ELK的日志解决方案
ELK是什么
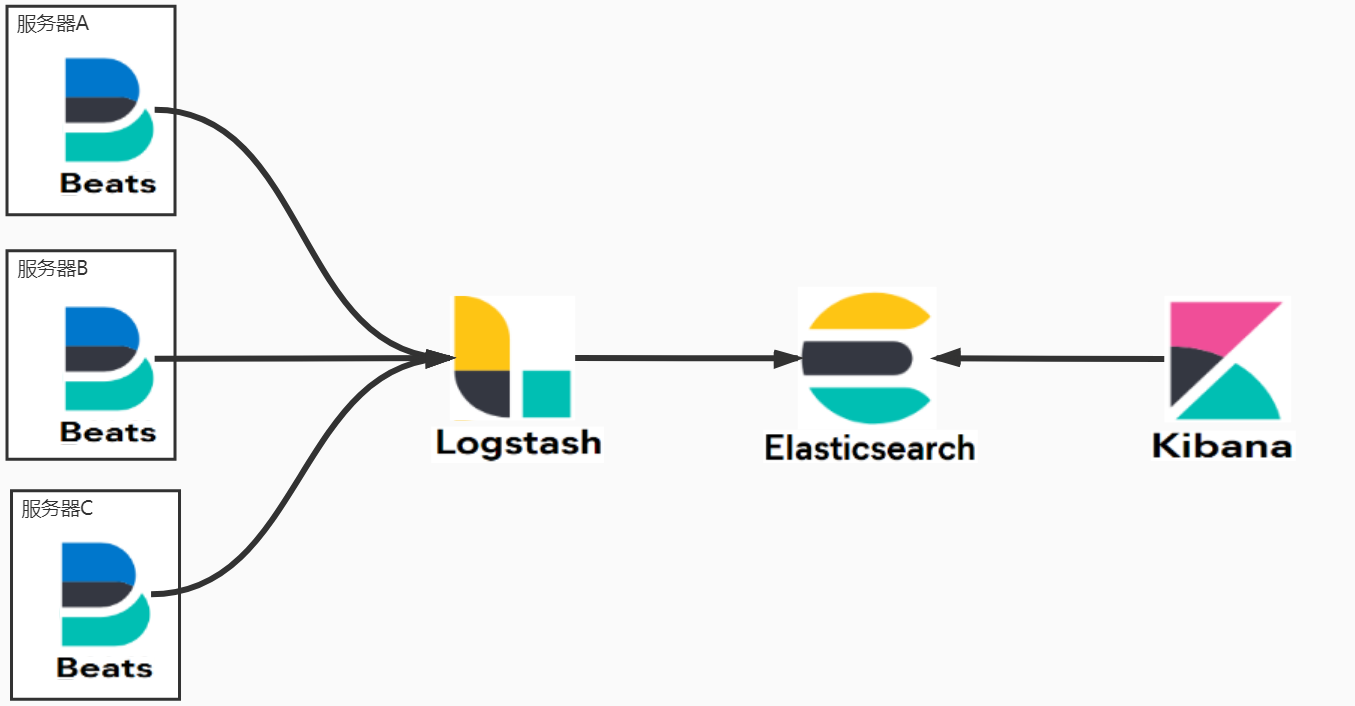
ELK 是一个缩写,代表 Elastic Stack,而不是三个独立的产品名称。Elastic Stack 是一个开源的数据处理和分析平台,用于实时搜索、分析和可视化大规模数据。ELK 是由三个主要的组件构成:
- Elasticsearch (ES): 一个分布式搜索引擎,用于实时存储和检索数据。它提供了强大的全文搜索能力和分布式性能,常用于存储和查询大规模的日志数据、指标数据等。
- Logstash (LS): 一个用于数据收集、过滤和转发的工具。Logstash 可以从各种来源(如日志文件、消息队列、数据库等)采集数据,然后进行处理和转换,最终将数据发送到 Elasticsearch 等目的地。
- Kibana (K): 一个用于数据可视化和仪表板创建的工具。Kibana 提供了一个直观的 Web 界面,使用户能够以图形化的方式探索、分析和可视化 Elasticsearch 中的数据。
这三个组件协同工作,形成了一个强大的数据处理和分析平台,被广泛用于日志分析、监控、安全分析等场景。Elastic Stack 还支持插件和扩展,使其能够与其他数据存储和处理工具集成,以满足各种复杂的需求。
ELK的优点
随着我们系统架构的不断升级,由单体转为分布式、微服务、网格系统等,用户访问产生的日志量也在不断增加,我们急需一个可以快速、准确查询和分析日志的平台。
- 实时搜索和分析: Elasticsearch 提供了强大的实时搜索和分析功能。它能够快速存储和检索大量的数据,使用户能够以实时方式探索和分析数据。
- 日志集中管理: Logstash 可以从多个来源(日志文件、消息队列、数据库等)集中收集、处理和转发数据,使日志管理变得更加集中和方便。
- 灵活的数据处理: Logstash 具有强大的数据处理能力,可以对收集到的数据进行过滤、转换和格式化,以适应特定的需求。这使得可以对原始数据进行预处理,以提高后续分析的效率。
- 直观的数据可视化: Kibana 提供了直观的 Web 界面,使用户能够轻松地创建仪表板、图表和可视化工具,以便更好地理解数据和趋势。
- 可扩展性: ELK Stack 是开源的,并且具有丰富的插件生态系统,可以扩展其功能以满足不同的需求。用户可以根据具体情况选择合适的插件或定制自己的解决方案。
- 广泛的应用场景: ELK Stack 被广泛应用于日志分析、系统监控、应用性能分析、安全信息和事件管理等领域。它提供了一个全面的解决方案,适用于各种复杂的数据处理和分析任务。
如何搭建ELK
本次使用docker来搭建ELK
1.搭建Elasticsearch
拉取镜像
docker pull elasticsearch:7.17.7
配置文件
创建三个空的文件夹
/usr/local/software/elk/elasticsearch/conf
/usr/local/software/elk/elasticsearch/data
/usr/local/software/elk/elasticsearch/plugins
[root@localhost elasticsearch]# tree
.
├── conf
├── data
└── plugins
3 directories, 0 files
在conf下创建elasticsearch.yml,修改权限777
[root@localhost conf]# touch elasticsearch.yml
[root@localhost conf]# chmod 777 elasticsearch.yml
[root@localhost conf]# ll
总用量 0
-rwxrwxrwx. 1 root root 0 12月 5 11:03 elasticsearch.yml
修改内容为
http:
host: 0.0.0.0
cors:
enabled: true
allow-origin: "*"
xpack:
security:
enabled: false
修改linux的vm.max_map_count
[root@localhost conf]# sysctl -w vm.max_map_count=262144
vm.max_map_count = 262144
[root@localhost conf]# sysctl -a|grep vm.max_map_count
sysctl: reading key "net.ipv6.conf.all.stable_secret"
sysctl: reading key "net.ipv6.conf.br-77cea35f59fa.stable_secret"
sysctl: reading key "net.ipv6.conf.default.stable_secret"
sysctl: reading key "net.ipv6.conf.docker0.stable_secret"
sysctl: reading key "net.ipv6.conf.enp4s0.stable_secret"
sysctl: reading key "net.ipv6.conf.lo.stable_secret"
sysctl: reading key "net.ipv6.conf.veth15fadfa.stable_secret"
sysctl: reading key "net.ipv6.conf.virbr0.stable_secret"
sysctl: reading key "net.ipv6.conf.virbr0-nic.stable_secret"
vm.max_map_count = 262144
创建运行容器
docker run -itd \
--name es \
--privileged \
--network wn_docker_net \
--ip 172.18.12.60 \
-p 9200:9200 \
-p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms4g -Xmx4g" \
-v /usr/local/software/elk/elasticsearch/conf/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /usr/local/software/elk/elasticsearch/data:/usr/share/elasticsearch/data \
-v /usr/local/software/elk/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
elasticsearch:7.17.7
此时可能会报异常
修改elasticsearch文件夹下的权限
[root@localhost elk]# pwd
/usr/local/software/elk
[root@localhost elk]# chmod 777 elasticsearch/**
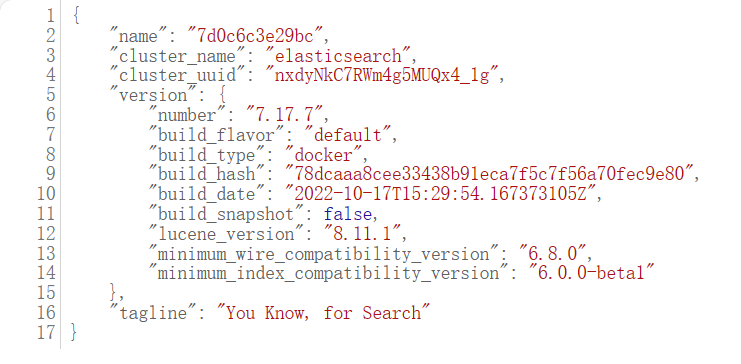
重启容器后浏览器输入192.168.100.128:9200(ip为你的虚拟机地址),看到这串json就是成功了
2.搭建Kibana
拉取镜像
docker pull kibana:7.17.7
创建运行容器
-e中HOSTS的值为刚才在浏览器中获取json的地址
docker run -it \
--name kibana \
--privileged \
--network wn_docker_net \
--ip 172.18.12.71 \
-e "ELASTICSEARCH_HOSTS=http://192.168.100.128:9200" \
-p 5601:5601 \
-d kibana:7.17.7
浏览器访问192.168.100.128:5601
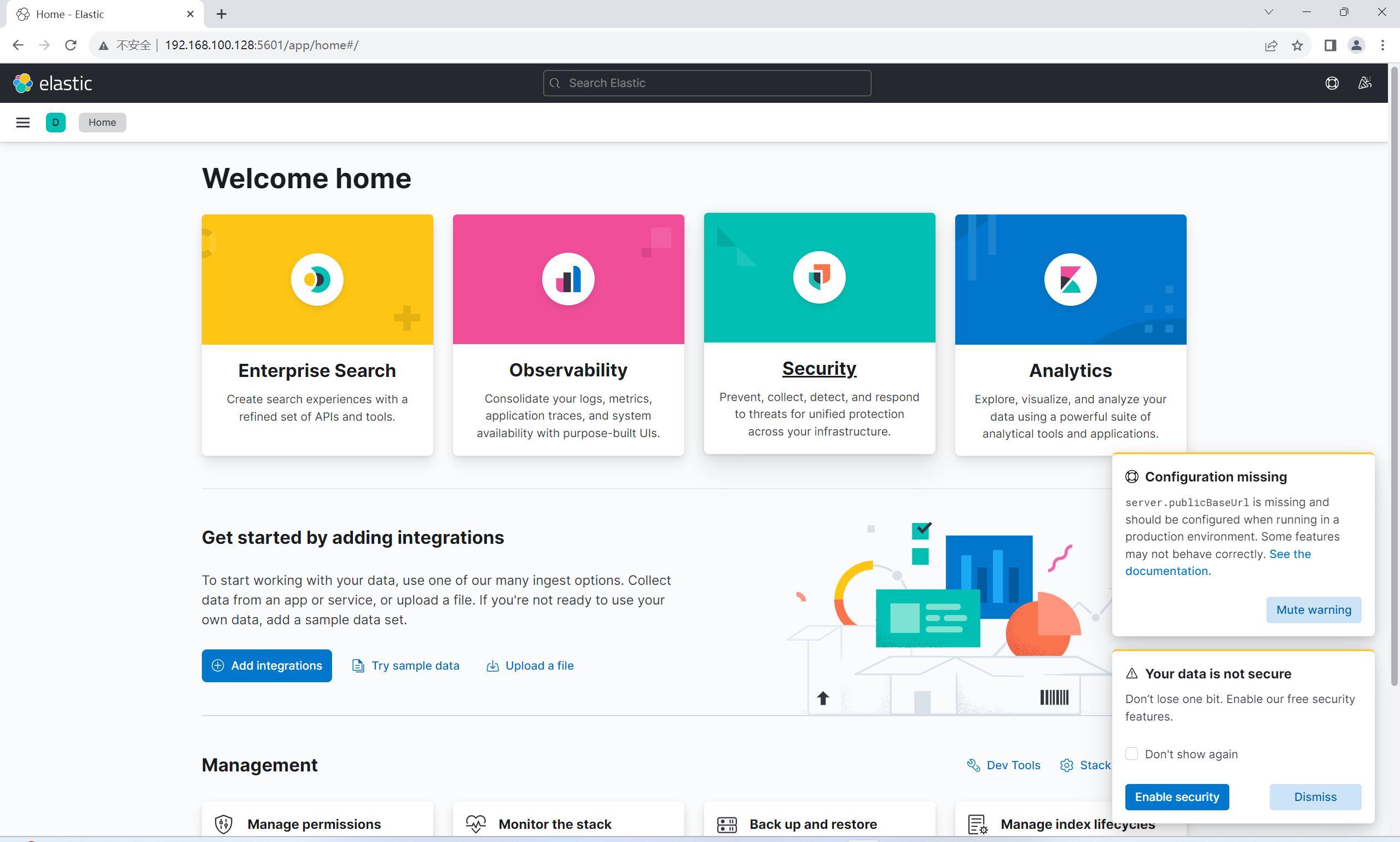
看到这个界面即为成功
ES的分词器
访问7.17.7 · Releases · medcl/elasticsearch-analysis-ik (github.com)下载分词器
上传分词器到linux

进入容器
创建一个文件夹ik
:/usr/share/elasticsearch/plugins/ik
拷贝分词器到容器中ik文件夹
[root@localhost plugins]# docker cp elasticsearch-analysis-ik-7.17.7.zip es:/usr/share/elasticsearch/plugins/ik
进入容器解压分词器
unzip elasticsearch-analysis-ik-7.17.7.zip
重启容器
docker restart es
kibana查看
点击侧边栏
GET _analyze
{
"analyzer": "ik_smart"
, "text": "我是中国人,中国会富强"
}
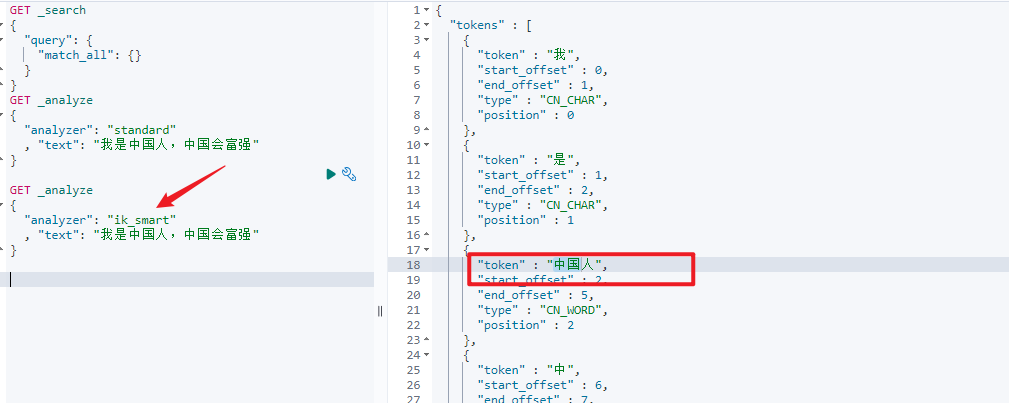
自定义分词器
进入容器的ik/config文件
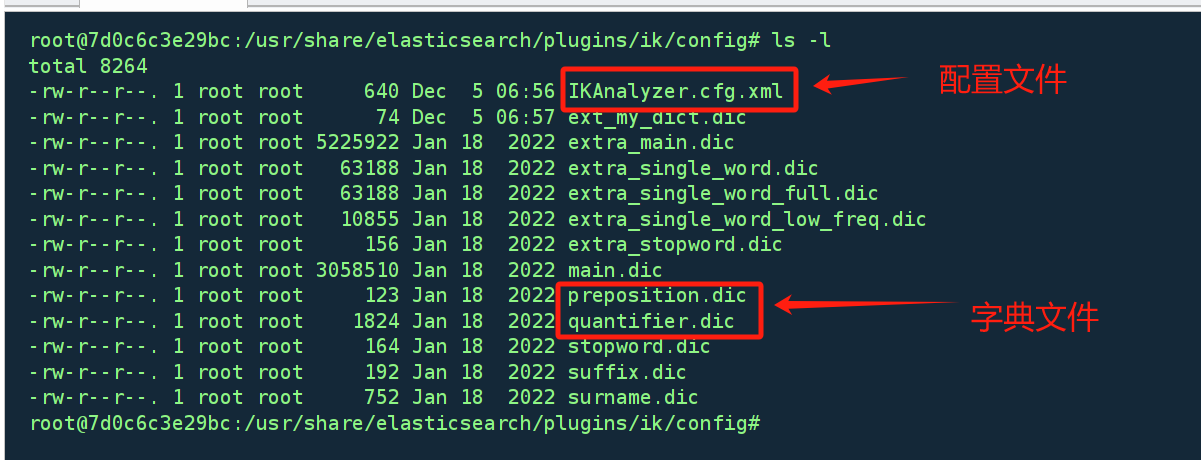
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict"></entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
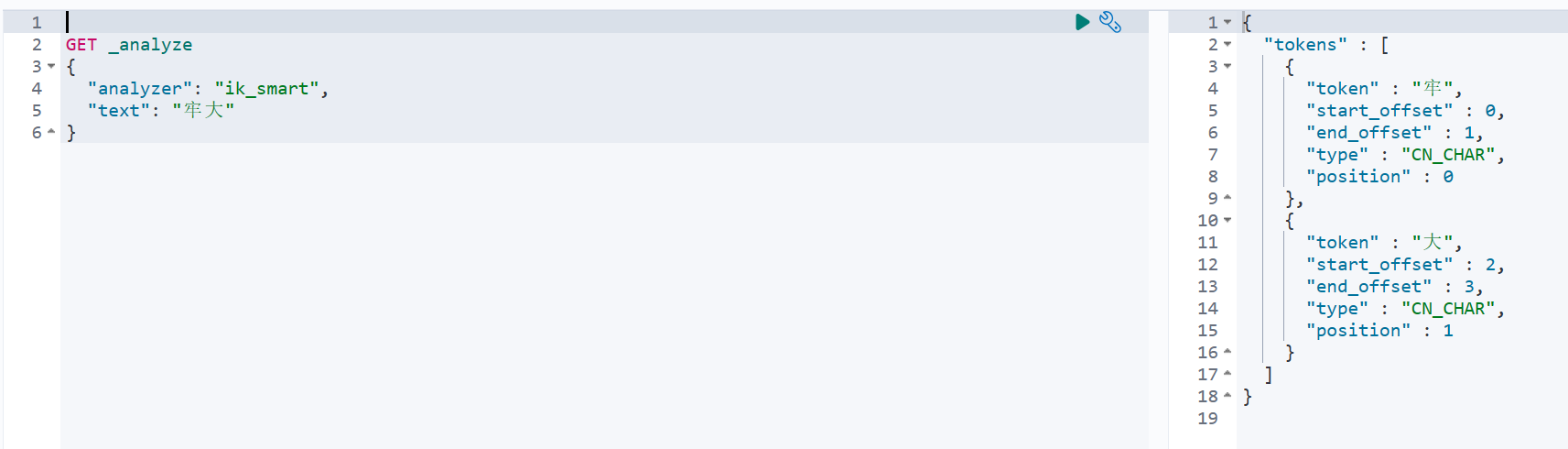
创建一个自己的分词文件ext_dict.dic
牢大
3.搭建Logstash
拉取镜像
[root@localhost ~]# docker pull logstash:7.17.7
创建运行容器
docker run -it \
--name logstash \
--privileged \
-p 5044:5044 \
-p 9600:9600 \
--network wn_docker_net \
--ip 172.18.12.72 \
-v /etc/localtime:/etc/localtime \
-d logstash:7.17.7
容器配置
创建三个文件
logstash.yml
path.logs: /usr/share/logstash/logs
config.test_and_exit: false
config.reload.automatic: false
http.host: "0.0.0.0"
xpack.monitoring.elasticsearch.hosts: [ "http://192.168.100.128:9200" ]
piplelines.xml
- pipeline.id: main
path.config: "/usr/share/logstash/pipeline/logstash.conf"
logstash.conf
input {
tcp {
mode => "server"
host => "0.0.0.0"
port => 5044
codec => json_lines
}
}
filter{
}
output {
elasticsearch {
hosts => ["192.168.100.128:9200"] #elasticsearch的ip地址
index => "ssc-logs" #索引名称
}
stdout { codec => rubydebug }
}
将这三个文件拷贝到容器中
[root@woniu logstash]# docker cp logstash.yml logstash:/usr/share/logstash/config
[root@woniu logstash]# docker cp pipelines.yml logstash:/usr/share/logstash/config/
[root@woniu logstash]# docker cp logstash.conf logstash:/usr/share/logstash/pipeline
重启容器
[root@woniu logstash]# docker restart logstash
1
访问192.168.100.128:9600(你自己的虚拟机ip:9600),出现如下页面表示成功
Spring Boot整合ELK
引入依赖(ES和Logback)
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>7.3</version>
</dependency>
application.yml配置
spring:
elasticsearch:
uris: http://192.168.100.128:9200
data:
elasticsearch:
repositories:
enabled: true
Logstash的配置
<?xml version="1.0" encoding="UTF-8"?>
<!-- 日志级别从低到高分为TRACE < DEBUG < INFO < WARN < ERROR < FATAL,如果设置为WARN,则低于WARN的信息都不会输出 -->
<!-- scan:当此属性设置为true时,配置文档如果发生改变,将会被重新加载,默认值为true -->
<!-- scanPeriod:设置监测配置文档是否有修改的时间间隔,如果没有给出时间单位,默认单位是毫秒。
当scan为true时,此属性生效。默认的时间间隔为1分钟。 -->
<!-- debug:当此属性设置为true时,将打印出logback内部日志信息,实时查看logback运行状态。默认值为false。 -->
<configuration scan="true" scanPeriod="10 seconds">
<!--1. 输出到控制台-->
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<!--此日志appender是为开发使用,只配置最低级别,控制台输出的日志级别是大于或等于此级别的日志信息-->
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>DEBUG</level>
</filter>
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} -%5level ---[%15.15thread] %-40.40logger{39} : %msg%n</pattern>
<!-- 设置字符集 -->
<charset>UTF-8</charset>
</encoder>
</appender>
<!-- 2. 输出到文件 -->
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!--日志文档输出格式-->
<append>true</append>
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} -%5level ---[%15.15thread] %-40.40logger{39} : %msg%n</pattern>
<charset>UTF-8</charset> <!-- 此处设置字符集 -->
</encoder>
</appender>
<!--LOGSTASH config -->
<appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<destination>192.168.100.128:5044</destination>
<encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder">
<!--自定义时间戳格式, 默认是yyyy-MM-dd'T'HH:mm:ss.SSS<-->
<timestampPattern>yyyy-MM-dd HH:mm:ss</timestampPattern>
<customFields>{"appname":"App"}</customFields>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="CONSOLE"/>
<appender-ref ref="FILE"/>
<appender-ref ref="LOGSTASH"/>
</root>
</configuration>
ES实体类
@Data
@NoArgsConstructor
@AllArgsConstructor
@Document(indexName = "book_index",createIndex = true)
public class BookDoc {
@Id
@Field(type = FieldType.Long)
private Long id;
@Field(type = FieldType.Text)
private String title;
private String isbn;
@Field(type = FieldType.Text)
private String introduction;
@Field(type = FieldType.Keyword)
private String author;
@Field(type = FieldType.Double)
private BigDecimal price;
@Field(type = FieldType.Date,format = DateFormat.year_month_day)
private LocalDate createTime;
}
dao接口
@Repository
public interface IBookDocDao extends ElasticsearchRepository<BookDoc, Long> {
List<BookDoc> findBookDocByAuthorAndTitleAndIntroduction(String author, String title, String introduction);
}
service
@Service
public class BookDocServiceImpl implements IBookDocService {
@Autowired
private IBookService bookService;
@Autowired
private IBookDocDao bookDocDao;
@Override
public void loadFromDb() {
List<Book> bookList = bookService.findAll();
for (Book book : bookList) {
BookDoc bookDoc = new BookDoc();
bookDoc.setId(book.getId());
bookDoc.setTitle(book.getTitle());
bookDoc.setAuthor(book.getAuthor());
bookDoc.setIntroduction(book.getIntroduction());
bookDoc.setIsbn(book.getIsbn());
Date createTime = book.getCreateTime();
Instant instant = createTime.toInstant();
LocalDate localDate = instant.atZone(ZoneId.systemDefault()).toLocalDate();
bookDoc.setCreateTime(localDate);
bookDocDao.save(bookDoc);
}
System.out.println("数据导入ES成功....");
}
@Override
public List<BookDoc> findAll() {
Iterable<BookDoc> all = bookDocDao.findAll();
List<BookDoc> collect = StreamSupport.stream(all.spliterator(), false).collect(Collectors.toList());
return collect;
}
@Override
public List<BookDoc> findBookDocByAuthorAndTitleAndIntroduction(String author, String title, String introduction) {
Iterable<BookDoc> all = bookDocDao.findBookDocByAuthorAndTitleAndIntroduction(author, title, introduction);
List<BookDoc> collect = StreamSupport.stream(all.spliterator(), false).collect(Collectors.toList());
return collect;
}
}
controller
先使用findAll把数据写入Elasticserch,然后就可以用Logstash条件查询了
@Slf4j
@RestController
@RequestMapping("/api/query")
public class QueryController {
@Autowired
private IBookDocService ibs;
@GetMapping("/helloLog")
public HttpResp helloLog() {
List<BookDoc> all = ibs.findAll();
log.debug("从es查询到的数据:{}", all);
log.debug("我是来测试logstash是否工作的");
return HttpResp.success(all.subList(0, 100));
}
@GetMapping("/searchBook")
public HttpResp searchBook(String author, String title, String introduction) {
List<BookDoc> all = ibs.findBookDocByAuthorAndTitleAndIntroduction(author, title, introduction);
log.debug("从es查询到的数据:{}", all);
log.debug("我是来测试logstash是否工作的");
return HttpResp.success(all.subList(0, 100));
}
}