文章目录
- 一、k3s简介
- 二、快速搭建
- 1.控制平面
- 2.镜像加速
- Pod容器集
- 1.创建和管理pod
- Deployment(部署)与ReplicaSet(副本集)
- 滚动更新
- Service
- 命名空间
- YAML语法
- 管理对象
- 常用命令缩写
- YAML规范
- 声明式配置对象
- 标签
- 选择器
- 容器运行时接口(CRI)与镜像导入导出
- 容器运行时接口(CRI)
- 金丝雀发布
- 创建Canary Deployment
- 局限性
- 运行有状态应用(MySQL数据库)
- 存储
- 创建Mysql
- 配置环境变量
- hostPath卷
- ConfigMap与Secret
- ConfigMap
- ConfigMap用法
- Secret
- 卷(Volume)
- 常见的卷类型
- 后端存储
- 临时卷(EV)
- 临时卷(Ephemeral Volume)
- emptyDir
- configMap卷和secret卷
- 持久卷(PV)与持久卷声明(PVC)
- 持久卷(PV)和持久卷声明(PVC)
- 创建持久卷(PV)
- 创建持久卷声明(PVC)
- 使用PVC作为卷
- 绑定
- 访问模式
- 卷的状态
- 卷模式
- 存储类(StorageClass)
- 创建持久卷(PV)
- 存储类(StorageClass)
- Local Path Provisioner
- 卷绑定模式
- 回收策略(Reclaim Policy)
- StatefulSet(有状态应用集)
- StatefulSet
- 创建StatefulSet
- 稳定的存储
- Pod 标识
- 部署和扩缩保证
- Headless Service(无头服务)
- 无头服务(Headless Services)
- 稳定的网络 ID
- Mysql主从复制
- Mysql主从复制
- 初始化容器(Init Containers)
- 边车Sidecar
- 客户端连接
- Port-forward端口转发
- 网络访问
- Helm安装MySQL机群
- Helm简介与安装
- 三大概念
- Helm部署MySQL集群
- 部署若依(RuoYi-Vue)
一、k3s简介
为什么使用K3s?
K3s 是一个轻量级的、完全兼容的 Kubernetes 发行版本。非常适合初学者。
K3s将所有 Kubernetes 控制平面组件都封装在单个二进制文件和进程中,文件大小
<100M占用资源更小,且包含了kubernetes运行所需要的部分外部依赖和本地存储提供
程序。
K3s提供了离线安装包,安装起来非常方便,可以避免安装过程中遇到各种网络资源访问
问题。
K3s特别适用于边缘计算、物联网、嵌入式和ARM移动端场景
二、快速搭建
1.控制平面
INSTALL_K3S_SKIP_DOWNLOAD=true ./install.sl
查看
watch -n 1 kubectl get node
记住token 使节点加入控制平面
cat /var/lib/rancher/k3s/server/node-token
工作节点
INSTALL_K3S_SKIP_DOWNLOAD=true \
K3S_URL=https://192.168.1.55:6443 \
K3S_TOKEN=xxx \
./install.sh
2.镜像加速
由于kubernetes从V1.24版本开始默认使用 containerd,
需要修改containerd的
配置文件,才能让Pod的镜像使用镜像加速器。
配置文件路径一般为 /etc/containerd/config,toml,详见阿里云镜像加速
查看containerd的一个进程
ps -ef | grep containerd
k3s会自动生成一个目录

K3s 会自动生成containerd的配置文件/var/lib/rancher/k3s/agent/etc/containerd/config.toml,
不要直接修改这个文件,k3s重启后修改会丢失。
为了简化配置,K3s 通过/etc/rancher/k3s/registries.yaml文件来配置镜像仓库,K3s
会在启动时检查这个文件是否存在。
我们需要在每个节点上新建/etc/rancher/k3s/registries.yaml文件,配置内容如下:
mirrors:
docker.io:
endpoint:
- "地址"
然后systemctl restasrt k3s重启k3s
然后再查看/etc/rancher/k3s/registries.yaml
配置其他工作节点**(可能需要创建)**
cd /etc/rancher/k3s/
vim registries.yaml
重启node节点systemctl restart k3s-agent
Pod容器集
Pod 是包含一个或多个容器的容器组,是 Kubernetes 中创建和管理的最小对象。
Pod 有以下特点:
- Pod是kubernetes中最小的调度单位 (原子单元),Kubernetes直接管理Pod而不是容
器。 - 同一个Pod中的容器总是会被自动安排到集群中的同一节点 (物理机或虚拟机)上,并且
一起调度 - Pod可以理解为运行特定应用的“逻辑主机”,这些容器共享存储、网络和配置声明(如资
源限制)。 - 每个 Pod 有唯一的IP 地址。IP地址分配给Pod,在同一个 Pod 内,所有容器共享一个
IP 地址和端口空间,Pod 内的容器可以使用locathost互相通信
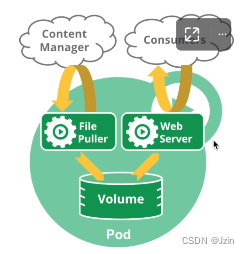
例如,你可能有一个容器,为共享卷中的文件提供 Web 服务器支持,以及一个单独的“边
车(sidercar)”容器负责从远端更新这些文件,如下图所示:
1.创建和管理pod
基于docker基础 会docker一点即通
创建nginx
kubectl run mynginx --image=nginx:1.22
查看pod
kubectl get pod
查看日志
kubectl logs -f mynginx
查看pod详细信息
kubectl describe pod mynginx
查看pods详细信息
kubectl get pod -owide
可以自行curl访问
进入pod
kubectl exec -it mynginx -- /bin/bash
一次性pod
kubectl run my-busybox --image=busybox -it --rm
删除pod
kubectl delete pod mynginx
Deployment(部署)与ReplicaSet(副本集)
Deployment是对ReplicaSet和Pod更高级的抽象
它使Pod拥有多副本,自愈,扩缩容、滚动升级等能力。
ReplicaSet(副本集)是一个Pod的集合
它可以设置运行Pod的数量,确保任何时间都有指定数量的 Pod 副本在运行
通常我们不直接使用ReplicaSet,而是在Deployment中声明。
创建Deployment 容量为3
kubectl create deployment nginx-deploy --image=nginx:1.22 --replicas=3
查看Deployment(可以缩写)
kubectl get deploy
实际上 并不是deployment创建的pod 而是通过ReplicaSet控制副本的数量 deployment只是声明(可能比较抽象)
可以查看replicaset对应关系
kubectl get replicaSet
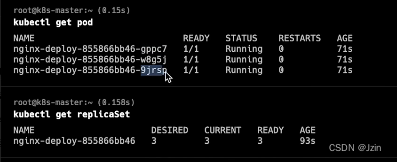
可以删除pod测试 是具备自愈能力的
也可以缩放副本
先watch实时查看
kubectl get replicaSet --watch
再开一个窗口
kubectl scale deploy nginx-deply --replicas=5
kubectl scale deploy nginx-deply --replicas=3
也可以自动缩放
#自动缩放 维持cpu负载在75%以下
kubectl autoscale deployment/nginx-auto --min=3 --max=10 --cpu-percent=75
#查看自动缩放
kubectl get hpa
#删除自动缩放
kubectl delete hpa nginx-deployment
自动缩放
自动缩放通过增加和减少副本的数量,以保持所有 Pod 的平均 CPU 利用率不超过75%
自动伸缩需要声明Pod的资源限制,同时使用 Metrics Server 服务(K3s默认已安装)
本例仅用来说明 kubectl autoscale 命令的使用,完整示例参考: HPA演示
滚动更新
打印详情
kubectl get deploy -owide
可以使用set命令来更新pod
先watch实时查看ReplicaSet(可以缩写rs)
kubectl get rs --watch
kubectl set image deploy/nginx-deploy nginx=nginx:1.23
可以自行体验理解上下线顺序
也可以回滚
查看部署版本
kubectl rollout history deploy/nginx-deploy
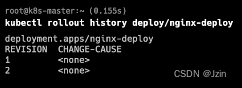
有2个版本
可以使用revision查看版本详情
kubectl rollout history deploy/nginx-deploy --revision=1
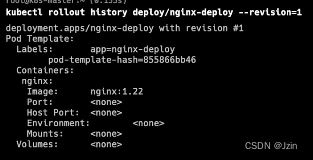
进行回滚
kubectl rollout undo deploy/nginx-deploy --to-revision=1
可以使用实时rs观察变化
Service
Service将运行在一组 Pods 上的应用程序公开为网络服务的抽象方法
Service为一组 Pod 提供相同的 DNS 名,并且在它们之间进行负载均衡。
Kubernetes 为 Pod 提供分配了IP 地址,但IP地址可能会发生变化。
集群内的容器可以通过service名称访问服务,而不需要担心Pod的IP发生变化
Kubernetes Service 定义了这样一种抽象:
逻辑上的一组可以互相替换的 Pod,通常称为微服务
Service 对应的 Pod 集合通常是通过选择算符来确定的。
举个例子,在一个Service中运行了3个nginx的副本。这些副本是可互换的,我们不需要
关心它们调用了哪个nginx,也不需要关注 Pod的运行状态,只需要调用这个服务就可以了。
我们可以将之前的deploy公开为service
向外公开8080 向pod指定80
kubectl expose deploy/nginx-deploy --name=nginx-service --port=8080 --target-port=80
查看service
kubectl get service
service之间是有负载均衡的 通过service名称
可以启动一个临时的pod测试
kubectl run test -it --image=nginx:1.22 --rm --bash
curl测试
查看这个service
kubectl describe service nginx-service
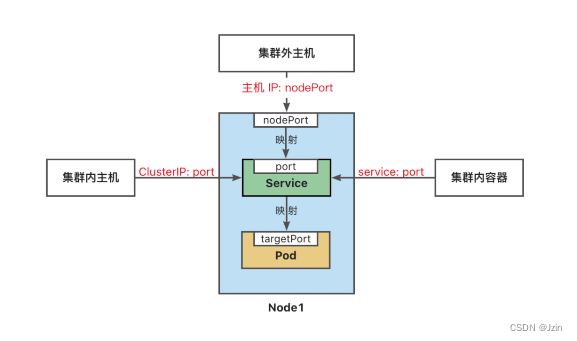
将service公开到哪?
如果要向外网指定端口 要指定service的类型 前面用的是ClusterlP
ServiceType 取值
- ClusterlP:将服务公开在集群内部。kubernetes会给服务分配一个集群内部的IP,集
群内的所有主机都可以通过这个Cluster-IP访问服务。集群内部的Pod可以通过service
名称访问服务 - NodePort: 通过每个节点的主机IP 和静态端口 (NodePort) 暴露服务。
集群的外部主
机可以使用节点IP和NodePort访问服务。 - ExternalName:将集群外部的网络引入集群内部
- LoadBalancer: 使用云提供商的负载均衡器向外部暴露服务
在创建一个service
kubectl expose deploy/nginx-deploy --name=nginx-outside --type=NodePort --port=8081 --target-port=80
查看分配的port进行访问
kubectl get service
总结service
命名空间
命名空间(Namespace) 是一种资源隔离机制,将同一集群中的资源划分为相互隔离的组
命名空间可以在多个用户之间划分集群资源 (通过资源配额)
- 例如我们可以设置开发、测试、生产等多个命名空间
同一命名空间内的资源名称要唯一,但跨命名空间时没有这个要求
命名空间作用域仅针对带有名字空间的对象,例如 Deployment、Service 等。
这种作用域对集群访问的对象不适用,例如 StorageClass、Node、PersistentVolume等。
查看命名空间
kubectl get namespace
Kubernetes 会创建四个初始命名空间:
- default 默认的命名空间,不可删除,未指定命名空间的对象都会被分配到default
中。 - kube-system Kubernetes 系统对象(控制平面和Node组件)所使用的命名空间
- kube-public 自动创建的公共命名空间,所有用户(包括未经过身份验证的用户)都
可以读取它。通常我们约定,将整个集群中公用的可见和可读的资源放在这个空间中 - kube-node-lease 租约 (Lease) 对象使用的命名空间。每个节点都有一个关联的
lease 对象,lease 是一种轻量级资源。lease对象通过发送心跳,检测集群中的每个节
点是否发生故障。 - 使用
kubectl get lease -A查看lease对象
创建新的namespace(可以缩写ns)
kubectl create ns develop
运行pod时加入ns
kubectl run nginx --image=nginx:1.22 -n=develop
查看指定命名空间下的pod
kubectl get pod -n=develop
可以设置默认的命名空间为develop
kubectl config set-context ${kubectl config current-context} --namespace=develop
kubectl get pod
删除ns会删除所有内容
kubectl delete ns develop
kubectl get ns
YAML语法
管理对象
命令行指令
例如,使用 kubectl命令来创建和管理 Kubernetes 对象
命令行就好比口头传达,简单、快速、高效。
但它功能有限,不适合复杂场景,操作不容易追溯,
多用于开发和调试
声明式配置
kubernetes使用yaml文件来描述 Kubernetes 对象
声明式配置就好比申请表,学习难度大且配置麻烦
好处是操作留痕,适合操作复杂的对象,多用于生产
常用命令缩写

YAML规范
- 缩进代表上下级关系
- 缩进时不允许使用Tab键,只允许使用空格,通常缩进2个空格
:键值对,后面必须有空格-列表,后面必须有空格[ ]数组#注释|多行文本块---表示文档的开始,多用于分割多个资源对象
示例:
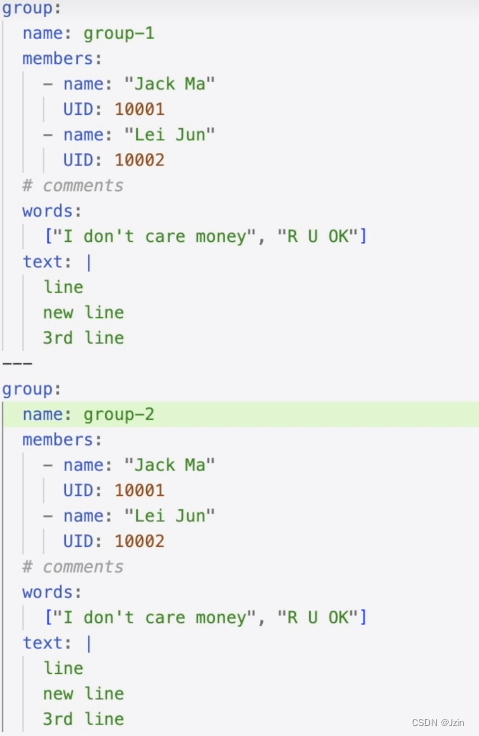
声明式配置对象
在创建的 Kubernetes 对象所对应的 yaml文件中,需要配置的字段如下:
apiversion- Kubernetes API的版本kind-对象类别,例如Pod、Deployment、Service、ReplicaSet等retadeta- 描述对象的元数据,包括一个 name 字符串、UID 和可选的 namespacespee-对象的配置
掌握程度:
- 不要求自己会写
- 找模版
- 能看懂
- 会修改
- 能排错
官方模板:https://kubernetes.io/zh-cn/docs/reference/kubectl/cheatsheet/
模板示例:
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:1.22
ports:
- containerPort: 80
运行:
kubectl apply -f my-pod.yaml
标签
标签 (Labels) 是附加到对象 (比如 Pod) 上的键值对,用于补充对象的描述信息
标签使用户能够以松散的方式管理对象映射,而无需客户端存储这些映射。
由于一个集群中可能管理成千上万个容器,我们可以使用标签高效的进行选择和操作容器
集合。
https://kubernetes.io/zh-cn/docs/concepts/overview/working-with-objects/labels/
键的格式:
前缀(可选)/名称(必须)
有效名称和值:
- 必须为 63 个字符或更少 (可以为空)
- 如果不为空,必须以字母数字字符 ([a-z0-9A-Z]) 开头和结尾
- 包含破折号一、下划线 、点,和字母或数字
例子:
apiVersion: v1
kind: Pod
metadata:
name: label-demo
labels:
environment: production
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.22
ports:
- containerPort: 80
运行
kubectl apply -f lable-pod.yaml
查看lable
kubectl get pod --show-albles
过滤
kubectl get pod -l "app-nginx"
如果有多个用,分割
选择器
标签选择器 可以识别一组对象。标签不支持唯一性
标签选择器最常见的用法是为Service选择一组Pod作为后端
Service配置模版
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
type: NodePort
selector:
app: nginx
ports:
# 默认情况下,为了方便起见,`targetPort` 被设置为与 `port` 字段相同的值。
- port: 80
targetPort: 80
# 可选字段
# 默认情况下,为了方便起见,Kubernetes 控制平面会从某个范围内分配一个端口号
#(默认:30000-32767)
nodePort: 30007
运行
kubectl apply -f my-service.yaml
查看
kubectl get svc
查看详情
kubectl describe svc/my-service
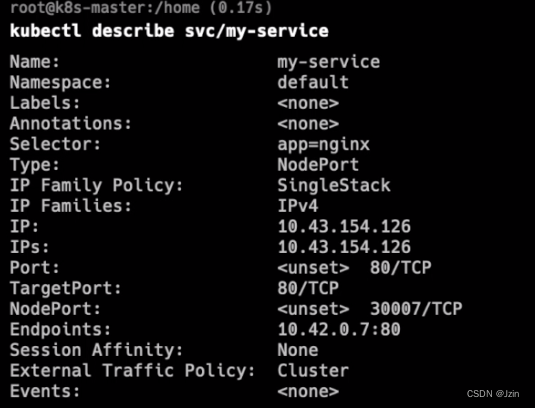
也可以过滤标签
kubectl get pod -l "app=nginx" -owide
目前支持两种类型的选择运算:基于等值的和基于集合的
多个选择条件使用逗号分隔,相当于**And(&&)**运算。
- 等值选择
容器运行时接口(CRI)与镜像导入导出
容器运行时接口(CRI)
Kubelet运行在每个节点(Node)上,用于管理和维护Pod和容器的状态。
容器运行时接口 (CRI)是kubelet 和容器运行时之间通信的主要协议。它将 Kubelet 与
容器运行时解耦,理论上,实现了CRI接口的容器引擎,都可以作为kubernetes的容器运
行时。
Docker没有实现 (CRI) 接口,Kubernetes使用 dockershim 来兼容docker。
自V1.24版本起,Dockershim 已从 Kubernetes 项目中移除。
crictl是一个兼容CRI的容器运行时命令,他的用法跟 docker 命令一样,可以用来检
查和调试底层的运行时容器。
查询运行时的容器
circtl ps
查询镜像
circtl images
在一些局域网环境下,我们没法通过互联网拉取镜像,可以手动的导出、导入镜像
crictl命令没有导出、导入镜像的功能。
需要使用ctr命令导出、导入镜像,它是containerd的命令行接口。
不建议使用ctr使用其他操作 只会镜像的导入导出即可
导入镜像(需要指定平台 这里是x64)
k3s默认的镜像都在k8s.io的命名空间下 所以要指定一下ns
ctr -n k8s.io images import ***.tar --platform linux/amd64
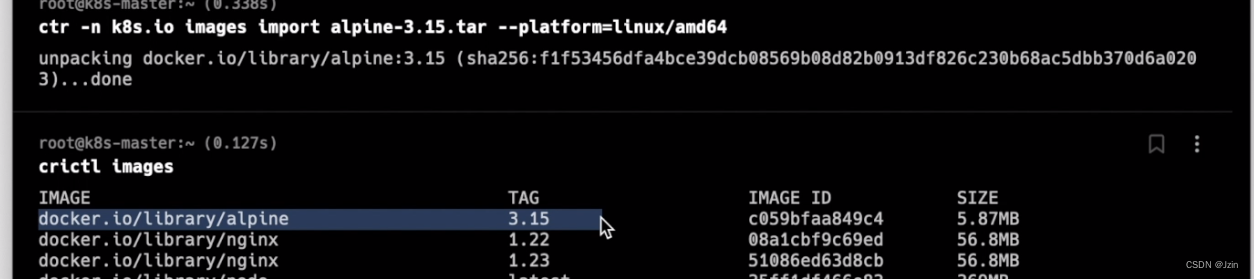
导出
ctr -n k8s.io images export alpine.tar docker.io/library/alipine:3.15 --platform linux/amd64

导入镜像需要在每一台节点上执行才可以
金丝雀发布
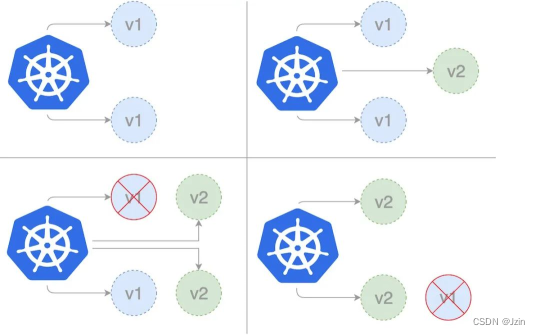
金丝雀部署(canary deployment) 也被称为灰度发布。
早期,工人下矿井之前会放入一只金丝雀检测井下是否存在有毒气体。
采用金丝雀部署,你可以在生产环境的基础设施中小范围的部署新的应用代码。
一旦应用签署发布,只有少数用户被路由到它,最大限度的降低影响。
如果没有错误发生,则将新版本逐渐推广到整个基础设施。
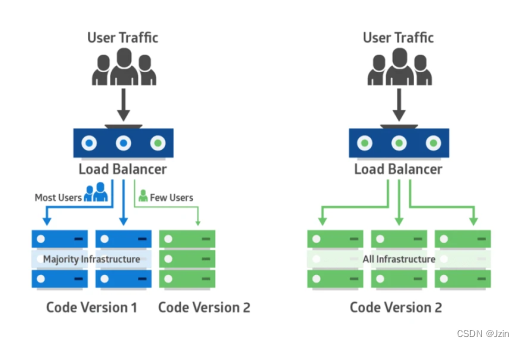
部署过程
部署第一个版本
发布v1版本的应用,镜像使用nginx:1.22,数量为 3。
- 创建Namespace
Namespace配置模版 - 创建Deployment
Deployment配置模版 - 创建外部访问的Service
Service配置模版
示例:
apiVersion: v1
kind: Namespace
metadata:
name: dev
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment-v1
namespace: dev
labels:
app: nginx-deployment-v1
spec:
replicas: 3
selector:
matchLabels: # 跟template.metadata.labels一致
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.22
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: canary-demo
namespace: dev
spec:
type: NodePort
selector: # 更Deployment中的selector一致
app: nginx
ports:
# By default and for convenience, the `targetPort` is set to the same value as the `port` field.
- port: 80
targetPort: 80
# Optional field
# By default and for convenience, the Kubernetes control plane will allocate a port from a range (default: 30000-32767)
nodePort: 30008
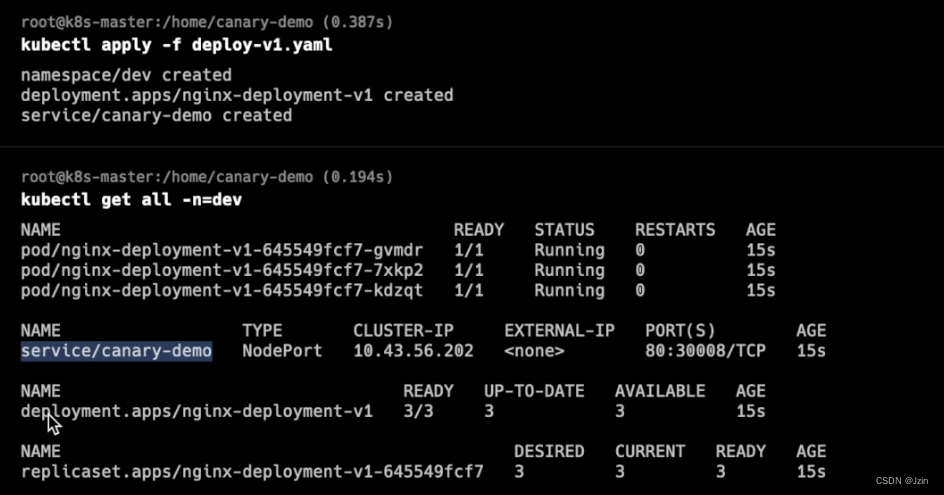
可以通过ns查询
访问:
创建Canary Deployment
发布新版本的应用,镜像使用docker/getting-started,数量为 1。
示例:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment-canary
namespace: dev
labels:
app: nginx-deployment-canary
spec:
replicas: 1
selector:
matchLabels: # 跟template.metadata.labels一致
app: nginx
template:
metadata:
labels:
app: nginx #这个pod和service的selector一致 因此新部署的pod会加入到service的负载均衡中
track: canary
spec:
containers:
- name: new-nginx
image: docker/getting-started
ports:
- containerPort: 80
查看服务:kubectl describe svc canary-demo --namespace=dev
待稳定运行一段时间后,扩大试用范围,将部署的v2版本数量调整为3,v1和v2的数量都是3个。
kubectl scale deployment/deploy-v2-canary --replicas=3 -n=dev
局限性
按照 Kubernetes 默认支持的这种方式进行金丝雀发布,有一定的局限性:
- 不能根据用户注册时间、地区等请求中的内容属性进行流量分配
- 同一个用户如果多次调用该 Service,有可能第一次请求到了旧版本的 Pod,第二次请求到了新版本的 Pod
在 Kubernetes 中不能解决上述局限性的原因是:Kubernetes Service 只在 TCP 层面解决负载均衡的问题,并不对请求响应的消息内容做任何解析和识别。如果想要更完善地实现金丝雀发布,可以考虑Istio灰度发布。
参考文档:
https://www.infoq.cn/article/lei4vsfpiw5a6en-aso4
https://kuboard.cn/learning/k8s-intermediate/workload/wl-deployment/canary.html
运行有状态应用(MySQL数据库)
我们以MySQL数据库为例,在kubernetes集群中运行一个有状态的应用。
部署数据库几乎覆盖了kubernetes中常见的对象和概念:
- 配置文件–ConfigMap
- 保存密码–Secret
- 数据存储–持久卷(PV)和持久卷声明(PVC)
- 动态创建卷–存储类(StorageClass)
- 部署多个实例–StatefulSet
- 数据库访问–Headless Service
- 主从复制–初始化容器和sidecar
- 数据库调试–port-forward
- 部署Mysql集群–helm
存储
创建Mysql
配置环境变量
- 使用MySQL镜像创建Pod,需要使用环境变量设置MySQL的初始密码。
- 环境变量配置示例
挂载卷
- 将数据存储在容器中,一旦容器被删除,数据也会被删除。
- 将数据存储到卷(Volume)中,删除容器时,卷不会被删除。
hostPath卷
hostPath 卷将主机节点上的文件或目录挂载到 Pod 中。
hostPath配置示例
| DirectoryOrCreate | 目录不存在则自动创建 |
| Directory | 挂载已存在目录。不存在会报错 |
| FileOrCreate | 文件不存在则自动创建。不会自动创建文件的父目录,必须确保文件路径已经存在。 |
| File | 挂载已存在的文件。不存在会报错 |
| Socket | 挂载 UNIX 套接字。例如挂载/var/run/docker.sock进程 |
参考文档:
https://kubernetes.io/zh-cn/docs/tasks/inject-data-application/define-environment-variable-container/
https://kubernetes.io/zh-cn/docs/concepts/storage/volumes/#hostpath
https://kubernetes.io/zh-cn/docs/tasks/configure-pod-container/configure-persistent-volume-storage/
ConfigMap与Secret
在Docker中,我们一般通过绑定挂载的方式将配置文件挂载到容器里
在Kubernetes集群中,容器可能被调度到任意节点,配置文件需要能在集群任意节点上
访问、分发和更新
ConfigMap
- ConfigMap 用来在键值对数据库(etcd)中保存非加密数据。一般用来保存配置文件。
- ConfigMap 可以用作环境变量、命令行参数或者存储卷。
- ConfigMap 将环境配置信息与 容器镜像 解耦,便于配置的修改。
- ConfigMap 在设计上不是用来保存大量数据的。
- 在 ConfigMap 中保存的数据不可超过 1 MiB。
- 超出此限制,需要考虑挂载存储卷或者访问文件存储服务。
ConfigMap用法
- ConfigMap配置示例
- Pod中使用ConfigMap
apiVersion: v1
kind: Pod
metadata:
name: mysql-pod
labels:
app: mysql
spec:
containers:
- name: mysql
image: mysql:5.7
env:
- name: MYSQL_ROOT_PASSWORD
value: "123456"
volumeMounts:
- mountPath: /var/lib/mysql
name: data-volume
- mountPath: /etc/mysql/conf.d
name: conf-volume
readOnly: true
volumes:
- name: conf-volume
configMap:
name: mysql-config
- name: data-volume
hostPath:
# directory location on host
path: /home/mysql/data
# this field is optional
type: DirectoryOrCreate
---
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql-config
data:
mysql.cnf: |
[mysqld]
character-set-server=utf8mb4
collation-server=utf8mb4_general_ci
init-connect='SET NAMES utf8mb4'
[client]
default-character-set=utf8mb4
[mysql]
default-character-set=utf8mb4

configMap可以缩写为cm
# 修改configMap,配置文件会被自动更新
kubectl edit cm mysql-config
Secret
Secret 用于保存机密数据的对象。一般由于保存密码、令牌或密钥等。
data字段用来存储 base64 编码数据。
stringData存储未编码的字符串。
Secret 意味着你不需要在应用程序代码中包含机密数据,减少机密数据(如密码)泄露的风险。
Secret 可以用作环境变量、命令行参数或者存储卷文件。
Secret用法:
- Secret配置示例
- 将Secret用作环境变量
echo -n '123456' | base64
echo 'MTIzNDU2' | base64 --decode
示例:
apiVersion: v1
kind: Secret
metadata:
name: mysql-password
type: Opaque
data:
PASSWORD: MTIzNDU2Cg==
---
apiVersion: v1
kind: Pod
metadata:
name: mysql-pod
spec:
containers:
- name: mysql
image: mysql:5.7
env:
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-password
key: PASSWORD
optional: false # 此值为默认值;表示secret已经存在了
volumeMounts:
- mountPath: /var/lib/mysql
name: data-volume
- mountPath: /etc/mysql/conf.d
name: conf-volume
readOnly: true
volumes:
- name: conf-volume
configMap:
name: mysql-config
- name: data-volume
hostPath:
# directory location on host
path: /home/mysql/data
# this field is optional
type: DirectoryOrCreate
---
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql-config
data:
mysql.cnf: |
[mysqld]
character-set-server=utf8mb4
collation-server=utf8mb4_general_ci
init-connect='SET NAMES utf8mb4'
[client]
default-character-set=utf8mb4
[mysql]
default-character-set=utf8mb4
注意:当Secret修改后 环境变量的Secret不会自动更新 需要重启pod
参考文档:
https://kubernetes.io/zh-cn/docs/concepts/configuration/
https://kubernetes.io/zh-cn/docs/concepts/configuration/configmap/
https://kubernetes.io/zh-cn/docs/concepts/configuration/secret/
https://kubernetes.io/zh-cn/docs/tasks/configure-pod-container/configure-pod-configmap/
卷(Volume)
将数据存储在容器中,一旦容器被删除,数据也会被删除。
卷是独立于容器之外的一块存储区域,通过挂载(Mount)的方式供Pod中的容器使用。
使用场景
- 卷可以在多个容器之间共享数据。
- 卷可以将容器数据存储在外部存储或云存储上。
- 卷更容易备份或迁移。
常见的卷类型
临时卷(Ephemeral Volume): 与 Pod 一起创建和删除,生命周期与 Pod 相同
- emptyDir - 作为缓存或存储日志
- configMap 、secret、 downwardAPI - 给Pod注入数据
持久卷(Persistent Volume):删除Pod后,持久卷不会被删除
- 本地存储 - hostPath、 local
- 网络存储 - NFS
- 分布式存储 - Ceph(cephfs文件存储、rbd块存储)
投射卷(Projected Volumes):projected 卷可以将多个卷映射到同一个目录上
后端存储
一个集群中可以包含多种存储(如local、NFS、Ceph或云存储)。
每种存储都对应一个存储类(StorageClass) ,存储类用来创建和管理持久卷,是集群与存储服务之间的桥梁。
管理员创建持久卷(PV)时,通过设置不同的StorageClass来创建不同类型的持久卷。
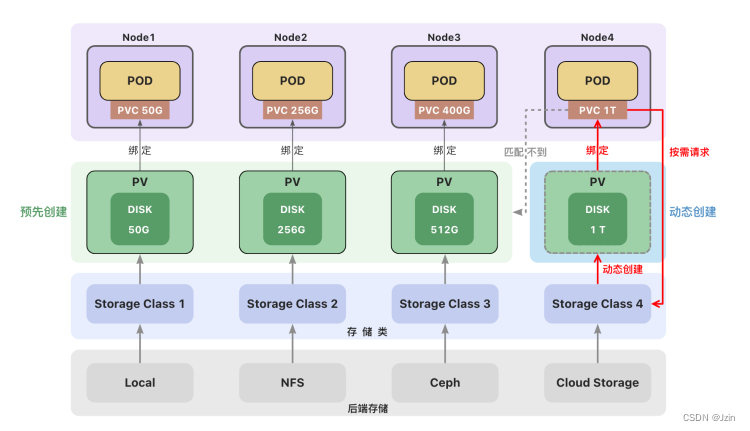
参考文档:
https://kubernetes.io/zh-cn/docs/concepts/storage/volumes/
https://kubernetes.io/zh-cn/docs/concepts/storage/ephemeral-volumes/
https://kubernetes.io/zh-cn/docs/tasks/configure-pod-container/configure-volume-storage/
临时卷(EV)
临时卷(Ephemeral Volume)
- 与 Pod 一起创建和删除,生命周期与 Pod 相同
- emptyDir - 初始内容为空的本地临时目录
- configMap - 为Pod注入配置文件
- secret - 为Pod注入加密数据
emptyDir
emptyDir会创建一个初始状态为空的目录,存储空间来自本地的 kubelet 根目录或内存(需要将emptyDir.medium设置为"Memory")。
通常使用本地临时存储来设置缓存、保存日志等。
例如,将redis的存储目录设置为emptyDir
示例:
apiVersion: v1
kind: Pod
metadata:
name: redis-pod
spec:
containers:
- name: redis
image: redis
volumeMounts:
- name: redis-storage
mountPath: /data/redis
volumes:
- name: redis-storage
emptyDir: {}
configMap卷和secret卷
注意: 这里的configMap和secret代表的是卷的类型,不是configMap和secret对象。
删除Pod并不会删除ConfigMap对象和secret对象。
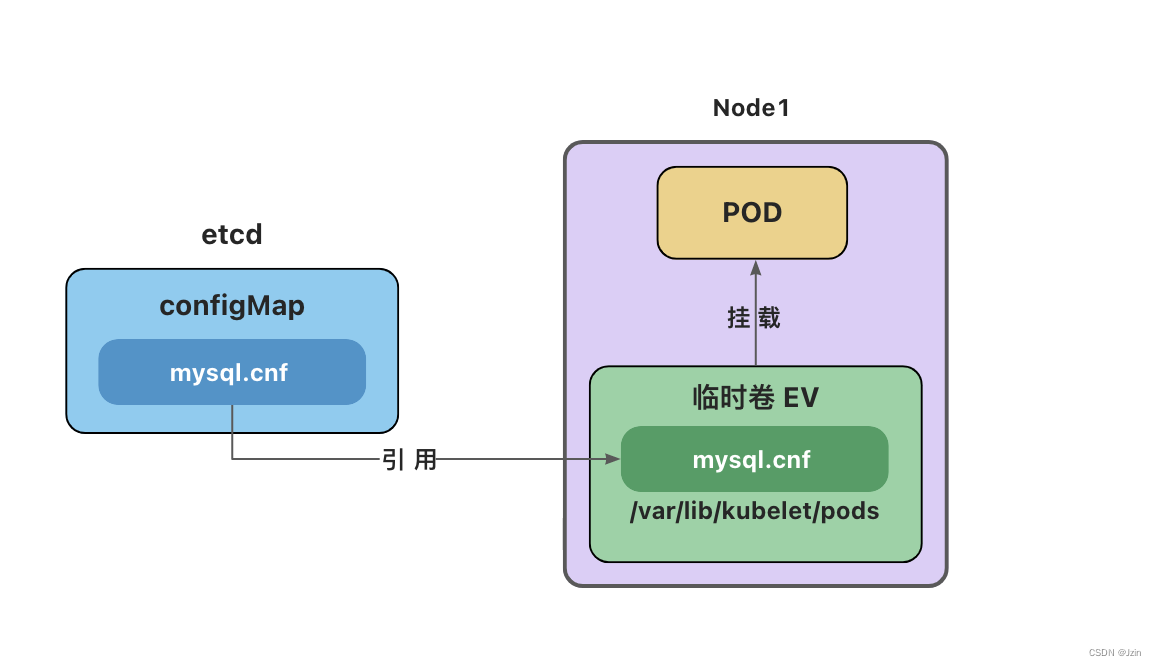
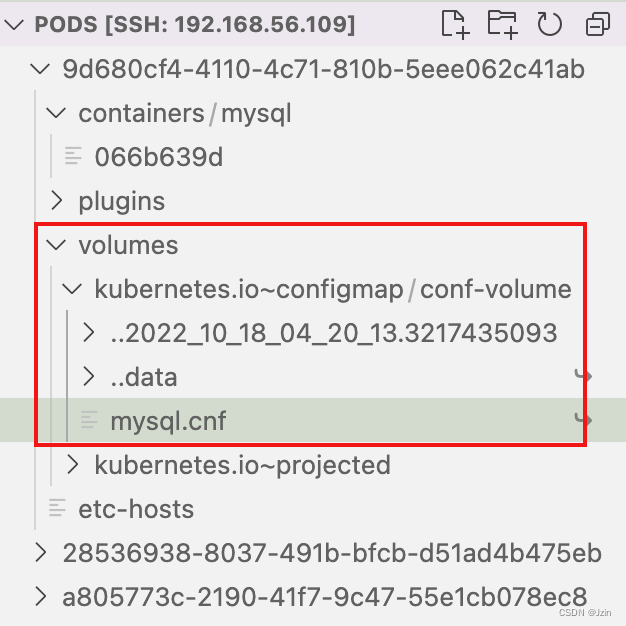
configMap卷和Secret卷是一种特殊类型的卷,kubelet引用configMap和Secret中定义的内容,在Pod所在节点上生成一个临时卷,将数据注入到Pod中。删除Pod,临时卷也会被删除。
临时卷位于Pod所在节点的/var/lib/kubelet/pods目录下。
参考文档:
https://kubernetes.io/zh-cn/docs/concepts/storage/volumes/
https://kubernetes.io/zh-cn/docs/concepts/storage/ephemeral-volumes/
https://kubernetes.io/zh-cn/docs/tasks/configure-pod-container/configure-volume-storage/
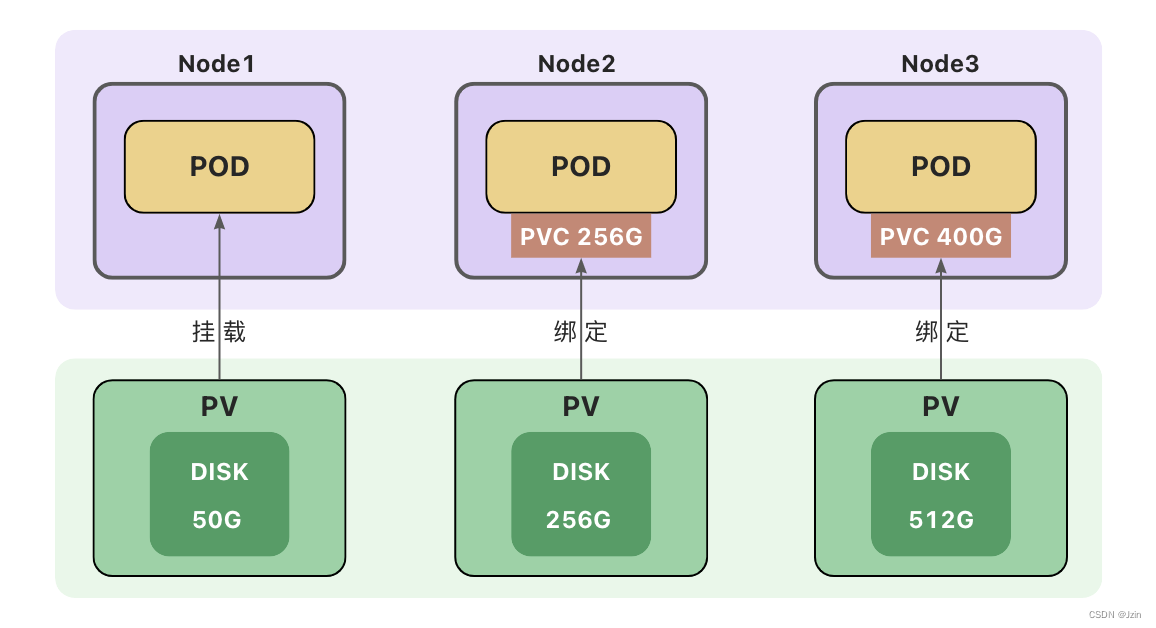
持久卷(PV)与持久卷声明(PVC)
持久卷(Persistent Volume):删除Pod后,卷不会被删除
本地存储
- hostPath - 节点主机上的目录或文件
(仅供单节点测试使用;多节点集群请用 local 卷代替) - local - 节点上挂载的本地存储设备(不支持动态创建卷)
网络存储
- NFS - 网络文件系统 (NFS)
分布式存储
- Ceph(cephfs文件存储、rbd块存储)
持久卷(PV)和持久卷声明(PVC)
持久卷(PersistentVolume,PV) 是集群中的一块存储。可以理解为一块虚拟硬盘。
持久卷可以由管理员事先创建, 或者使用存储类(Storage Class)根据用户请求来动态创建。
持久卷属于集群的公共资源,并不属于某个namespace;
持久卷声明(PersistentVolumeClaim,PVC) 表达的是用户对存储的请求。
PVC声明好比申请单,它更贴近云服务的使用场景,使用资源先申请,便于统计和计费。
Pod 将 PVC 声明当做存储卷来使用,PVC 可以请求指定容量的存储空间和访问模式 。PVC对象是带有namespace的。
创建持久卷(PV)
创建持久卷(PV)是服务端的行为,通常集群管理员会提前创建一些常用规格的持久卷以备使用。
hostPath仅供单节点测试使用,当Pod被重新创建时,可能会被调度到与原先不同的节点上,导致新的Pod没有数据。多节点集群使用本地存储,可以使用local卷
创建local类型的持久卷,需要先创建存储类(StorageClass)。
本地存储类示例
# 创建本地存储类
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: local-storage
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: Immediate
local卷不支持动态创建,必须手动创建持久卷(PV)。
创建local类型的持久卷,必须设置nodeAffinity(节点亲和性)。
调度器使用nodeAffinity信息来将使用local卷的 Pod 调度到持久卷所在的节点上,不会出现Pod被调度到别的节点上的情况。
注意: local卷也存在自身的问题,当Pod所在节点上的存储出现故障或者整个节点不可用时,Pod和卷都会失效,仍然会丢失数据,因此最安全的做法还是将数据存储到集群之外的存储或云存储上。
● 创建PV
PV示例/local卷示例
apiVersion: v1
kind: PersistentVolume
metadata:
name: local-pv-1
spec:
capacity:
storage: 4Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Delete
storageClassName: local-storage #通过指定存储类来设置卷的类型
local:
path: /mnt/disks/ssd1
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values: #节点亲和度 防止被调度到不同的节点
- k8s-worker1
创建持久卷声明(PVC)
持久卷声明(PVC)是用户端的行为,用户在创建Pod时,无法知道集群中PV的状态(名称、容量、是否可用等),用户也无需关心这些内容,只需要在声明中提出申请,集群会自动匹配符合需求的持久卷(PV)。
Pod使用持久卷声明(PVC)作为存储卷。
PVC示例
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: local-pv-claim
spec:
storageClassName: local-storage # 与PV中的storageClassName一致
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 3Gi
使用PVC作为卷
Pod 的配置文件指定了 PersistentVolumeClaim,但没有指定 PersistentVolume。
对 Pod 而言,PersistentVolumeClaim 就是一个存储卷。
PVC卷示例
apiVersion: v1
kind: Pod
metadata:
name: mysql-pod
spec:
containers:
- name: mysql
image: mysql:5.7
env:
- name: MYSQL_ROOT_PASSWORD
value: "123456"
ports:
- containerPort: 3306
volumeMounts:
- mountPath: /var/lib/mysql #容器中的目录
name: local-mysql-data
volumes:
- name: local-mysql-data
persistentVolumeClaim:
claimName: local-pv-claim
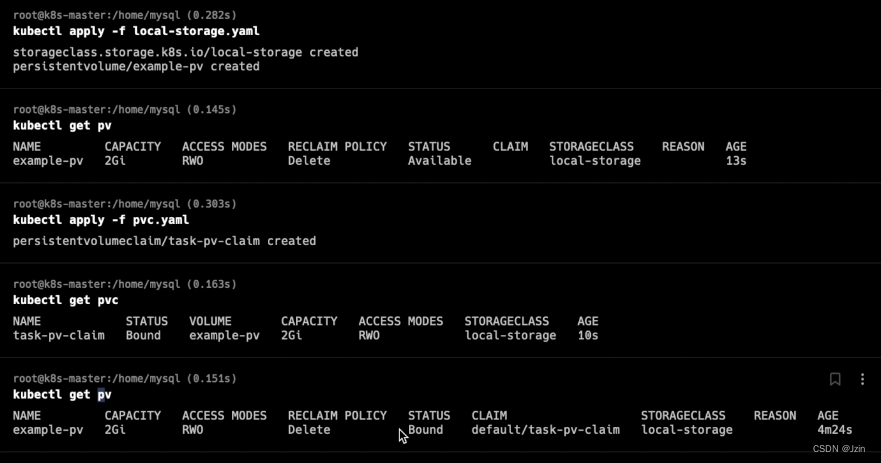
绑定
创建持久卷声明(PVC)之后,集群会查找满足要求的持久卷(PV),将 PVC 绑定到该 PV上。
PVC与PV之间的绑定是一对一的映射关系,绑定具有排他性,一旦绑定关系建立,该PV无法被其他PVC使用。
PVC可能会匹配到比声明容量大的持久卷,但是不会匹配比声明容量小的持久卷。
例如,即使集群上存在多个 50 G大小的 PV ,他们加起来的容量大于100G,也无法匹配100 G大小的 PVC。
找不到满足要求的 PV ,PVC会无限期地处于未绑定状态(Pending) , 直到出现了满足要求的 PV时,PVC才会被绑定。
访问模式
ReadWriteOnce
卷可以被一个节点以读写方式挂载,并允许同一节点上的多个 Pod 访问。
ReadOnlyMany
卷可以被多个节点以只读方式挂载。
ReadWriteMany
卷可以被多个节点以读写方式挂载。
ReadWriteOncePod
卷可以被单个 Pod 以读写方式挂载。 集群中只有一个 Pod 可以读取或写入该 PVC。
只支持 CSI 卷以及需要 Kubernetes 1.22 以上版本。
卷的状态
- Available(可用)-- 卷是一个空闲资源,尚未绑定到任何;
- Bound(已绑定)-- 该卷已经绑定到某个持久卷声明上;
- Released(已释放)-- 所绑定的声明已被删除,但是资源尚未被集群回收;
- Failed(失败)-- 卷的自动回收操作失败。
卷模式
卷模式(volumeMode)是一个可选参数。
针对 PV 持久卷,Kubernetes 支持两种卷模式(volumeModes):
- Filesystem(文件系统)
默认的卷模式。 - Block(块)
将卷作为原始块设备来使用。
参考文档:
https://kubernetes.io/zh-cn/docs/concepts/storage/volumes/
https://kubernetes.io/zh-cn/docs/concepts/storage/persistent-volumes/
https://kubernetes.io/zh-cn/docs/tasks/configure-pod-container/configure-persistent-volume-storage/
访问模式
● ReadWriteOnce
○ 卷可以被一个节点以读写方式挂载,并允许同一节点上的多个 Pod 访问。
● ReadOnlyMany
○ 卷可以被多个节点以只读方式挂载。
● ReadWriteMany
○ 卷可以被多个节点以读写方式挂载。
● ReadWriteOncePod
○ 卷可以被单个 Pod 以读写方式挂载。 集群中只有一个 Pod 可以读取或写入该 PVC。
○ 只支持 CSI 卷以及需要 Kubernetes 1.22 以上版本。
卷的状态
- Available(可用)-- 卷是一个空闲资源,尚未绑定到任何;
- Bound(已绑定)-- 该卷已经绑定到某个持久卷声明上;
- Released(已释放)-- 所绑定的声明已被删除,但是资源尚未被集群回收;
- Failed(失败)-- 卷的自动回收操作失败。
卷模式
卷模式(volumeMode)是一个可选参数。
针对 PV 持久卷,Kubernetes 支持两种卷模式(volumeModes):
● Filesystem(文件系统)
默认的卷模式。
● Block(块)
- 将卷作为原始块设备来使用。
参考文档:
https://kubernetes.io/zh-cn/docs/concepts/storage/volumes/
https://kubernetes.io/zh-cn/docs/concepts/storage/persistent-volumes/
https://kubernetes.io/zh-cn/docs/tasks/configure-pod-container/configure-persistent-volume-storage/
存储类(StorageClass)
创建持久卷(PV)
● 静态创建
- 管理员预先手动创建
- 手动创建麻烦、不够灵活(local卷不支持动态创建,必须手动创建PV)
- 资源浪费(例如一个PVC可能匹配到比声明容量大的卷)
- 对自动化工具不够友好
● 动态创建
- 根据用户请求按需创建持久卷,在用户请求时自动创建
- 动态创建需要使用存储类(StorageClass)
- 用户需要在持久卷声明(PVC)中指定存储类来自动创建声明中的卷。
- 如果没有指定存储类,使用集群中默认的存储类。
存储类(StorageClass)
一个集群可以存在多个存储类(StorageClass)来创建和管理不同类型的存储。
每个 StorageClass 都有一个制备器(Provisioner),用来决定使用哪个卷插件创建持久卷。 该字段必须指定。
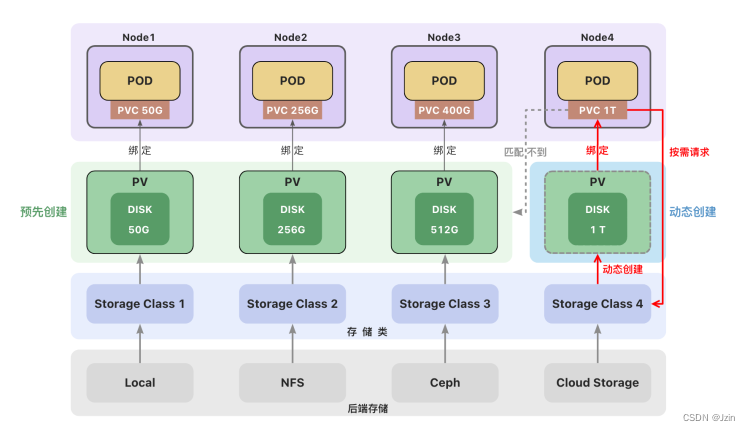
Local Path Provisioner

K3s自带了一个名为local-path的存储类(StorageClass),它支持动态创建基于hostPath或local的持久卷。
创建PVC后,会自动创建PV,不需要再去手动的创建PV。
删除PVC,PV也会被自动删除。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: local-path-pvc
namespace: default
spec:
accessModes:
- ReadWriteOnce
storageClassName: local-path
resources:
requests:
storage: 2Gi
---
apiVersion: v1
kind: Pod
metadata:
name: mysql-pod
spec:
containers:
- name: mysql
image: mysql:5.7
env:
- name: MYSQL_ROOT_PASSWORD
value: "123456"
ports:
- containerPort: 3306
volumeMounts:
- mountPath: /var/lib/mysql #容器中的目录
name: local-mysql-data
volumes:
- name: local-mysql-data
persistentVolumeClaim:
claimName: local-path-pvc
卷绑定模式
volumeBindingMode用于控制什么时候动态创建卷和绑定卷。
● Immediate立即创建
创建PVC后,立即创建PV并完成绑定。
● WaitForFirstConsumer 延迟创建
当使用该PVC的 Pod 被创建时,才会自动创建PV并完成绑定。
回收策略(Reclaim Policy)
回收策略告诉集群,当用户删除PVC 对象时, 从PVC中释放出来的PV将被如何处理。
● 删除(Delete)
如果没有指定,默认为Delete
当PVC被删除时,关联的PV 对象也会被自动删除。
● 保留(Retain)
当 PVC 对象被删除时,PV 卷仍然存在,数据卷状态变为"已释放(Released)"。
此时卷上仍保留有数据,该卷还不能用于其他PVC。需要手动删除PV。
参考文档:
https://kubernetes.io/zh-cn/docs/concepts/storage/storage-classes/
https://kubernetes.io/zh-cn/docs/concepts/storage/storage-classes/#volume-binding-mode
https://rancher.com/docs/k3s/latest/en/storage/
StatefulSet(有状态应用集)
StatefulSet
如果我们需要部署多个MySQL实例,就需要用到StatefulSet。
StatefulSet 是用来管理有状态的应用。一般用于管理数据库、缓存等。
与 Deployment 类似, StatefulSet用来管理 Pod 集合的部署和扩缩。
Deployment用来部署无状态应用。StatefulSet用来有状态应用。
创建StatefulSet
StatefulSet配置模版
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql
spec:
selector:
matchLabels:
app: mysql # 必须匹配 .spec.template.metadata.labels
serviceName: db
replicas: 3 # 默认值是 1
minReadySeconds: 10 # 默认值是 0
template:
metadata:
labels:
app: mysql # 必须匹配 .spec.selector.matchLabels
spec:
terminationGracePeriodSeconds: 10
containers:
- name: mysql
image: mysql:5.7
env:
- name: MYSQL_ROOT_PASSWORD
value: "123456"
ports:
- containerPort: 3306
volumeMounts:
- mountPath: /var/lib/mysql #容器中的目录
name: mysql-data
volumeClaimTemplates:
- metadata:
name: mysql-data
spec:
accessModes:
- ReadWriteOnce
storageClassName: local-path
resources:
requests:
storage: 2Gi
稳定的存储
在 StatefulSet 中使用 VolumeClaimTemplate,为每个 Pod 创建持久卷声明(PVC)。
每个 Pod 将会得到基于local-path 存储类动态创建的持久卷(PV)。 Pod 创建(或重新调度)时,会挂载与其声明相关联的持久卷。
请注意,当 Pod 或者 StatefulSet 被删除时,持久卷声明和关联的持久卷不会被删除。
Pod 标识
在具有 N 个副本的 StatefulSet中,每个 Pod 会被分配一个从 0 到 N-1 的整数序号,该序号在此 StatefulSet 上是唯一的。
StatefulSet 中的每个 Pod 主机名的格式为StatefulSet名称-序号。
上例将会创建三个名称分别为 mysql-0、mysql-1、mysql-2 的 Pod。
部署和扩缩保证
- 对于包含 N 个 副本的 StatefulSet,当部署 Pod 时,它们是依次创建的,顺序为 0…N-1。
- 当删除 Pod 时,它们是逆序终止的,顺序为 N-1…0。
- 在将扩缩操作应用到 Pod 之前,它前面的所有 Pod 必须是 Running 和 Ready 状态。
- 在一个 Pod 终止之前,所有的继任者必须完全关闭。
在上面的mysql示例被创建后,会按照 mysql-0、mysql-1、mysql-2 的顺序部署三个 Pod。
在 mysql-0 进入 Running 和 Ready 状态前不会部署 mysql-1。
在 mysql-1 进入 Running 和 Ready 状态前不会部署 mysql-2。
如果 mysql-1 已经处于 Running 和 Ready 状态,而 mysql-2 尚未部署,在此期间发生了 mysql-0 运行失败,那么 mysql-2 将不会被部署,要等到 mysql-0 部署完成并进入 Running 和 Ready 状态后,才会部署 mysql-2。
如果用户想将示例中的 StatefulSet 扩缩为 replicas=1,首先被终止的是 mysql-2。
在 mysql-2 没有被完全停止和删除前,mysql-1 不会被终止。
当 mysql-2 已被终止和删除、mysql-1 尚未被终止,如果在此期间发生 mysql-0 运行失败, 那么就不会终止 mysql-1,必须等到 mysql-0 进入 Running 和 Ready 状态后才会终止 web-1。
参考文档:
https://kubernetes.io/zh-cn/docs/concepts/workloads/controllers/statefulset/
https://kubernetes.io/zh-cn/docs/tasks/run-application/run-replicated-stateful-application/
Headless Service(无头服务)
之前我们创建了三个各自独立的数据库实例,mysql-0,mysql-1,mysql-2。
要想让别的容器访问数据库,我们需要将它发布为Service,但是Service带负载均衡功能,每次请求都会转发给不同的数据库,这样子使用过程中会有很大的问题。
无头服务(Headless Services)
无头服务(Headless Service)可以为 StatefulSet 成员提供稳定的 DNS 地址。
在不需要负载均衡的情况下,可以通过指定 Cluster IP的值为 “None” 来创建无头服务。
注意:StatefulSet中的ServiceName必须要跟Service中的metadata.name一致
# 为 StatefulSet 成员提供稳定的 DNS 表项的无头服务(Headless Service)
apiVersion: v1
kind: Service
metadata:
#重要!这里的名字要跟后面StatefulSet里ServiceName一致
name: db
labels:
app: database
spec:
ports:
- name: mysql
port: 3306
# 设置Headless Service
clusterIP: None
selector:
app: mysql
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql
spec:
selector:
matchLabels:
app: mysql # 必须匹配 .spec.template.metadata.labels
serviceName: db #重要!这里的名字要跟Service中metadata.name匹配
replicas: 3 # 默认值是 1
minReadySeconds: 10 # 默认值是 0
template:
metadata:
labels:
app: mysql # 必须匹配 .spec.selector.matchLabels
spec:
terminationGracePeriodSeconds: 10
containers:
- name: mysql
image: mysql:5.7
env:
- name: MYSQL_ROOT_PASSWORD
value: "123456"
ports:
- containerPort: 3306
volumeMounts:
- mountPath: /var/lib/mysql
name: mysql-data
volumeClaimTemplates:
- metadata:
name: mysql-data
spec:
accessModes:
- ReadWriteOnce
storageClassName: local-path
resources:
requests:
storage: 2Gi
稳定的网络 ID
StatefulSet 中的每个 Pod 都会被分配一个StatefulSet名称-序号格式的主机名。
集群内置的DNS会为Service分配一个内部域名db.default.svc.cluster.local,它的格式为 服务名称.命名空间.svc.cluster.local。
Service下的每个Pod会被分配一个子域名,格式为pod名称.所属服务的域名,例如mysql-0的域名为mysql-0.db.default.svc.cluster.local。添加链接描述
创建Pod时,DNS域名生效可能会有一些延迟(几秒或几十秒)。
Pod之间可以通过DNS域名访问,同一个命名空间下可以省略命名空间及其之后的内容。
kubectl run dns-test -it --image=busybox:1.28 --rm
# 访问mysql-0数据库
nslookup mysql-0.db
参考文档:
https://kubernetes.io/zh-cn/docs/concepts/workloads/controllers/statefulset/
https://kubernetes.io/zh-cn/docs/tutorials/stateful-application/basic-stateful-set/
https://kubernetes.io/zh-cn/docs/concepts/services-networking/service/#headless-services
https://kubernetes.io/zh-cn/docs/tasks/run-application/run-replicated-stateful-application/
https://kubernetes.io/zh-cn/docs/concepts/services-networking/dns-pod-service/
Mysql主从复制
注意
1.本例子配置比较复杂,仅用于讲解原理,无需掌握配置细节。
2.后面我们会讲使用helm自动化部署,用起来非常简单。
3.本例子不能用于生产,mysql的密码允许设置为空。
下面是部署一个读写分离Mysql数据库的示意图。
通过部署无头服务(Headless Service)将写操作指向固定的数据库。
部署一个Service用来做读操作的负载均衡。
数据库之间通过同步程序保持数据一致。
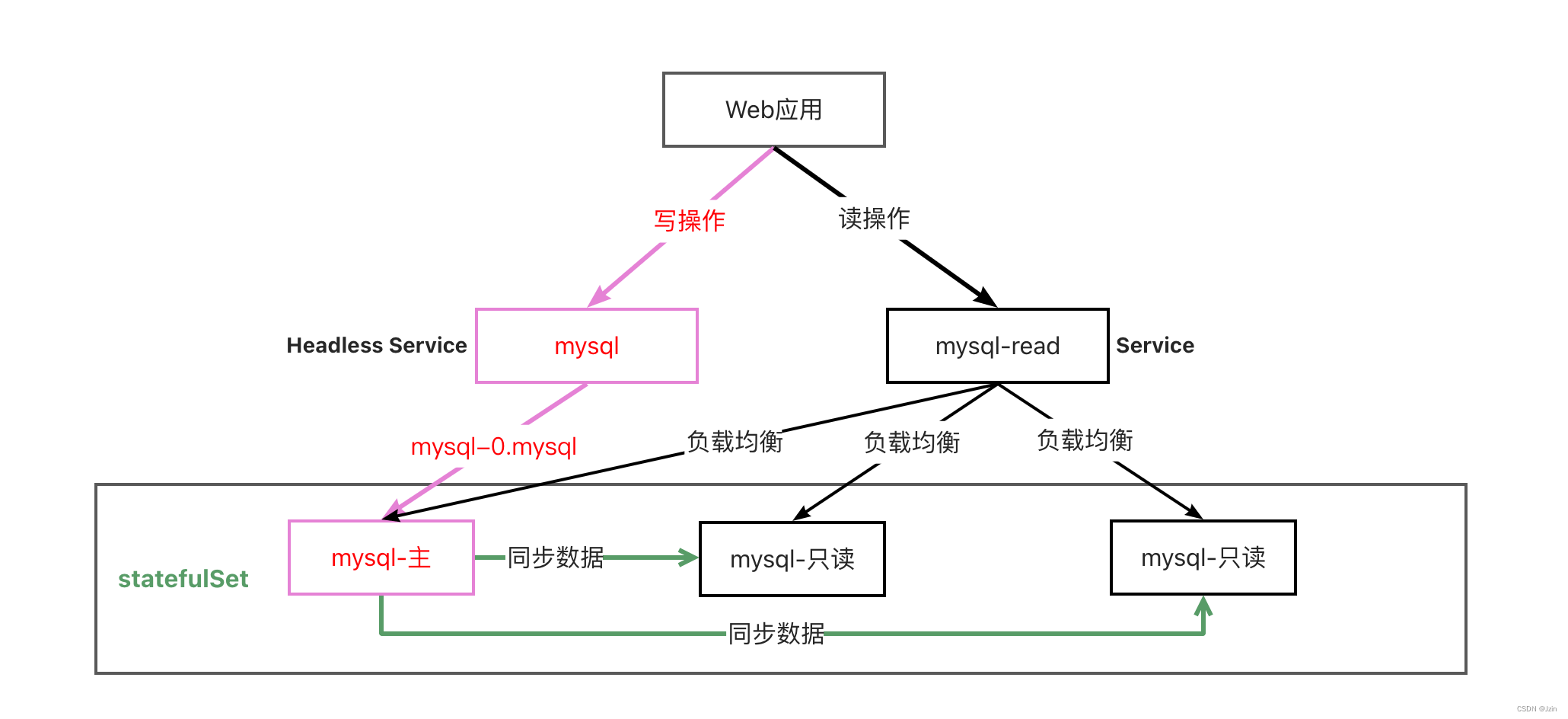
Mysql主从复制
运行一个有状态的应用程序
注意:
1.官方的安装文档有错误,mysql镜像需要使用mysql:5.7-debian。否则会出现如下错误:
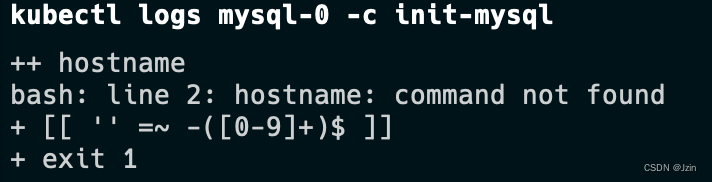
详见:https://github.com/kubernetes/website/pull/35857。
2.谷歌的镜像·gcr.io/google-samples/xtrabackup:1.0·访问不到,使用·ist0ne/xtrabackup:1.0·代替
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql
labels:
app: mysql
app.kubernetes.io/name: mysql
data:
primary.cnf: |
# 仅在主服务器上应用此配置
[mysqld]
log-bin
replica.cnf: |
# 仅在副本服务器上应用此配置
[mysqld]
super-read-only
---
# 为 StatefulSet 成员提供稳定的 DNS 表项的无头服务(Headless Service)
apiVersion: v1
kind: Service
metadata:
name: mysql
labels:
app: mysql
app.kubernetes.io/name: mysql
spec:
ports:
- name: mysql
port: 3306
clusterIP: None
selector:
app: mysql
---
# 用于连接到任一 MySQL 实例执行读操作的客户端服务
# 对于写操作,你必须连接到主服务器:mysql-0.mysql
apiVersion: v1
kind: Service
metadata:
name: mysql-read
labels:
app: mysql
app.kubernetes.io/name: mysql
readonly: "true"
spec:
ports:
- name: mysql
port: 3306
selector:
app: mysql
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql
spec:
selector:
matchLabels:
app: mysql
app.kubernetes.io/name: mysql
serviceName: mysql
replicas: 3
template:
metadata:
labels:
app: mysql
app.kubernetes.io/name: mysql
spec:
initContainers:
- name: init-mysql
image: mysql:5.7-debian
command:
- bash
- "-c"
- |
set -ex
# 基于 Pod 序号生成 MySQL 服务器的 ID。
[[ `hostname` =~ -([0-9]+)$ ]] || exit 1
ordinal=${BASH_REMATCH[1]}
echo [mysqld] > /mnt/conf.d/server-id.cnf
# 添加偏移量以避免使用 server-id=0 这一保留值。
echo server-id=$((100 + $ordinal)) >> /mnt/conf.d/server-id.cnf
# 将合适的 conf.d 文件从 config-map 复制到 emptyDir。
if [[ $ordinal -eq 0 ]]; then
cp /mnt/config-map/primary.cnf /mnt/conf.d/
else
cp /mnt/config-map/replica.cnf /mnt/conf.d/
fi
volumeMounts:
- name: conf
mountPath: /mnt/conf.d
- name: config-map
mountPath: /mnt/config-map
- name: clone-mysql
image: ist0ne/xtrabackup:1.0
command:
- bash
- "-c"
- |
set -ex
# 如果已有数据,则跳过克隆。
[[ -d /var/lib/mysql/mysql ]] && exit 0
# 跳过主实例(序号索引 0)的克隆。
[[ `hostname` =~ -([0-9]+)$ ]] || exit 1
ordinal=${BASH_REMATCH[1]}
[[ $ordinal -eq 0 ]] && exit 0
# 从原来的对等节点克隆数据。
ncat --recv-only mysql-$(($ordinal-1)).mysql 3307 | xbstream -x -C /var/lib/mysql
# 准备备份。
xtrabackup --prepare --target-dir=/var/lib/mysql
volumeMounts:
- name: data
mountPath: /var/lib/mysql
subPath: mysql
- name: conf
mountPath: /etc/mysql/conf.d
containers:
- name: mysql
image: mysql:5.7-debian
env:
- name: MYSQL_ALLOW_EMPTY_PASSWORD
value: "1"
ports:
- name: mysql
containerPort: 3306
volumeMounts:
- name: data
mountPath: /var/lib/mysql
subPath: mysql
- name: conf
mountPath: /etc/mysql/conf.d
resources:
requests:
cpu: 500m
memory: 1Gi
livenessProbe:
exec:
command: ["mysqladmin", "ping"]
initialDelaySeconds: 30
periodSeconds: 10
timeoutSeconds: 5
readinessProbe:
exec:
# 检查我们是否可以通过 TCP 执行查询(skip-networking 是关闭的)。
command: ["mysql", "-h", "127.0.0.1", "-e", "SELECT 1"]
initialDelaySeconds: 5
periodSeconds: 2
timeoutSeconds: 1
- name: xtrabackup
image: ist0ne/xtrabackup:1.0
ports:
- name: xtrabackup
containerPort: 3307
command:
- bash
- "-c"
- |
set -ex
cd /var/lib/mysql
# 确定克隆数据的 binlog 位置(如果有的话)。
if [[ -f xtrabackup_slave_info && "x$(<xtrabackup_slave_info)" != "x" ]]; then
# XtraBackup 已经生成了部分的 “CHANGE MASTER TO” 查询
# 因为我们从一个现有副本进行克隆。(需要删除末尾的分号!)
cat xtrabackup_slave_info | sed -E 's/;$//g' > change_master_to.sql.in
# 在这里要忽略 xtrabackup_binlog_info (它是没用的)。
rm -f xtrabackup_slave_info xtrabackup_binlog_info
elif [[ -f xtrabackup_binlog_info ]]; then
# 我们直接从主实例进行克隆。解析 binlog 位置。
[[ `cat xtrabackup_binlog_info` =~ ^(.*?)[[:space:]]+(.*?)$ ]] || exit 1
rm -f xtrabackup_binlog_info xtrabackup_slave_info
echo "CHANGE MASTER TO MASTER_LOG_FILE='${BASH_REMATCH[1]}',\
MASTER_LOG_POS=${BASH_REMATCH[2]}" > change_master_to.sql.in
fi
# 检查我们是否需要通过启动复制来完成克隆。
if [[ -f change_master_to.sql.in ]]; then
echo "Waiting for mysqld to be ready (accepting connections)"
until mysql -h 127.0.0.1 -e "SELECT 1"; do sleep 1; done
echo "Initializing replication from clone position"
mysql -h 127.0.0.1 \
-e "$(<change_master_to.sql.in), \
MASTER_HOST='mysql-0.mysql', \
MASTER_USER='root', \
MASTER_PASSWORD='', \
MASTER_CONNECT_RETRY=10; \
START SLAVE;" || exit 1
# 如果容器重新启动,最多尝试一次。
mv change_master_to.sql.in change_master_to.sql.orig
fi
# 当对等点请求时,启动服务器发送备份。
exec ncat --listen --keep-open --send-only --max-conns=1 3307 -c \
"xtrabackup --backup --slave-info --stream=xbstream --host=127.0.0.1 --user=root"
volumeMounts:
- name: data
mountPath: /var/lib/mysql
subPath: mysql
- name: conf
mountPath: /etc/mysql/conf.d
resources:
requests:
cpu: 100m
memory: 100Mi
volumes:
- name: conf
emptyDir: {}
- name: config-map
configMap:
name: mysql
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 2Gi
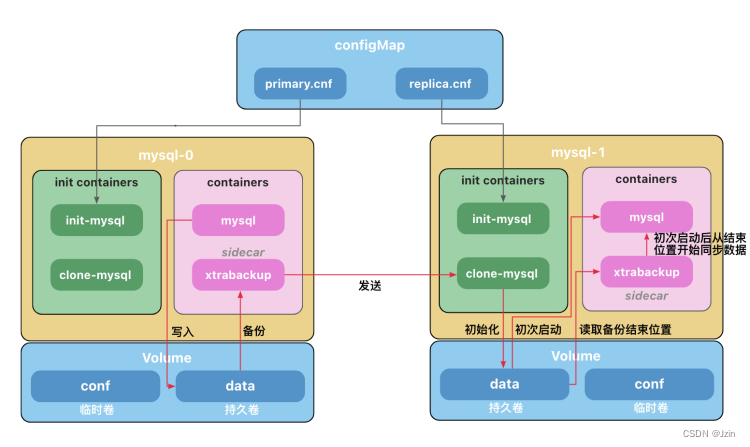
初始化容器(Init Containers)
初始化容器(Init Containers)是一种特殊容器,它在 Pod 内的应用容器启动之前运行。
初始化容器未执行完毕或以错误状态退出,Pod内的应用容器不会启动。
初始化容器需要在initContainers中定义,与containers同级。
基于上面的特性,初始化容器通常用于
- 生成配置文件
- 执行初始化命令或脚本
- 执行健康检查(检查依赖的服务是否处于Ready或健康Health的状态)
在本例子中,有两个初始化容器。
- init-mysql为MySQL实例分配server-id,并将mysql-0的配置文件设置为primary.cnf,其他副本设置为replica.cnf
- clone-mysql从前一个Pod中获取备份的数据文件放到自己的数据目录下
边车Sidecar
Pod中运行了2个容器,MySQL 容器和一个充当辅助工具的 xtrabackup 容器,我们称之为边车(sidecar)。
Xtrabackup是一个开源的MySQL备份工具,支持在线热备份(备份时不影响数据读写),是目前各个云厂商普遍使用的MySQL备份工具。

sidecar容器负责将备份的数据文件发送给下一个Pod,并在副本服务器初次启动时,使用数据文件完成数据的导入。
MySQL使用bin-log同步数据,但是,当数据库运行一段时间后,产生了一些数据,这时候如果我们进行扩容,创建了一个新的副本,有可能追溯不到bin-log的源头(可能被手动清理或者过期自动删除),因此需要将现有的数据导入到副本之后,再开启数据同步,sidecar只负责数据库初次启动时完成历史数据导入,后续的数据MySQL会自动同步。
客户端连接
写操作
写操作连接mysql-0.mysql
kubectl run mysql-client --image=mysql:5.7 -it --rm \
-- mysql -h mysql-0.mysql
CREATE DATABASE test;
CREATE TABLE test.messages (message VARCHAR(250));
INSERT INTO test.messages VALUES ('hello');
读操作
读操作连接到mysql-read,它是一个service,会自动将请求负载均衡到后端的三个mysql实例上。
kubectl run mysql-client --image=mysql:5.7 -it --rm \
-- mysql -h mysql-read
SELECT * FROM test.messages
参考文档:
https://kubernetes.io/zh-cn/docs/concepts/workloads/pods/init-containers/
https://kubernetes.io/zh-cn/docs/tasks/run-application/run-replicated-stateful-application/
深入理解StatefulSet:有状态应用实践
Port-forward端口转发
通常,集群中的数据库不直接对外访问。
但是,有时候我们需要图形化工具连接到数据库进行操作或者调试。
我们可以使用端口转发来访问集群中的应用。
kubectl port-forward可以将本地端口的连接转发给容器。
此命令在前台运行,命令终止后,转发会话将结束。
这种类型的连接对数据库调试很有用。
#主机端口在前,容器端口在后
#如果主机有多个IP,需要指定IP,如不指定IP,默认为127.0.0.1
kubectl port-forward pods/mysql-0 --address=192.168.56.109 33060:3306
网络访问
● 容器中应用访问数据库:
○ 读操作:mysql-read:3306
○ 写操作:mysql-0.mysql:3306
● 集群中的Node访问:
○ ClusterIP:port
● 集群外的主机访问:
○ 主机IP:nodePort
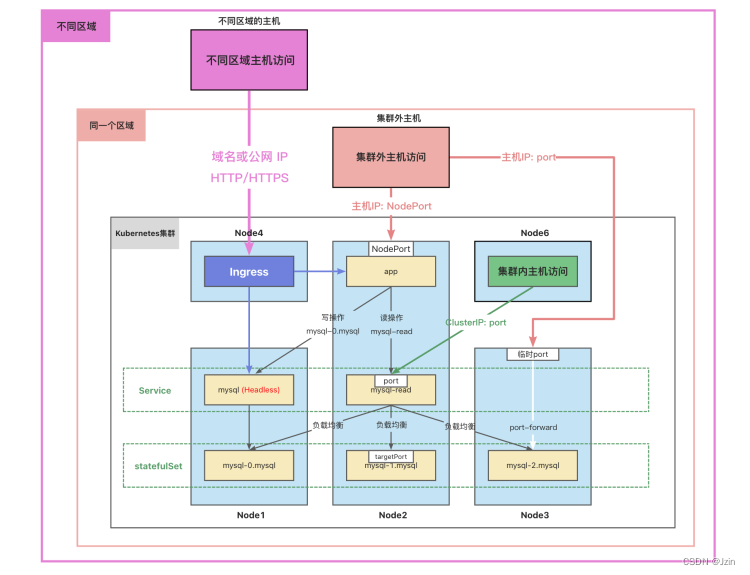
参考资料:
https://kubernetes.io/zh-cn/docs/tasks/run-application/run-replicated-stateful-application/
https://kubernetes.io/zh-cn/docs/concepts/services-networking/dns-pod-service/
https://kubernetes.io/zh-cn/docs/tasks/access-application-cluster/port-forward-access-application-cluster/
Helm安装MySQL机群
Helm简介与安装
Helm 是一个 Kubernetes 应用的包管理工具,类似于 Ubuntu 的 APT 和 CentOS 中的 YUM。
Helm使用chart 来封装kubernetes应用的 YAML 文件,我们只需要设置自己的参数,就可以实现自动化的快速部署应用。
安装Helm
下载安装包:
https://github.com/helm/helm/releases
https://get.helm.sh/helm-v3.10.0-linux-amd64.tar.gz
mv linux-amd64/helm /usr/local/bin/helm
在K3s中使用,需要配置环境变量
export KUBECONFIG=/etc/rancher/k3s/k3s.yaml
三大概念
● Chart 代表着 Helm 包。
○ 它包含运行应用程序需要的所有资源定义和依赖,相当于模版。
○ 类似于maven中的pom.xml、Apt中的dpkb或 Yum中的RPM。
● Repository(仓库) 用来存放和共享 charts。
○ 不用的应用放在不同的仓库中。
● Release 是运行 chart 的实例。
一个 chart 通常可以在同一个集群中安装多次。
每一次安装都会创建一个新的 release,release name不能重复。
Helm仓库
Helm有一个跟docker Hub类似的应用中心(https://artifacthub.io/),我们可以在里面找到我们需要部署的应用。
安装单节点Mysql
#添加仓库
helm repo add bitnami https://charts.bitnami.com/bitnami
#查看chart
helm show chart bitnami/mysql
#查看默认值
helm show values bitnami/mysql
#安装mysql
helm install my-mysql \
--set-string auth.rootPassword="123456" \
--set primary.persistence.size=2Gi \
bitnami/mysql
#查看设置
helm get values my-mysql
#删除mysql
helm delete my-release
Helm部署MySQL集群
安装过程中有两种方式传递配置数据:
● -f (或--values):使用 YAML 文件覆盖默认配置。可以指定多次,优先使用最右边的文件。
● --set:通过命令行的方式对指定项进行覆盖。
如果同时使用两种方式,则 --set中的值会被合并到 -f中,但是 --set中的值优先级更高。
使用配置文件设置MySQL的参数。
auth:
rootPassword: "123456"
primary:
persistence:
size: 2Gi
enabled: true
secondary:
replicaCount: 2
persistence:
size: 2Gi
enabled: true
architecture: replication
helm install my-db -f values.yaml bitnami/mysql
参考文档:
https://helm.sh/zh/docs/intro/install/
https://helm.sh/zh/docs/intro/using_helm/