DINet
- 方法
- 形变
- 修补
- 损失函数
- perception loss
- GAN loss
- Lip-sync loss
- 实现细节
- 参考
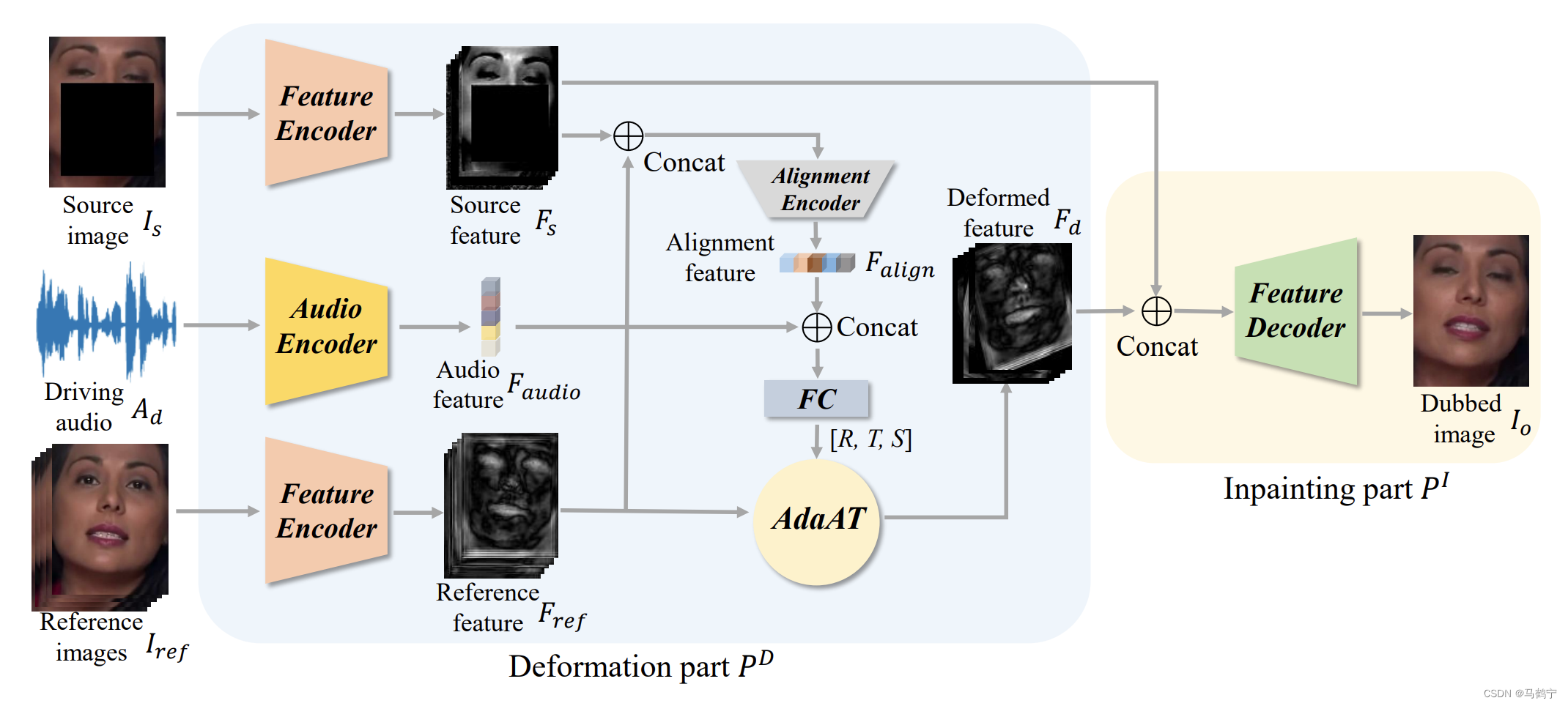
如下图所示,人脸视觉配音(Face visually dubbing)旨在根据输入的驱动音频同步源视频中的嘴型,同时保持身份和头部姿势与源视频帧一致。然而在少样本条件下,实现高分辨率视频下的高质量人脸视觉配音仍然是一项挑战。一个主要原因是,在少数样本的条件下,嘴部纹理细节与驱动音频的相关性很小,因此直接生成高频纹理细节是比较困难的。为了解决这个问题,形变修复网路DINet通过对参考人脸图像进行空间形变来保留更多的嘴部纹理细节。具体地,首先对参考人脸图像的特征图做空间形变,形变后的特征包含与语音同步和头部姿态对齐的口型特征;然后使用空间形变后的特征修补嘴部区域,空间形变是将像素移动,而不是重新生成,因此能够保存足够多的纹理信息。

方法
DINet网络架构由两部分组成,形变网络
P
D
P^{D}
PD和修补网路
P
I
P^{I}
PI。形变部分对五张参考图像的特征进行空间形变,创建每帧嘴部形状的变形特征图,以便于对齐输入驱动音频和输入源图像的头部姿态。修复部分则侧重于利用形变结果修复源面部的嘴部区域。
形变
自适应仿射变换算子(Adaptive Affine Transformation, AdaAT)解决人脸驱动前后空间不对齐的问题。AdaAT使用仿射变换来模拟和约束空间形变,它直接在特征通道空间中进行仿射变换。
给定一个源图像 I s ∈ R 3 × H × W I_{s} \in R^{3 \times H \times W} Is∈R3×H×W,一个驱动音频 A d ∈ R T × 29 A_{d} \in R^{T \times 29} Ad∈RT×29和五个参考图像 I r e f ∈ R 15 × H × W I_{ref} \in R^{15 \times H \times W} Iref∈R15×H×W,形变网络 P D P^{D} PD的任务就是输出与 A d A_{d} Ad同步的嘴型且与 I s I_{s} Is头部姿态对齐的形变特征 F d ∈ R 256 × H 4 × W 4 F_{d} \in R^{256 \times \frac{H}{4} \times \frac{W}{4}} Fd∈R256×4H×4W。
- 首先, A d A_{d} Ad被喂入到一个语音编码器中,提取语音特征 F a u d i o ∈ R 128 F_{audio} \in R^{128} Faudio∈R128。
- 然后, I s I_{s} Is和 I r e f I_{ref} Iref分别作为两个不同的特征提取的输入,提取256维的源图像特征 F s ∈ R 256 × H × W F_{s} \in R^{256 \times H \times W} Fs∈R256×H×W和256维的参考图像特征 F r e f ∈ R 256 × H × W F_{ref} \in R^{256 \times H \times W} Fref∈R256×H×W。
- 接下来,合并 F s F_{s} Fs和 F r e f F_{ref} Fref,将其喂入到一个对齐编码器中计算得到对齐特征 F a l i g n ∈ R 128 F_{align} \in R^{128} Falign∈R128。
- 最后,合并语音特征 F a u d i o F_{audio} Faudio和对齐特征 F a l i g n F_{align} Falign,喂入一个全连接层后输出 [ R , T , S ] [R,T,S] [R,T,S]系数,然后传递给AdaAT算子,将特征 F r e f F_{ref} Fref形变为 F d F_{d} Fd。
注: 第四步的全连接网络被用于计算rotation R = { θ c } c = 1 256 R=\{\theta^{c}\}_{c=1}^{256} R={θc}c=1256、translation T x = { t x c } c = 1 256 / T y = { t y c } c = 1 256 T_{x} = \{t_{x}^{c}\}_{c=1}^{256} / T_{y} = \{t_{y}^{c}\}_{c=1}^{256} Tx={txc}c=1256/Ty={tyc}c=1256和Scale S = { s c } c = 1 256 S=\{s^{c}\}_{c=1}^{256} S={sc}c=1256的系数。然后这些仿射系数与 F r e f F_{ref} Fref做仿射变换。
(
x
c
,
y
c
)
\left(x_{c}, y_{c}\right)
(xc,yc)和
(
x
^
c
,
y
^
c
)
\left(\hat{x}_{c}, \hat{y}_{c}\right)
(x^c,y^c)分别为仿射变换前后的像素坐标,
c
∈
[
1
,
256
]
c \in [1,256]
c∈[1,256]为
F
r
e
f
F_{ref}
Fref中
c
t
h
c_{th}
cth的通道。
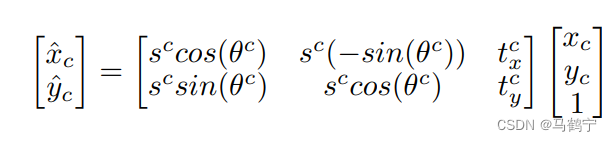
这也是为什么能选择AdaAT算子的原因,AdaAT算子在不同的特征通道中计算不同的仿射系数。
修补
修补网路 P I P^{I} PI相比于形变网络 P D P^{D} PD而言就简单很多,只包含一个由卷积层组成的特征解码器网络。将源图像特征 F s F_{s} Fs和形变特征 F d F_{d} Fd按通道合并后,送入到特征编码器后输出配音图像 I o ∈ R 3 × H × W I_{o} \in R^{3 \times H \times W} Io∈R3×H×W。
损失函数
在训练阶段,DINet的损失函数由三张不同的损失函数加权组成。
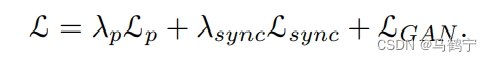
perception loss
感知损失(perception loss)是一种基于深度学习的图像风格迁移方法中常用的损失函数。感知损失是通过预训练的神经网络(常见是VGG网络)来计算两张图片之间的差异。感知损失的目标是最小化输入图像和目标图像在特征空间的距离。
在这篇论文中,首先对真实图像
I
r
I_{r}
Ir和配音图像
I
o
I_{o}
Io进行降采样分别得到
I
^
r
∈
R
3
×
H
2
×
W
2
\hat{I}_{r} \in R^{3 \times \frac{H}{2} \times \frac{W}{2}}
I^r∈R3×2H×2W和
I
^
o
∈
R
3
×
H
2
×
W
2
\hat{I}_{o} \in R^{3 \times \frac{H}{2} \times \frac{W}{2}}
I^o∈R3×2H×2W,然后一起计算
{
I
o
,
I
r
}
\{I_{o}, I_{r}\}
{Io,Ir}和
{
I
^
o
,
I
^
r
}
\{\hat{I}_{o}, \hat{I}_{r}\}
{I^o,I^r}的感知损失值。损失感知公式如下所示:

预训练模型选用VGG-19网路,
V
(
⋅
)
V\left( \cdot \right)
V(⋅)为
i
t
h
i_{th}
ith层,
W
i
H
i
C
i
W_{i}H_{i}C_{i}
WiHiCi为
i
t
h
i_{th}
ith层的特征尺寸。
GAN loss
GAN loss使用的是least square GAN,公式为
L
G
A
N
=
L
D
+
L
G
L_{GAN} = L_{D} + L_{G}
LGAN=LD+LG,
G
G
G表示的是DINet网络,
D
D
D为判别器。

论文中缺少判别器的资料。通过代码理解GAN loss。
# GAN 损失
class GANLoss(nn.Module):
'''
GAN loss
'''
def __init__(self, use_lsgan=True, target_real_label=1.0, target_fake_label=0.0):
super(GANLoss, self).__init__()
self.register_buffer('real_label', torch.tensor(target_real_label))
self.register_buffer('fake_label', torch.tensor(target_fake_label))
if use_lsgan:
self.loss = nn.MSELoss()
else:
self.loss = nn.BCELoss()
def get_target_tensor(self, input, target_is_real):
if target_is_real:
target_tensor = self.real_label
else:
target_tensor = self.fake_label
return target_tensor.expand_as(input)
def forward(self, input, target_is_real):
target_tensor = self.get_target_tensor(input, target_is_real)
return self.loss(input, target_tensor)
# train
net_dI = Discriminator(*) # 判别器D
net_g = DINet(*) # DINet网络
criterionGAN = GANLoss().cuda()
fake_out = net_g(*)
# (1) Update D network
optimizer_dI.zero_grad()
# compute fake loss
_,pred_fake_dI = net_dI(fake_out)
loss_dI_fake = criterionGAN(pred_fake_dI, False)
# compute real loss
_,pred_real_dI = net_dI(source_image_data)
loss_dI_real = criterionGAN(pred_real_dI, True)
# Combined DI loss
loss_dI = (loss_dI_fake + loss_dI_real) * 0.5
loss_dI.backward(retain_graph=True)
optimizer_dI.step()
Lip-sync loss
lip-sync损失是为了提高配音视频中的嘴唇的同步性。损失公式定义如下。
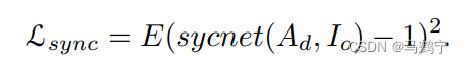
实现细节
- 所有的视频的帧率是25fps
- 根据OpenFace的68个面部关键点裁剪脸部区域
- 将所有的脸部区域resize为 416 × 320 416 \times 320 416×320大小,其中嘴部区域的大小为 256 × 256 256 \times 256 256×256
- 使用deepspeech模型提取29维的语音特征。语音特征与25fps的视频对齐。
- 训练视频分辨率为720P或者1080P
- Adam 优化器,学习率是0.0001
参考
- DINet code
- 论文:DINet: Deformation Inpainting Network for Realistic Face Visually Dubbing on High Resolution Video
- AAAI 2023 | DINet:实现高分辨率下的人脸视觉配音