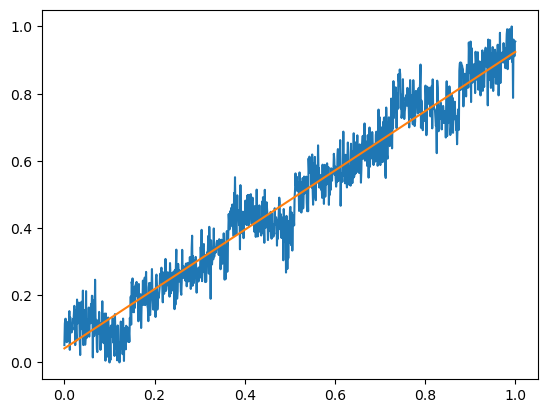
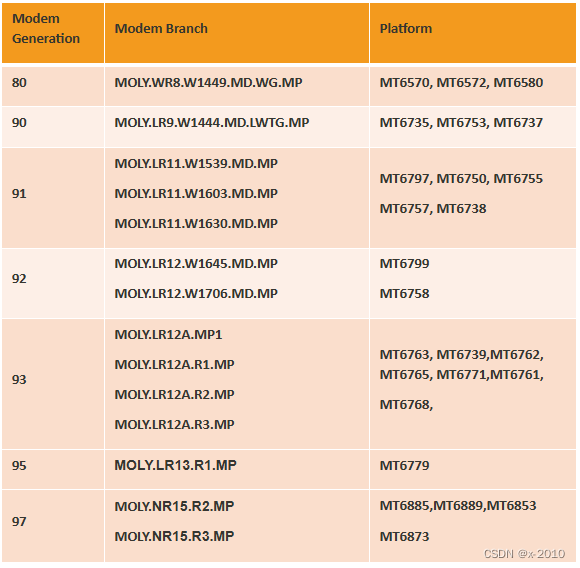
X = torch.arange(1,1001)# Y = 0.7 * X + 100 + torch.randn(X.size())
Y = trend(X,0.3)+ seasonality(X, period=365, amplitude=30)+ noise(X,15)+200
X.shape, Y.shape
(torch.Size([1000]), torch.Size([1000]))
plt.plot(X.numpy(), Y.numpy());
对测试数据进行处理
# 模型的数据的类型需要是32位浮点型
X = X.type(torch.float32)
Y = Y.type(torch.float32)
X.dtype, Y.dtype
(torch.float32, torch.float32)
# 模型的数据需要进行归一化或者标准化,下面是归一化
X =(X - X.min())/(X.max()- X.min())
Y =(Y - Y.min())/(Y.max()- Y.min())
plt.plot(X.numpy(), Y.numpy());
定义模型和模型参数
# 线性模型只有两个参数斜率k,和偏置b# 线性模型的方程为y = k * x + b
k = nn.Parameter(torch.rand(1, dtype=torch.float32))
b = nn.Parameter(torch.rand(1, dtype=torch.float32))# 下面输出中的requires_grad=True 表示该参数需要计算梯度# 梯度用于在反向传播中对参数进行优化,优化方法即梯度下降
k, b
第二届材料科学与智能制造国际学术会议(MSIM 2024)
2024 2nd International Conference on Materials Science and Intelligent Manufacturing
2024年第二届材料科学与智能制造国际学术会议 (MSIM2024)将于2024年1月19日至21日在…
前言
最近作者的电脑 C 盘变红了,这让我很难受(有点小强迫症),所以准备重新安装下系统,顺便把 C 盘扩大点。 注意: 操作系统是 windows 11 23H2。 所有的命令行都是使用 Windows Terminal 中进行的。 安装 Windows Terminal
由于…