C++STL标准库与泛型编程
STL六大部件
- 容器 Containers
- 分配器 Allocators 一种用来修饰容器或仿函数或迭代器接口的东西
- 算法 Algorithms
- 迭代器 Iterators
- 适配器 Adapters
- 仿函数 Functors

容器

前闭后开
大致分为两种容器:序列容器,关联容器
所谓关联容器,就是key和value的结构
序列容器:array、vector、deque、list、forward-list
关联容器:set、multiset、map、multimap,实现使用红黑树(高度平衡二叉树)做的
C++11中有Unordered容器,但他也属于关联容器,实现使用hash table做的
vector<int> c;
vector<int>::iterator ite = c.begin();
for (; ite != c.end(); ++ite);
对于关联式容器,在循环中使用erase,需要在erase中it++;对于序列式容器,不需要++操作;erase操作返回的是删除当前迭代器的下一个迭代器

list

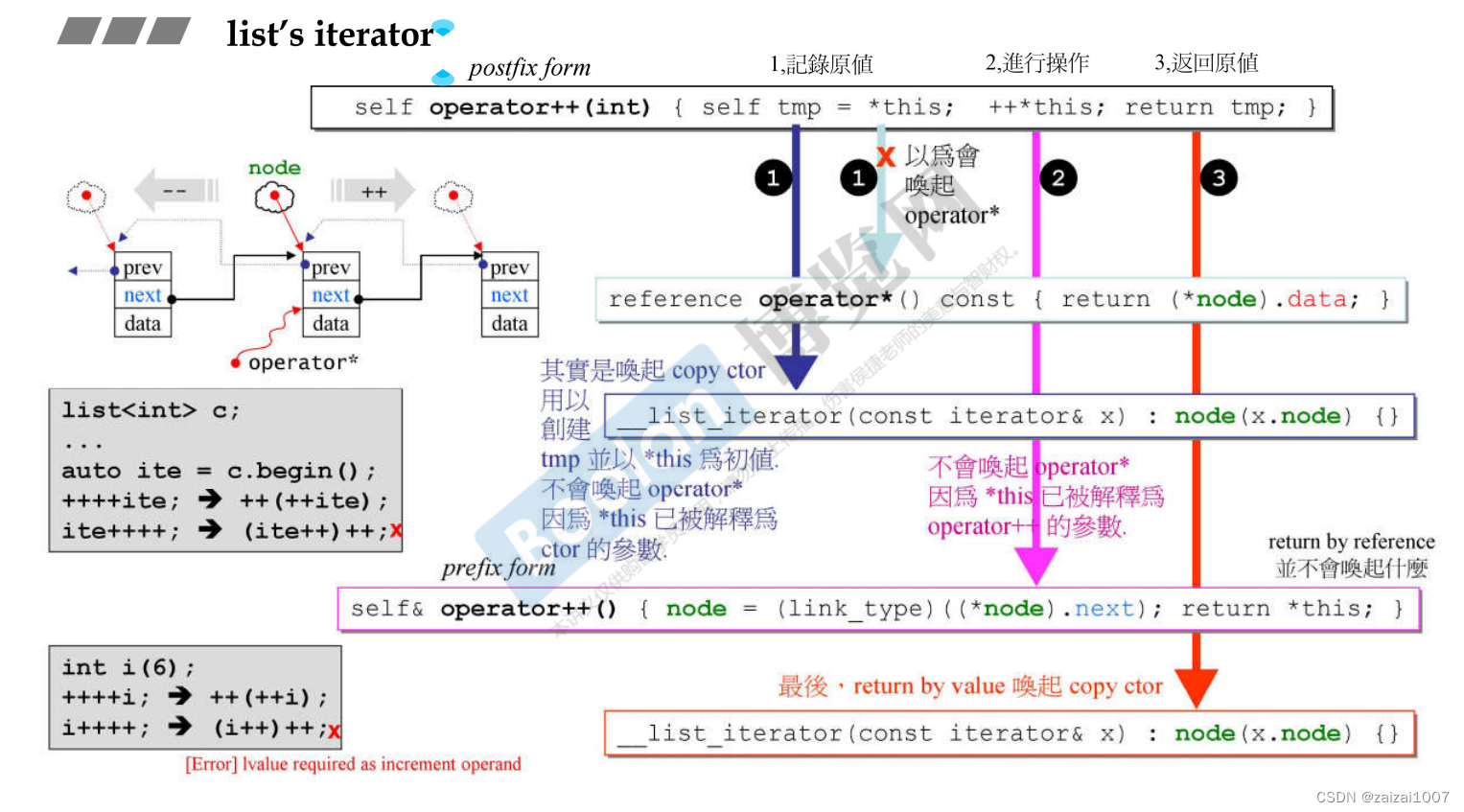
前++ 和 后++ 本身都没有参数,但是为了区分定义,后++的函数定义上有一个形式上的参数,但是没有用,只是为了区分
后++ 的返回值不是reference ,所以不能连串后++
为什么要有这么多typedef?
一定要有5个typedef,也就是下图中括号行。这就牵扯到了迭代器的Traits(特征特性)设计。
迭代器需要遵循的原则:迭代器是连接容器和算法的中间件,因此迭代器必须能够回答算法的一些提问,这样算法才能更好的对容器进行操作。这5种迭代器关联类型分别为:pointer、reference、iterator_category(迭代器类型,比如说随机存取)、value_type(值存放类型)、difference_type(容器两个元素之间的距离类型)。
类中才能typedef,那如果一个迭代器不是一个类呢,他就不能回答算法的问题了?因此,会引入Traits机作为中间层,接收类迭代器和指针迭代器,会做相应的工作(模板偏特化),得到指针的5种迭代器关联类型。
vector
容器容量按2倍增长,扩充的时候需要找到和当前容量两倍大的连续的内存才行
在进行增长的时候,会调用大量的构造函数
Deque

Deque 两端开口
其中是一个一个的 buffer ,Deque 做出其中是连续的假象

map会将这些分段的node给串起来。
node指向map的哪一块
first和last指的是node的边界
cur指向当前node的元素
还会有一个start和finish的迭代器,保存双向队列的两端头元素。
map不够大,也会二倍扩充。
deque还需要指定buffer size,也就是每一个buffer容纳的元素个数,默认是0,就会做相应的操作来存放默认数量的元素,但是肯定不会是让一个buffer存放0个元素的。迭代器类型用的是随机存取(也就是连续的)是deque类做的伪装。迭代器做了模拟连续空间的操作!
deque<int> c;
c.push_back(2);
c.pop_back();
c.push_front(2);
c.pop_front();
c.max_size();
c.front();
c.back();
stack
stack<int> c;
c.push(2);
c.pop();
c.top();
c.size();
queue
queue<int> c;
c.push(2);
c.pop();
c.front();
c.back();
c.size();
RB-Tree
红黑树是平衡二分搜索树的一种。平衡二分搜索树的特征:排列规则有利于 search 和 insert,并保证适当平衡--无任何节点过深

使用红黑树,有5个模板参数。sizeof(RBTree)=12(GNU2.9)。为什么要在右下角放双向链表呢?因为红黑树和双向链表都有一个不用的节点,双向链表是end后面的节点,红黑树是头节点。


set
map
这两种方法和前面的multi xx 使用方法一样,只是不允许有重复的key值。
map可以通过下标[]来插入
set不能够通过迭代器来修改容器里面的key值,因为是根据key来进行排序,实现的方法是使用const的迭代器。
map也不能够修改key值,但是可以修改key对应的value值,具体的实现方法是RBTree的迭代器指定模板参数的时候,value_type对应的类型为pair<const key, T>,即key是const类型的,但是value不是。
set和map大多数工作都是交给RBTree,从这个角度看,set和map也是一种容器适配器
unordered开头的容器,之前是用hash开头
HashTable
使用hash表,冲突采用拉链表法.
如果元素的大小和bucket的大小一样大了(不管有没有填满),就会扩充bucket的大小,变为当前bucket大小的倍数附近的质数,然后每个元素rehash,插入。这是一条经验法则。
需要指定6个模板参数!ExtractKey是放入的Object的Key,EqualKey是比较函数,使用hashtable最困难的事决定使用什么hash函数

具体写一个使用hashtable的例子:
标准库没有提供现成的hashstd::string
hashtable<
const char*,
const char*,
hash<const char*>,
identity<const char*>,
eqstr,
alloc>
ht(50, hash<const char*>(), eqstr());
multiset

multimap

array
是C语言本来就有的东西,为什么要把他包装成容器?因为要让他有容器的行为,要有迭代器,才能配合算法。必须指定大小,不能拓展。没有构造函数,没有析构函数!

array<long, msize> c;
c.size();
c.front();
c.back();
c.data();//返回array的起点地址
qsort(c.data(), msize, sizeof(long), compareLong); // 快速排序,指定地址,多少个元素,每个元素大小是多少,比较方法是怎样
bsreach(&target, c.data(), msize, sizeof(long), compareLong); //二分查找,指定查找对象
forward_list
forward_list<int> c;
c.push_front(); //头插
c.max_size();
c.front();
//无c.back()
//无c.size()
分配器 allocator
比如说vector的模版定义如下,会有一个默认的分配器std::allocator<_Tp>,如果不指定分配器,就会默认使用这一个
template<typename _Tp, typename _Alloc = std::allocator<_Tp>>
class vector : protected _Vector_base<_Tp, _Alloc>

容器需要一个东西来支持它对内存的使用,这个东西就是分配器,最好的情况下,我们不需要知道这个东西,所以需要一个默认的分配器。
malloc 会自带一个固定大小的header

有效空间只占其中的一部分,如果每次malloc一个小空间然后多次malloc,那么header的所占空间将会大的无法忍受
这些额外开销有什么用呢?00000041是两个cookie,保存了这个内存块的大小。但是对于容器来说,容器的一个块大小是固定的,有必要使用这个cookie吗?可以不要。
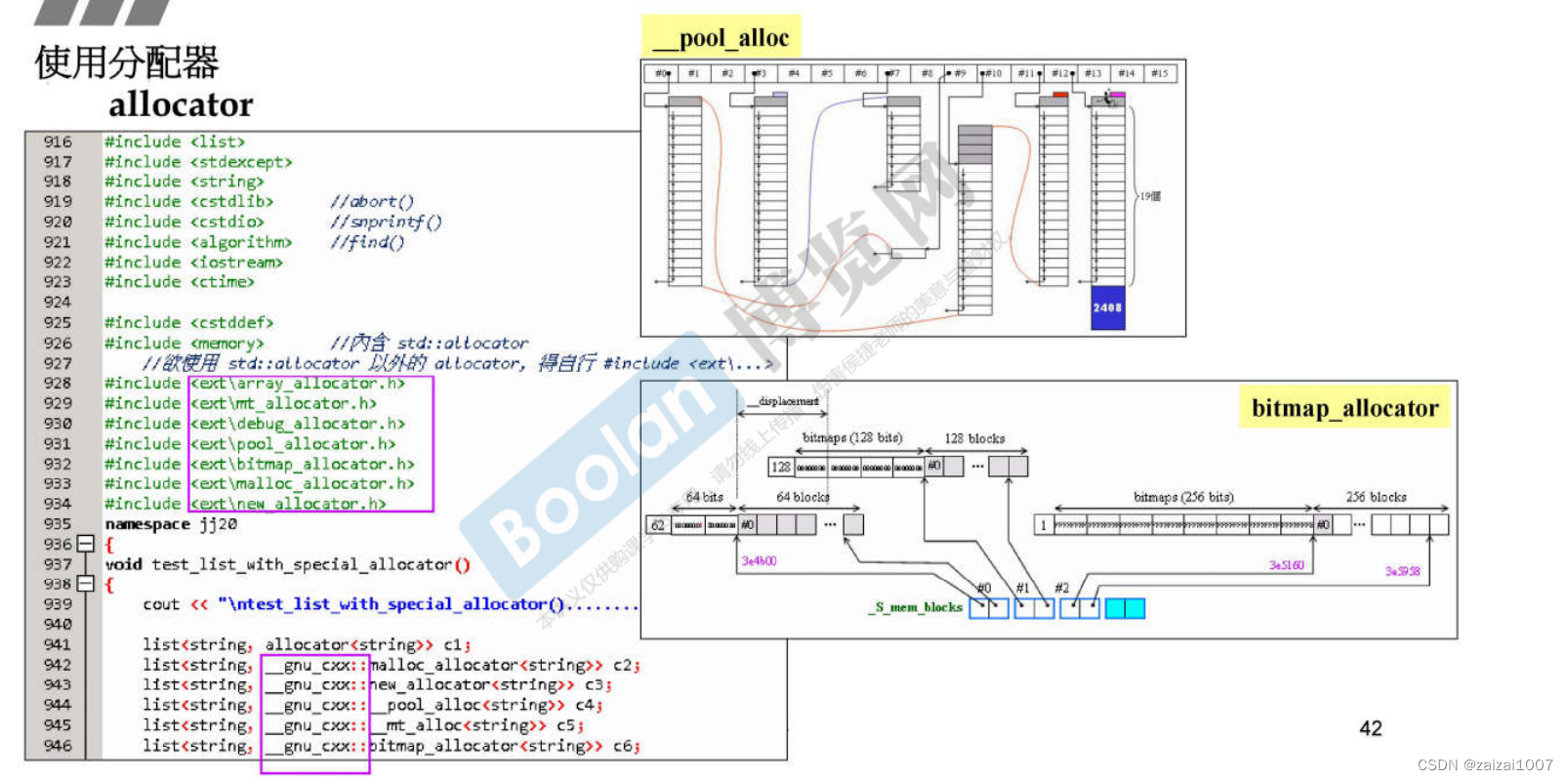
GNU2.9使用的是alloc,解决了上面的疑问(额外开销的问题)!实现行为如下,主要的思路就是减少malloc的次数,因为malloc一次就会附带一个头尾。

16条链表,负责不同大小的内存分配。8字节对齐。每个内存块不会都带cookie。只会在链表的头尾有cookie。
迭代器
前面说到迭代器中必须要有5种关联类型:pointer、reference、iterator_category(迭代器类型,比如说随机存取)、value_type(值存放类型)、difference_type(容器两个元素之间的距离类型)。
iterator_category
也有五种迭代器类型:随机存取迭代器(array、vector、deque)、双向迭代器(list、红黑树容器)、单向迭代器(forward_list,hash类容器)、输入迭代器(istream迭代器),输出迭代器(ostream迭代器)。

iterator_category对算法的影响
以这个distance函数为例,会根据迭代器的类别来调用不同的具体实现函数,一个是只包含一个减法操作的语句,一个是包含一个while循环的语句,可想而知,当真实距离很大时,有while循环的具体实现函数效率会非常低下。

如果是随机存取的内存连续的容器的迭代器,就可以直接用尾指针减去头指针计算 distance ,但是如果不是的话,就只能一步一步走一个一个算,比较费时
看一个特别能体现C++注重效率的体现:
copy实现,到最终的实现细节,经过了很多判断,这些判断是为了找到最高效率的实现,就是判断迭代器的分类。

算法
必须要是下面的两种形式的函数,才是STL中的算法,比如说qsort和bsreach的参数就不是传入迭代器,所以不是C++STL中的算法,而是C中的函数。
template<typename Iterator>
Algorithm(Iterator it1, Iterator it2){
...
}
template<typename Iterator, typename Cmp>
Algorithm(Iterator it1, Iterator it2, Cmp comp){
...
}
算法看不见容器,关于容器的一切信息都必须通过迭代器获得,所以又和前面的Traits机联系到一起了。
accumulate(InputIterator first, InputIterator last, T init)
另外一个版本为:accumulate(InputIterator first, InputIterator last, T init, BinaryOperation binary_op)
上面这个binary_op指明是一个二元操作数的函数,可以是仿函数(实质上是一个类),也可以是函数,只要是能够在该算法的函数体内通过小括号调用就行!!!!也就是能够这么用:binary_op(a, b);所以,之前的疑虑就可以消除了。就算是在算法(函数)里面,也能够使用仿函数,但是传入的是仿函数的对象实例,而如果要传入函数的话,就传函数名就可以了。
int init = 100;
int nums[] = {10,20,30};
accumulate(nums, nums+3, init);//不指定具体怎么操作,默认为加法,输出160
accumulate(nums, nums+3, init, minus<int>()); //这minus时减法的意思,所以输出为40
lower_bound(ForwardIterator first, ForwardIterator last, T target)
二分查找的一个版本,如果找到对应的值,则返回指向其中第一个元素的迭代器,如果不存在,则返回最适合安插这个target的点的迭代器 ,也就是说它返回迭代器指向第一个不小于target的元素,也就是说它返回的是不破坏排序得以安插target的第一个适当位置
upper_bound(ForwardIterator first, ForwardIterator last, T target)
binary_search(ForwardIterator first, ForwardIterator last, const T& value)
源码中就是调用lower_bound
for_each(InputIterator first, InputIterator last, Function f)
对容器区间内的元素做同样的事情
replace(ForwardIterator first, ForwardIterator last, const T& old_value, const T& new_value)
将容器区间内的元素进行替换,如果元素值等于old_value就把它替换为new_value.
replace_if(ForwardIterator first, ForwardIterator last, Predicate pred, const T& new_value)
Predicate为一个条件,判断式子,如果符合条件就进行替换
replace_copy(ForwardIterator first, ForwardIterator last, OutputIterator result, const T& old_value, const T& new_value)
范围内所有等同于old_value的都以new_value放置新的区间中,不符合原值的也放入新的区间
count(InputIterator first, InputIterator last, const T& value)
区间内有和value相等的元素count+1。
红黑树、hash容器中有自己的count
count_if(InputIterator first, InputIterator last, Predicate pred)
区间内有符合pred条件的count+1
find(InputIterator first, InputIterator last, const T& value)
循序查找,返回第一个和value相等的迭代器
红黑树、hash容器中有自己的find
find_if(InputIterator first, InputIterator last, const T& value)
循序查找,查找符合条件的第一个元素的迭代器
sort(InputIterator first, InputIterator last, Function f)
默认从小到大排序,也可以指定自己的比较函数,可以是仿函数,可以是函数,仿函数必须传入该仿函数的实例。
reverse iterator ,rbegin() rend 逆向迭代器

仿函数
只为算法服务
有三种仿函数:算术类(+、-、*、/等)、逻辑运算类(&&、 ||等)、相对关系类(返回bool),一共大概24个仿函数。

给一个加法的仿函数
template<class T>
struct plus : public binary_function<T, T, T>{
T operator()(const T& x, const T& y) const{
return x + y;
}
}
再写写binary_function的定义:
template<class Arg1, class Arg2, class Result>
struct bianry_fucntion{
typedef Arg1 first_argument_type;
typedef Arg2 second_argument_type;
typedef Result result_type;
}
为什要让仿函数继承这些类呢?
首先,继承他们,不会增加仿函数的内存大小,其次,继承了他们,会有了first_argument_type等的typedef,后续可以根据这个类型进行一些修改。
一个仿函数的可适配条件是什么?就是必须(合适地)继承binary_function,unary_function等类,才能回答适配器的问题,就像Traits机要回答迭代器的问题一样。
一个示例:
template<class Pair>
struct select1st :public unary_function<pair, typename Pair::first_type>
{
const typename Pair::first_type& operator()(const Pair& x) const
{
return x.first;
}
};参考文章:侯捷C++八部曲笔记(二、STL标准库和泛型编程)_侯捷stl_Wanncye的博客-CSDN博客
参考书籍:《STL源码剖析》