LiDAR 怎么生成呢,通过 2D 原始图像和 2D 预测的深度图可以直接在 3D 空间中生成一系列的伪点云,伪点云是可以直接通过 3D 网络框架进行处理的,那所以本文作者也提供了一个伪点云的 nuScenes 的结果和它自己的方法进行一个比较,比伪点云的方法有了明显的提升。伪点云我们之前也讲过主要存在什么问题呢,深度估计不准的问题,而 DETR3D 其实一定程度上避免了深度误差的影响的

表 6 中讨论了 Query 的数量问题,我们说 Query 是目标查询,其实囊括的是 3D 场景当中物体可能出现的位置,那 3D 场景很大,比如说我们仅仅依靠 30 个或者 100 个 Query 很难涵盖周全,因此我们也能看到如果仅仅使用 30 个或者 100 个 Query 性能不是特别好的。那 Query 的数量是不是越多越好呢,也不是,你能看到其实从 600 到 1500 的 Query 性能已经趋近于饱和了,那也就是说我们这么多的 Query 我们认为对于初始位置的假设已经足够了,那么大家可能会问既然 Query 已经足够了那它的性能怎么不是百分百呢,所以它其实后续的问题不是 Query 的原因,初始位置给得再好它也只是一个位置,后续性能涉及到方方面面,包括图像特征提取得好不好,Decoder 设计得好不好,损失函数设计得好不好,有没有合适的优化策略等等

表 7 提供的是 Backbone 的一个结果,我们文中也讲了初始的 Backbone 是什么呢,是 ResNet+FPN,那所以作者这里提供了两个 ResNet 框架的结果,一个是 ResNet50 一个是 ResNet101,同时提供了 DLA 的结果,框架的选择其实是一个比较 trick 的过程,可以多试试看不同的网络

我们再来接着看,表 5 和上图其实说的是同一个事情,是针对 Layer 的分析,也就是我们 Decoder Head 一共有 6 层的 Decoder Head,每一层的输入是 Object Query Feature,输出是预测结果。通过 Decoder Layer 的叠加性能总体来讲是越来越好的,可视化结果也能看到我们一开始可能会有一些重复框或者误检的结果,那随着我们 Layer 数的叠加我们检测结果越来越好,慢慢的重复框和这些误检结果就没有了,我们的预测值和提供的 GT 是越来越接近了

那最后论文的作者也展示了检测结果,我们看一下其实其中还是存在很多 failure case 的,一些性能不太好的地方。首先第一点它对于远距离比如离得比较远的地方,存在一些漏检和误检的结果,其次 DETR3D 对于尺寸的建模不是特别好,大家可以看一下我们在 GT 中有的车是很长的,我们预测结果车相对而言是很短的,我们可以猜测一下产生这样尺寸差异的原因是什么呢,这可能和 DETR3D 本身设计的方法有关,我们说 DETR3D 是从 3D 生成 reference point 到 2D 的投影过程,那本身 reference points 是一个很局部的,很 local 的一个点,所以它投影到 2D 上面它也只能采样到一小部分区域的图像,那么仅仅依靠着一小部分的区域特征是很难预测一个尺寸比较大的物体的,比如公交车或者大尺寸的物体
我们本次 DETR3D 的内容到这里就结束了,下节我们会给和大家一起学习另外一个经典框架叫 BEVFormer
总结
这节课程我们学习了一个非常经典的纯视觉 BEV 感知算法叫做 DETR3D,DETR3D 其实是 DETR 在 3D 领域的延伸。我们都知道 BEV 感知算法的核心是视角转换模块,那以往的视角转换方法是从 2D 到 3D 再到 BEV,而 DETR3D 作者不是这么做的,他是从 3D 到 2D,通过 Object Query 生成一系列的 3D 参考点,将 3D 参考点投影到 2D 图像平面上去采样特征,然后将多尺度特征拼接成完整的特征向量去做当前 Object Query 的预测,通过这样一个不断迭代优化的过程后输出最终的检测结果。此外,DETR3D 的损失函数沿用的是 DETR 的二分图匹配损失,每个 GT 只会和一个预测结果对应,不再需要额外的后处理方法。
OK,以上就是 DETR3D 的全部内容了,下节我们学习另外一篇非常经典的框架 BEVFormer,敬请期待😄
下载链接
- 论文下载链接【提取码:6463】
- 数据集下载链接【提取码:data】
参考
- [1] Wang et al. Detr3d: 3d object detection from multi-view images via 3d-to-2d queries