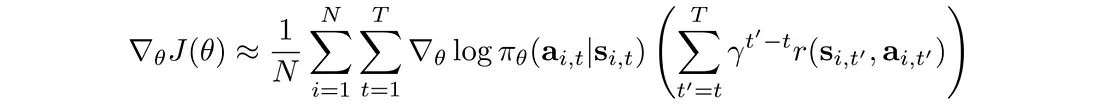文章目录
- 一、完整代码
- 二、论文解读
- 2.1 介绍
- 2.2 NMT
- 2.3 Unigram language model
- 2.4 subword 抽样
- 2.5 效果
- 三、整体总结
论文:Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates
作者:Taku Kudo
时间:2018
一、完整代码
这里我们使用python代码进行实现
# 完整代码在这里
有时间再来写;
二、论文解读
2.1 介绍
根据论文标题,subword regularization,类似于其他的regularization,其目的是为了增强结果的robust,这里的目标是利用多种分割方式产生的结果来改善NMT的效果;
subwords是一个解决NMT中的oov问题有效的方法,但是其在切词的时候会出现一个问题,就是说单个词可能被切割成多种形式,这给切割带来了模糊性,这里论文考虑能否利用切割的模糊性作为噪声来增强结果的鲁棒性;
论文中利用概率抽样的方式对多种分割方式进行抽取数据来进行训练;
BPE segmentation gives a good balance between the vocabulary size and the decoding efficiency, and also sidesteps the need for a special treatment of unknown words.
BPE能够很好的平衡词表大小和模型转化效率,但是其弊端在于同一个词可能有多种的分割方式;如图所示:

同一个词的多种分词方式可能会造成语意不明确,但是我们可以利用这个弊端,把其看作噪声进行训练;实验证明这种处理方式可以得到显著的改进;
2.2 NMT
NMT其本质是一个语言模型,给定一个序列 x = ( x 1 , x 2 , … , x 3 ) x=(x_1,x_2,\dots,x_3) x=(x1,x2,…,x3), y = ( y 1 , y 2 , … , y 3 ) y=(y_1,y_2,\dots,y_3) y=(y1,y2,…,y3),语言模型就是使

概率达到最大,本质使用的是最大似然估计MLE,在给定语料
D
=
{
<
X
(
s
)
>
,
<
Y
(
s
)
>
}
s
=
1
∣
D
∣
D=\{<X^{(s)}>,<Y^{(s)}>\}_{s=1}^{|D|}
D={<X(s)>,<Y(s)>}s=1∣D∣时,对总体,其Loss,就可以对
p
p
p,求log得到:

但是由于在分词的时候 x x x和 y y y可能会被分为多个subwords,所以这里我们可以把模型修改为

其中 P ( x ∣ X ) P(x|X) P(x∣X)和 P ( y ∣ Y ) P(y|Y) P(y∣Y)是 x x x和 y y y的分割概率,这个稍后会讲解是如何计算的;
由于分词数量相对于句子的长度呈现指数型增长,所以我们不可能把所有的分词都计算出来,我们只使用一部分,比如都只使用 k k k个分词结果,得到最后的公式为:
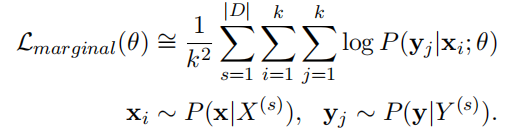
在decoding阶段,由于我们只有一个
x
x
x的分割序列,我们选出概率最大的
x
x
x作为best decoding,或者我们选出前几个概率最大的
x
x
x作为best decoding,后一种由于有不同的分割
x
i
x_i
xi,会产生不同的
y
i
y_i
yi,所以我们需要选择一个好的
y
i
y_i
yi来做最终的
y
y
y;这里论文给了一个评分公式:
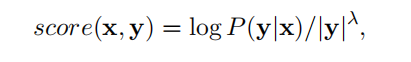
这里 ∣ y ∣ |y| ∣y∣是指 y y y的subwords的个数; λ \lambda λ是其惩罚参数;
2.3 Unigram language model
BPE分割方式是在NMT任务中运用较为广泛的一种方式,该方法可以有效平衡词表大小和模型转化效率,同一个词可能有多种的分割方式,这是我们需要利用的点,但是如何给出每种分割方式的概率很困难;
为了解决这个问题,这里提出了一个新的分割方法,利用Unigram language model去计算每个分割的subwords的分割概率;
首先定义 P ( x ) P(x) P(x)
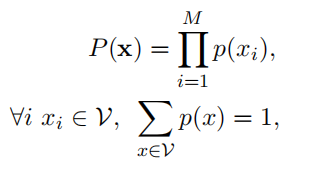
这里要满足上述条件,最简单的方式就是统计一段文本中subword出现的次数,然后用次数除以总次数得到 P ( x i ) P(x_i) P(xi);
这里再定义 S ( x ) S(x) S(x)为 x x x的所有分割序列;
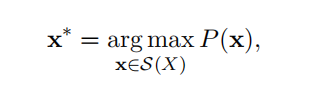
因为文本越长,subword就呈现指数型增长,这里并不好直接计算,但是可以利用Viterbi算法快速求到;
在给定词表vocabulary的情况下,我们接着定义:

通过EM估计最大化似然函数
L
L
L,再结合上面
P
(
x
)
P(x)
P(x)的定义等式条件,我们可以估计出每一个
P
(
x
i
)
P(x_i)
P(xi)
Unigram language model的步骤如下所示:
- 先从训练语料中建立一个种子词表,最自然的方式便是结合所处出现的字符以及最常见的字符串,由于UIM是从大表到小表,所以说初始表要尽可能的大才行;这里使用the Enhanced Suffix Array 算法,可以在O (T)时间和O(20T)空间中枚举频繁的子字符串,这里T是语料库的大小;然后选择出现次数排在前面的字符串便可;要值得注意的是,必须要包括所有的单个字符;
- 重复这一步直到
vocabulary的大小符合预期;首先在词表给定的情况下,通过EM估计每一个 P ( x i ) P(x_i) P(xi),然后计算在vocabulary中删除了 x i x_i xi后似然函数 L L L的变化 l o s s i loss_i lossi,把 l o s s i loss_i lossi从大到小排列,选择排在前面的 η \eta η%的 x i x_i xi构建新的词表;在这里必须要保证单个字符在词表内;
这样UIM的步骤就完成了!
最终的词汇表vocabulary包含了语料库中的所有单个字符,语言模型的分词可以看作是char、word和subword的概率混合;
2.4 subword 抽样
如上文介绍,抽样我们是从 P ( x ∣ X ) P(x|X) P(x∣X)分布中抽取,首先抽取 l − b e s t l-best l−best分割,这是我们主要考虑的分割;
P ( x ∣ X ) P(x|X) P(x∣X)分布如下,做了一些平滑处理,其中 α \alpha α是平滑因子:
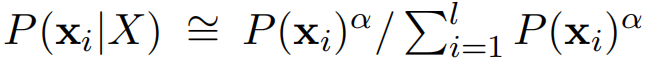
在 l l l趋近于无穷的时候,即充分考虑所有的分割,单个计算是不显示的,这里可以使用FFBS算法进行优化;
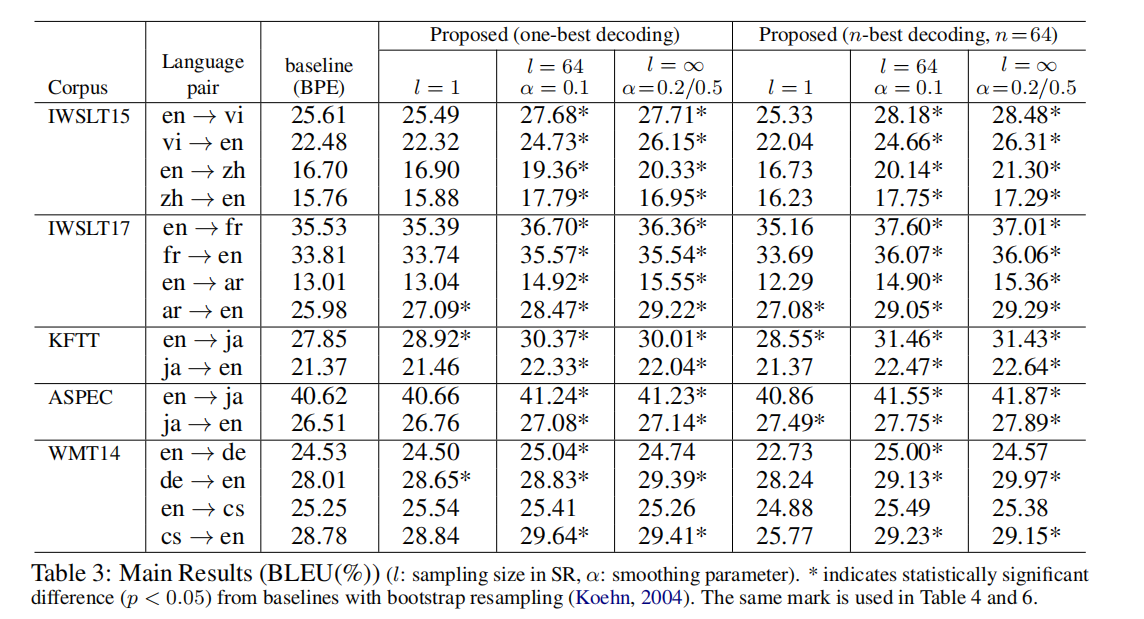
2.5 效果
效果如图所示,有一点点提升:
三、整体总结
noise regularization技术在神经网络中比较常见;
seq2seq中添加噪声:
- 通过改变句子顺序添加噪声 DAEs(Lample et al., 2017; Artetxe et al., 2017)
- 用word embeding的平均来表示word sequence,在平均之前,随机删除某些单词 Word dropout (Iyyer et al., 2015)
- 随机改变
word中character的顺序(Belinkov and Bisk, 2017)(Xie et al., 2017)
subword regularization背后的基本思想和动机与之前的工作相似。为了提高robust,通过随机改变句子的内部表示方式,向输入的句子注入噪声。然而,以往的方法往往依赖于启发式方法来产生合成噪声,这些噪声并不总是反映训练和推理时的真实噪声;此外,这些方法只能应用于源句(编码器),因为它们不可逆地重写了句子的表面。另一方面,subword regularization是用底层语言模型生成合成的子词序列,以更好地模拟噪声和分割错误。由于subword regularization是基于可逆转换的,我们可以安全地将其应用于源句和目标句。