简介
用atomic定义的变量,支持原子操作,即要么全部完成操作,要不全部没有完成,我们是不可能看到中间状态。一般在多线程程序中,可以用atomic来完成数据同步。
标准库为我们主要提供了四类工具
- atomic类模板
- 操作atomic的全局方法
- atomic_flag
- 内存顺序,即约束了当前atomic对象前后代码直行的相对顺序
atomic_flag是保证无锁的,任何平台都可以放心使用;atomic 对于整型,浮点类型,提供的方法会略有不同;内存顺序是在操作原子对象的时候,可以施加影响
atomic_flag
atomic_flag相当于是一个原子的bool类型,与atomic的不同点,除了无锁之外,atomic_flag提供的方法也是比较有限的,没有load和store方法:

构造了方法,atomic_flag有默认构造方法,但是直到C++20,默认构造时才会将状态置为false,在此之前为定义状态。所以在C++20之前都是这么定义atomic_flag的
std::atomic_flag automatic_flag = ATOMIC_FLAG_INIT; // false
test_and_set 将atomic_flag设置true,并返回之前的值,可能是true,也可能是false
bool test_and_set( std::memory_order order = std::memory_order_seq_cst ) volatile noexcept; // order是内存顺序,后面会写
bool test_and_set( std::memory_order order = std::memory_order_seq_cst ) noexcept;
用atomic_flag实现自旋锁是一个经典用法
#include <atomic>
class Spinlock
{
public:
spinlock_mutex():m_flag(ATOMIC_FLAG_INIT) {}
void lock() {
while(flag.test_and_set()); // 不断重试,直到test_and_set返回false。测试m_flag
}
void unlock() {
flag.clear(std::memory_order_release);
}
private:
std::atomic_flag m_flag;
};
std::atomic
atomic对于不同的类型支持的方法不一样,任何类型都有的方法如下:
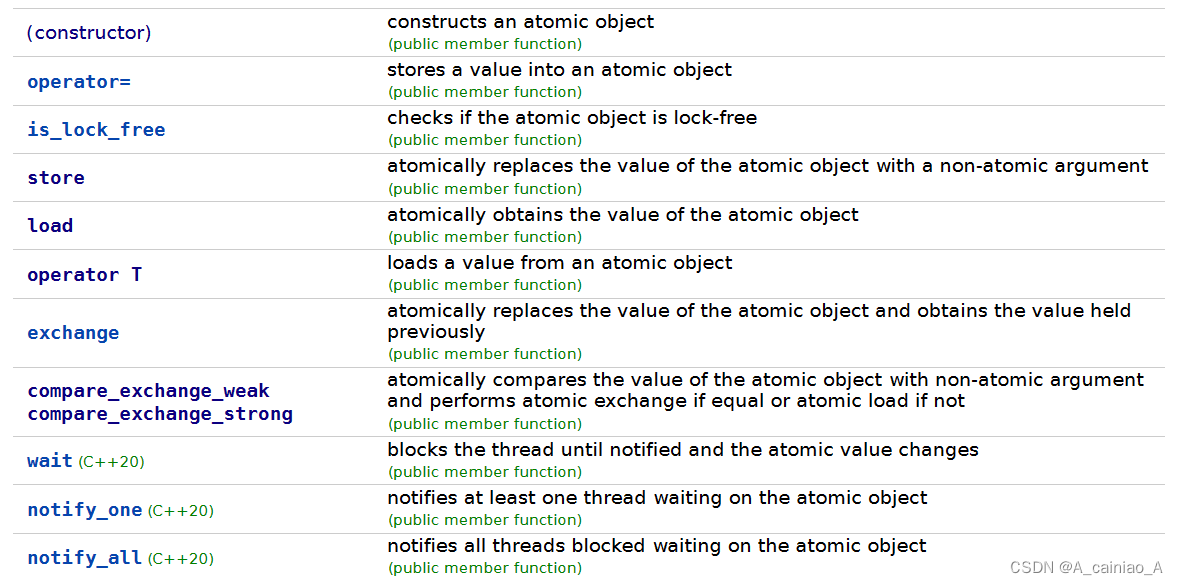
构造方法
atomic() noexcept = default;
constexpr atomic( T desired ) noexcept; // 将atomic初值设置为desired,**但这个过程不是原子的**
atomic( const atomic& ) = delete;
atomic的拷贝赋值操作和普通类的不一样,他的返回值不是引用,而是拷贝。如果返回了引用就无法保证原则操作了。另外,等号右边的是T类型,而不是atomic类型。
T operator=( T desired ) noexcept;
T operator=( T desired ) volatile noexcept;
atomic& operator=( const atomic& ) = delete;
atomic& operator=( const atomic& ) volatile = delete;
检查atomic的当前实现是否为无锁方式。如果是,则atomic原子操作是cpu指令级,否则就是通过锁实现的原子操作,可能用的就是:std::mutex
bool is_lock_free() const noexcept;
bool is_lock_free() const volatile noexcept;
向atomic中写值,为原子操作
void store( T desired, std::memory_order order = std::memory_order_seq_cst ) noexcept;
void store( T desired, std::memory_order order = std::memory_order_seq_cst ) volatile noexcept;
从atomic中读取值,为原子操作。返回值为atomic中保存值的拷贝
T load( std::memory_order order = std::memory_order_seq_cst ) const noexcept;
T load( std::memory_order order = std::memory_order_seq_cst ) const volatile noexcept;
隐式转换,等价于load()
operator T() const noexcept;
operator T() const volatile noexcept;
读改写当前变量,返回值是读到的之前的值,改是指对atomic中管理值的修改(瞎猜的:会不会是写缓存,后面研究一下 ),写是指写内存。
T exchange( T desired, std::memory_order order = std::memory_order_seq_cst ) noexcept;
T exchange( T desired, std::memory_order order = std::memory_order_seq_cst ) volatile noexcept;
比较修改当前变量
如果*this == expected, *this = desired,return true
否则 expected = *this, return false
bool compare_exchange_weak( T& expected, T desired,
std::memory_order success,
std::memory_order failure ) noexcept;
bool compare_exchange_strong( T& expected, T desired,
std::memory_order success,
std::memory_order failure ) noexcept;
weak版本的CAS允许偶然出乎意料的返回(比如在字段值和期待值一样的时候却返回了false),不过在一些循环算法中,这是可以接受的。通常它比起strong有更高的性能。
atomic对整型支持的最好的,提供的方法也是最多的,还提供了很多typedef的别名,类似这样
对于整型atomic提供的额外方法有:

加法会返回之前的值
T fetch_add( T arg, std::memory_order order = std::memory_order_seq_cst ) noexcept;
加法也会返回之前的值
T fetch_sub( T arg, std::memory_order order = std::memory_order_seq_cst ) noexcept;
按位与,或,异或,也都会返回之前的值
如果atomic的类型为T*,那么直行加,减方法的时候,会返回T*
如果使用自定义类型去作为atomic的模板参数,需要这个自定义类型是可平凡复制的(TriviallyCopyable ),即下面对象的value都必须为true
std::is_trivially_copyable<T>::value
std::is_copy_constructible<T>::value
std::is_move_constructible<T>::value
std::is_copy_assignable<T>::value
std::is_move_assignable<T>::value
简单来说,可平凡复制类型表示这个类型的对象可以直接进行内存拷贝,而不需要执行特殊的拷贝构造函数或者析构函数。换句话说,可平凡复制类型的对象可以拷贝到char或者unsigned char数组中,可以通过std::memcpy or std::memmove操作。一个可平凡复制类型通常具有简单的内存布局,没有虚拟函数或者虚拟基类,并且其拷贝构造函数和析构函数是默认生成的。这意味着这种类型的对象可以更高效地进行拷贝和赋值操作。像标量类型(算术类型/枚举/指针),标量类型作为成员变量构成的类,以及相应数组和cv-qualified修饰的,都是平凡复制类型。
这里有一些例子:https://www.cnblogs.com/BuzzWeek/p/17578402.html
cv-qualified
CV分别是const 以及volatile的缩写。
用const,volatile以及const volatile之一作修饰的变量被成为cv-qualified ,否则该变量是cv-unqualified
内存顺序 std::memory_order
在atomic的很多方法中都有一个参数为std::memory_order类型,不过一般都有默认值(memory_order_seq_cst)。现代C++编译器为了进一步提高代码运行效率,在编译的时候,可能会改变代码的直行顺序,当然是在不改变原有代码逻辑的情况下。比如下面例子,不管那种顺序直行代码,都不影响最终结果。但改变顺序后,可能直行效率会更高一些。std::memory_order正是用来告诉编译器,要不要做这种优化,当然C++中定义会更加详细一些。
int a = 1;
int b = 2;
int c = a;
---
int b = 2;
int a = 1;
int c = a;
std::memory_order的定义如下
typedef enum memory_order {
memory_order_relaxed,
memory_order_consume,
memory_order_acquire,
memory_order_release,
memory_order_acq_rel,
memory_order_seq_cst
} memory_order;
| 枚举值 | 含义 |
|---|---|
| memory_order_relaxed | 允许编译器为了效率可以任意优化执行顺序 |
| memory_order_consume | 如果后续有关于当前原子变量的操作,必须在本条原子操作完成之后直行 |
| memory_order_acquire | 所有后续的读操作必须在本条原子操作完成后直行 |
| memory_order_release | 所有之前的写操作完成后才能执行本条原子操作 |
| memory_order_acq_rel | memory_order_acquire 和 memory_order_release 的组合 |
| memory_order_seq_cst | 全部存取都按顺序执行,不允许编译器优化直行顺序 |
比如使用 memory_order_consume
atomic<int*> ptr;
atomic<int> data;
{
int* p2;
while(!(p2=ptr.load(memory_order_consume)));
assert(*p2=="Hello"); // 这一行一定在while之后
int d = 5; // 这一行可能在int* 2之前直行,也可能在while之前,总之由于他不依赖ptr,所以就有可能被编译器优化执行顺序
}
再比如 memory_order_acquire
atomic<int> a;
atomic<int> b;
{
while(b.load(memory_order_acquire)!=2);//本原子操作必须完成才能执行之后所有的读原子操作, 即a.load一定在本条语句之后
std::cout << a.load(memory_order_relaxed) << std::endl;
}
其他的基本类似
前面提到std::memory_order一般是作为atomic相关的方法的一个参数。那么如果想脱离atomic使用std::memory_order,C++提供了std::atomic_thread_fence
extern "C" void atomic_thread_fence( std::memory_order order ) noexcept;
一个官方的例子
// Global
std::string computation(int);
void print(std::string);
std::atomic<int> arr[3] = {-1, -1, -1};
std::string data[1000]; //non-atomic data
// Thread A, compute 3 values.
void ThreadA(int v0, int v1, int v2)
{
// assert(0 <= v0, v1, v2 < 1000);
data[v0] = computation(v0);
data[v1] = computation(v1);
data[v2] = computation(v2);
std::atomic_thread_fence(std::memory_order_release);
std::atomic_store_explicit(&arr[0], v0, std::memory_order_relaxed);
std::atomic_store_explicit(&arr[1], v1, std::memory_order_relaxed);
std::atomic_store_explicit(&arr[2], v2, std::memory_order_relaxed);
}
// Thread B, prints between 0 and 3 values already computed.
void ThreadB()
{
int v0 = std::atomic_load_explicit(&arr[0], std::memory_order_relaxed);
int v1 = std::atomic_load_explicit(&arr[1], std::memory_order_relaxed);
int v2 = std::atomic_load_explicit(&arr[2], std::memory_order_relaxed);
std::atomic_thread_fence(std::memory_order_acquire);
// v0, v1, v2 might turn out to be -1, some or all of them.
// Otherwise it is safe to read the non-atomic data because of the fences:
if (v0 != -1)
print(data[v0]);
if (v1 != -1)
print(data[v1]);
if (v2 != -1)
print(data[v2]);
}
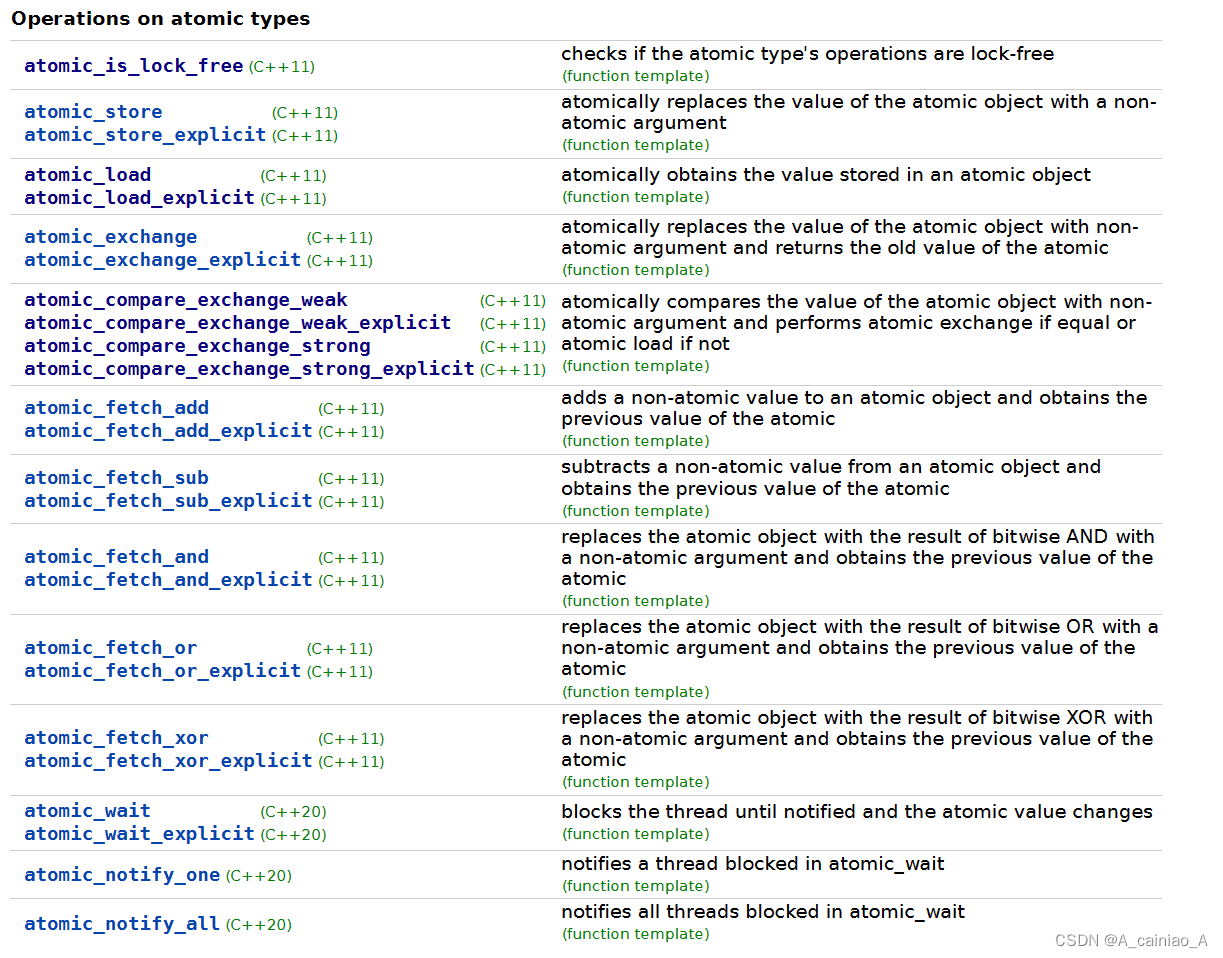
操作atomic的全局方法
功能和atomic的成员方法一样,命名风格基本都是 atomic_xxx