大数据可视化项目——基于Python豆瓣电影数据可视化分析系统的设计与实现
本项目旨在通过对豆瓣电影数据进行综合分析与可视化展示,构建一个基于Python的大数据可视化系统。通过数据爬取收集、清洗、分析豆瓣电影数据,我们提供了一个全面的电影信息平台,为用户提供深入了解电影产业趋势、影片评价与演员表现的工具。项目的关键步骤包括数据采集、数据清洗、数据分析与可视化展示。首先,我们使用爬虫技术从豆瓣电影网站获取丰富的电影数据,包括电影基本信息、评分、评论等存储到Mysql数据库。然后,通过数据清洗与预处理,确保数据的质量与一致性,以提高后续分析的准确性。数据分析阶段主要包括对电影评分分布、不同类型电影的数量分布、评分、演员的影响力等方面的深入研究。基于Echarts进行可视化展示,借助Python中的数据分析库(如Pandas、NumPy)和可视化库(如Matplotlib、Seaborn),我们能够以图表的形式清晰地展示电影数据的特征和趋势。最终,我们将分析结果以交互式的可视化界面呈现,用户可以通过系统自定义的查询与过滤功能,深入挖掘他们感兴趣的电影信息。这个项目不仅为电影爱好者提供了一个全面的数据参考平台,也为电影产业从业者提供了洞察行业动向的工具。
最后我们爬取到的字段信息:电影名,评分,封面图,详情url,上映时间,导演,类型,制作国家,语言,片长,电影简介,星星比例,多少人评价,预告片,前五条评论,五张详情图片
for i,moveInfomation in enumerate(moveisInfomation):
try:
resultData = {}
# 详情
resultData['detailLink'] = detailUrls[i]
# 导演(数组)
resultData['directors'] = ','.join(moveInfomation['directors'])
# 评分
resultData['rate'] = moveInfomation['rate']
# 影片名
resultData['title'] = moveInfomation['title']
# 主演(数组)
resultData['casts'] = ','.join(moveInfomation['casts'])
# 封面
resultData['cover'] = moveInfomation['cover']
# =================进入详情页====================
detailMovieRes = requests.get(detailUrls[i], headers=headers)
soup = BeautifulSoup(detailMovieRes.text, 'lxml')
# 上映年份
resultData['year'] = re.findall(r'[(](.*?)[)]',soup.find('span', class_='year').get_text())[0]
types = soup.find_all('span',property='v:genre')
for i,span in enumerate(types):
types[i] = span.get_text()
# 影片类型(数组)
resultData['types'] = ','.join(types)
country = soup.find_all('span',class_='pl')[4].next_sibling.strip().split(sep='/')
for i,c in enumerate(country):
country[i] = c.strip()
# 制作国家(数组)
resultData['country'] = ','.join(country)
lang = soup.find_all('span', class_='pl')[5].next_sibling.strip().split(sep='/')
for i, l in enumerate(lang):
lang[i] = l.strip()
# 影片语言(数组)
resultData['lang'] = ','.join(lang)
upTimes = soup.find_all('span',property='v:initialReleaseDate')
upTimesStr = ''
for i in upTimes:
upTimesStr = upTimesStr + i.get_text()
upTime = re.findall(r'\d*-\d*-\d*',upTimesStr)[0]
# 上映时间
resultData['time'] = upTime
if soup.find('span',property='v:runtime'):
# 时间长度
resultData['moveiTime'] = re.findall(r'\d+',soup.find('span',property='v:runtime').get_text())[0]
else:
# 时间长度
resultData['moveiTime'] = random.randint(39,61)
# 评论个数
resultData['comment_len'] = soup.find('span',property='v:votes').get_text()
starts = []
startAll = soup.find_all('span',class_='rating_per')
for i in startAll:
starts.append(i.get_text())
# 星星比例(数组)
resultData['starts'] = ','.join(starts)
# 影片简介
resultData['summary'] = soup.find('span',property='v:summary').get_text().strip()
# 五条热评
comments_info = soup.find_all('span', class_='comment-info')
comments = [{} for x in range(5)]
for i, comment in enumerate(comments_info):
comments[i]['user'] = comment.contents[1].get_text()
comments[i]['start'] = re.findall('(\d*)', comment.contents[5].attrs['class'][0])[7]
comments[i]['time'] = comment.contents[7].attrs['title']
contents = soup.find_all('span', class_='short')
for i in range(5):
comments[i]['content'] = contents[i].get_text()
resultData['comments'] = json.dumps(comments)
# 五张详情图
imgList = []
lis = soup.select('.related-pic-bd img')
for i in lis:
imgList.append(i['src'])
resultData['imgList'] = ','.join(imgList)
将结果保存到CSV文件和SQL数据库中,并在完成后更新页数记录。
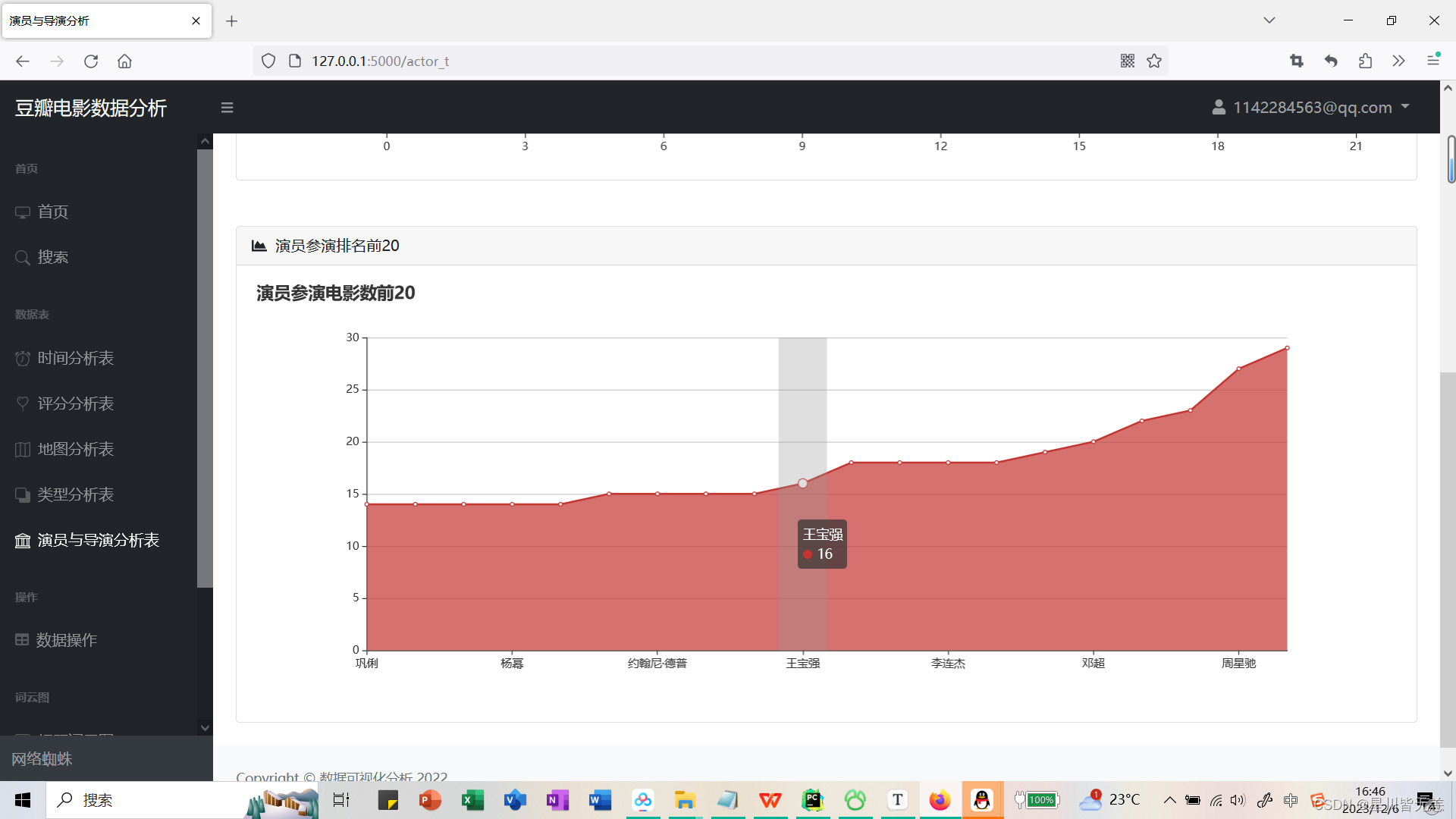
从豆瓣电影数据中提取演员和导演的电影数量信息,以便后续的分析和可视化展示。
def getAllActorMovieNum():
allData = homeData.getAllData()
ActorMovieNum = {}
for i in allData:
for j in i[1]:
if ActorMovieNum.get(j,-1) == -1:
ActorMovieNum[j] = 1
else:
ActorMovieNum[j] = ActorMovieNum[j] + 1
ActorMovieNum = sorted(ActorMovieNum.items(), key=lambda x: x[1])[-20:]
x = []
y = []
for i in ActorMovieNum:
x.append(i[0])
y.append(i[1])
return x,y
定义统计导演执导电影数量的函数getAllDirectorMovieNum():
def getAllDirectorMovieNum():
allData = homeData.getAllData()
ActorMovieNum = {}
for i in allData:
for j in i[4]:
if ActorMovieNum.get(j,-1) == -1:
ActorMovieNum[j] = 1
else:
ActorMovieNum[j] = ActorMovieNum[j] + 1
ActorMovieNum = sorted(ActorMovieNum.items(), key=lambda x: x[1])[-20:]
x = []
y = []
for i in ActorMovieNum:
x.append(i[0])
y.append(i[1])
return x,y
allData = homeData.getAllData():调用homeData模块中的getAllData函数,获取所有的电影数据,并将其保存在allData变量中。ActorMovieNum = {}:创建一个空字典ActorMovieNum,用于存储导演与其执导电影数量的映射。for i in allData::遍历所有电影数据,其中i代表每一部电影的信息。for j in i[4]::在每部电影的信息中,使用i[4]访问导演的信息,然后遍历每个导演。if ActorMovieNum.get(j, -1) == -1::检查字典ActorMovieNum中是否已经存在该导演的记录。如果不存在,则将该导演作为键加入字典,并将对应的值初始化为1。else::如果字典中已存在该导演的记录,则将对应的值加1,表示该导演又执导了一部电影。ActorMovieNum = sorted(ActorMovieNum.items(), key=lambda x: x[1])[-20:]:将字典中的导演及其执导电影数量按照电影数量进行降序排序,然后取排序后的前20项。排序的依据是key=lambda x: x[1],即按照字典中的值进行排序。x = []和y = []:创建两个空列表,用于存储导演名称和对应的执导电影数量。for i in ActorMovieNum::遍历排序后的前20项导演及其执导电影数量。x.append(i[0])和y.append(i[1]):将导演的名称和执导电影数量分别加入列表x和y。return x, y:返回存储导演名称和执导电影数量的两个列表。
从名为homeData的模块中导入getAllData函数,然后使用pandas库创建一个数据框(DataFrame)df。getAllData函数的返回值被传递给DataFrame的构造函数,同时指定了数据框的列名。
from . import homeData: 这行代码从当前目录(.表示当前目录)导入homeData模块。import pandas as ps: 这行代码导入pandas库,并使用ps作为别名。一般来说,pandas的别名是pd,但在这里使用了ps。df = ps.DataFrame(homeData.getAllData(), columns=[...]): 这行代码创建一个数据框df,并使用homeData.getAllData()的返回值填充数据框。列名由columns参数指定,列的顺序与列表中的顺序相对应。列名包括:- ‘id’: 电影ID
- ‘directors’: 导演
- ‘rate’: 评分
- ‘title’: 标题
- ‘casts’: 演员
- ‘cover’: 封面
- ‘year’: 上映年份
- ‘types’: 类型
- ‘country’: 制片国家
- ‘lang’: 语言
- ‘time’: 时长
- ‘moveiTime’: 电影时长
- ‘comment_len’: 评论长度
- ‘starts’: 星级
- ‘summary’: 摘要
- ‘comments’: 评论
- ‘imgList’: 图片列表
- ‘movieUrl’: 电影链接
- ‘detailLink’: 详细链接
这样就创建了一个包含特定列名的数据框,其中的数据来自homeData.getAllData()函数的返回结果。
from . import homeData
import pandas as ps
df = ps.DataFrame(homeData.getAllData(),columns=[
'id',
'directors',
'rate',
'title',
'casts',
'cover',
'year',
'types',
'country',
'lang',
'time',
'moveiTime',
'comment_len',
'starts',
'summary',
'comments',
'imgList',
'movieUrl',
'detailLink'
])
从数据框(DataFrame)中的’country’列中提取地址数据。数据框中的地址数据提取出来,并统计每个地址出现的次数。它首先检查’country’列中的每个元素,如果元素是一个列表,则将列表中的每个元素添加到一个新的列表(address)中。然后,它创建一个字典(addressDic),将地址作为键,出现次数作为值,最后返回地址列表和对应的出现次数列表。
def getAddressData():
# 获取名为 'country' 的列的值
addresses = df['country'].values
# 创建一个空列表来存储地址
address = []
# 遍历 'country' 列的每个元素
for i in addresses:
# 如果元素是列表类型
if isinstance(i, list):
# 遍历列表中的每个元素并添加到 address 列表中
for j in i:
address.append(j)
else:
# 如果元素不是列表类型,直接将其添加到 address 列表中
address.append(i)
# 创建一个空字典来存储地址及其出现次数
addressDic = {}
# 遍历地址列表中的每个元素
for i in address:
# 如果地址字典中不存在该地址,则将其添加并设置出现次数为1
if addressDic.get(i, -1) == -1:
addressDic[i] = 1
else:
# 如果地址字典中已存在该地址,则将其出现次数加1
addressDic[i] = addressDic[i] + 1
# 返回地址列表和对应的出现次数列表
return list(addressDic.keys()), list(addressDic.values())
从数据框的’lang’列中提取语言数据,并统计每种语言出现的次数。最终返回语言列表和对应的出现次数列表。
def getLangData():
# 获取名为 'lang' 的列的值
langs = df['lang'].values
# 创建一个空列表来存储语言数据
languages = []
# 遍历 'lang' 列的每个元素
for i in langs:
# 如果元素是列表类型
if isinstance(i, list):
# 遍历列表中的每个元素并添加到 languages 列表中
for j in i:
languages.append(j)
else:
# 如果元素不是列表类型,直接将其添加到 languages 列表中
languages.append(i)
# 创建一个空字典来存储语言及其出现次数
langsDic = {}
# 遍历语言列表中的每个元素
for i in languages:
# 如果语言字典中不存在该语言,则将其添加并设置出现次数为1
if langsDic.get(i, -1) == -1:
langsDic[i] = 1
else:
# 如果语言字典中已存在该语言,则将其出现次数加1
langsDic[i] = langsDic[i] + 1
# 返回语言列表和对应的出现次数列表
return list(langsDic.keys()), list(langsDic.values())
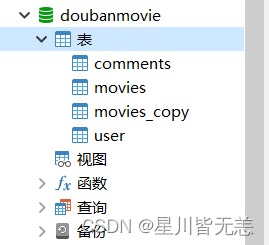
数据库创建四个表:
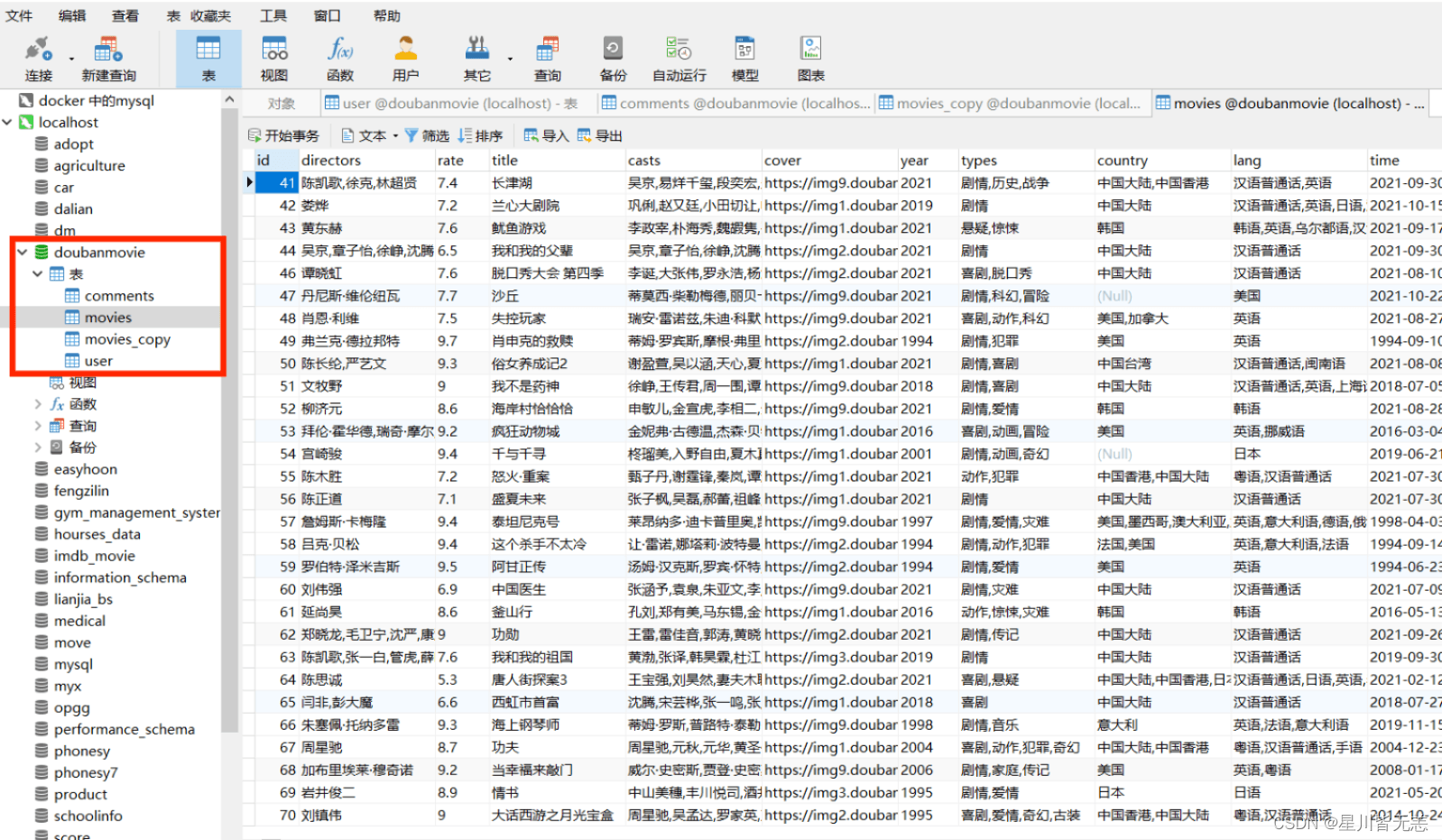
修改为自己的数据库主机名和账号密码:
启动项目:
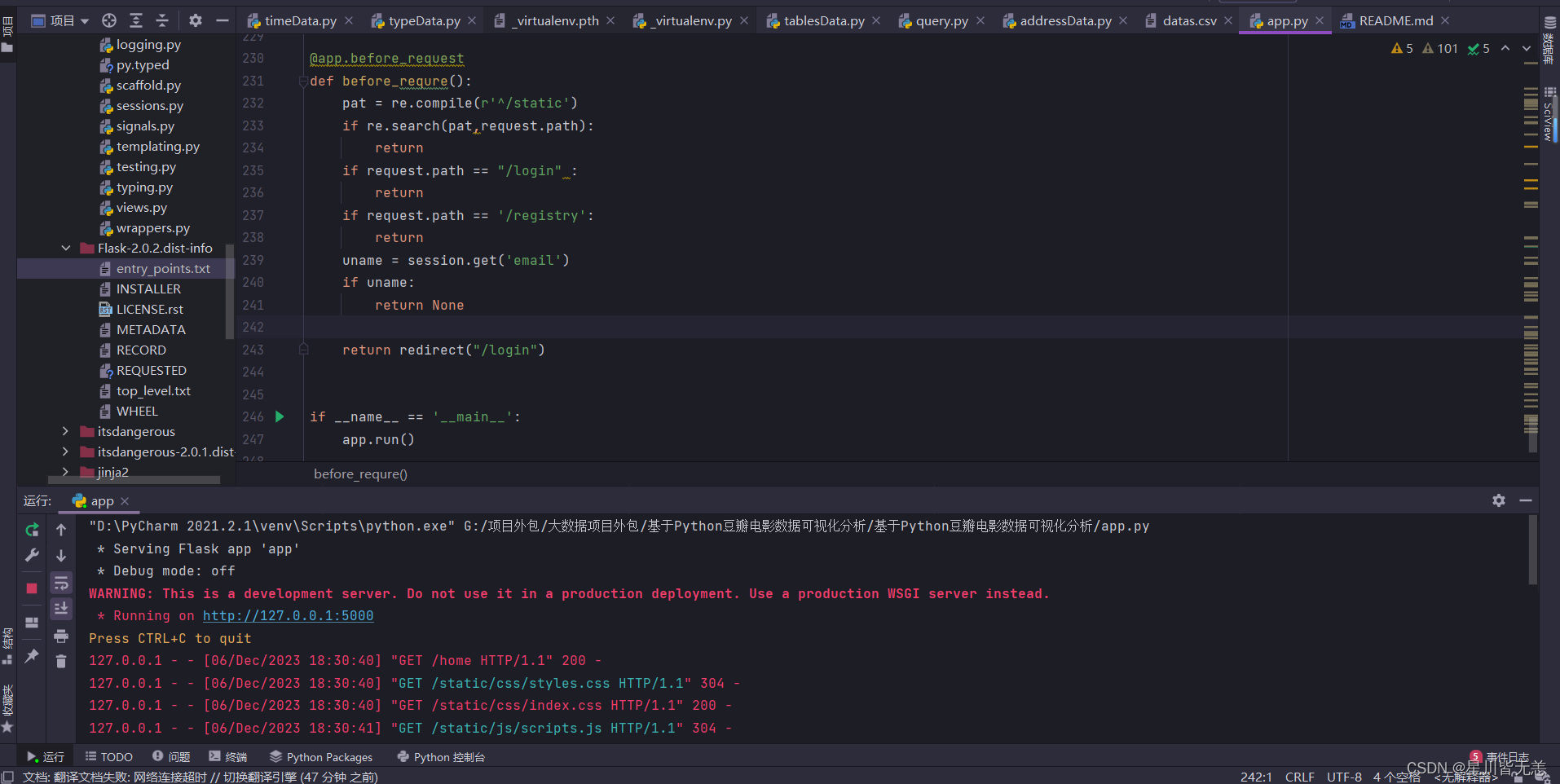
服务端口:5000 http://127.0.0.1:5000
用户注册 http://127.0.0.1:5000/registry
用户登录
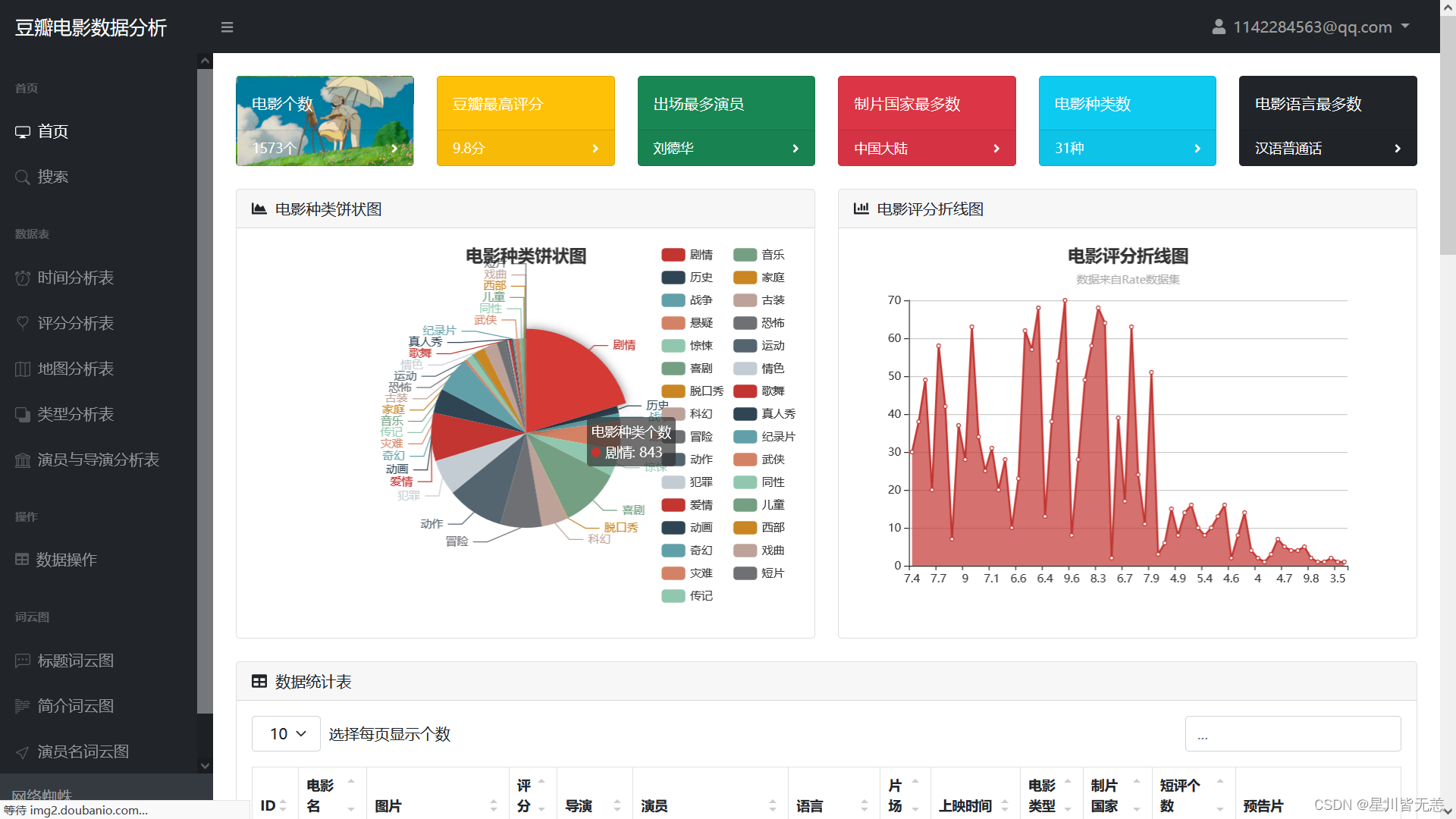
首页页面展示:
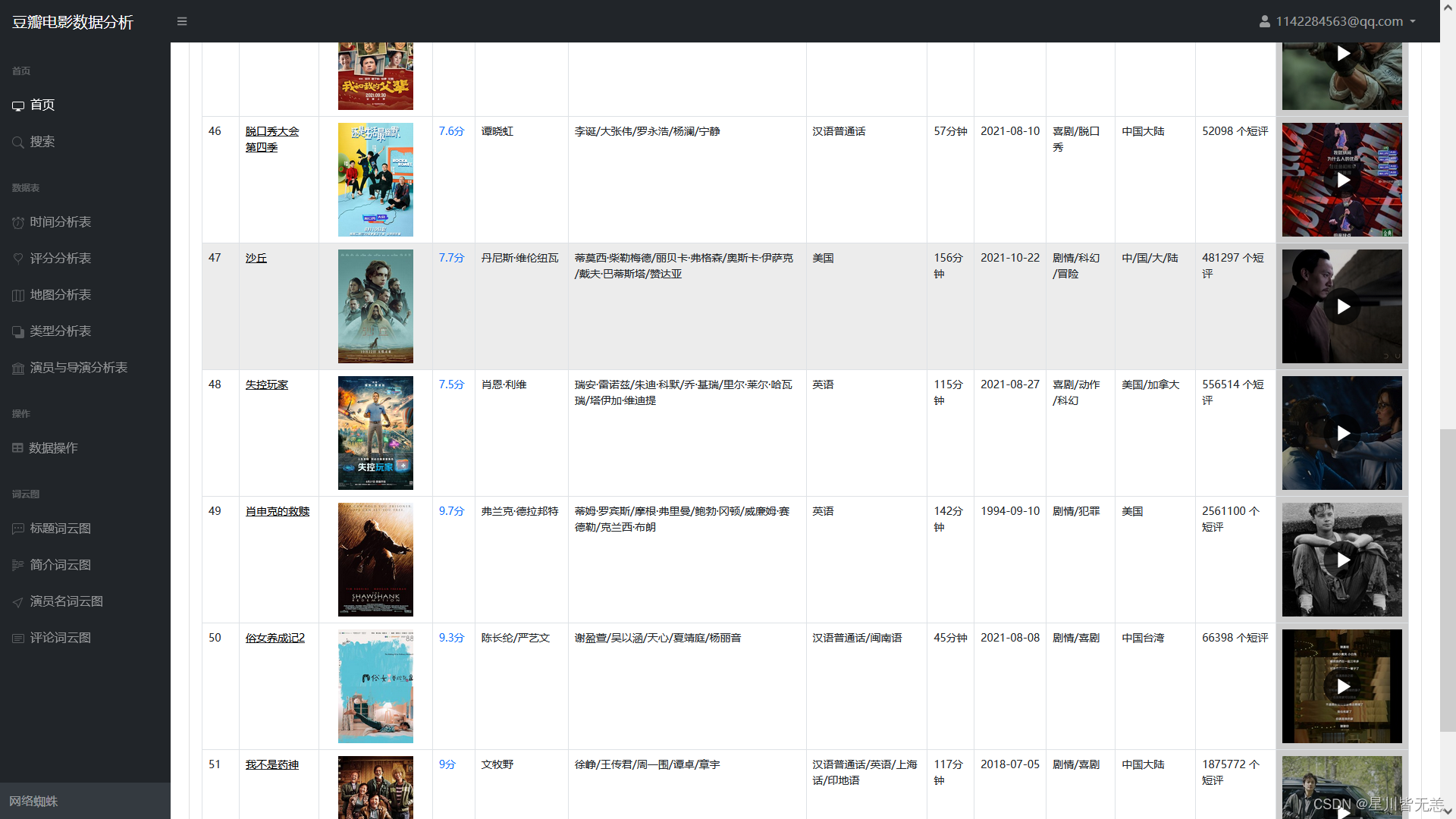
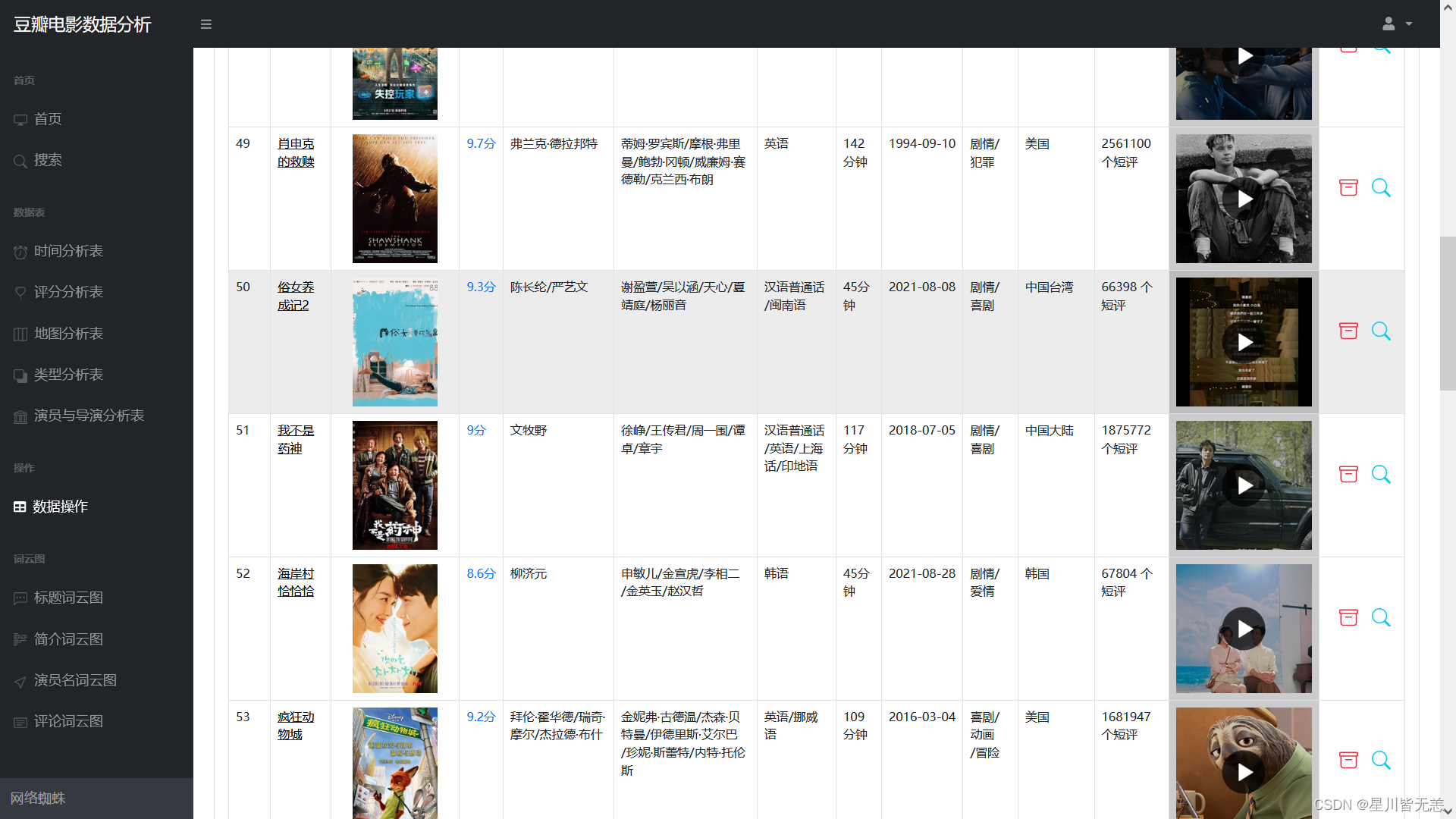
还有电影数据,包括电影名、评分、片场、预告片等数据。
查看电影预告片
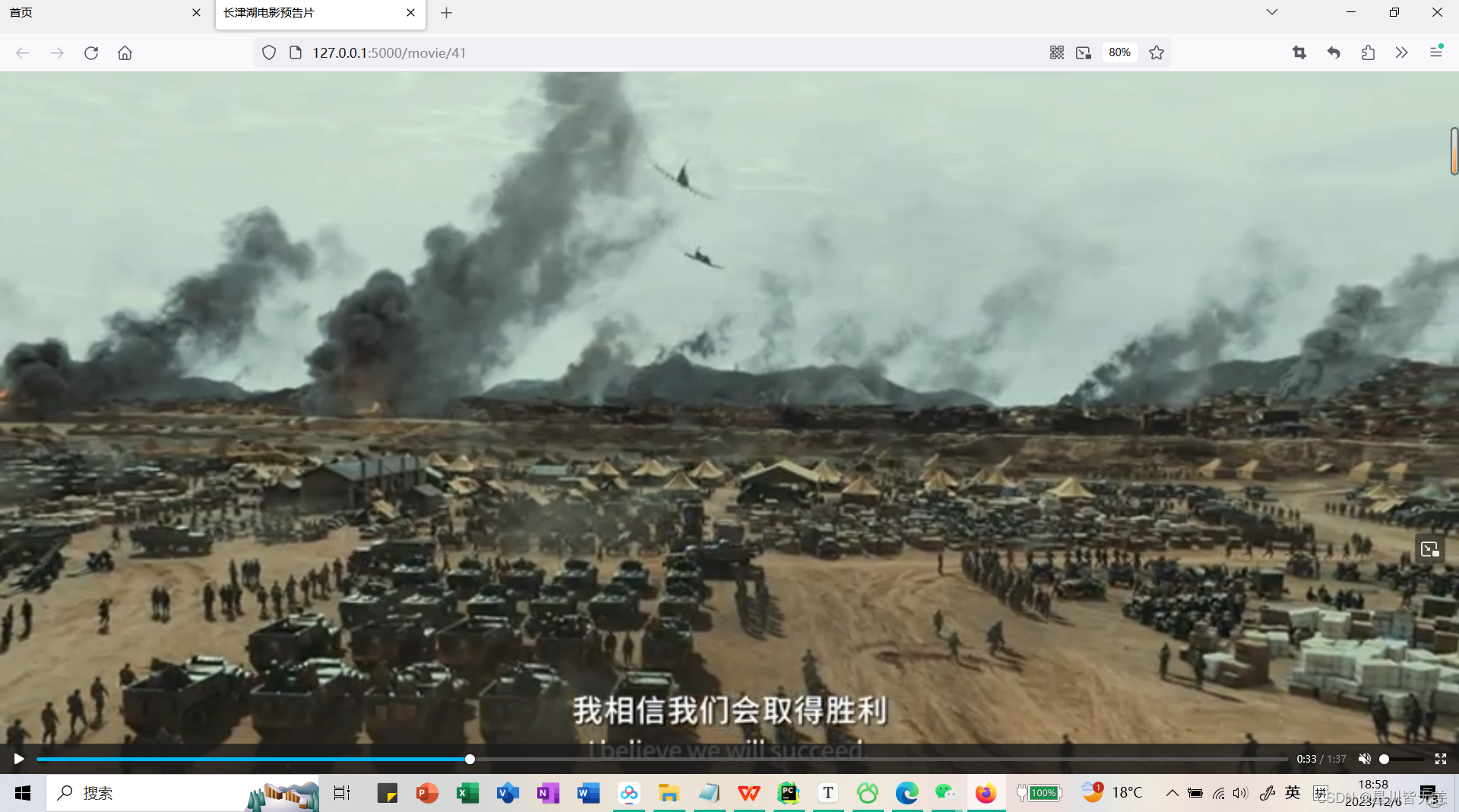
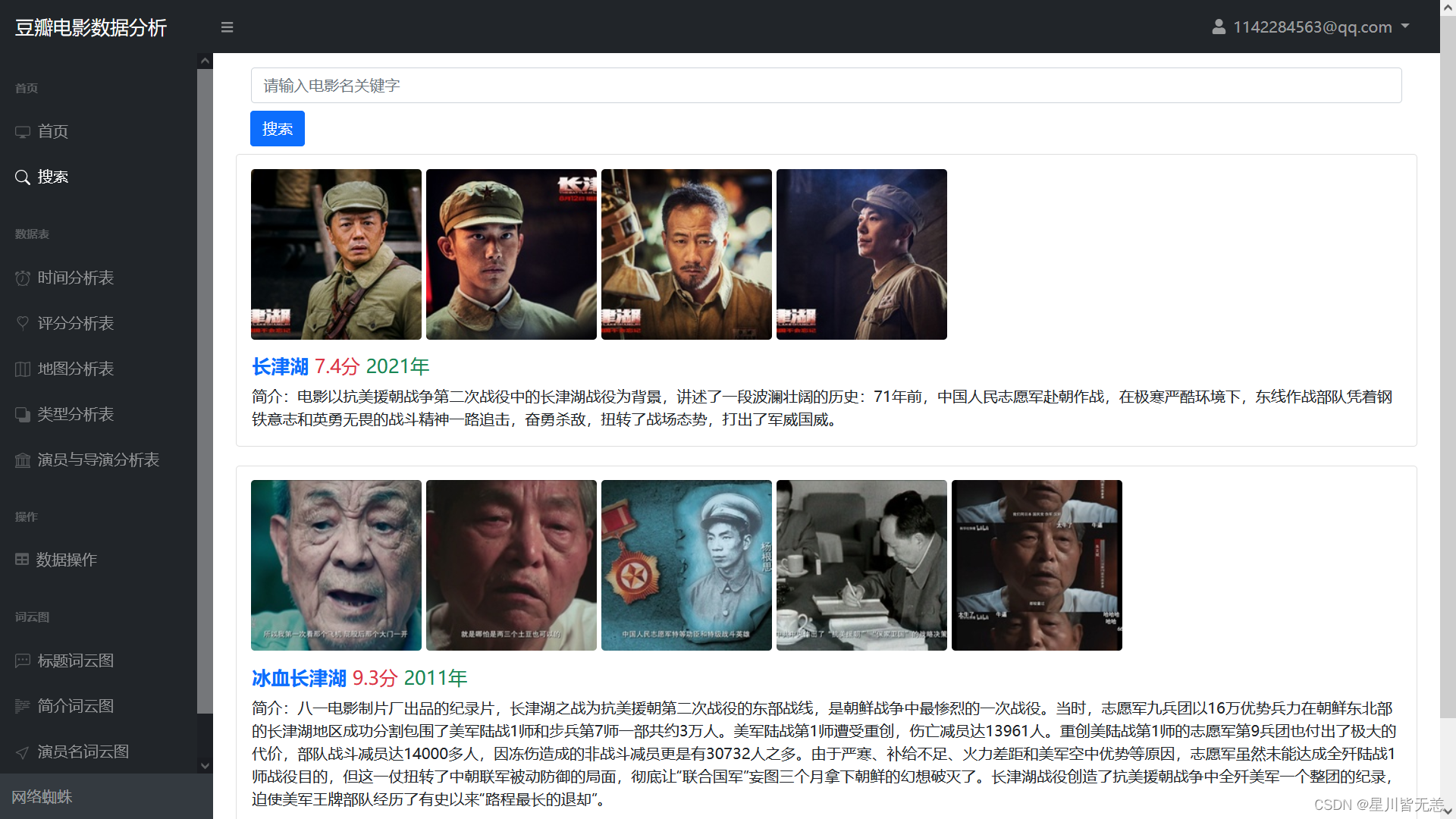
电影搜索
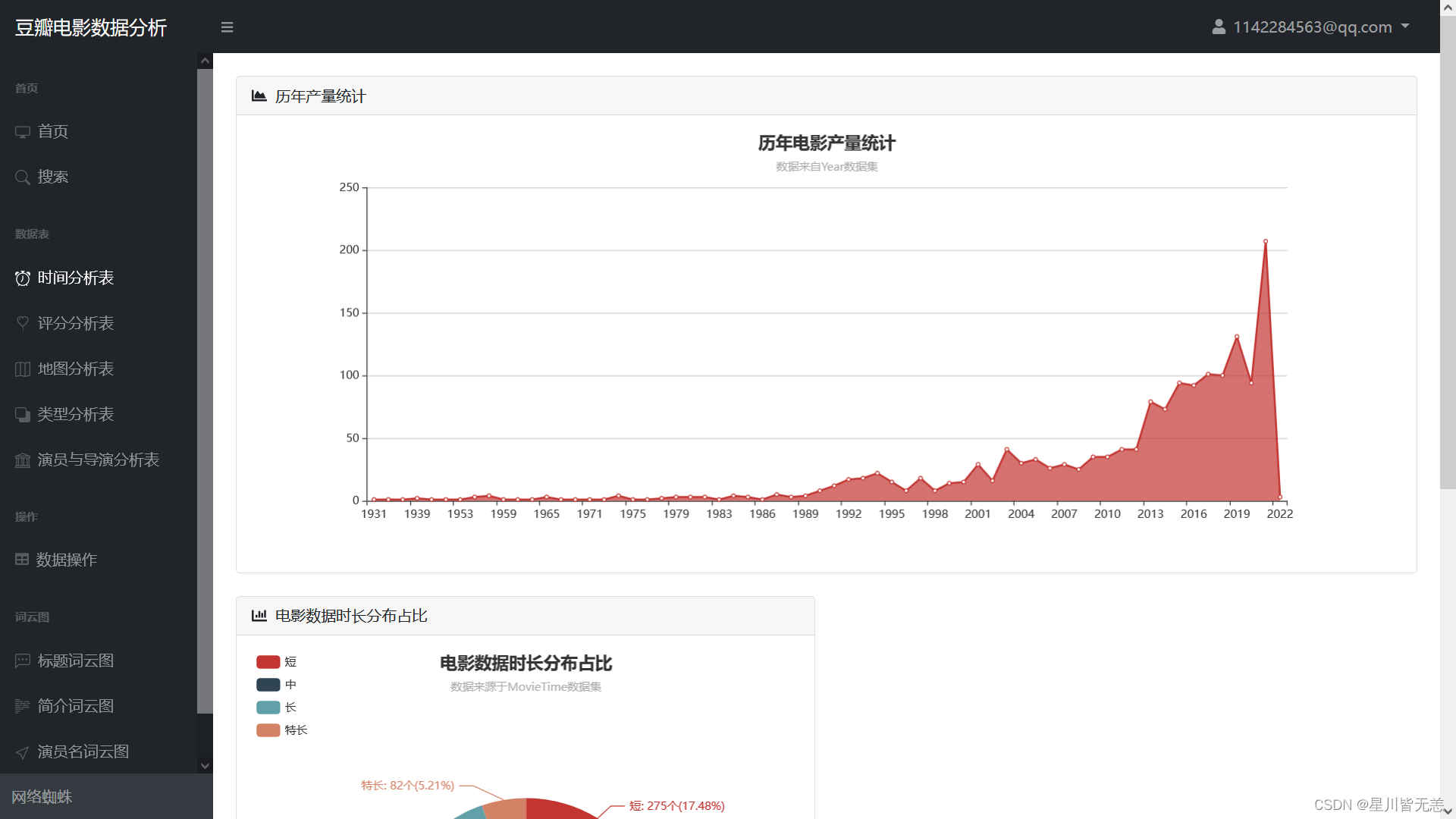
电影产量分析
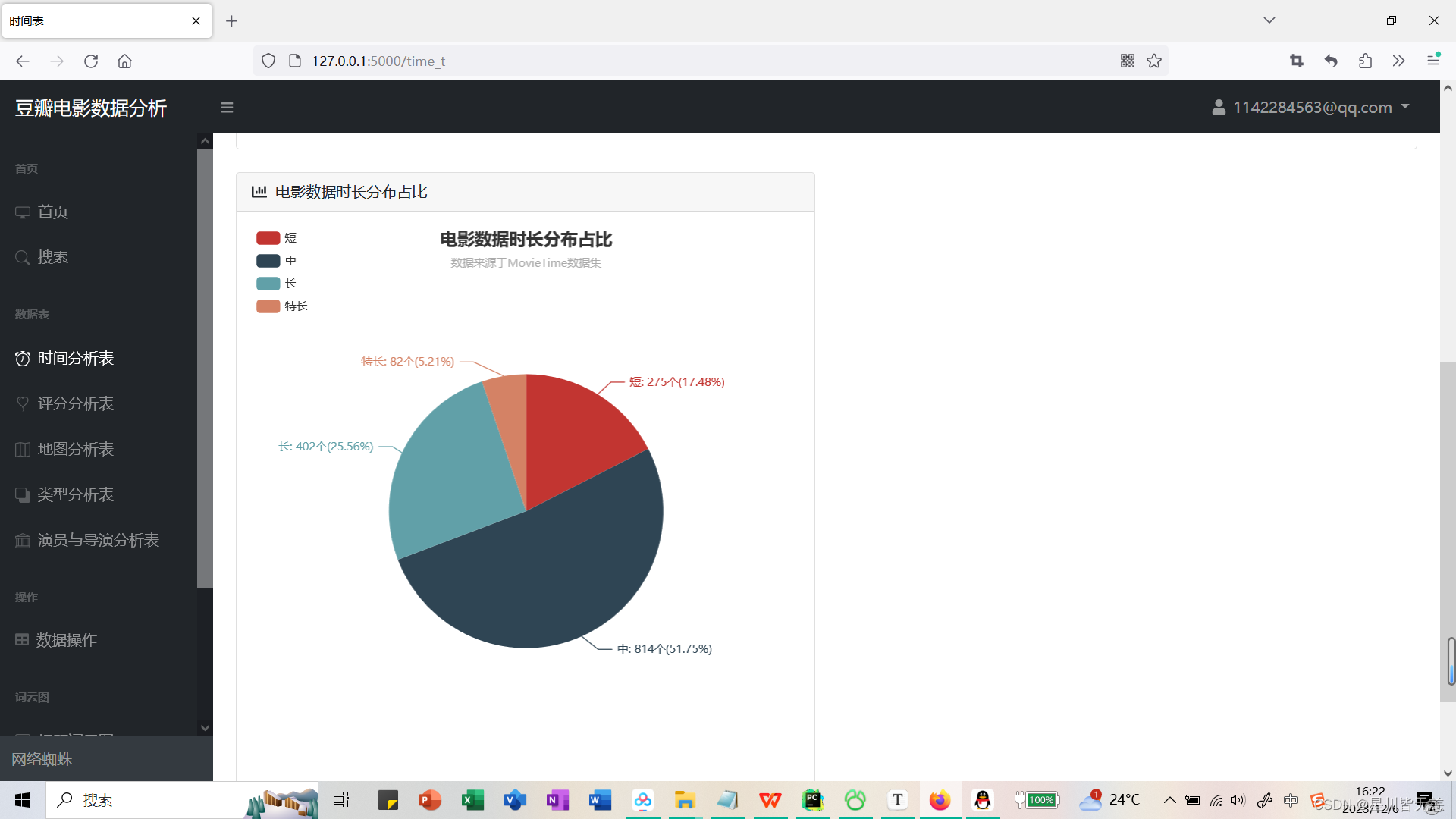
电影数据时长分布占比
电影评分统计分析
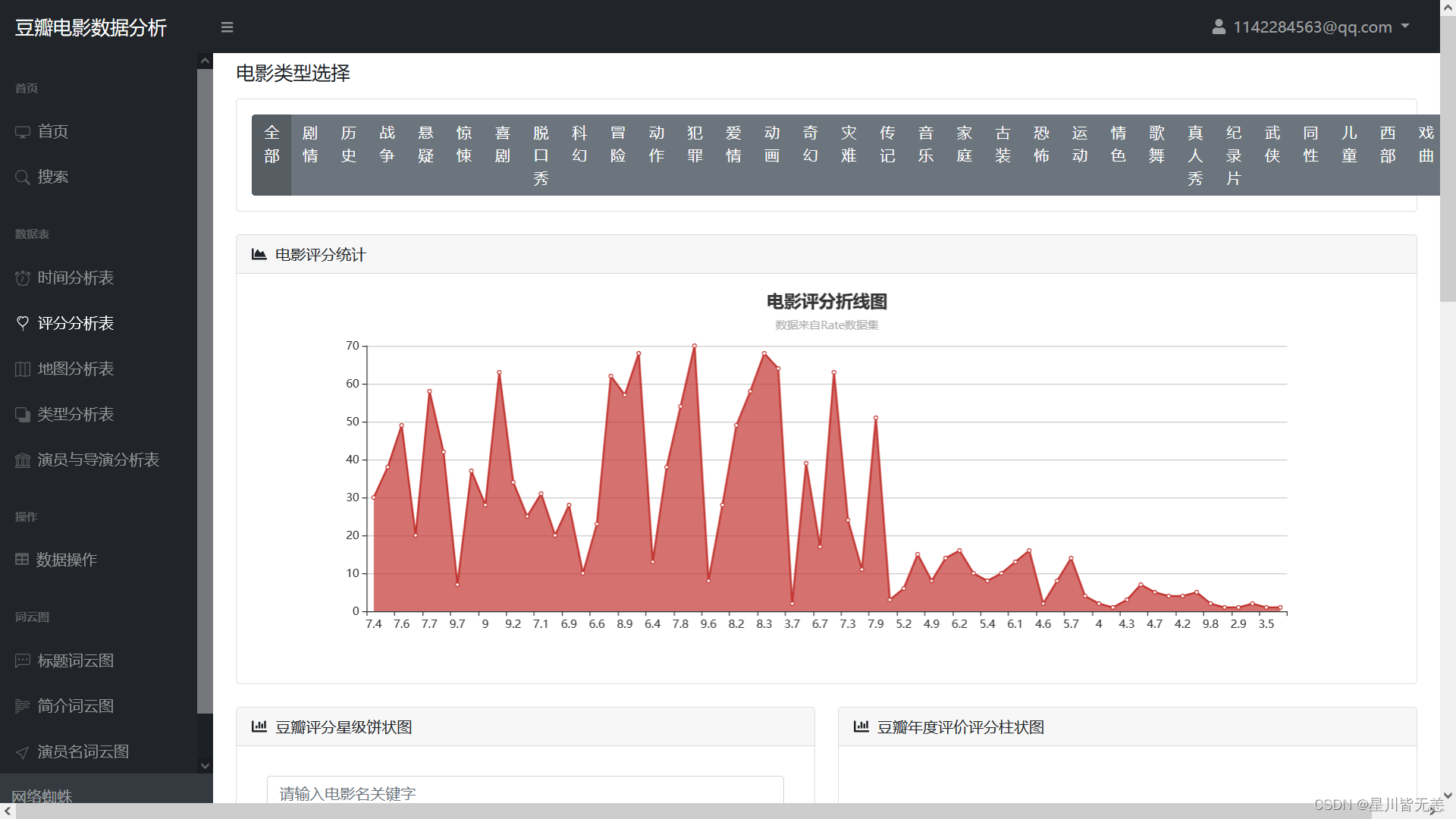
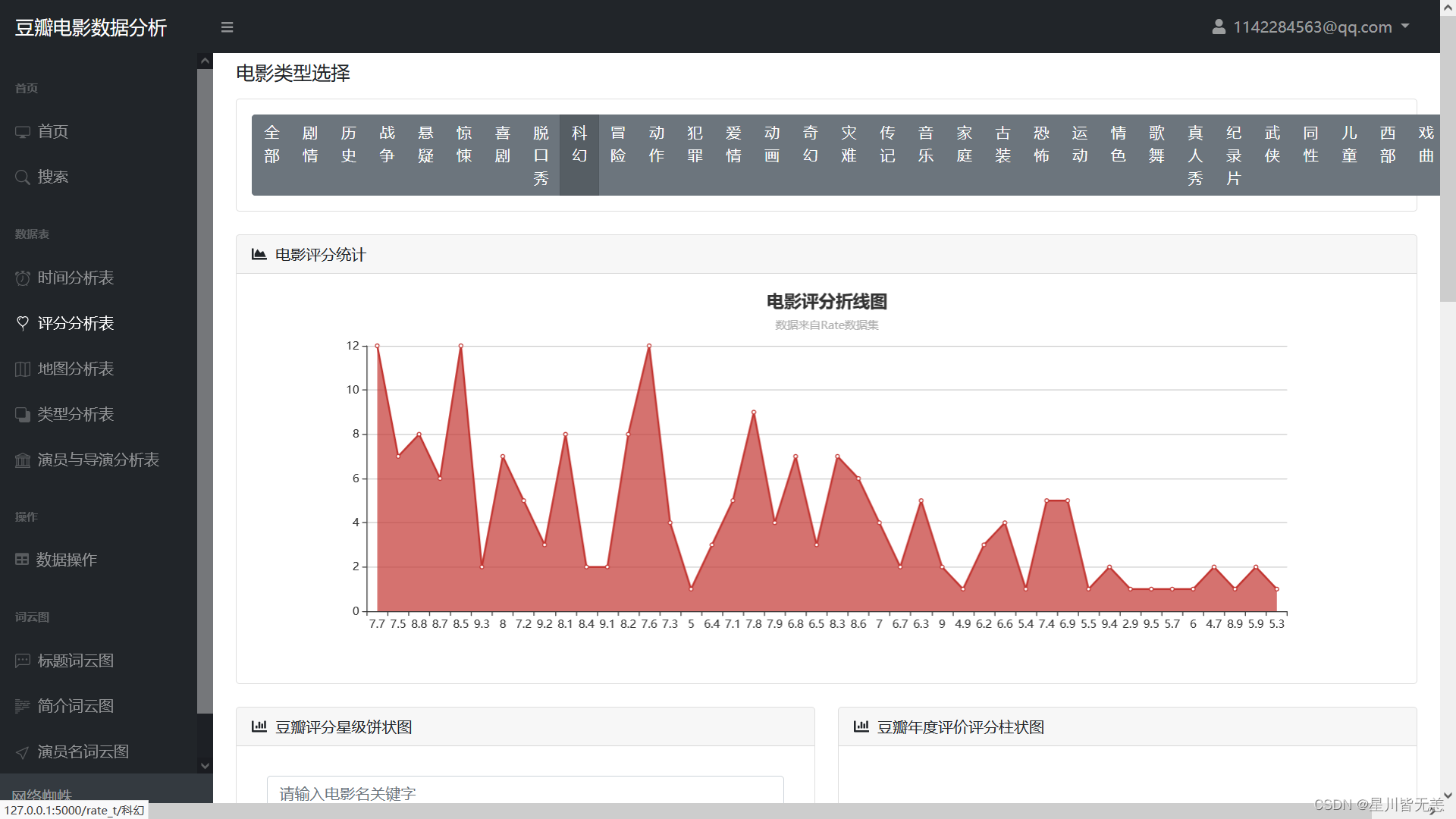
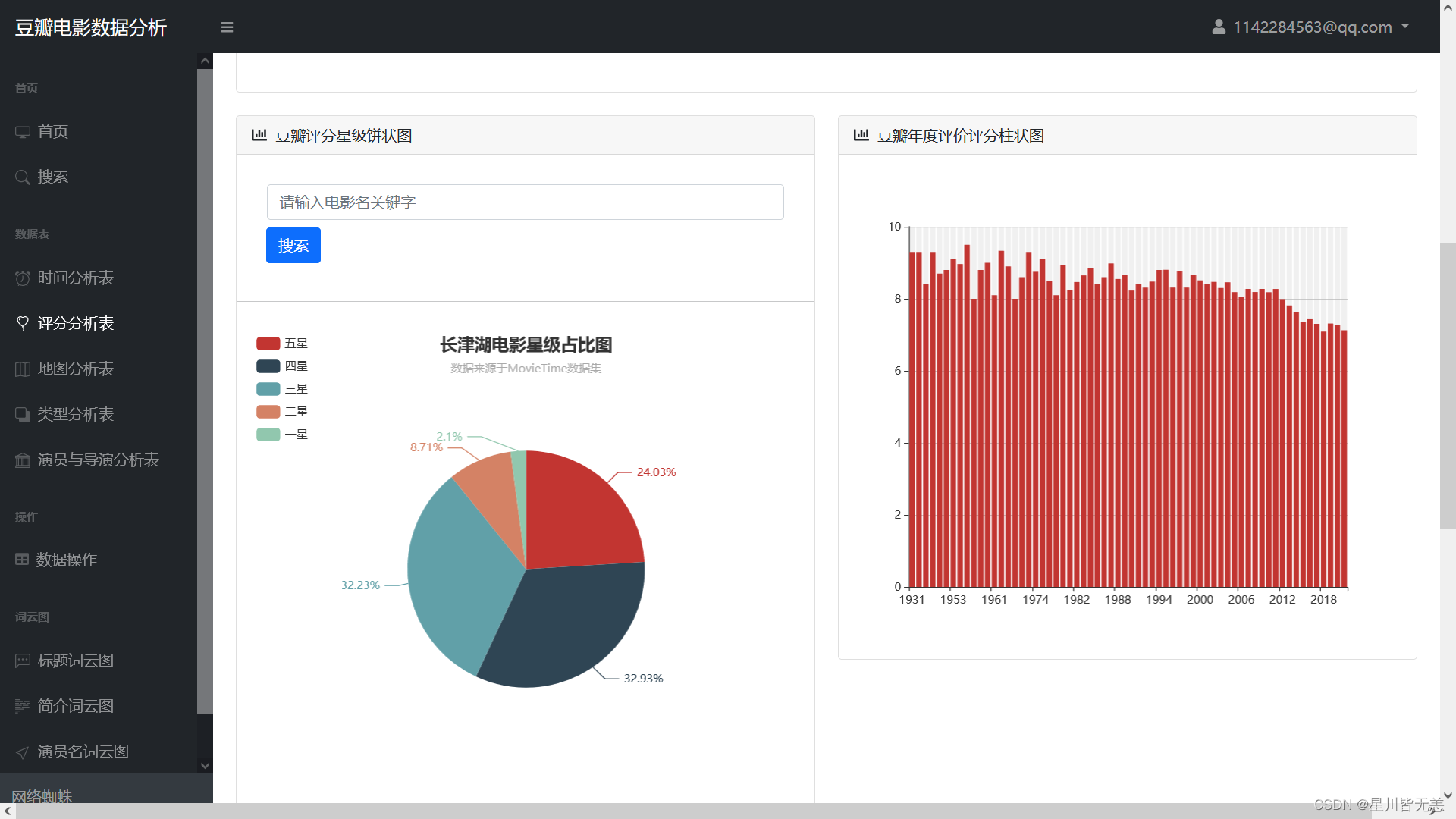
豆瓣评分星级饼状图、豆瓣年度评价评分柱状图
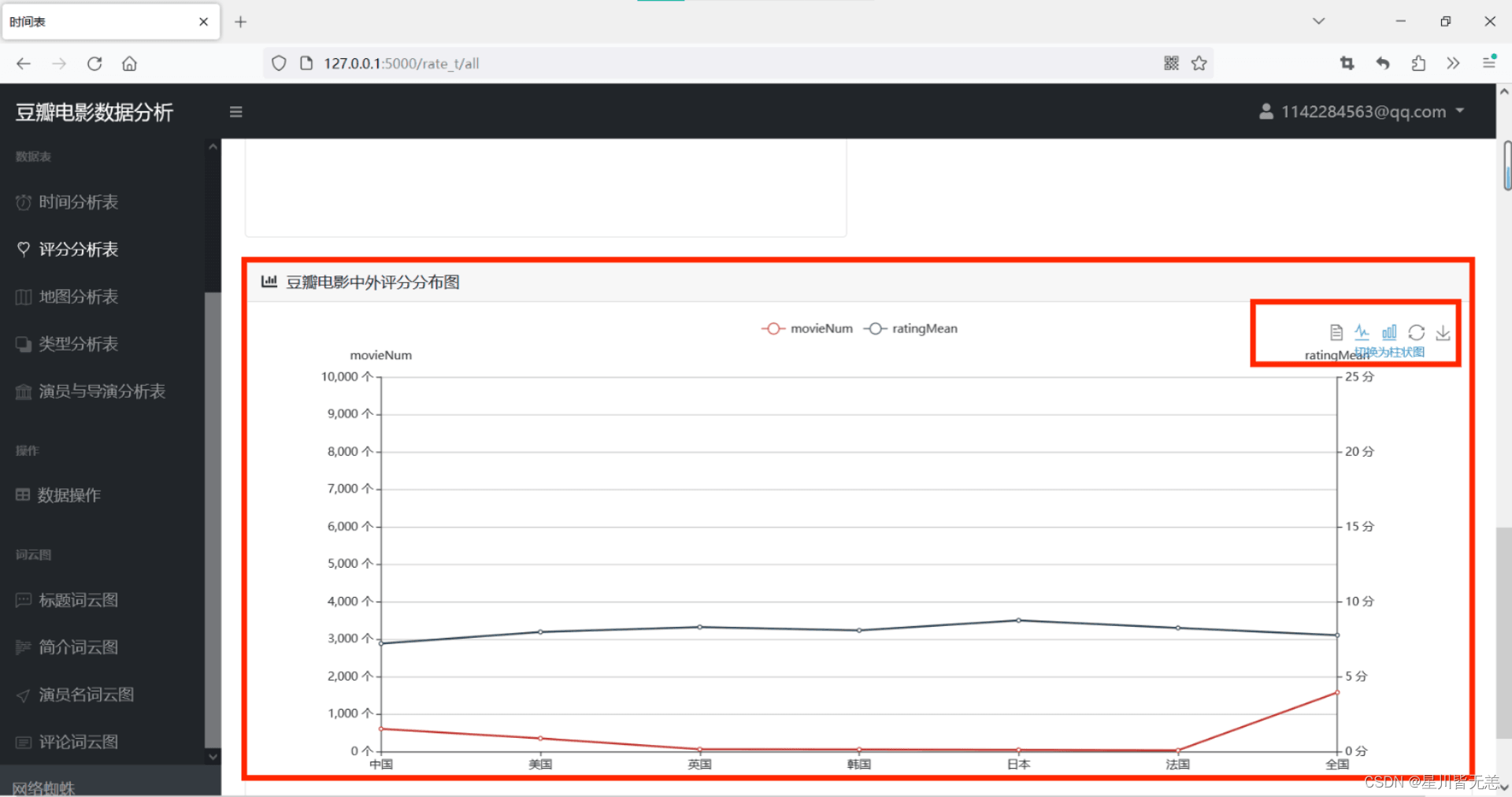
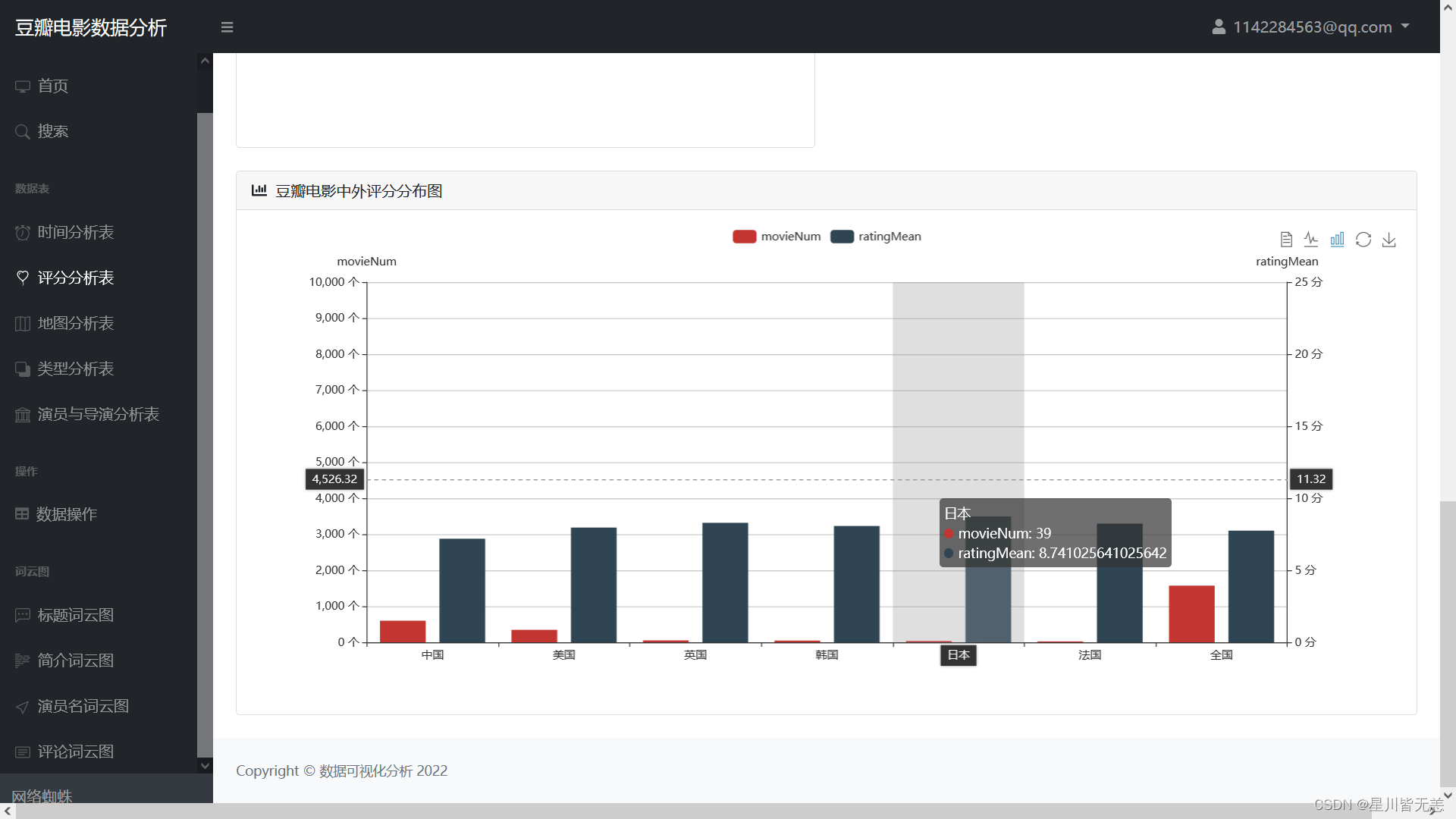
豆瓣电影中外评分分布图
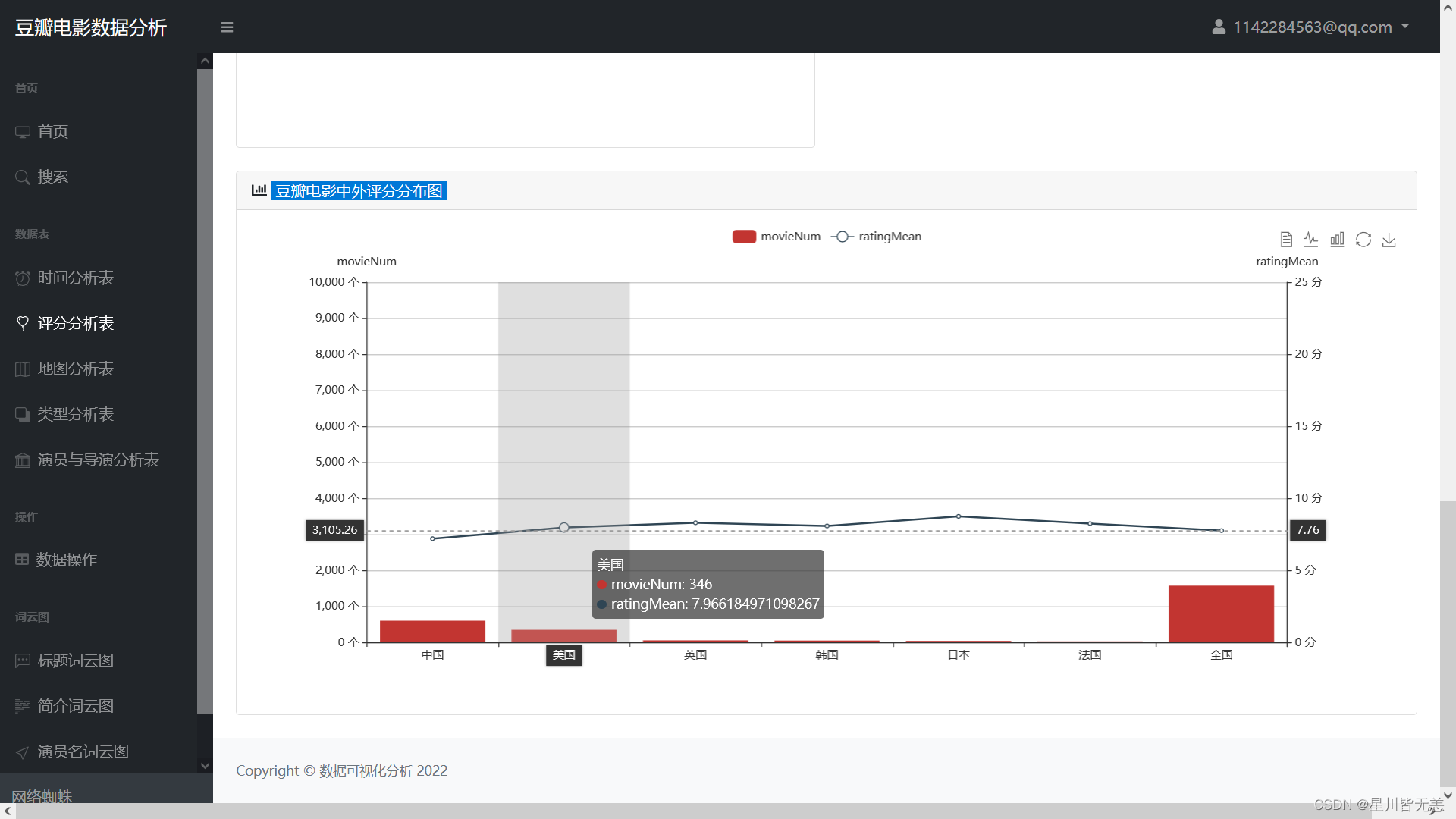
数据视图切换
电影拍摄地点统计图
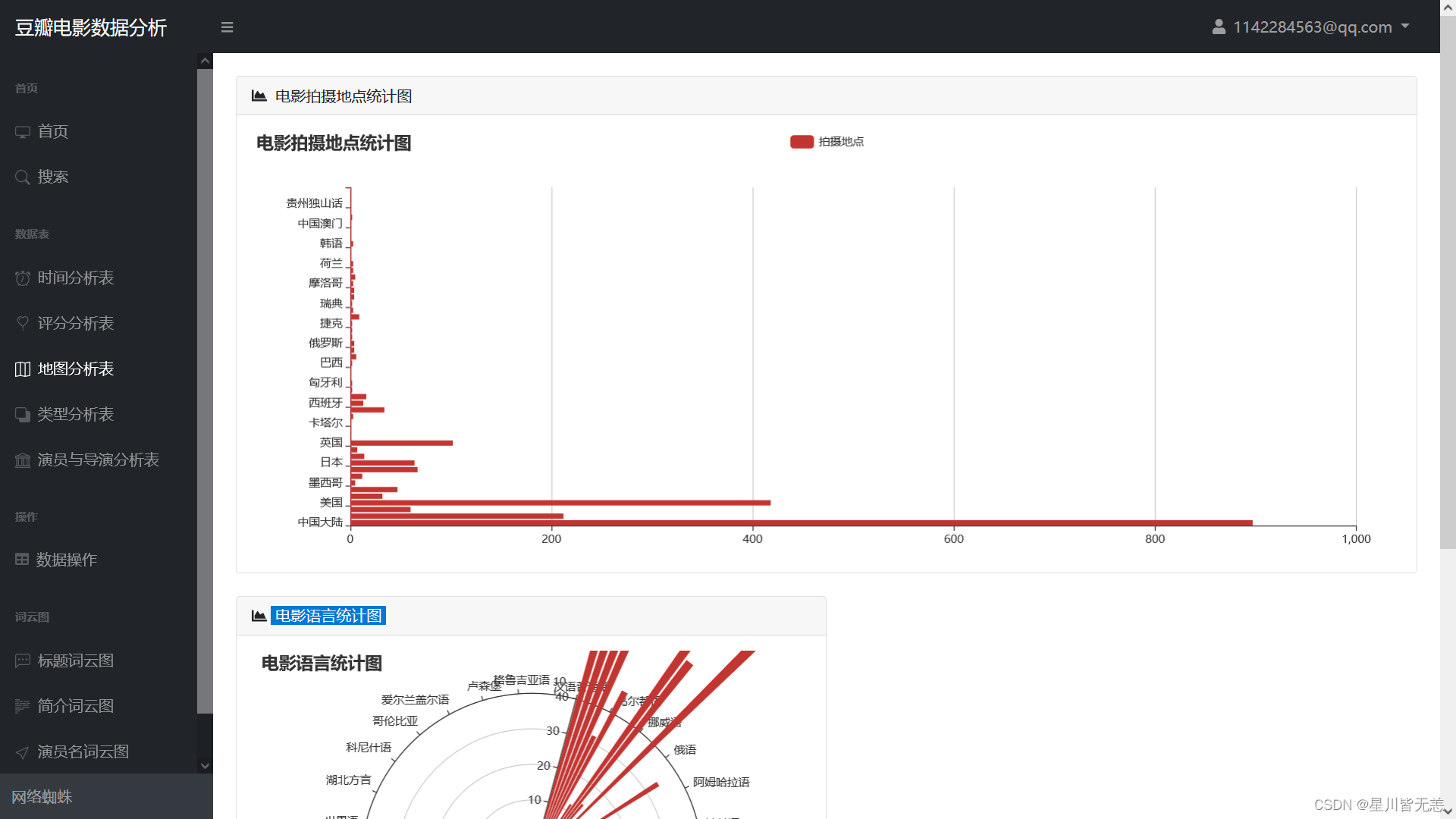
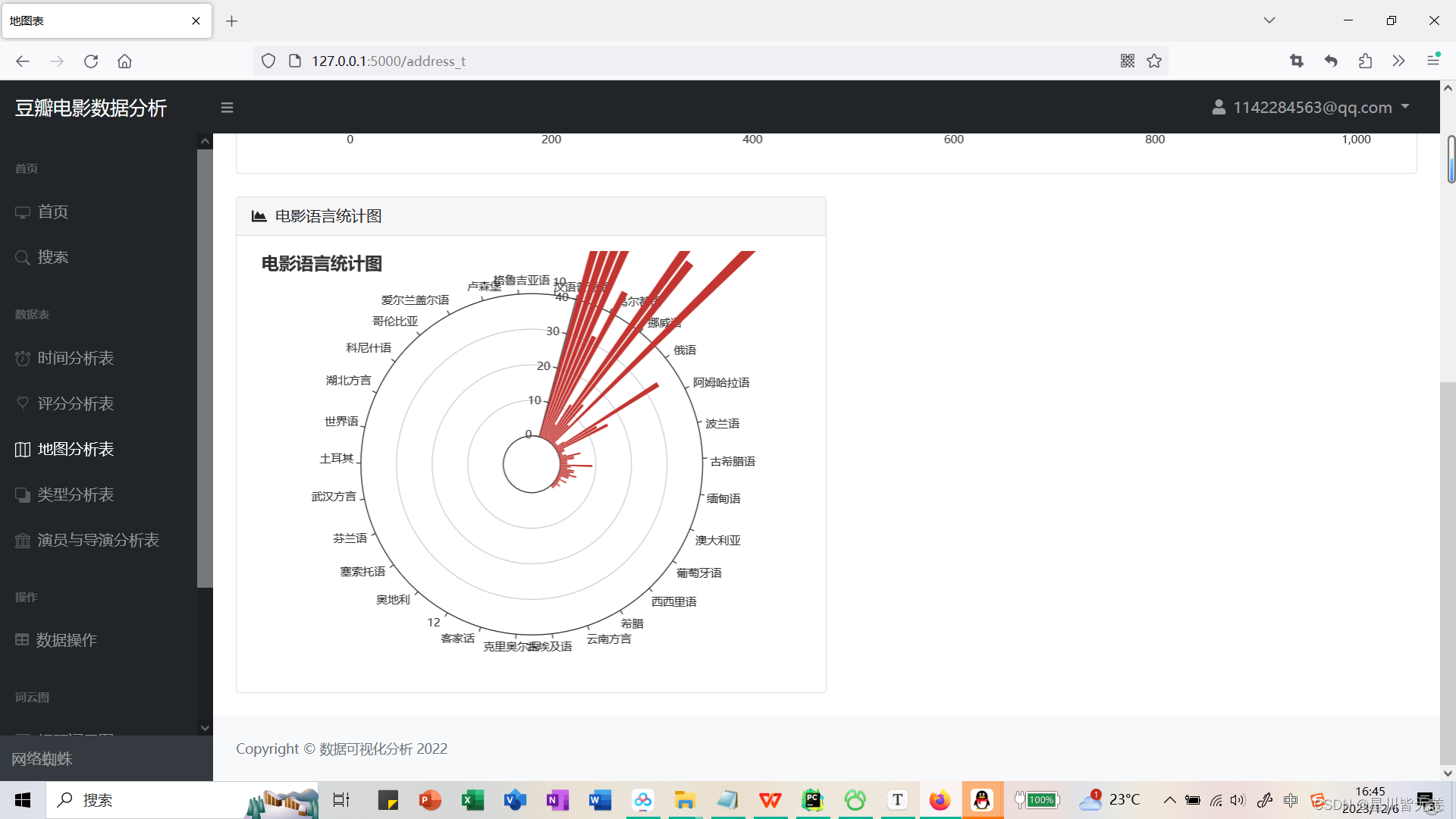
电影语言统计图
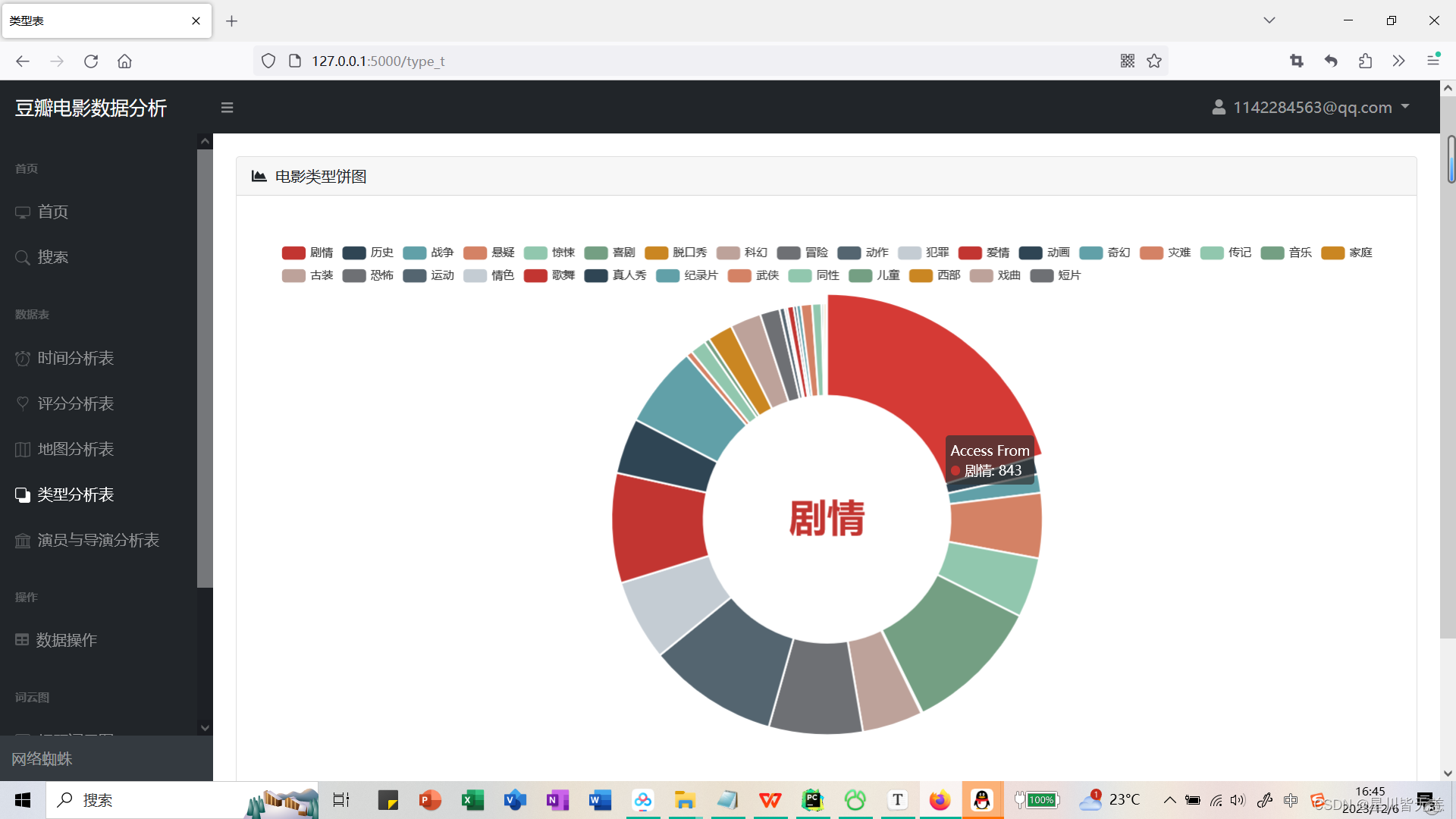
电影类型饼图
导演作品数量前20

数据表操作
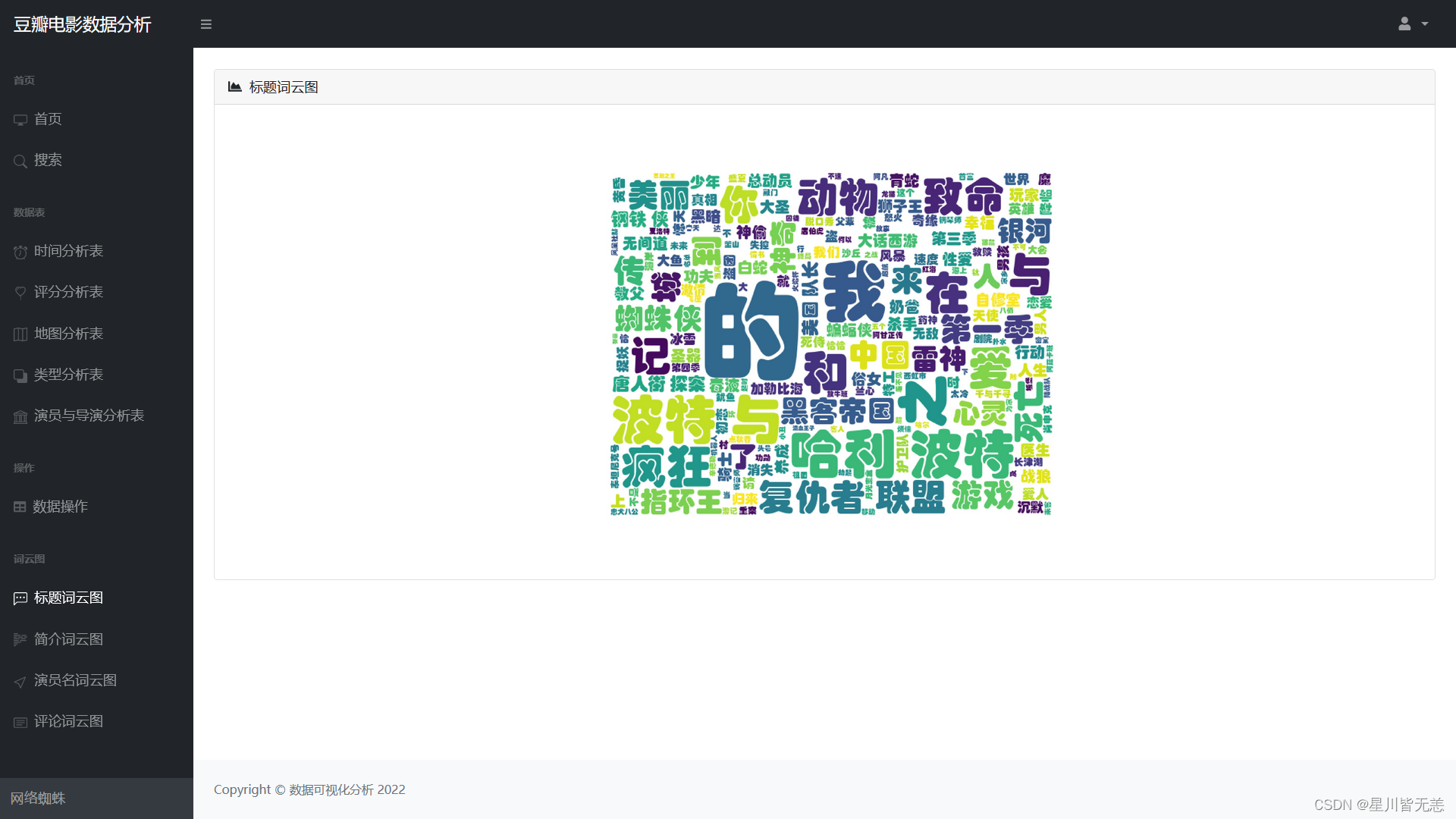
标题词云图
简介词云图
s4XV8qh-1701860368769)
演员名词云图
评论词云图
经过对一系列测试结果的有效分析,本平台开发系统符合用户的要求和需求。所有的基本功能齐全,可视化展示效果好,服务运行稳定,操作起来简单方便,测试系统性能、整体设计和代码逻辑都很Nice!
各位有兴趣的小伙伴 可以私信我要项目开发文档、完整项目源码和其它相关资料。
后面有时间和精力也会分享更多关于大数据领域方面的优质内容,喜欢的小伙伴可以点赞关注收藏,有需要的都可以私信我!感谢各位的喜欢与支持!