目录
介绍
准备
目标
规定
思路
补充知识
解法参考
介绍
Markdown 因为其简洁的语法大受欢迎,已经成为大家写博客或文档时必备的技能点,众多博客平台都提倡用户使用 Markdown 语法进行文章书写,然后再发布后,实时的将其转化为常规的 HTML 页面渲染。
本题需要在已提供的基础项目中,使用 Nodejs 实现简易的 Markdown 文档解析器。
准备
开始答题前,需要先打开本题的项目代码文件夹,目录结构如下:
├── docs.md
├── images
│ └── md.jpg
├── index.html
└── js
├── index.js
└── parse.js其中:
index.html是主页面。images是图片文件夹。docs.md是需要解析的 Markdown 文件。js/index.js是提供的工具脚本,用于快速验证代码结果。js/parse.js是需要补充的脚本文件。
注意:打开环境后发现缺少项目代码,请手动键入下述命令进行下载:
cd /home/project
wget https://labfile.oss.aliyuncs.com/courses/18213/07.zip && unzip 07.zip && rm 07.zip目标
在 js/parse.js 中实现几种特定的 Markdown 语法解析,目前初始文件中已实现标题解析(即从 # 前缀转换为 <hn> 标签),请你继续完善该文件 TODO 部分,完成剩余语法解析操作,具体需求如下:
1.对分隔符进行解析,Markdown 中使用 --- (三条及以上的短横线) 作为分隔符,将其解析成为 <hr> 标签:
<!-- Markdown -->
----
<!-- 对应 HTML -->
<hr>2.对引用区块进行解析,Markdown 中使用 > 作为前缀,将其解析成为 <blockquote> 标签:
<!-- Markdown -->
> 引用区块1
> 多级引用区块2
> 多级引用区块2
<!-- 对应 HTML -->
<blockquote>
<p>引用区块1</p>
</blockquote>
<blockquote>
<p>多级引用区块2</p>
<p>多级引用区块2</p>
</blockquote>3.对无序列表进行解析,Markdown 中使用 * 或者 - 作为前缀,将其解析成为 <ul> 标签:
<!-- Markdown -->
* 无序列表
* 无序列表
* 无序列表
或者:
- 无序列表
- 无序列表
- 无序列表
<!-- 对应 HTML -->
<ul>
<li>无序列表</li>
<li>无序列表</li>
<li>无序列表</li>
</ul>4.对图片进行解析,Markdown 中使用  表示,将其解析成为 <img> 标签:
<!-- Markdown -->

<!-- 对应 HTML -->
<img src="./images/md.jpg" alt="图片">5.对文字效果进行解析,比如粗体效果,和行内代码块,将其分别解析成 <b> 和 code 标签:
<!-- Markdown -->
这是**粗体**的效果文字,这是内嵌的`代码行`
<!-- 对应 HTML -->
这是<b>粗体</b>的效果文字,这是内嵌的<code>代码行</code>在验证代码效果时,你可以在终端运行:
node ./js/index.js程序会将解析的结果输出到 index.html 文件中,然后通过浏览器查看输出的 index.html 是否符合解析要求(注意:程序不会实时的将结果更新到 index.html 文件中,在你的代码变更后,请重新执行上述命令)。
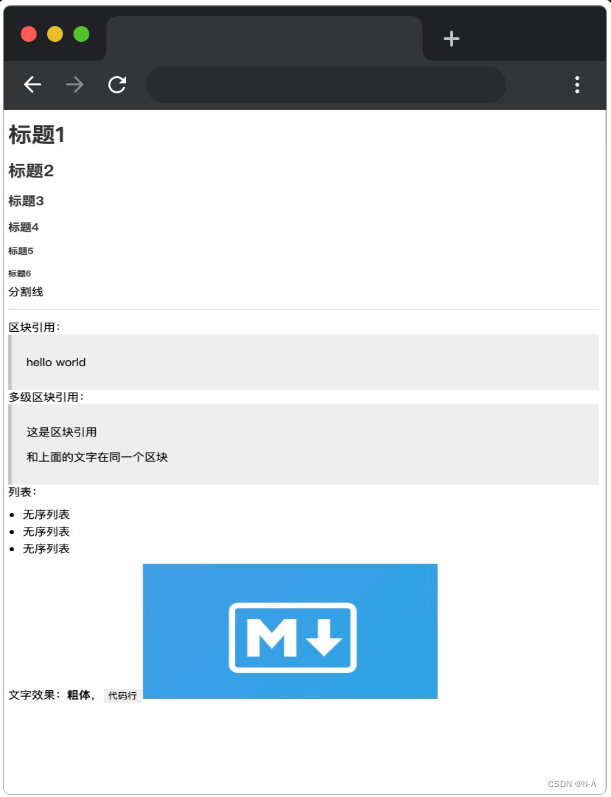
在题目所提供的数据的情况下,完成后的效果如下:
规定
- 请勿修改
js/parse.js文件外的任何内容。 - 请严格按照考试步骤操作,切勿修改考试默认提供项目中的文件名称、文件夹路径、class 名、id 名、图片名等,以免造成无法判题通过。自己先做以下把,传送门
思路
本道题在14届省赛中是倒数第二道题目,还是有一定的难度的。本文的题目表示考查的点是Node.js。但是在做这道题目我们压根就不需要使用到Node.js的知识点,因此这部分的功能题目源码都已经帮我们写好了。它主要是使用到了Node.js中的fs模块来读取md文件,后续对其进行读取到的文本内容通过解析之后渲染到了html文档中。如果对Node.js感兴趣的小伙伴可以看我之前发布的文章。一共6篇,还有一篇案例。
这道题主要是给我们一些规则,让我们通过对应的规则去将代码进行转换。做这道题目首先自己需要对正则有一点的了解。然后需要对字符串或者数组的一些方法熟悉,才能方便处理。同时还需要你会观察上下文的代码,通过它已经提供的代码来对其进行理解,然后编写出自己的代码。
补充知识
JavaScript中的正则表达式(正则规则)是用于匹配字符串模式的工具。它们提供了强大的方式来搜索、替换或提取字符串中的特定部分。以下是一些常见的JS正则表达式规则:
1.字面量表示法:使用斜杠(/)来包裹正则表达式模式,例如:/pattern/flags。pattern 是你要匹配的模式,flags 是标志,可以是 i(忽略大小写)、g(全局匹配)、m(多行匹配)等。
2.元字符:元字符是在正则表达式中具有特殊含义的字符,如 ^(匹配开头)、$(匹配结尾)、.(匹配除换行符外的任何字符)、*(匹配前一个元素零次或多次)等。
3.字符类:使用方括号 [ ] 来定义一个字符类,代表匹配其中任何一个字符。比如 [abc] 表示匹配字符 a、b 或 c。
4.量词:量词用于指定匹配元素的数量。常见的量词包括 *(零次或多次匹配)、+(一次或多次匹配)、?(零次或一次匹配)、{n}(匹配 n 次)、{n,}(至少匹配 n 次)、{n,m}(匹配 n 到 m 次)等。
5.捕获组:使用括号 () 可以创建一个捕获组,用于匹配子表达式,并可以在后续操作中引用它。
6.特殊字符转义:在正则表达式中,有些字符具有特殊含义,如果想要匹配这些字符本身,需要使用反斜杠 \ 进行转义,比如 \. 可以匹配 . 字符。
7.预定义模式:如 \d(匹配数字字符)、\w(匹配字母、数字或下划线)、\s(匹配空白字符)等,它们表示常见的字符集合。
8.修饰符:修饰符用于指定匹配规则的标志,比如 i(不区分大小写)、g(全局匹配)、m(多行匹配)等。
匹配数字
const pattern = /\d+/;
console.log(pattern.test("Hello 123")); // 输出 true,匹配到数字
console.log(pattern.test("Hello World")); // 输出 false,未匹配到数字
匹配邮箱:
const emailPattern = /^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$/;
console.log(emailPattern.test("example@mail.com")); // 输出 true,匹配邮箱格式
console.log(emailPattern.test("invalid_email.com")); // 输出 false,不匹配邮箱格式
提取字符串中的数字:
const str = "Age: 25, Height: 180cm";
const numberPattern = /\d+/g;
const numbers = str.match(numberPattern);
console.log(numbers); // 输出 ["25", "180"]
替换字符串中的特定内容:
const sentence = "Learn JavaScript, it's JavaScript";
const replacePattern = /JavaScript/g;
const replaced = sentence.replace(replacePattern, "JS");
console.log(replaced); // 输出 "Learn JS, it's JS"
检查字符串是否以特定模式开头:
const startsWithPattern = /^Start/;
console.log(startsWithPattern.test("Starts with Start")); // 输出 true
console.log(startsWithPattern.test("Does not start")); // 输出 false
解法参考
首先我们需要对分隔符来进行解析。我们先写出其对应的正则表达式,Markdown 中使用 --- (三条及以上的短横线) 作为分隔符。使用正则表示为:this.hr = /-{3,}/。接着我们判断是否符合分隔符,并且对其进行转化函数的编写。
//是否符合分隔符规范
isHr(){
return this.hr.test(this.lineText);
}
//解析分隔符
parseHr(){
return `<hr>`;
}然后在渲染类的 runParser()中编写对应的渲染处理。这部分我们跟上面提供的代码的标题函数一样即可。
// 分割线渲染
if (this.parser.isHr()) {
hasParsed.push(this.parser.parseHr());
currentLine++;
continue;
}接着我们对引用区块进行解析,同样对其进行判断以及解析。这部分的解析我们分为三个方法,开始标签,中间p标签以及结束标签的解析。
// 解析blockQuote开始标签
parseStartBlockQuote(){
return `<blockquote>`;
}
// 解析blockQuote结束标签
parseEndBlockQuote(){
return `</blockquote>`;
}接着我们解析中间的文字,我们使用到了split方法来进行获取到的那一行文字通过>符号来进行分割成字符串数组,如下。接着我们获取下标为1的元素,并使用trim()用于去除字符串中的空格。最后将这部分获取到的文字包裹来一个p标签中。
[ '', ' hello world' ]
[ '', ' 这是区块引用' ]
[ '', ' 和上面的文字在同一个区块' ] // 生成blockQuote中的p标签
parseBlockQuoteP(){
//split将一个字符串分割成字符串数组
const temp = this.lineText.split(">");
//trim()用于去除字符串中的空格
console.log(temp)
const content = temp[1].trim();
// console.log(content)
return `<p>${content}</p>`;
}接下来我们对引用区块进行渲染,首先若匹配到 < 标签我们就先为其加上一个块级的开始标签,同时也加上中间文字的解析,然后我们通过循环,来对现在的currentLine不断往下,然后获取对应的行文本内容,判断若匹配不到 < 标签,我们就为其添加一个块级的结束标签。
// 块作用区渲染
if (this.parser.isBlockQuote()){
hasParsed.push(this.parser.parseStartBlockQuote())
while(true){
hasParsed.push(this.parser.parseBlockQuoteP())
currentLine++;
this.parser.parseLineText(this.getLineText(currentLine));
if(!this.parser.isBlockQuote()){
hasParsed.push(this.parser.parseEndBlockQuote())
break
}
}
continue;
}接下来的无序列表进行解析为块级作用域的解析思路是一样的。这里就不做过多的解释。
//是否为无序列表
isUnorderedList(){
return this.unorderedList.test(this.lineText);
}
// // 解析unorderedList开始标签
parseStartUnorderedList(){
return `<ul>`;
}
// 解析unorderedList结束标签
parseEndUnorderedList(){
return `</ul>`;
}
// 生成unorderedList中的li标签
parseUnorderedListLi(){
//split将一个字符串分割成字符串数组
const temp = this.lineText.split(" ");
//trim()用于去除字符串中的空格
const content = temp[1].trim();
// console.log(content)
return `<li>${content}</li>`;
} //无序列表渲染
if (this.parser.isUnorderedList()){
hasParsed.push(this.parser.parseStartUnorderedList())
while(true){
hasParsed.push(this.parser.parseUnorderedListLi())
currentLine++;
this.parser.parseLineText(this.getLineText(currentLine));
if(!this.parser.isUnorderedList()){
hasParsed.push(this.parser.parseEndUnorderedList())
break
}
}
continue;
}接着我们对图片进行解析,Markdown 中使用  表示,将其解析成为 <img> 标签。这部分也比较简单使用到了slice方法来进行截取对应的图片的路径已经alt属性的值。slice方法我们在第一篇真题讲解中有介绍了,可以去看看。
//是否为图片
isImage(){
return this.image.test(this.lineText);
}
// 解析image标签
parseImage(){
const src=this.lineText.slice(6,-1);
const alt=this.lineText.slice(2,4);
return `<img src="${src}" alt="${alt}">`;
} //图片渲染
if(this.parser.isImage()){
hasParsed.push(this.parser.parseImage());
currentLine++;
continue;
}最后,我们需要对文字效果进行解析,比如粗体效果,和行内代码块,将其分别解析成<b>和code标签。this.strongText 是一个匹配粗体文本的正则表达式。replace 方法会将匹配到的粗体文本替换成函数中返回的内容。参数 match 包含了整个匹配的字符串,而 p1 则是捕获组中捕获到的内容,也就是粗体文本的实际内容。若遇到粗体以及代码块的标识则解析成对应的格式,否则对正常文字进行正常解析。
//解析文本
parseText(){
let temp=this.lineText;
//若有粗体则对其进行添加标签
temp=temp.replace(this.strongText,(match,p1)=>{
return `<b>${p1}</b>`;
})
//若遇到代码块则对其进行添加标签
temp=temp.replace(this.codeLine,(match,p1)=>{
return `<code>${p1}</code>`;
})
return temp;
}; //渲染文本
hasParsed.push(this.parser.parseText());
currentLine++;
continue;
好啦!本文就到这里结束了~~~