数据库系统概论考试需知
一、分值分布
1、判断题(10分) 1分一个
2、填空题(20分) 2分一个
3、选择题(20分) 2分一个
4、分析题(30分) 第一题10分,第二题20分
5、综合题(20分)
二、考试范围:
1、计科1-4班:
1、2、3、4、5、6、7、10、11章出题;
其中6.2.7多值依赖、6.2.8 4NF不考、第6章不考证明题、标※不考;
2、计科5-8班:
添加重点:2.4关系代数、6.2.3范式、7数据库设计、11.2封锁;
3、信安专业:
1、4、5、6、10、11章考选择题,填空题,判断题 ;
2、3、7章考大题(关系代数、SQL、概念和逻辑设计);
4、大数据专业:
判断题:1、2、4、5、6、7、10、11章;
填空题:1、4、5、7、10、11章;
选择题:1、2、4、5、6、7、10、11章;
分析题:2.4(关系代数)、3(SQL语句);
综合题:7(数据库设计);
第一章 绪论
一、数据库系统概述
1、数据库的4个基本概念
(1)数据(Data):
- 数据是数据库中存储的基本对象;
- 描述事物的符号记录称为数据;
- 数据的定义称为数据的语义,数据与其语义是不可分的。
(2)数据库(DataBase):
- 数据库是长期储存在计算机内、有组织的、可共享的大量数据的集合;
- 数据库中的数据按一定的数据模型组织、描述和储存,具有较小的冗余度、较高的数据独立性和易扩展性,并可为各种用户共享。
(3)数据库管理系统(DataBase Management System):
- 数据库管理系统是计算机的基础软件;
- 数据库的主要功能:
- 数据定义功能;
- 数据组织、存储和管理;
- 数据操纵功能;
- 数据库的事务管理和运行管理;
- 数据库的建立和维护功能;
- 其他功能(如DBMS与网络中其它软件系统的通信功能等)。
(4)数据库系统(DataBase System):
数据库系统是由数据库、数据库管理系统(及其应用开发工具)、应用程序和数据库管理员组成的存储、管理、处理和维护数据的功能。
2、数据管理技术的产生和发展
- 人工管理阶段;
- 文件系统阶段;
- 数据库系统阶段(从文件系统到数据库系统标志着数据管理技术的飞跃)。
3、数据库系统的特点
(1)数据结构化:
- 数据库系统实现整体数据的结构化,是数据的主要特征之一,也是数据库系统与文件系统的本质区别;
- 整体结构化是指数据库中的数据不再仅针对某一个应用,而是面向整个组织或企业;不仅数据内部是结构化的,而且整体是结构化的,数据之间是具有联系的。
(2)数据的共享性高、冗余度低且易扩充:
- 数据共享可以大大减少数据冗余,节约存储空间。数据共享还能够避免数据之间的不相容性与不一致性;
- 数据面向整个系统,是具有结构的数据,可被多个应用共享使用,也容易增加新的应用。这使得数据库系统弹性大,易于扩充。
(3)数据独立性高:
- 物理独立性(用户的应用程序与数据库中数据的物理存储相互独立);
- 逻辑独立性(用户的应用程序与数据库的逻辑结构相互独立)。
(4)数据由数据库管理系统来统一管理和控制:
- 数据的安全性保护(保护数据以防止不合法使用造成的数据泄密和破坏);
- 数据的完整性检查(数据的正确性,有效性和相容性);
- 并发控制;
- 数据库恢复;
# 总结:
数据库是长期储存在计算机内、有组织的、可共享的大量数据的集合。它可以供各种用户共享,具有最小冗余度和较高的数据独立性。数据库管理系统在数据库建立、运用和维护是对数据库进行统一控制,以保证数据的完整性和安全性,并在多用户同时使用数据库时进行并发控制,在发生故障后对数据库进行恢复。数据库系统的出现使信息系统从以加工数据的程序为中心转向围绕共享的数据库为中心的新阶段。
二、数据模型
1、概念
数据模型是对现实世界数据特征的抽象,是数据库系统的核心和基础。
2、两类数据模型
(1)概念模型;
(2)逻辑模型和物理模型;
3、概念模型
(1)信息实际中的基本概念:
实体:客观存在并可相互区别的事物称为实体。
属性:实体所具有的某一特性称为属性。
码:唯一标识实体的属性集称为码。
实体型:用实体名及其属性名集合来抽象和刻画同类实体,称为实体型。
实体集:同一类型实体的集合称为实体集。
联系:实体之间的联系通常是指不同实体集之间的联系。实体之间的联系有一对一、一对多和多对多等多种类型。
(2)概念模型的一种表示方法:
实体-联系方法(Entity-Relationship approach)。该方法用E-R图(E-R diagram)来描述现实世界的概念模型,E-R方法也称为E-R模型。
4、数据模型的组成要素
(1)数据结构:
数据结构描述数据库的组成对象以及对象之间的联系。
(2)数据操作:
数据操作是指对数据库中各种对象(型)的实例(值)允许执行的操作的集合,包括操作及有关的操作规则。
(3)数据的完整性约束条件:
数据的完整性约束条件是一组完整性规则。
5、常用的数据模型
- 层次模型(hierarchical model);
- 网状模型(network model);
- 关系模型(relational model);
- 面向对象数据模型(object oriented data model).;
- 对象关系数据模型(object relational data model);
- 半结构化数据模型(semi structure data model);
#层次模型和网状模型统称为格式化模型。
#所谓基本层次联系是指两个记录以及它们之间的一对多(包括一对一)的联系:

图中R位于联系L的始点,称为双亲结点,R位于联系L,的终点,称为子女结点。
6、层次模型
(1)定义:
在数据库中定义满足下面两个条件的基本层次联系的集合为层次模型:
有且只有一个结点没有双亲结点,这个结点称为根结点;
根以外的其他结点有且只有一个双亲结点。
在层次模型中,每个结点表示一个记录类型,记录类型之间的联系用结点之间的线(有向边)表示,这种联系是父子之间的一对多的联系。这就使得层次数据库系统只能处理一对多的实体联系。
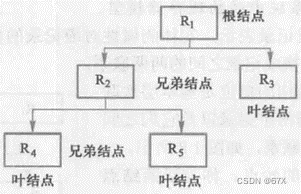
层次模型像一棵倒立的树,结点的双亲是唯一的。
(2)优点:
- 层次模型的数据结构比较简单清晰。
- 层次数据库的查询效率高。
- 层次数据模型提供了良好的完整性支持。
(3)缺点:
- 现实世界中很多联系是非层次性的,如多对多联系,不适合用层次模型表示。
- 如果一个结点具有多个双亲结点等,用层次模型表示这类联系就很笨拙,只能通过引入冗余数据(易产生不一致性)或创建非自然的数据结构(引入虚拟结点)来解决。对插入和删除操作的限制比较多,因此应用程序的编写比较复杂。
- 查询子女结点必须通过双亲结点。
- 由于结构严密,层次命令趋于程序化。
7、网状模型:
(1)典型代表系统:DBTG系统,亦称CODASYL系统。
(2)定义:在数据库中,把满足以下两个条件的基本层次联系集合称为网状模型:
- 允许一个以上的结点无双亲;
- 一个结点可以有多于一个的双亲。
从定义可以看出,层次模型中子女结点与双亲结点的联系是唯一的,而在网状模型中这种联系可以不唯一(下图为网状模型的例子)。
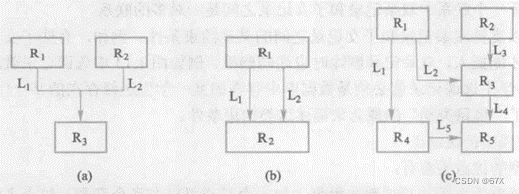
(3)优点:
- 能够更为直接地描述现实世界,如一个结点可以有多个双亲,结点之间可以有多种联系。
- 具有良好的性能,存取效率较高。
(4)缺点:
- 结构比较复杂,而且随着应用环境的扩大,数据库的结构就变得越来越复杂,不利于最终用户掌握。
- 网状模型的DDL、DML复杂,并且要嵌入某一种高级语言(如COBOL、C)中。用户不容易掌握,不容易使用。
- 由于记录之间的联系是通过存取路径实现的,应用程序在访问数据时必须选择适当的存取路径,因此用户必须了解系统结构的细节,加重了编写应用程序的负担。
8、关系模型:
(1)关系模型的数据结构
关系:一个关系对应通常说的一张表。
元组:表中的一行即为一个元组。
属性:表中的一列即为一个属性,给每一个属性起一个名称即属性名
码:也称为码键。表中的某个属性组,可以唯一确定一个元组,也就成为本关系的码。
域:域是一组具有相同数据类型的值的集合,属性的取值范围来自某个域。
分量:元组中的一个属性值。
关系模式:对关系的描述,一般表示为:关系名(属性1,属性2,……,属性n)。
# 关系模型要求关系必须是规范化的,关系的每一个分量必须是不可分的数据项。

(2)关系模型的数据操纵与完整性约束
关系模型的数据操纵主要包括查询、插入、删除和更新数据。这些操作必须满足关系的完整性约束条件。关系的完整性约束条件包括三大类:实体完整性、参照完整性和用户定义的完整性。
# 操作对象和操作结果都是关系,关系模型把存取路径向用户隐蔽起来,用户只要指出“干什么”或“找什么”,不必详细说明“怎么干”或“怎么找”。
(3)优点
- 关系模型与格式化模型不同,它是建立在严格的数学概念的基础上的。
- 关系模型的概念单一。无论实体还是实体之间的联系都用关系来表示。对数据的检索和更新结果也是关系(即表)。所以其数据结构简单、清晰,用户易懂易用。
- 关系模型的存取路径对用户透明,从而具有更高的数据独立性、更好的安全保密性,也简化了程序员的工作和数据库开发建立的工作。
(4)缺点
- 由于存取路径对用户是隐蔽的,查询效率往往不如格式化数据模型。
- 为了提高性能,数据库管理系统必须对用户的查询请求进行优化,因此增加了开发数据库管理系统的难度。
三、数据库系统的结构
1、数据库系统模式的概念
在数据模型中有“型”(type)和“值”(value)的概念。型是指对某一类数据的结构和属性的说明,值是型的一个具体赋值。
模式(schema)是数据库中全体数据的逻辑结构和特征的描述,它仅仅涉及型的描述不涉及具体的值。模式的一个具体值称为模式的一个实例(instance)。模式是相对稳定的,而实例是相对变动的。
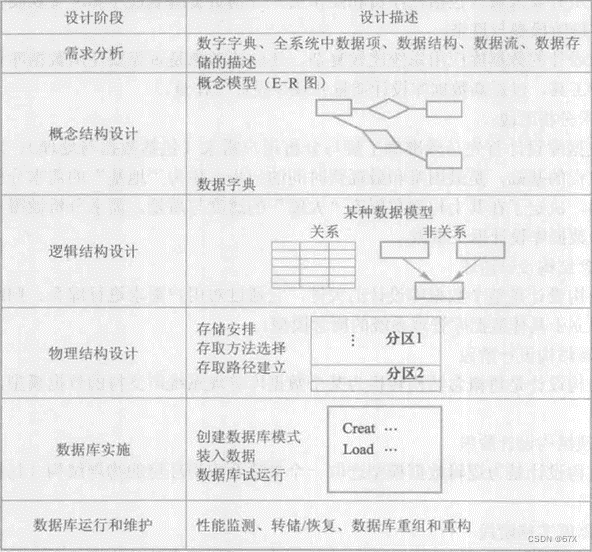
2、数据库系统的三级模式结构
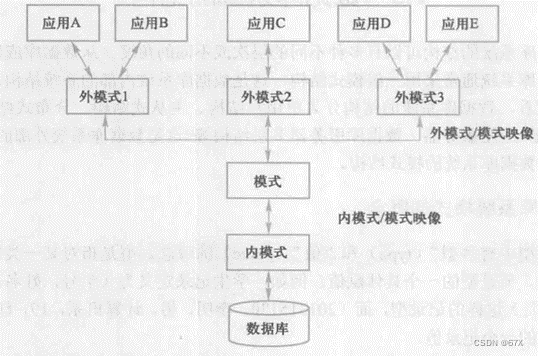
- 模式(schema):模式也称逻辑模式,是数据库中全体数据的逻辑结构和特征的描述,是所有用户的公共数据视图。
- 外模式(external schema):也称子模式(subschema)或用户模式,它是数据库用户(包括应用程序员和最终用户)能够看见和使用的局部数据的逻辑结构和特征的描述,是数据库用户的数据视图,是与某一应用有关的数据的逻辑表示。
- 内模式(internal schema):也称存储模式(storage schema),一个数据库只有一个内模式。它是数据物理结构和存储方式的描述,是数据在数据库内部的组织方式。
# 数据库系统的三级结构的优点:
数据库系统的三级模式是对数据的三个抽象级别,它把数据的具体组织留给DBMS管理,使用户能逻辑抽象地处理数据,而不必关心数据在计算机中的表示和存储。为了能够在内部实现这三个抽象层次的联系和转换,数据库系统在这三级模式之间提供了两层映像:外模式/模式映像和模式/内模式映像。正是这两层映像保证了数据库系统中的数据能够具有较高的逻辑独立性和物理独立性。
3、数据库的二级映像功能和数据独立性
- 外模式/模式映像:当模式改变时(例如增加新的关系、新的属性、改变属性的数据类型等),由数据库管理员对各个外模式/模式的映像作相应改变,可以使外模式保持不变。应用程序是依据数据的外模式编写的,从而应用程序不必修改,保证了数据与程序的逻辑独立性,简称数据的逻辑独立性。
- 模式/内模式映像:当数据库的存储结构改变时(例如选用了另一种存储结构),由数据库管理员对模式/内模式映像作相应改变,可以使模式保持不变,从而应用程序也不必改变。保证了数据与程序的物理独立性,简称数据的物理独立性。
# 数据与程序之间的独立性使得数据的定义和描述可以从应用程序中分离出去。另外,由于数据的存取由数据库管理系统管理,从而简化了应用程序的编制,大大减少了应用程序的维护和修改。
四、数据库系统的组成
数据库系统一般由数据库、数据库管理系统(及其应用开发工具)、应用程序和数据库管理员构成。
# 数据库管理员的职责:
- 决定数据库中的信息内容和结构;
- 决定数据库的存储结构和存取策略;
- 定义数据的安全性要求和完整性约束条件;
- 监控数据库的使用和运行;
- 数据库的改进和重组、重构。
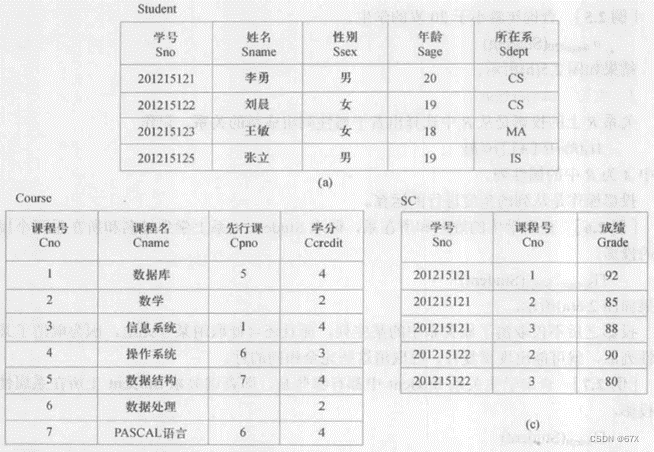
第二章 关系数据库
一、关系数据结构及形式化定义
1、关系
关系模型是建立在集合代数的基础上的,这里从集合论角度给出关系数据结构的形式化定义。
- 域:域是一组具有相同数据类型的值的集合。
- 笛卡尔积:给定一组域D1、D2、…、Dn,允许其中某些域是相同的,D1、D2、…、Dn的笛卡儿积为D1×D2×…×Dn={(d1、d2、 …、dn)|d,∈Di,i=1、2、…、n},其中,每一个元素(d1、d2、…、dn)叫作一个n元组,或简称元组。元素中的每个值di叫做一个分量。一个域允许的不同取值个数称为这个域的基数。若Di(i=1,2,…,n)为有限集,其基数为mi(i=1、2、…、n),则D1×D2×…×Dn的基数M为:
- 笛卡儿积可表示为一张二维表。表中的每行对应一个元组,表中的每一列的值来自一个域。
- 关系:D1×D2×…×Dn的子集叫做在域D1、D2、…、Dn上的关系,表示为R(D1、D2、…、Dn),R表示关系的名字,n是关系的目或度(n元关系)。若关系中的某一属性组的值能唯一地标识一个元组,而其子集不能,则称该属性组为候选码。若一个关系有多个候选码,则选定其中一个为主码、候选码的诸属性称为主属性。不包含在任何候选码中的属性称为非主属性或非码属性。在最简单的情况下,候选码只包含一个属性。在最极端的情况下,关系模式的所有属性是这个关系模式的候选码,称为全码。关系可以有三种类型:基本关系(通常又称为基本表或基表)、查询表和视图表。
- # 基本关系的性质:
- 列是同质的;
- 不同的列可出自同一个域;
- 列的次序可以任意交换;
- 任意两个元组的候选码不能取相同的值;
- 行的次序可以任意交换;
- 分量必须取原子值,即每一个分量都必须是不可分的数据项。
- # 规范化的关系简称为范式(Normal Form,NF)。
2、关系模式
关系的描述称为关系模式。它可以形式化地表示为R(U,D,DOM,F),其中R为关系名,U为组成该关系的属性名集合,D为U中属性所来自的域,DOM为属性向域的映像集合,F为属性间数据的依赖关系集合。
关系模式通常可以简记为R(U)或R(A1,A2,…,An),其中R为关系名,A1,A2,…,An为属性名,而域名及属性向域的映像常常直接说明为属性的类型、长度。
3、关系数据库
关系数据库也有型和值之分。关系数据库的型也称为关系数据库模式,是对关系数据库的描述。关系数据库模式包括若干域的定义,以及在这些域上定义的若干关系模式。关系数据库的值是这些关系模式在某一时刻对应的关系的集合,通常就称为关系数据库。
二、基本的关系操作
常用的关系操作包括:查询操作和插入、删除、修改操作两大部分。
# 查询操作包括:选择、投影、连接、除、并、差、交、笛卡尔积等(标“_”的为基本操作)。
三、关系数据语言的分类

# 关系数据语言的特点:
语言具有完备的表达能力,是非过程化的集合操作语言,功能强,能够嵌入高级语言中使用。
四、关系的完整性
1、实体完整性
若属性(指一个或一组属性)A是基本关系R的主属性,则A不能取空值。所谓空值就是“不知道”或“不存在”或“无意义”的值。
2、参照完整性
(1)参照关系:
设F是基本关系R的一个或一组属性,但不是关系R的码,K是基本关系S的主码。如果F与K,相对应,则称F是R的外码,并称基本关系R为参照关系,基本关系S为被参照关系或目标关系。关系R和S不一定是不同的关系。

(2)定义:
若属性(或属性组)F是基本关系R的外码,它与基本关系S的主码K,相对应(基本关系R和S不一定是不同的关系),则对于R中每个元组在F上的值必须取空值(F的每个属性值均为空值),或者等于S中某个元组的主码值。
(3)用户定义的完整性
针对某一具体关系数据库的约束条件,它反映某一具体应用所涉及的数据必须满足的语义要求。
五、关系代数
1、运算符
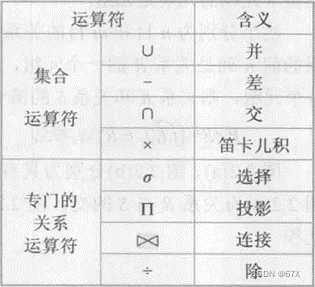
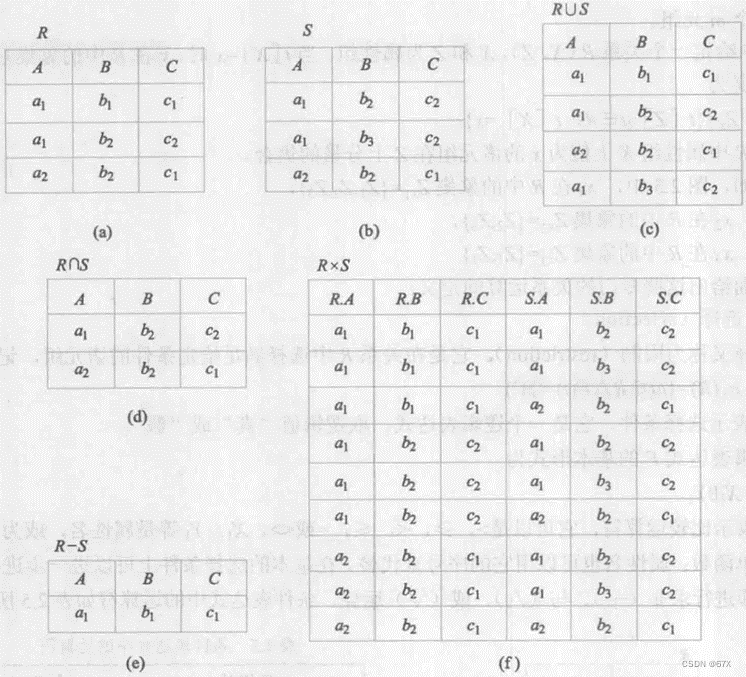
2、传统的集合运算
3、专门的关系运算
(1)选择:
(2)投影:

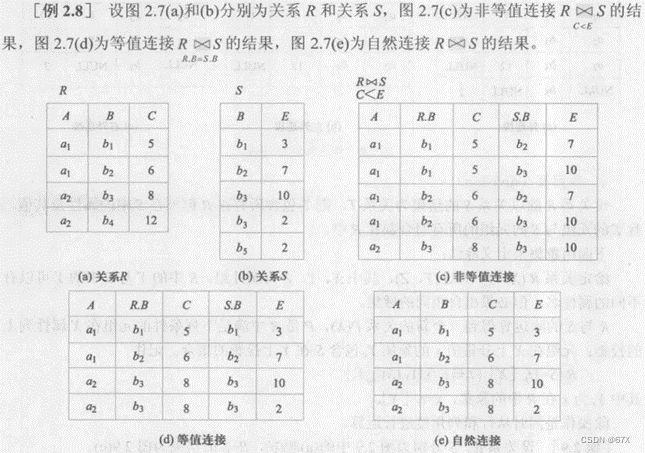
(3)连接:
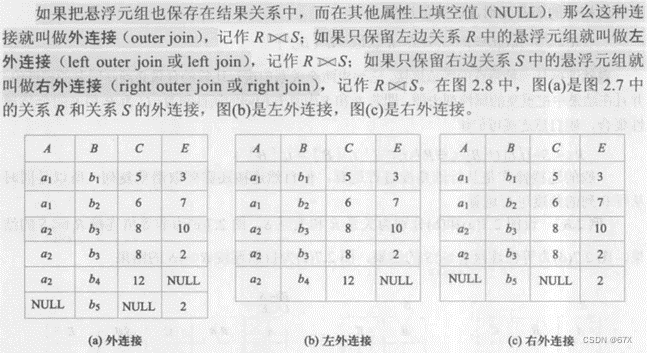
(4)除运算:

4、练习:




第三章 关系数据库标准语言SQL
一、SQL的特点(SQL→结构化查询语言)
- 综合统一。SQL语言集数据定义语言DDL、数据操纵语言DML、数据控制语言DCL的功能于一体;
- 高度非过程化。用SQL语言进行数据操作,只要提出“做什么”,而无需指明“怎么做”,因此无需了解存取路径,存取路径的选择以及SQL语句的操作过程由系统自动完成;
- 面向集合的操作方式。SQL语言采用集合操作方式,不仅操作对象、查找结果可以是元组的集合,而且一次插入、删除、更新操作的对象也可以是元组的集合;
- 以同一种语法结构提供两种使用方式。SQL语言既是自含式语言,又是嵌入式语言。作为自含式语言,它能够独立地用于联机交互的使用方式;作为嵌入式语言,它能够嵌入到高级语言程序中,供程序员设计程序时使用;
- 语言简捷,易学易用。
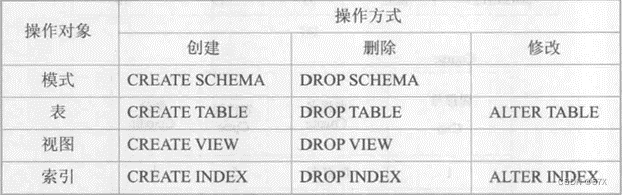
二、数据定义
三、数据查询
1、一般格式
SELECT[ALL | DISTINCT]<目标列表达式>[,<目标列表达式>]…
FROM<表名或视图名>[,<表名或视图名>…]I(<SELECT语句>)[AS]<别名>
[WHERE<条件表达式>]
[GROUP BY<列名1>[HAVING<条件表达式>]]
[ORDER BY<列名2>[ASC|DESC]];
2、常用的查询条件

# 字符匹配:
(1)%(百分号)代表任意长度(长度可以为0)的字符串。例如a%b表示以a开头,以b结尾的任意长度的字符串。如acb、addgb、ab等都满足该匹配串。
(2)_(下横线)代表任意单个字符。例如ab表示以a开头,以b结尾的长度为3的任意字符串。如acb、afb等都满足该匹配串。
3、聚集函数

# 当聚集函数遇到空值时,除COUNT(*)外,都跳过空值而只处理非空值。
# WHERE子句中是不能用聚集函数作为条件表达式的。聚集函数只能用于SELECT子句和GROUP BY中的HAVING子句。

4、连接查询
(1)等值与非等值连接查询:
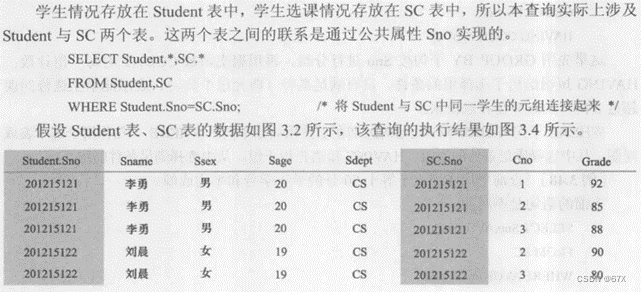
# 关系数据库管理系统执行连接操作的示意图:
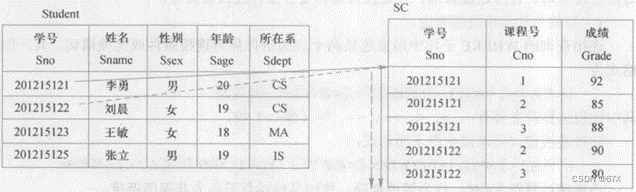

(2)自身连接:

(3)外连接:

(4)多表连接:

5、嵌套查询

# 带有EXISTS谓词的子查询
- 使用存在量词EXISTS后,若内层查询结果非空,则外层的WHERE子句返回真值,否则返回假值。
- 使用存在量词NOT EXISTS后,若内层查询结果为空,则外层的WHERE子句返回真值,否则返回假值。

6、集合查询
SELECT语句的查询结果是元组的集合,所以多个SELECT语句的结果可进行集合操作。集合操作主要包括并操作UNION、交操作INTERSECT和差操作EXCEPT。
# 参加集合操作的各查询结果的列数必须相同;对应项的数据类型也必须相同。
7、基于派生表的查询
子查询不仅可以出现在WHERE子句中,还可以出现在FROM子句中,这时子查询生成的临时派生表成为主查询的查询对象。
8、SELECT语句总结


四、数据更新
1、插入数据
(1)插入元组:

(2)插入子查询结果:
INSERT
INTO<表名>[(<属性列1>[,,<属性列2>…])
子查询;
2、修改数据


3、删除数据


五、空值的处理
1、产生
- 插入数据设为”null”;
- 外连接;
- 空值的关系运算;
2、判断
判断一个属性的值是否为空值,用IS NULL或IS NOT NULL来表示。
3、约束条件
属性定义(或者域定义)中有NOT NULL约束条件的不能取空值,加了UNIQUE限制的属性不能取空值,码属性不能取空值。
4、算术、比较和逻辑运算
空值与另一个值(包括另一个空值)的算术运算的结果为空值,空值与另一个值(包括另一个空值)的比较运算的结果为UNKNOWN。有了UNKNOWN后,传统的逻辑运算中二值(TRUE,FALSE)逻辑就扩展成了三值逻辑。
在查询语句中,只有使WHERE和HAVING子句中的选择条件为TRUE的元组才被选出作为输出结果。
六、视图
1、定义视图
SQL语言用CREATE VIEW命令建立视图,其一般格式为
CREATE VIEW<视图名>[(<列名>[,<列名>])]
AS<子查询>
[WITH CHECK OPTION]:WITH CHECK OPTION表示对视图进行UPDATE、INSERT和DELETE操作时要保证更新、插入或删除的行满足视图定义中的谓词条件(即子查询中的条件表达式)。
# 执行CREATE VIEW语句后只是把视图的定义存入数据字典,不执行其中的SELECT语句。
2、删除视图
该语句的格式为
DROP VIEW<视图名>[CASCADE];视图删除后视图的定义将从数据字典中删除。如果该视图上还导出了其他视图,则使用CASCADE级联删除语句把该视图和由它导出的所有视图一起删除。
基本表删除后,由该基本表导出的所有视图均无法使用了,但是视图的定义没有从字典中清除。删除这些视图定义需要显式地使用DROP VIEW语句。
3、查询视图
视图定义后,用户就可以像对基本表一样对视图进行查询了。
4、更新视图
更新视图是指通过视图来插入、删除和修改数据。
由于视图是不实际存储数据的虚表,因此对视图的更新最终要转换为对基本表的更新。像查询视图那样,对视图的更新操作也是通过视图消解,转换为对基本表的更新操作。
为防止用户通过视图对数据进行增加、删除、修改时,有意无意地对不属于视图范围内的基本表数据进行操作,可在定义视图时加上WITH CHECK OPTION子句。这样在视图上增、删、改数据时,关系数据库管理系统会检查视图定义中的条件,若不满足条件则拒绝执行该操作。
5、视图的作用
- 视图能够简化用户的操作;
- 视图使用户能以多种角度看待同一数据;
- 视图对重构数据库提供了一定程度的逻辑独立性;
- 视图能够对机密数据提供安全保护;
- 适当利用视图可以更清晰地表达查询。
第四章 数据库安全性
一、数据库安全性概述
数据库的安全性是指保护数据库以防止不合法使用所造成的数据泄露、更改或破坏。
二、数据库安全性控制
1、常用方法和技术
- 用户标识和鉴别:该方法由系统提供一定的方式让用户标识自己的名字或身份。每次用户要求进入系统时,由系统进行核对,通过鉴定后才提供系统的使用权。
- 存取控制:通过用户权限定义和合法权检查确保只有合法权限的用户访问数据库,所有未被授权的人员无法存取数据。例如CZ级中的自主存取控制(DAC),BI级中的强制存取控制(MAC).
- 视图机制:为不同的用户定义视图,通过视图机制把要保密的数据对无权存取的用户隐藏起来,从而自动地对数据提供一定程度的安全保护。
- 审计:建立审计日志,把用户对数据库的所有操作自动记录下来放入审计日志中,DBA可以利用审计跟踪的信总,重现导致数据库现有状况的一系列事件,找出非法存取数据的人、时间和内容等。
- 数据加密:对存储和传输的数据进行加密处理,从而使得不知道解密算法的人无法获知数据的内容。
# 数据库中的自主存取控制方法和强制存取控制方法:
- 自主存取控制方法:定义各个用户对不同数据对象的存取权限。当用户对数据库访问时首先检查用户的存取权限。防止不合法用户对数据库的存取。
- 强制存取控制方法:每一个数据对象被(强制地)标以一定的密级,每一个用户也被(强制地)授予某个级别的许可证。系统规定只有具有某一许可证级别的用户才能存取某一个密级的数据对象。
2、授权:授予与收回
(1)GRANT:
GRANT语句的一般格式为
GRANT<权限>[,<权限>]…
ON<对象类型><对象名>[,<对象类型><对象名>]…
TO<用户>[,<用户>]…
[WITH GRANT OPTION];如果指定了WITH GRANT OPTION子句,则获得某种权限的用户还可以把这种权限再授予其他的用户。如果没有指定WITH GRANT OPTION子句,则获得某种权限的用户只能使用该权限,不能传播该权限。
SQL标准允许具有WITH GRANT OPTION的用户把相应权限或其子集传递授予其他用户,但不允许循环授权,即被授权者不能把权限再授回给授权者或其祖先。
(2)REVOKE:
REVOKE语句的一般格式为
REVOKE<权限>[<权限>]…
ON<对象类型><对象名>[,<对象类型><对象名>]…
FROM<用户>[<用户>]…[CASCADE|RESTRICT];3、创建数据库模式的权限
CREATE USER语句一般格式如下:
CREATE USER <username>[WITH][DBA|RESOURCE|CONNECT];# 权限与可执行的操作对照表:

4、数据库角色
(1)角色的创建:
创建角色的SQL语句格式是
CREATE ROLE<角色名>(2)角色授权:
GRANT<权限>[,<权限>]·
ON<对象类型>对象名
T0<角色>[,<角色>]…数据库管理员和用户可以利用GRANT语句将权限授予某一个或几个角色。
(3)将一个角色授予其他的角色或用户:
GRANT<角色1>[,<角色2>]...
T0<角色3>[,<用户1>]…
[WITH ADMIN OPTION]该语句把角色授予某用户,或授予另一个角色。这样,一个角色(例如角色3)所拥有的权限就是授予它的全部角色(例如角色1和角色2)所包含的权限的总和。
授予者或者是角色的创建者,或者拥有在这个角色上的ADMIN OPTION.
如果指定了WITH ADMIN OPTION子句,则获得某种权限的角色或用户还可以把这种权限再授予其他的角色。
一个角色包含的权限包括直接授予这个角色的全部权限加上其他角色授予这个角色的全部权限。
(4)角色权限的收回
REVOKE<权限>[,<权限>]…
ON<对象类型><对象名>
FROM<角色>[<角色>]…用户可以收回角色的权限,从而修改角色拥有的权限。
REVOKE动作的执行者或者是角色的创建者,或者拥有在这个(些)角色上的ADMNOPTION。
5、审计(什么是数据库的审计功能/为什么要提供审计功能)
审计功能是指DBMS的审计模块在用户对数据库执行操作的同时把所有操作自动记录到系统的审计日志中。任何系统的安全保护措施都不是完美无缺的,蓄意盗窃破坏数据的人总可能存在。利用数据库的审计功能,DBA可以根据审计跟踪的信息,重现导致数据库现有状况的一系列事件,找出非法存取数据的人、时间和内容等。
第五章 数据库完整性
一、定义
数据库的完整性是指数据的正确性和相容性。
二、实体完整性
1、定义实体完整性
关系模型的实体完整性在CREATE TABLE中用PRIMARY KEY定义。
2、实体完整性检查和违约处理
- 检查主码值是否唯一,如果不唯一则拒绝插入或修改。
- 检查主码的各个属性是否为空,只要有一个为空就拒绝插入或修改。
三、参照完整性
1、定义参照完整性
关系模型的参照完整性在CREATE TABLE中用FOREIGN KEY短语定义哪些列为外码,用REFERENCES短语指明这些外码参照哪些表的主码。
2、参照完整性检查和违约处理

四、用户定义的完整性
1、属性上的约束条件
在CREATE TABLE中定义属性的同时,可以根据应用要求定义属性上的约束条件,即属性值限制,包括:
- 列值非空(NOT NULL);
- 列值唯一(UNIQUE);
- 检查列值是否满足一个条件表达式(CHECK短语)。
2、属性上约束条件的检查和违约处理
当往表中插入元组或修改属性的值时,关系数据库管理系统将检查属性上的约束条件是否被满足,如果不满足则操作被拒绝执行。
3、元组上的约束条件
与属性上约束条件的定义类似,在CREATE TABLE语句中可以用CHECK短语定义元组上的约束条件,即元组级的限制。同属性值限制相比,元组级的限制可以设置不同属性之间的取值的相互约束条件。
4、元组上约束条件的检查和违约处理
当往表中插入元组或修改属性的值时,关系数据库管理系统将检查元组上的约束条件是否被满足,如果不满足则操作被拒绝执行。
五、完整性约束命名子句
1、完整性约束命名子句
CONSTRAINT<完整性约束条件名><完整性约束条件><完整性约束条件>包括NOT NULL、UNIQUE、PRIMARY KEY、FOREIGN KEY、CHECK短语等。
2、修改表中的完整性限制
可以使用ALTER TABLE语句修改表中的完整性限制。
六、断言
1、创建断言的语句格式
CREATE ASSERTION<断言名><CHECK子句>每个断言都被赋予一个名字,<CHECK子句>中的约束条件与WHERE子句的条件表达式类似。断言创建以后,任何对断言中所涉及关系的操作都会触发关系数据库管理系统对断言的检查,任何使断言不为真值的操作都会被拒绝执行。
2、删除断言的语句格式
DROP ASSERTION<断言名>;七、触发器
触发器是用户定义在关系表上的一类由事件驱动的特殊过程。
1、定义触发器
触发器又叫做事件-条件-动作(event-condition-.action)规则。当特定的系统事件(如对一个表的增、删、改操作,事务的结束等)发生时,对规则的条件进行检查,如果条件成立则执行规则中的动作,否则不执行该动作。规则中的动作体可以很复杂,可以涉及其他表和其他数据库对象,通常是一段SQL存储过程。
CREATE TRIGGER<触发器名>
/*每当触发事件发生时,该触发器被激活*/
(BEFORE|AFTER}<触发事件>ON<表名>
/*指明触发器激活的时间是在执行触发事件前或后*/
REFERENCING NEWJOLD ROW AS<变量>
/*REFERENCING指出引用的变量*/
FOR EACH(ROW STATEMENT)
/*体定义触发器的类型,指明动作体执行的频率*/
WHEN<触发条件>]<触发动作体>
/*仅当触发条件为真时才执行触发动作体*/# 详细说明:
- 只有表的拥有者,即创建表的用户才可以在表上创建触发器,并且一个表上只能创建一定数量的触发器。触发器的具体数量由具体的关系数据库管理系统在设计时确定。
- 触发器名可以包含模式名,也可以不包含模式名。同一模式下,触发器名必须是唯的,并且触发器名和表名必须在同一模式下。
- 触发器只能定义在基本表上,不能定义在视图上。当基本表的数据发生变化时,将激活定义在该表上相应触发事件的触发器,因此该表也称为触发器的目标表。
- 触发事件可以是NSERT、DELETE或UPDATE,也可以是这几个事件的组合,如INSERT OR DELETE等,还可以是UPDATE OF<触发列,>,即进一步指明修改哪些列时激活触发器。AFTER/BEFORE是触发的时机。AFTER表示在触发事件的操作执行之后激活触发器;BEFORE表示在触发事件的操作执行之前激活触发器。
- 触发器按照所触发动作的间隔尺寸可以分为行级触发器(FOR EACH ROW)和语句级触发器(FOR EACH STATEMENT)。
- 触发器被激活时,只有当触发条件为真时触发动作体才执行,否则触发动作体不执行。如果省略WHEN触发条件,则触发动作体在触发器激活后立即执行。
- 触发动作体既可以是一个匿名PL/SQL过程块,也可以是对已创建存储过程的调用。如果是行级触发器,用户可以在过程体中使用NEW和OLD引用UPDATE/NSERT事件之后的新值和UPDATE/DELETE事件之前的旧值;如果是语句级触发器,则不能在触发动作体中使用NEW或OLD进行引用。如果触发动作体执行失败,激活触发器的事件(即对数据库的增、删、改操作)就会终止执行,触发器的目标表或触发器可能影响的其他对象不发生任何变化。
2、激活触发器
触发器的执行是由触发事件激活,并由数据库服务器自动执行的。一个数据表上可能定义了多个触发器,如多个BEFORE触发器、多个AFTER触发器等,同一个表上的多个触发器激活时遵循如下的执行顺序:
- 执行该表上的BEFORE触发器
- 激活触发器的SQL语句。
- 执行该表上的AFTER触发器。
对于同一个表上的多个BEFORE(AFTER)触发器,遵循“谁先创建谁先执行”的原则,即按照触发器创建的时间先后顺序执行。有些关系数据库管理系统是按照触发器名称的字母排序顺序执行触发器。
3、删除触发器
删除触发器的SQL语法如下:
DROP TRIGGER<触发器名>ON<表名>;触发器必须是一个已经创建的触发器,并且只能由具有相应权限的用户删除。
第六章 关系数据理论——规范化
一、函数依赖
设R(U)是属性集U上的关系模式,X、Y是U的子集。若对于R(U)的任意一个可能的关系r,r中不可能存在两个元组在X上的属性值相等,而在Y上的属性值不等,则称X函数确定Y或Y函数依赖于X,记作X→Y。其中,若有X→Y,但Y不包含于X,则称非平凡的函数依赖;若有X→Y,但Y包含于X,则称平凡的函数依赖;若有X→Y,Y→X,则记作X← →Y。
# 完全函数依赖与部分函数依赖

二、码

三、范式

- 1NF:所有字段值都是不可分解的原子值。
- 2NF:不包含非主属性对码的部分函数依赖,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。
- 3NF:不包含非主属性对码的传递函数依赖,确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
- BCNF:消除每一属性对候选键的传递依赖,BCNF是修正的第三范式。

四、候选码
1、概念
如果关系中的某一属性组的值能唯一标识一个元组,而其子集不能,则成为该属性组为候选码(可以推出所有属性)。
2、候选码的筛选步骤
- 只出现在左边的一定是候选码;
- 只出现在右边的一定不是候选码;
- 左右都出现的不一定是候选码;
- 左右都不出现的一定是候选码;
- 再求确定的候选码的闭包,如果可以推出全部,那么当前确定的就是候选码,否则要把每一个可能的值放进当前确定的候选码里面进行求闭包
3、示例
R<U,F>,U(A,B,C,D,E,G),F = { AB→C,CD→E,E→A,A→G ),求候选码:
- B和D一定是候选码;
- G一定不是候选码;
- A、C和E不一定是候选码;
- BD推不出任何内容,因此所以要把每一个可能的求闭包:
- (BDA)+ 可推出CEG,所以可以推出ABCDEG;
- (BDC)+ 可推出EAG,所以可以推出ABCDEG;
- (BDE)+ 可推出AGC,所以可以推出ABCDEG;
- 则候选码最终是{(BDA),(BDC),(BDE)};
# 补充:
- 超码:能表示出所有属性的集合;
- 候选码:最小的超码;
- 主码:从候选码里面任意挑出一个作为主码;
- 主属性:包含在所有候选码的属性,如ABCDE;
- 非主属性:不包含在候选码中的属性,如G;
- 全码:所有的属性都是主码;
五、最小依赖集

# 如何求最小依赖集?
- 拆开右边为多个元素的。比如A→BC拆为A→B和A→C;
- 除去当前元素,求它的闭包,把集合里面所有元素都弄完;
- 左边最小化(通过遮住元素来看能不能推出其他元素),比如BCD,遮住B能否推出CD;遮住C能否推出BD;遮住D能否推出BC。
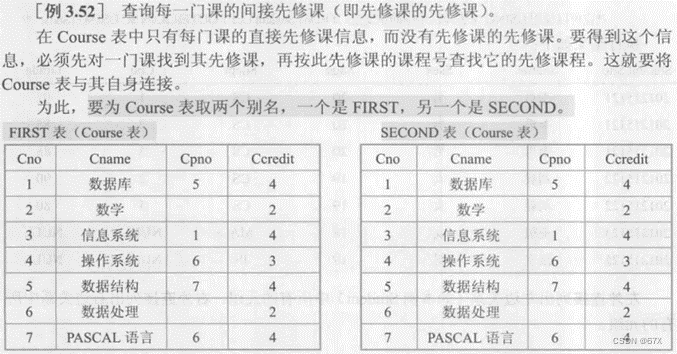
第七章 数据库设计
一、数据库设计的基本步骤
1、需求分析
进行数据库设计首先必须准确了解与分析用户需求(包括数据与处理)。
2、概念结构设计
概念结构设计是整个数据库设计的关键,它通过对用户需求进行综合、归纳与抽象,形成一个独立于具体数据库管理系统的概念模型。
3、逻辑结构设计
逻辑结构设计是将概念结构转换为某个数据库管理系统所支持的数据模型,并对其进行优化。
4、物理结构设计
物理结构设计是为逻辑数据模型选取一个最适合应用环境的物理结构(包括存储结构和存取方法)。
5、数据库实施
在数据库实施阶段,设计人员运用数据库管理系统提供的数据库语言及其宿主语言,根据逻辑设计和物理设计的结果建立数据库,编写与调试应用程序,组织数据入库,并进行试运行。
6、数据库运行和维护
数据库应用系统经过试运行后即可投入正式运行。在数据库系统运行过程中必须不断地对其进行评估、调整与修改。
二、数据库设计过程中的各级模式
三、E-R模型
1、三类联系
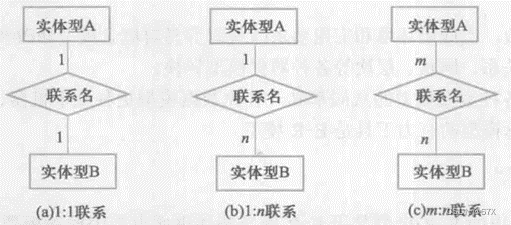
# E-R图向关系模型的转换:
(1)1:1联系:把关系合并到任意一个表,并且把其他表里面的主键放到另一个里面;
(2)1:n联系:把A的主码放到B里面,然后把关系的属性放到B里面;
(3)m:n联系:需要两边实体的主键和自身的属性单独作为一个关系模式。
2、E-R图
E-R图提供了表示实体型、属性和联系的方法。
- 实体型用矩形表示,矩形框内写明实体名。
- 属性用椭圆形表示,并用无向边将其与相应的实体型连接起来。
- 联系用菱形表示,菱形框内写明联系名,并用无向边分别与有关实体型连接起来,同时在无向边旁标上联系的类型(1:1、1:n或m:n).
# 如果一个联系具有属性,则这些属性也要用无向边与该联系连接起来。
3、示例:

![]()
解:
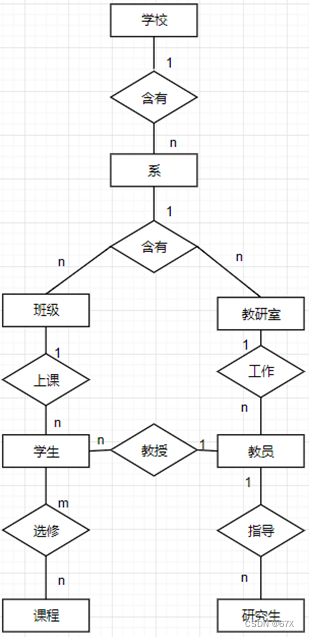
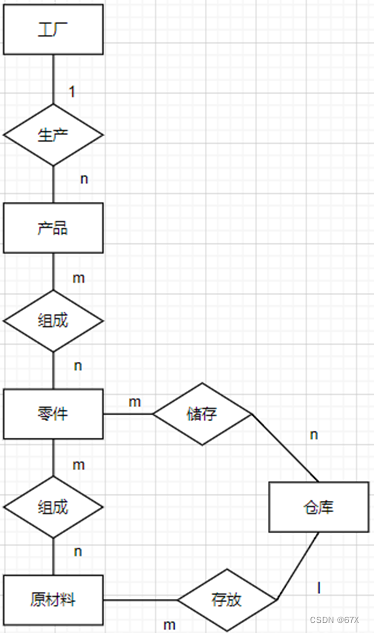
系(系编号,系名,学校名) 产品(产品号,产品名,工厂名)
班级(班级号,班级人数,系编号) 零件(零件号,零件名,供应厂商)
教研室(教研室号,教研室人数,系编号) 原材料(原材料号,原材料名,类别,供应商)
学生(学号,姓名,班级号,教员编号) 仓库(仓库号,仓库名,仓库位置)
教员(教员编号,姓名,职位,教研室号) 产品组成(产品号,零件号,零件用量)
课程(课程号,课程名,学分) 零件组成(零件号,原材料号,原材料用量)
研究生(研究生号,姓名,教员编号) 零件储存(零件号,仓库号,储存量)
选修(学号,课程号,成绩) 原材料存放(原材料类别,仓库号,存放量)
第十章 数据库恢复技术
一、事务的基本概念
1、事务
所谓事务是用户定义的一个数据库操作序列,这些操作要么全做,要么全不做,是一个不可分割的工作单位。
COMMIT表示提交事务的所有操作,ROLLBACK表示回滚撤销事务对数据库的所有已完成的操作。
2、事务的ACID特性
- 原子性(Atomicity);
- 一致性(Consistency);
- 隔离性(Isolation);
- 持续性(Durability)。
二、故障的种类
- 事务内部的故障;
- 系统故障;
- 介质故障;
- 计算机病毒;
三、恢复的实现技术
恢复的基本原理:冗余。
- 数据转储;
- 登记日志文件;
四、恢复策略
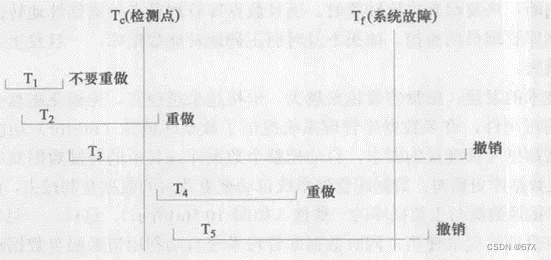
1、事务故障恢复
- 反向扫描日志文件(即从最后向前扫描日志文件),查找该事务的更新操作;
- 对该事务的更新操作执行逆操作,即将日志记录中“更新前的值”写入数据库。这样,如果记录中是插入操作,则相当于做删除操作(因此时“更新前的值”为空):若记录中是删除操作,则做插入操作;若是修改操作,则相当于用修改前值代替修改后值;
- 继续反向扫描日志文件,查找该事务的其他更新操作,并做同样处理;
- 如此处理下去,直至读到此事务的开始标记,事务故障恢复就完成了。
2、系统故障恢复
- 正向扫描日志文件(即从头扫描日志文件),找出在故障发生前已经提交的事务(这些事务既有BEGIN TRANSACTION记录,也有COMMIT记录),将其事务标识记入重做队列(REDO-LIST)。同时找出故障发生时尚未完成的事务(这些事务只有BEGN TRANSACTION记录,无相应的COMMIT记录),将其事务标识记入撤销队列(UNDO-LIST).
- 对撤销队列中的各个事务进行撤销(UNDO)处理。进行撤销处理的方法是,反向扫描日志文件,对每个撒销事务的更新操作执行逆操作,即将日志记录中“更新前的值”写入数据库。
- 对重做队列中的各个事务进行重做处理。进行重做处理的方法是:正向扫描日志文件,对每个重做事务重新执行日志文件登记的操作,即将日志记录中“更新后的值”写入数据库。
3、介质故障的恢复
- 装入最新的数据库后备副本(离故障发生时刻最近的转储副本),使数据库恢复到最近一次转储时的一致性状态。对于动态转储的数据库副本,还需同时装入转储开始时刻的日志文件副本,利用恢复系统故障的方法(即REDO+UNDO),才能将数据库恢复到一致性状态。
- 装入相应的目志文件副本(转储结束时刻的日志文件副本),重做已完成的事务。即首先扫描日志文件,找出故障发生时已提交的事务的标识,将其记入重做队列;然后正向扫描日志文件,对重做队列中的所有事务进行重做处理。即将日志记录中“更新后的值”写入数据库。
五、具有检查点的恢复技术

第十一章 并发技术
一、并发控制
- 1、事务是并发控制的基本单位。
- 2、并发操作带来的数据不一致性问题:

二、封锁(解决并发操作带来的数据不一致性问题)
- 排他锁又称为写锁。若事务T对数据对象A加上X锁,则只允许T读取和修改A,其他任何事务都不能再对A加任何类型的锁,直到T释放A上的锁为止。这就保证了其他事务在T释放A上的锁之前不能再读取和修改A。
- 共享锁又称为读锁。若事务T对数据对象A加上S锁,则事务T可以读A但不能修改A,其他事务只能再对A加S锁,而不能加X锁,直到T释放A上的S锁为止。这就保证了其他事务可以读A,但在T释放A上的S锁之前不能对A做任何修改。

三、封锁协议
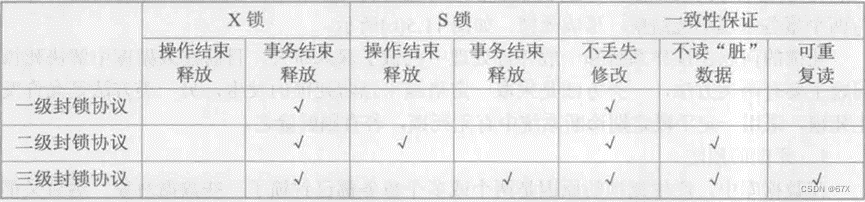

四、活锁(封锁技术带来的新问题)

避免活锁的简单方法是采用先来先服务的策略。当多个事务请求封锁同一数据对象时,封锁子系统按请求封锁的先后次序对事务排队,数据对象上的锁一旦释放就批准申请队列中第一个事务获得锁。
五、死锁(封锁技术带来的新问题)
T1在等待T2,而T2又在等待T的局面,T1和T2两个事务永远不能结束,形成死锁。
1、死锁的预防
- 一次封锁法;
- 顺序封锁法;
2、死锁的诊断与解除
- 超时法;
- 等待图法;
六、并发调度的可串行性
1、可串行化调度
多个事务的并发执行是正确的,当且仅当其结果与按某一次序串行地执行这些事务时的结果相同,称这种调度策略为可串行化调度
可串行性是并发事务正确调度的准则。按这个准则规定,一个给定的并发调度,当且仅当它是可串行化的,才认为是正确调度。
2、冲突可串行化调度
冲突操作是指不同的事务对同一个数据的读写操作和写写操作。
一个调度Sc在保证冲突操作的次序不变的情况下,通过交换两个事务不冲突操作的次序得到另一个调度Sc',如果Sc'是串行的,称调度Sc为冲突可串行化的调度。若一个调度是冲突可串行化,则一定是可串行化的调度。因此可以用这种方法来判断一个调度是否是冲突可串行化的。
冲突可串行化调度是可串行化调度的充分条件,不是必要条件。
七、封锁的粒度
封锁对象的大小称为封锁粒度。
封锁粒度与系统的并发度和并发控制的开销密切相关。直观地看,封锁的粒度越大,数据库所能够封锁的数据单元就越少,并发度就越小,系统开销也越小;反之,封锁的粒度越小,并发度较高,但系统开销也就越大。